






create table t_partition(
pname varchar2(10) not null,
pid char(5) not null,
psex varchar2(10),
ptime date
)
insert into t_partition(pname,pid,psex,ptime)values('张三','00001','男',sysdate);
insert into t_partition(pname,pid,psex,ptime)values('张三','00002','男',sysdate);
insert into t_partition(pname,pid,psex,ptime)values('张三','00003','男',sysdate);
insert into t_partition(pname,pid,psex,ptime)values('李四','00004','男',sysdate);
insert into t_partition(pname,pid,psex,ptime)values('李四','00005','男',sysdate);
insert into t_partition(pname,pid,psex,ptime)values('王五','00006','男',sysdate);

查询同一个人的重复纪录
select pname name,ptime time,count(pname) num
from t_partition
group by pname,ptime
(having pname='张三')

这条语句得问题:如果除了pname还有其他字段不同,则无法查询姓名相同的数量.
如 全部取出字段的话由于id不同 所以没有得到上图的效果
select pname name,ptime time,pid id,count(pname) num
from t_partition
group by pname,ptime,pid

如果用分区函数partition的话就可以解决这个问题
查询同一个人的重复纪录
select distinct pname name,ptime time,count(pname)over(partition by pname) num
from t_partition

增加id字段后的sql
select pname name,ptime time,pid id,count(pname)over(partition by pname) num
from t_partition
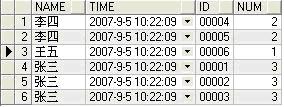
显示有些零乱,我自定义了一个聚合函数t_add
create or replace function t_add(t_str in SYS_REFCURSOR) return varchar2
is
Result varchar2(32767);
v_tmp varchar2(50);
begin
loop
fetch t_str into v_tmp;
exit when t_str%notfound;
Result := Result ||' '|| v_tmp;
end loop;
close t_str;
return(Result);
end t_add;
调用这个函数
select distinct a.pname name,a.ptime time,t_add(cursor(select b.pid from t_partition b where b.pname= a.pname)) id_collect,count(pname)over(partition by pname) num
from t_partition a

 欢迎交流
欢迎交流















 1804
1804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









