







partition by是Oracle中的一个分析函数。它的功能有点儿像分组函数group by,但又有较大区别。本文通过示例的方式,介绍一下partition by的用法。
数据准备
建表
create table xzq_person ( --行政区人口表
province varchar(10),
city varchar(10),
persons number(10)
);
插入数据
insert into xzq_person values ('江苏','苏州',10);
insert into xzq_person values ('江苏','南京',20);
insert into xzq_person values ('浙江','杭州',19);
insert into xzq_person values ('浙江','义乌',13);
insert into xzq_person values ('浙江','金华',11);
insert into xzq_person values ('广东','广州',18);
insert into xzq_person values ('广东','深圳',18);
insert into xzq_person values ('广东','中山',16);
insert into xzq_person values ('广东','惠州',16);
insert into xzq_person values ('广东','东莞',15);
partition by 的用法与含义
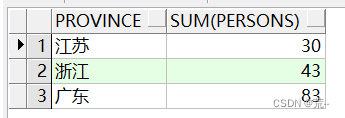
首先我们看一下group by的用法,比如根据省份分组。
select province, sum(persons) from xzq_person group by province;
使用了group by后,select语句中只能是分组的字段(比如上面的province)或者是一个聚合函数(比如count()、sum()、max()等等)。
partition从字面上看是分区、分块的意思,所以partition by其实就是根据某个字段将数据分块,然后可以对该分块数据再做查询(包括聚合查询)。
例如,partition by常同row_number() over一起使用:
select province, city, persons, row_number() over(partition by province order by persons) from xzq_person;
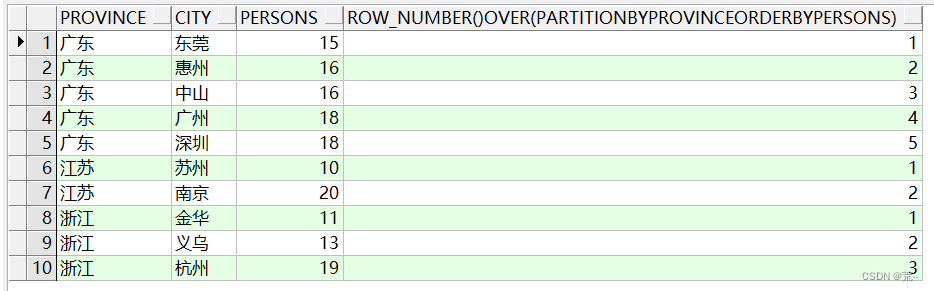
这个sql的作用就是根据province分组,并且分组后的每组的数据按照persons正序排序。
我们看到通过partition by分组后,select中是可以查出非分组的字段,这和group by是不一样的。
如果我们要查找每个省份人数最少的城市,可以用如下sql:
select * from (
select province, city, persons, row_number() over(partition by province order by persons) forder from xzq_person
) temp
where temp.forder=1;
其中,row_number()是对分组后的数据进行顺序连续排序。
除了row_number() over,partition by还可以跟rank() over、dense_rank()一起使用。
rank()、dense_rank()和row_number()排序的区别:
row_number()顺序排序,依次从第一个至最后一个。
rank()跳跃排序,如果有并列第一个会直接跳到第三个。
dense_rank()连续排序,如果有两个第一级别时仍然从第二级别开始。
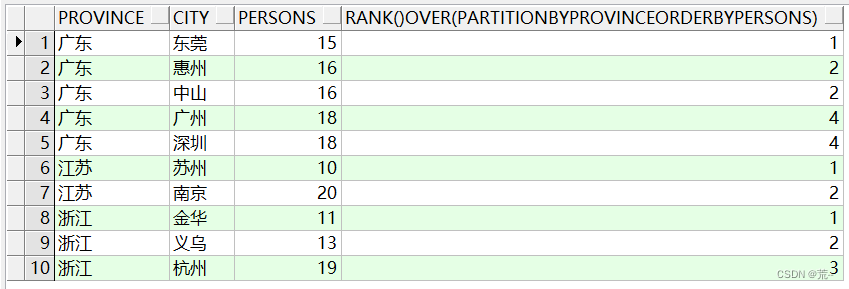
具体看如下的例子,使用partition by和rank() over一起使用。
select province, city, persons, rank() over(partition by province order by persons) from xzq_person;
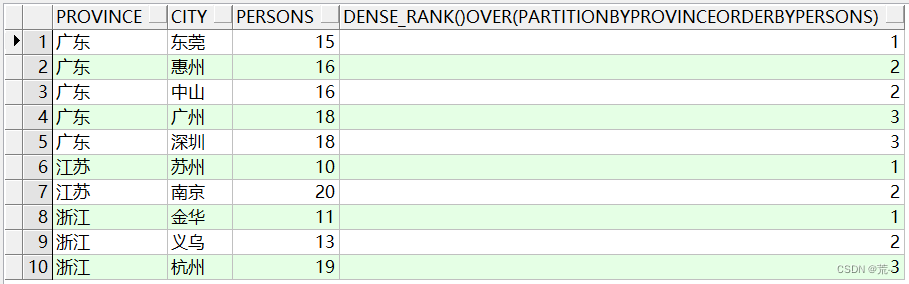
使用partition by和dense_rank() over一起使用。
select province, city, persons, dense_rank() over(partition by province order by persons) from xzq_person;
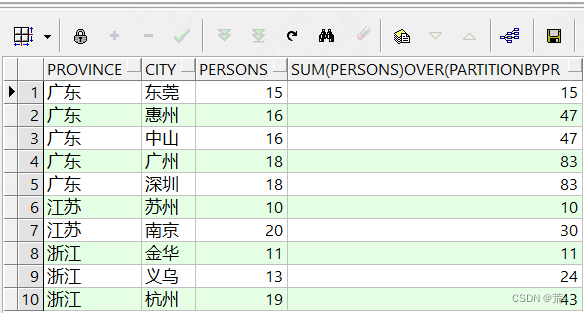
另外,也可以做分组+排序后,求累计值的功能等。
select province, city, persons, sum(persons) over(partition by province order by persons) forder from xzq_person;
用途举例
删除表中重复的记录
DELETE FROM T_PROD_CODE WHERE ID IN (
SELECT ID FROM (
SELECT CODE,ID,ROW_NUMBER() over(PARTITION BY CODE ORDER BY ID) AS RN FROM T_PROD_CODE
) T WHERE RN>1
);
练习SQL如下:
-- group by的用法,比如根据省份分组,根据人数多少排序
select province,sum(persons) as num from xzq_person GROUP BY province ORDER BY num;
-- partition从字面上看是分区、分块的意思,所以partition by其实就是根据某个字段将数据分块,然后可以对该分块数据再做查询(包括聚合查询)
-- partition by常同row_number() over一起使用
-- 这个sql的作用就是根据province分组,并且分组后的每组的数据按照persons正序排序
select province, city, persons, row_number() over(partition by province ORDER BY persons) from xzq_person;
select province, persons, row_number() over(partition by province ORDER BY persons) from xzq_person; -- 数据行不变,且不会分组,相比较上一个查询,只是少了一个查询列
---------------------------------------------------------------
-- 如果我们要查找每个省份人数最少的城市,如下
-- 先找出每个省份人数,按照升序排列
select province,persons, row_number() over(PARTITION BY province ORDER BY persons) as rankfirst from xzq_person;
select temp.* from(
select province,persons, row_number() over(PARTITION BY province ORDER BY persons) as rankfirst from xzq_person
) temp
where temp.rankfirst = 1;
-- 如果采用group by实现
select temp.province,min(temp.num) from(
select province,city,sum(persons) as num from xzq_person GROUP BY province,city order by persons
) temp GROUP BY temp.province;
----------------------------------------------------------------
/*
其中,row_number()是对分组后的数据进行顺序连续排序。
除了row_number() over,partition by还可以跟rank() over、dense_rank()一起使用。
rank()、dense_rank()和row_number()排序的区别:
row_number()顺序排序,依次从第一个至最后一个。
rank()跳跃排序,如果有并列第一个会直接跳到第三个。
dense_rank()连续排序,如果有两个第一级别时仍然从第二级别开始。
具体看如下的例子,使用partition by和rank() over一起使用
*/
select province,city,persons, rank() over(PARTITION BY province order by persons) from xzq_person;
select province,city,persons, dense_rank() over(PARTITION BY province order by persons) from xzq_person;
-- 删除表中code字段重复的记录,sql如下
DELETE FROM T_PROD_CODE WHERE ID IN (
SELECT ID FROM (
SELECT CODE,ID,ROW_NUMBER() over(PARTITION BY CODE ORDER BY ID) AS RN FROM T_PROD_CODE
) T WHERE RN>1
);
/*****查询案例二***/
1、数据
CREATE TABLE Student
(
s_id VARCHAR(20) COMMENT '学生编号',
s_name VARCHAR(20) NOT NULL DEFAULT '' COMMENT '学生姓名',
s_birth VARCHAR(20) NOT NULL DEFAULT '' COMMENT '出生年月',
s_sex VARCHAR(10) NOT NULL DEFAULT '' COMMENT '学生性别',
PRIMARY KEY (s_id)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8 COMMENT '学生表';
-- 课程表
CREATE TABLE Course
(
c_id VARCHAR(20) COMMENT '课程编号',
c_name VARCHAR(20) NOT NULL DEFAULT '' COMMENT '课程名称',
t_id VARCHAR(20) NOT NULL COMMENT '教师编号',
PRIMARY KEY (c_id)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8 COMMENT '课程表';
-- 教师表
CREATE TABLE Teacher
(
t_id VARCHAR(20) COMMENT '教师编号',
t_name VARCHAR(20) NOT NULL DEFAULT '' COMMENT '教师姓名',
PRIMARY KEY (t_id)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8 COMMENT '教师表';
-- 成绩表
CREATE TABLE Score
(
s_id VARCHAR(20) COMMENT '学生编号',
c_id VARCHAR(20) COMMENT '课程编号',
s_score INT(3) COMMENT '分数',
PRIMARY KEY (s_id, c_id)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8 COMMENT '成绩表';
-- 查询每门功课成绩最好的前两名
/*该sql查询所有信息列表*/
select stu.s_name,c_name,sc.s_score from score sc
left join student stu on stu.s_id = sc.s_id
left join course c on c.c_id = sc.c_id order by c_name;
-- 该sql查询没门课程前两名的详细数据
select c.c_name,stu.s_name,ss.s_score from(
select s_id,c_id,s_score from(
select s_id,c_id,s_score, dense_rank() over(PARTITION BY c_id ORDER BY s_score desc) as sc from score
) temp where temp.sc <= 2
) ss left join course c on ss.c_id = c.c_id
left join student stu on stu.s_id = ss.s_id;
/*不同课程,成绩相同的学生的学生编号、课程编号、学生成绩 建议使用PARTITION BY*/
select c.c_name,stu.s_name,temp.s_score from(
select s1.* from score s1 join score s2
where s1.s_id != s2.s_id and s1.c_id = s2.c_id and s1.s_score = s2.s_score
-- ORDER BY s1.c_id,s1.s_score
)temp
left join course c on temp.c_id = c.c_id
left join student stu on stu.s_id = temp.s_id
ORDER BY c.c_name,temp.s_score;
















 4141
4141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











