




UVFA通过值函数近似泛化任务目标,并在h-DQN等分层结构中与HRL相结合,实现了不同子目标值函数的高效统一学习,但其根本局限在于子目标本身仍完全依赖于人工设定。作为对UVFA框架的补充与发展,Option-Critic架构在同一时期选择了不同的技术路径。它从策略梯度方法出发,将核心目标设定为让模型自主地发现与学习子目标,从而在选项层面推动更高程度的自动化。
Option-Critic
Option-Critic(选项-评论家,本文简称OC)架构以Actor-Critic架构为基础,采用了选项框架来封装子任务,其设计目的是将选项内化为可学习的部件。回顾一下,在选项框架中,一个选项 ω ∈ Ω \omega\in\Omega ω∈Ω由三元组 ( I ω , π ω , β ω ) (\mathcal I_\omega,\pi_\omega,\beta_\omega) (Iω,πω,βω)描述:
- 初始集 I ω ⊆ S \mathcal I_\omega\subseteq\mathcal S Iω⊆S:规定了在哪些状态下可以启用这个选项;
- 内部策略 π ω \pi_\omega πω:一个底层策略,在执行选项时根据当前状态选择动作 a a a;
- 终止函数 β ω ( s ) ∈ [ 0 , 1 ] \beta_\omega(s)\in[0,1] βω(s)∈[0,1]:给出选项在状态 s s s下终止的概率。
OC假设所有选项 ω \omega ω都能在任意状态下被启用,即初始集 I ω \mathcal I_\omega Iω是整个状态空间 S \mathcal S S。模型将通过环境奖励学习选项的价值函数,在策略中隐式学习选项的初始集。
选项学习
OC的决策架构由一个上层策略 π Ω \pi_\Omega πΩ和所有选项 ω \omega ω的内部策略 π ω \pi_\omega πω组成。对于某个状态 s s s,智能体首先根据上层策略 π Ω \pi_\Omega πΩ选择一个选项 ω \omega ω,并将控制权交由其内部策略 π ω \pi_\omega πω。在 π ω \pi_\omega πω执行原始动作的每一步,选项的终止函数 β ω \beta_\omega βω都会评估当前状态以决定选项是否应该终止。选项终止后,控制权将返回给上层策略 π Ω \pi_\Omega πΩ,如此循环往复。
OC选项学习的视角与此前介绍的算法有所不同:
- 选项内部策略的学习不依赖人为设计的内部奖励,而是完全基于环境提供的全局奖励;
- 选项学习的出发点不在于如何将主任务分解为一系列子目标,而是在于评估选项的持续执行价值。
具体而言,OC学习每个选项应该在何时被坚持、何时被终止,即选项的终止函数。其判断依据为继续执行当前选项能否为最终任务带来更高的长期价值。可是内部策略也是我们随机初始化后交给模型同时学习的,这导致我们无从得知内部策略收敛后的具体行动逻辑,但模型确实“学会”了。这种追求自动化的选项学习的代价便是选项可解释性和可重用性的丧失。
在OC中,上层策略 π Ω \pi_\Omega πΩ直接根据选项的价值函数做出决策,每个选项的内部策略则由参数为 θ \theta θ的策略网络 π ω , θ \pi_{\omega,\theta} πω,θ来学习,每个选项的终止函数由参数为 ϑ \vartheta ϑ的网络 β ω , ϑ \beta_{\omega,\vartheta} βω,ϑ学习。OC没有限制不同选项的参数是独立还的是共享的,如果参数独立则每个选项都有自己的策略网络和终止函数网络,如果参数共享则策略和终止函数还需接收选项编码作为输入,因此选项的数量和编码方式仍然需要人为设计。
OC最大化的目标函数即为期望累积奖励(即时收益下标为 t + 1 t+1 t+1而非 t t t)
ρ ( Ω , θ , ϑ , s 0 , ω 0 ) = E [ ∑ t = 0 ∞ γ t r t + 1 ∣ s 0 , ω 0 ] \rho(\Omega,\theta,\vartheta,s_0,\omega_0)=\mathbb E\left[\left.\sum^\infty_{t=0}\gamma^tr_{t+1}\right|s_0,\omega_0\right] ρ(Ω,θ,ϑ,s0,ω0)=E[t=0∑∞γtrt+1 s0,ω0]
梯度定理:准备工作
为了给出选项框架下的策略梯度定理,OC定义了三个相互关联的价值函数,它们共同描述了在选项框架下的决策过程。在状态 s s s下,上层策略 π Ω \pi_\Omega πΩ选择并开始执行选项 ω \omega ω,随后遵循策略 π ω , θ \pi_{\omega,\theta} πω,θ直至选项 ω \omega ω终止,并将控制权交还上层策略 π Ω \pi_\Omega πΩ以继续进行决策循环,直至整个任务终止。在这个过程中
- 选项价值函数 Q Ω ( s , ω ) Q_\Omega(s,\omega) QΩ(s,ω)给出 π Ω \pi_\Omega πΩ在状态 s s s选择选项 ω \omega ω之后的期望累积奖励
Q Ω ( s , ω ) = E a ∼ π ω , θ ( ⋅ ∣ s ) [ Q U ( s , ω , a ) ] Q_\Omega(s,\omega)=\mathbb E_{a\sim\pi_{\omega,\theta}(\cdot|s)}[Q_U(s,\omega,a)] QΩ(s,ω)=Ea∼πω,θ(⋅∣s)[QU(s,ω,a)]
- 动作价值函数 Q U ( s , ω , a ) Q_U(s,\omega,a) QU(s,ω,a)给出 π ω , θ \pi_{\omega,\theta} πω,θ在状态 s s s选择动作 a a a之后的期望累积奖励
Q U ( s , ω , a ) = r ( s , a ) + γ E s ′ ∼ P ( ⋅ ∣ s , a ) [ U ( ω , s ′ ) ] Q_U(s,\omega,a)=r(s,a)+\gamma\mathbb E_{s'\sim P(\cdot|s,a)}[U(\omega,s')] QU(s,ω,a)=r(s,a)+γEs′∼P(⋅∣s,a)[U(ω,s′)]
- 抵达时价值函数 U ( ω , s ′ ) U(\omega,s') U(ω,s′)给出智能体带着选项 ω \omega ω转移到状态 s ′ s' s′之后的期望累积奖励
U ( ω , s ′ ) = ( 1 − β ω , ϑ ( s ′ ) ) Q Ω ( s ′ , ω ) + β ω , ϑ ( s ′ ) V Ω ( s ′ ) U(\omega,s')=(1-\beta_{\omega,\vartheta}(s'))Q_\Omega(s',\omega)+\beta_{\omega,\vartheta}(s')V_\Omega(s') U(ω,s′)=(1−βω,ϑ(s′))QΩ(s′,ω)+βω,ϑ(s′)VΩ(s′)
该函数即学习终止函数 β ω , ϑ \beta_{\omega,\vartheta} βω,ϑ的关键,它是两种情况的加权平均:
- 选项以 1 − β ω , ϑ ( s ′ ) 1-\beta_{\omega,\vartheta}(s') 1−βω,ϑ(s′)的概率不终止,后继回报即在状态 s ′ s' s′下选项 ω \omega ω的价值;
- 选项以 β ω , ϑ ( s ′ ) \beta_{\omega,\vartheta}(s') βω,ϑ(s′)的概率终止,后继回报即状态 s ′ s' s′由 π Ω \pi_\Omega πΩ重新决策的价值。
最后,由于选项是否终止这一因素的存在,OC定义了MDP在包含选项空间 Ω \Omega Ω的增强状态空间 S × Ω \mathcal S\times\Omega S×Ω下的转移概率,这将用于在梯度定理的推导中得到更简洁的形式
P ( s t + 1 , ω t + 1 ∣ s t , ω t ) = E a ∼ π ω t , θ ( ⋅ ∣ s t ) [ P ( s t + 1 ∣ s t , a ) ⋅ ( ( 1 − β ω t , ϑ ( s t + 1 ) ) 1 ω t = ω t + 1 + β ω t , ϑ ( s t + 1 ) π Ω ( ω t + 1 ∣ s t + 1 ) ) ] P(s_{t+1},\omega_{t+1}|s_t,\omega_t)=\mathbb E_{a\sim\pi_{\omega_t,\theta}(\cdot|s_t)}\Big[P(s_{t+1}|s_t,a)\cdot\Big((1-\beta_{\omega_t,\vartheta}(s_{t+1}))\mathbf 1_{\omega_t=\omega_{t+1}}+\beta_{\omega_t,\vartheta}(s_{t+1})\pi_{\Omega}(\omega_{t+1}|s_{t+1})\Big)\Big] P(st+1,ωt+1∣st,ωt)=Ea∼πωt,θ(⋅∣st)[P(st+1∣st,a)⋅((1−βωt,ϑ(st+1))1ωt=ωt+1+βωt,ϑ(st+1)πΩ(ωt+1∣st+1))]
其中指示函数 1 ω t = ω t + 1 \mathbf 1_{\omega_t=\omega_{t+1}} 1ωt=ωt+1在 ω t = ω t + 1 \omega_t=\omega_{t+1} ωt=ωt+1时为 1 1 1,否则为 0 0 0。该指示函数的意义是,选项不发生变化的概率需要计算“选项不终止”和“选项终止后被上层策略重新选择”两种情况,而选项变化的概率只需要计算“原选项 ω t \omega_t ωt终止后上层策略选择指定的新选项 ω t + 1 \omega_{t+1} ωt+1”的情况。
内部选项策略梯度定理
现在我们可以推导选项价值函数关于 θ \theta θ的梯度以学习内部策略 π ω , θ \pi_{\omega,\theta} πω,θ
∇ θ Q Ω ( s , ω ) = ∇ θ E a ∼ π ω , θ ( ⋅ ∣ s ) [ Q U ( s , ω , a ) ] = ∇ θ ∑ a π ω , θ ( a ∣ s ) Q U ( s , ω , a ) = ∑ a ( ∇ θ π ω , θ ( a ∣ s ) ⋅ Q U ( s , ω , a ) + π ω , θ ( a ∣ s ) ⋅ ∇ θ Q U ( s , ω , a ) ) = ∑ a ( ∇ θ π ω , θ ( a ∣ s ) ⋅ Q U ( s , ω , a ) + π ω , θ ( a ∣ s ) ⋅ ∇ θ ( r ( s , a ) + γ E s ′ ∼ P ( ⋅ ∣ s , a ) [ U ( ω , s ′ ) ] ) ) = ∑ a ( ∇ θ π ω , θ ( a ∣ s ) ⋅ Q U ( s , ω , a ) + γ π ω , θ ( a ∣ s ) ∑ s ′ P ( s ′ ∣ s , a ) ⋅ ∇ θ U ( ω , s ′ ) ) \begin{split} \nabla_\theta Q_\Omega(s,\omega)&=\nabla_\theta\mathbb E_{a\sim\pi_{\omega,\theta}(\cdot|s)}[Q_U(s,\omega,a)]\\ &=\nabla_\theta\sum_a\pi_{\omega,\theta}(a|s)Q_U(s,\omega,a)\\ &=\sum_a\Big(\nabla_\theta\pi_{\omega,\theta}(a|s)\cdot Q_U(s,\omega,a)+\pi_{\omega,\theta}(a|s)\cdot\nabla_\theta Q_U(s,\omega,a)\Big)\\ &=\sum_a\Big(\nabla_\theta\pi_{\omega,\theta}(a|s)\cdot Q_U(s,\omega,a)+\pi_{\omega,\theta}(a|s)\cdot\nabla_\theta(r(s,a)+\gamma\mathbb E_{s'\sim P(\cdot|s,a)}[U(\omega,s')])\Big)\\ &=\sum_a\Big(\nabla_\theta\pi_{\omega,\theta}(a|s)\cdot Q_U(s,\omega,a)+\gamma\pi_{\omega,\theta}(a|s)\sum_{s'}P(s'|s,a)\cdot\nabla_\theta U(\omega,s')\Big)\\ \end{split} ∇θQΩ(s,ω)=∇θEa∼πω,θ(⋅∣s)[QU(s,ω,a)]=∇θa∑πω,θ(a∣s)QU(s,ω,a)=a∑(∇θπω,θ(a∣s)⋅QU(s,ω,a)+πω,θ(a∣s)⋅∇θQU(s,ω,a))=a∑(∇θπω,θ(a∣s)⋅QU(s,ω,a)+πω,θ(a∣s)⋅∇θ(r(s,a)+γEs′∼P(⋅∣s,a)[U(ω,s′)]))=a∑(∇θπω,θ(a∣s)⋅QU(s,ω,a)+γπω,θ(a∣s)s′∑P(s′∣s,a)⋅∇θU(ω,s′))
我们需要进一步推导抵达时价值函数的梯度
∇ θ U ( ω , s ′ ) = ∇ θ [ ( 1 − β ω , ϑ ( s ′ ) ) Q Ω ( s ′ , ω ) + β ω , ϑ ( s ′ ) V Ω ( s ′ ) ] = ( 1 − β ω , ϑ ( s ′ ) ) ⋅ ∇ θ Q Ω ( s ′ , ω ) + β ω , ϑ ( s ′ ) ∑ ω ′ π Ω ( ω ′ ∣ s ′ ) ⋅ ∇ θ Q Ω ( s ′ , ω ′ ) = ∑ ω ′ [ ( 1 − β ω , ϑ ( s ′ ) ) 1 ω = ω ′ + β ω , ϑ ( s ′ ) π Ω ( ω ′ ∣ s ′ ) ] ⋅ ∇ θ Q Ω ( s ′ , ω ′ ) \begin{split} \nabla_\theta U(\omega,s')&=\nabla_\theta[(1-\beta_{\omega,\vartheta}(s'))Q_\Omega(s',\omega)+\beta_{\omega,\vartheta}(s')V_\Omega(s')]\\ &=(1-\beta_{\omega,\vartheta}(s'))\cdot\nabla_\theta Q_\Omega(s',\omega)+\beta_{\omega,\vartheta}(s')\sum_{\omega'}\pi_\Omega(\omega'|s')\cdot\nabla_\theta Q_\Omega(s',\omega')\\ &=\sum_{\omega'}[(1-\beta_{\omega,\vartheta}(s'))\mathbf 1_{\omega=\omega'}+\beta_{\omega,\vartheta}(s')\pi_{\Omega}(\omega'|s')]\cdot\nabla_\theta Q_\Omega(s',\omega') \end{split} ∇θU(ω,s′)=∇θ[(1−βω,ϑ(s′))QΩ(s′,ω)+βω,ϑ(s′)VΩ(s′)]=(1−βω,ϑ(s′))⋅∇θQΩ(s′,ω)+βω,ϑ(s′)ω′∑πΩ(ω′∣s′)⋅∇θQΩ(s′,ω′)=ω′∑[(1−βω,ϑ(s′))1ω=ω′+βω,ϑ(s′)πΩ(ω′∣s′)]⋅∇θQΩ(s′,ω′)
现在将其代回选项价值函数的梯度
∇ θ Q Ω ( s , ω ) = ∑ a ( ∇ θ π ω , θ ( a ∣ s ) ⋅ Q U ( s , ω , a ) + γ π ω , θ ( a ∣ s ) ∑ s ′ P ( s ′ ∣ s , a ) ⋅ ∑ ω ′ [ ( 1 − β ω , ϑ ( s ′ ) ) 1 ω = ω ′ + β ω , ϑ ( s ′ ) π Ω ( ω ′ ∣ s ′ ) ] ⋅ ∇ θ Q Ω ( s ′ , ω ′ ) ) = ∑ a ∇ θ π ω , θ ( a ∣ s ) ⋅ Q U ( s , ω , a ) + ∑ s ′ , ω ′ γ ∑ a π ω , θ ( a ∣ s ) P ( s ′ ∣ s , a ) [ ( 1 − β ω , ϑ ( s ′ ) ) 1 ω = ω ′ + β ω , ϑ ( s ′ ) π Ω ( ω ′ ∣ s ′ ) ] ⋅ ∇ θ Q Ω ( s ′ , ω ′ ) \begin{split} \nabla_\theta Q_\Omega(s,\omega)&=\sum_a\Big(\nabla_\theta\pi_{\omega,\theta}(a|s)\cdot Q_U(s,\omega,a)+\gamma\pi_{\omega,\theta}(a|s)\sum_{s'}P(s'|s,a)\cdot\sum_{\omega'}[(1-\beta_{\omega,\vartheta}(s'))\mathbf 1_{\omega=\omega'}+\beta_{\omega,\vartheta}(s')\pi_{\Omega}(\omega'|s')]\cdot\nabla_\theta Q_\Omega(s',\omega')\Big)\\ &=\sum_a\nabla_\theta\pi_{\omega,\theta}(a|s)\cdot Q_U(s,\omega,a)+\sum_{s',\omega'}\gamma\sum_a\pi_{\omega,\theta}(a|s)P(s'|s,a)[(1-\beta_{\omega,\vartheta}(s'))\mathbf 1_{\omega=\omega'}+\beta_{\omega,\vartheta}(s')\pi_{\Omega}(\omega'|s')]\cdot\nabla_\theta Q_\Omega(s',\omega') \end{split} ∇θQΩ(s,ω)=a∑(∇θπω,θ(a∣s)⋅QU(s,ω,a)+γπω,θ(a∣s)s′∑P(s′∣s,a)⋅ω′∑[(1−βω,ϑ(s′))1ω=ω′+βω,ϑ(s′)πΩ(ω′∣s′)]⋅∇θQΩ(s′,ω′))=a∑∇θπω,θ(a∣s)⋅QU(s,ω,a)+s′,ω′∑γa∑πω,θ(a∣s)P(s′∣s,a)[(1−βω,ϑ(s′))1ω=ω′+βω,ϑ(s′)πΩ(ω′∣s′)]⋅∇θQΩ(s′,ω′)
注意到第二项的概率分布包含增强状态空间 S × Ω \mathcal S\times\Omega S×Ω下的转移概率,我们记经过 k k k次折扣的转移概率为
P γ ( k ) ( s ′ , ω ′ ∣ s , ω ) = γ k P ( s ′ , ω ′ ∣ s , ω ) P_\gamma^{(k)}(s',\omega'|s,\omega)=\gamma^kP(s',\omega'|s,\omega) Pγ(k)(s′,ω′∣s,ω)=γkP(s′,ω′∣s,ω)
则选项价值函数梯度为
∇ θ Q Ω ( s , ω ) = ∑ a ∇ θ π ω , θ ( a ∣ s ) ⋅ Q U ( s , ω , a ) + ∑ s ′ , ω ′ P γ ( 1 ) ( s ′ , ω ′ ∣ s , ω ) ⋅ ∇ θ Q Ω ( s ′ , ω ′ ) (展开递归) = ∑ k = 0 ∞ ∑ s ′ , ω ′ P γ ( k ) ( s ′ , ω ′ ∣ s , ω ) ∑ a ∇ θ π ω , θ ( a ∣ s ) ⋅ Q U ( s , ω , a ) \begin{split} \nabla_\theta Q_\Omega(s,\omega) &=\sum_a\nabla_\theta\pi_{\omega,\theta}(a|s)\cdot Q_U(s,\omega,a)+\sum_{s',\omega'}P^{(1)}_\gamma(s',\omega'|s,\omega)\cdot\nabla_\theta Q_\Omega(s',\omega')\\ \text{(展开递归)}&=\sum^\infty_{k=0}\sum_{s',\omega'}P^{(k)}_\gamma(s',\omega'|s,\omega)\sum_a\nabla_\theta\pi_{\omega,\theta}(a|s)\cdot Q_U(s,\omega,a) \end{split} ∇θQΩ(s,ω)(展开递归)=a∑∇θπω,θ(a∣s)⋅QU(s,ω,a)+s′,ω′∑Pγ(1)(s′,ω′∣s,ω)⋅∇θQΩ(s′,ω′)=k=0∑∞s′,ω′∑Pγ(k)(s′,ω′∣s,ω)a∑∇θπω,θ(a∣s)⋅QU(s,ω,a)
其中折扣转移概率对 k k k的求和部分可视为从初始状态选项对 ( s 0 , ω 0 ) (s_0,\omega_0) (s0,ω0)开始,智能体访问状态选项对 ( s , ω ) (s,\omega) (s,ω)的折扣概率,记为
μ Ω ( s , ω ∣ s 0 , ω 0 ) = ∑ k = 0 ∞ P γ ( k ) ( s , ω ∣ s 0 , ω 0 ) \mu_\Omega(s,\omega|s_0,\omega_0)=\sum_{k=0}^\infty P^{(k)}_\gamma(s,\omega|s_0,\omega_0) μΩ(s,ω∣s0,ω0)=k=0∑∞Pγ(k)(s,ω∣s0,ω0)
则我们最终得到内部选项策略梯度定理为
∇ θ Q Ω ( s , ω ) = ∑ s , ω μ Ω ( s , ω ∣ s 0 , ω 0 ) ∑ a ∇ θ π ω , θ ( a ∣ s ) ⋅ Q U ( s , ω , a ) = ∑ s , ω , a μ Ω ( s , ω ∣ s 0 , ω 0 ) π ω , θ ( a ∣ s ) ∇ θ log π ω , θ ( a ∣ s ) ⋅ Q U ( s , ω , a ) = E s , ω ∼ μ Ω , a ∼ π ω , θ ( ⋅ ∣ s ) [ ∇ θ log π ω , θ ( a ∣ s ) ⋅ Q U ( s , ω , a ) ] \begin{split} \nabla_\theta Q_\Omega(s,\omega)&=\sum_{s,\omega}\mu_\Omega(s,\omega|s_0,\omega_0)\sum_a\nabla_\theta\pi_{\omega,\theta}(a|s)\cdot Q_U(s,\omega,a)\\ &=\sum_{s,\omega,a}\mu_\Omega(s,\omega|s_0,\omega_0)\pi_{\omega,\theta}(a|s)\nabla_\theta\log\pi_{\omega,\theta}(a|s)\cdot Q_U(s,\omega,a)\\ &=\mathbb E_{s,\omega\sim\mu_\Omega,a\sim\pi_{\omega,\theta}(\cdot|s)}[\nabla_\theta\log\pi_{\omega,\theta}(a|s)\cdot Q_U(s,\omega,a)] \end{split} ∇θQΩ(s,ω)=s,ω∑μΩ(s,ω∣s0,ω0)a∑∇θπω,θ(a∣s)⋅QU(s,ω,a)=s,ω,a∑μΩ(s,ω∣s0,ω0)πω,θ(a∣s)∇θlogπω,θ(a∣s)⋅QU(s,ω,a)=Es,ω∼μΩ,a∼πω,θ(⋅∣s)[∇θlogπω,θ(a∣s)⋅QU(s,ω,a)]
该定理优雅地匹配了策略梯度定理的一般形式。
终止梯度定理
(博主实在忍不住拿出原论文的证明过程进行批斗,想挑战自我的可以尝试理解这张图的推导)

现在我们推导目标函数对 ϑ \vartheta ϑ的梯度以学习终止函数 β ω , ϑ \beta_{\omega,\vartheta} βω,ϑ。 β ω , ϑ \beta_{\omega,\vartheta} βω,ϑ仅直接参与抵达时价值函数 U ( ω , s ′ ) U(\omega,s') U(ω,s′)的计算,我们先初步对抵达时价值函数求梯度
∇ ϑ U ( ω , s ′ ) = ∇ ϑ ( ( 1 − β ω , ϑ ( s ′ ) ) Q Ω ( s ′ , ω ) + β ω , ϑ ( s ′ ) V Ω ( s ′ ) ) = ∇ ϑ β ω , ϑ ( s ′ ) ⋅ ( V Ω ( s ′ ) − Q Ω ( s ′ , ω ) ) + ( 1 − β ω , ϑ ( s ′ ) ) ⋅ ∇ ϑ Q Ω ( s ′ , ω ) + β ω , ϑ ( s ′ ) ⋅ ∇ ϑ V Ω ( s ′ ) \begin{split} \nabla_\vartheta U(\omega,s')&=\nabla_\vartheta\Big((1-\beta_{\omega,\vartheta}(s'))Q_\Omega(s',\omega)+\beta_{\omega,\vartheta}(s')V_\Omega(s')\Big)\\ &=\nabla_\vartheta\beta_{\omega,\vartheta}(s')\cdot(V_\Omega(s')-Q_\Omega(s',\omega))+(1-\beta_{\omega,\vartheta}(s'))\cdot\nabla_\vartheta Q_\Omega(s',\omega)+\beta_{\omega,\vartheta}(s')\cdot\nabla_\vartheta V_\Omega(s') \end{split} ∇ϑU(ω,s′)=∇ϑ((1−βω,ϑ(s′))QΩ(s′,ω)+βω,ϑ(s′)VΩ(s′))=∇ϑβω,ϑ(s′)⋅(VΩ(s′)−QΩ(s′,ω))+(1−βω,ϑ(s′))⋅∇ϑQΩ(s′,ω)+βω,ϑ(s′)⋅∇ϑVΩ(s′)
将后面两项中的梯度展开
∇ ϑ Q Ω ( s ′ , ω ) = ∑ a π ω , θ ( a ∣ s ′ ) ∑ s ′ ′ γ P ( s ′ ′ ∣ s ′ , a ) ⋅ ∇ ϑ U ( ω , s ′ ′ ) ∇ ϑ V Ω ( s ′ ) = ∑ ω ′ π Ω ( ω ′ ∣ s ′ ) ∑ a π ω ′ , θ ( a ∣ s ′ ) ∑ s ′ ′ γ P ( s ′ ′ ∣ s ′ , a ) ⋅ ∇ ϑ U ( ω ′ , s ′ ′ ) \begin{split} &\nabla_\vartheta Q_\Omega(s',\omega)=\sum_a\pi_{\omega,\theta}(a|s')\sum_{s''}\gamma P(s''|s',a)\cdot\nabla_\vartheta U(\omega,s'')\\ &\nabla_\vartheta V_\Omega(s')=\sum_{\omega'}\pi_\Omega(\omega'|s')\sum_a\pi_{\omega',\theta}(a|s')\sum_{s''}\gamma P(s''|s',a)\cdot\nabla_\vartheta U(\omega',s'') \end{split} ∇ϑQΩ(s′,ω)=a∑πω,θ(a∣s′)s′′∑γP(s′′∣s′,a)⋅∇ϑU(ω,s′′)∇ϑVΩ(s′)=ω′∑πΩ(ω′∣s′)a∑πω′,θ(a∣s′)s′′∑γP(s′′∣s′,a)⋅∇ϑU(ω′,s′′)
由于公式太长,博主不列出将 ∇ ϑ Q Ω ( s ′ , ω ) \nabla_\vartheta Q_\Omega(s',\omega) ∇ϑQΩ(s′,ω)和 ∇ ϑ V Ω ( s ′ ) \nabla_\vartheta V_\Omega(s') ∇ϑVΩ(s′)代回 ∇ ϑ U ( ω , s ′ ) \nabla_\vartheta U(\omega,s') ∇ϑU(ω,s′)的完整结果。总之在代回后,如果将选项 ω \omega ω未终止的情况视为 ω ′ = ω \omega'=\omega ω′=ω,我们可以得到针对 ∇ ϑ U ( ω ′ , s ′ ′ ) \nabla_\vartheta U(\omega',s'') ∇ϑU(ω′,s′′)的概率分布也是增强状态空间 S × Ω \mathcal S\times\Omega S×Ω下的转移概率,因此 ∇ ϑ U ( ω , s ′ ) \nabla_\vartheta U(\omega,s') ∇ϑU(ω,s′)可简化为
∇ ϑ U ( ω , s ′ ) = ∇ ϑ β ω , ϑ ( s ′ ) ⋅ ( V Ω ( s ′ ) − Q Ω ( s ′ , ω ) ) + ∑ ω ′ , s ′ ′ P γ ( 1 ) ( s ′ ′ , ω ′ ∣ s ′ , ω ) ∇ ϑ U ( ω ′ , s ′ ′ ) \begin{split} \nabla_\vartheta U(\omega,s') =\nabla_\vartheta\beta_{\omega,\vartheta}(s')\cdot(V_\Omega(s')-Q_\Omega(s',\omega))+\sum_{\omega',s''}P^{(1)}_\gamma(s'',\omega'|s',\omega)\nabla_\vartheta U(\omega',s'')\end{split} ∇ϑU(ω,s′)=∇ϑβω,ϑ(s′)⋅(VΩ(s′)−QΩ(s′,ω))+ω′,s′′∑Pγ(1)(s′′,ω′∣s′,ω)∇ϑU(ω′,s′′)
现在记选项的优势函数为
A ( s , ω ) = Q ( s , ω ) − V ( s ) A(s,\omega)=Q(s,\omega)-V(s) A(s,ω)=Q(s,ω)−V(s)
代入梯度得
∇ ϑ U ( ω , s ′ ) = − ∇ ϑ β ω , ϑ ( s ′ ) ⋅ A Ω ( s ′ , ω ) + ∑ ω ′ , s ′ ′ P γ ( 1 ) ( s ′ ′ , ω ′ ∣ s ′ , ω ) ∇ ϑ U ( ω ′ , s ′ ′ ) (展开递归) = − ∑ ω ′ , s ′ ′ ∑ k = 0 ∞ P γ ( k ) ( s ′ ′ , ω ′ ∣ s ′ , ω ) ∇ ϑ β ω ′ , ϑ ( s ′ ′ ) ⋅ A Ω ( s ′ ′ , ω ′ ) \begin{split} \nabla_\vartheta U(\omega,s') &=-\nabla_\vartheta\beta_{\omega,\vartheta}(s')\cdot A_\Omega(s',\omega)+\sum_{\omega',s''}P^{(1)}_\gamma(s'',\omega'|s',\omega)\nabla_\vartheta U(\omega',s'')\\ \text{(展开递归)}&=-\sum_{\omega',s''}\sum_{k=0}^{\infty}P^{(k)}_\gamma(s'',\omega'|s',\omega)\nabla_\vartheta\beta_{\omega',\vartheta}(s'')\cdot A_\Omega(s'',\omega') \end{split} ∇ϑU(ω,s′)(展开递归)=−∇ϑβω,ϑ(s′)⋅AΩ(s′,ω)+ω′,s′′∑Pγ(1)(s′′,ω′∣s′,ω)∇ϑU(ω′,s′′)=−ω′,s′′∑k=0∑∞Pγ(k)(s′′,ω′∣s′,ω)∇ϑβω′,ϑ(s′′)⋅AΩ(s′′,ω′)
与内部选项策略梯度定理类似,将上式的求和转换为从初始选项 ω o \omega_o ωo和初始后继状态 s 1 s_1 s1开始,智能体访问后继状态-选项对 ( s ′ , ω ) (s',\omega) (s′,ω)的折扣概率,则最终我们得到终止梯度定理为
∇ ϑ U ( ω 0 , s 1 ) = − ∑ s ′ , ω μ Ω ( s ′ , ω ∣ s 1 , ω 0 ) ∇ ϑ β ω , ϑ ( s ′ ) ⋅ A Ω ( s ′ , ω ) = − E s ′ , ω ∼ μ Ω [ ∇ ϑ β ω , ϑ ( s ′ ) ⋅ A Ω ( s ′ , ω ) ] \begin{split} \nabla_\vartheta U(\omega_0,s_1)&=-\sum_{s',\omega}\mu_\Omega(s',\omega|s_1,\omega_0)\nabla_\vartheta\beta_{\omega,\vartheta}(s')\cdot A_\Omega(s',\omega)\\ &=-\mathbb E_{s',\omega\sim\mu_\Omega}[\nabla_\vartheta\beta_{\omega,\vartheta}(s')\cdot A_\Omega(s',\omega)] \end{split} ∇ϑU(ω0,s1)=−s′,ω∑μΩ(s′,ω∣s1,ω0)∇ϑβω,ϑ(s′)⋅AΩ(s′,ω)=−Es′,ω∼μΩ[∇ϑβω,ϑ(s′)⋅AΩ(s′,ω)]
算法流程
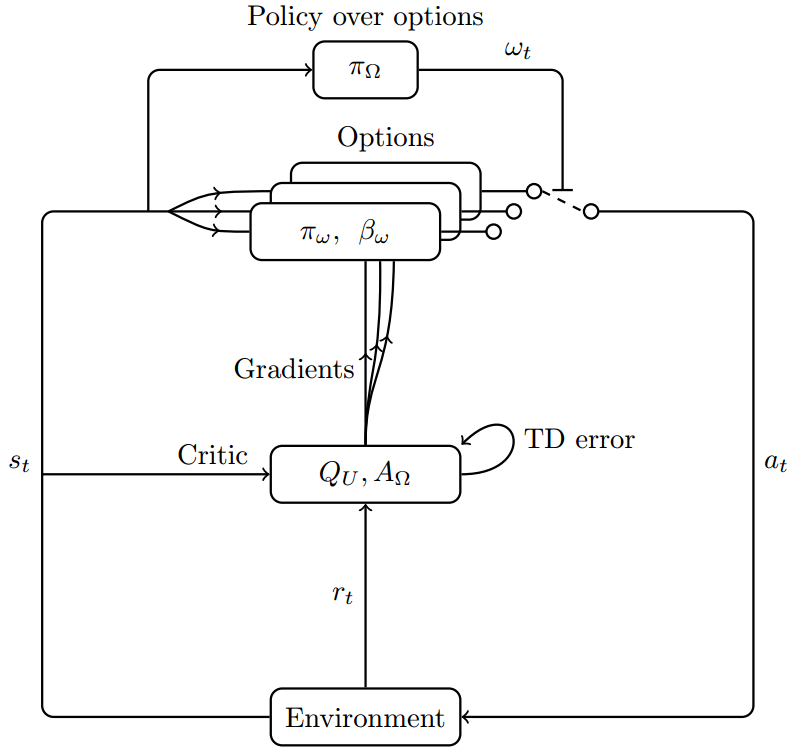
论文中同时提出了表格型Q学习和Q函数逼近两种算法形式,但是只给出了表格型Q学习的伪代码,因此我们也基于表格型Q学习介绍算法流程。 Q U ( s , ω , a ) Q_U(s,\omega,a) QU(s,ω,a)通过TD误差更新,如果后继状态不是终止状态,则估计目标为
g t = r t + 1 + γ ( ( 1 − β ω t , ϑ ( s t + 1 ) ) Q Ω ( s t + 1 , ω t ) + β ω t , ϑ ( s t + 1 ) max ω Q Ω ( s t + 1 , ω ) ) g_t=r_{t+1}+\gamma\left((1-\beta_{\omega_t,\vartheta}(s_{t+1}))Q_\Omega(s_{t+1},\omega_t)+\beta_{\omega_t,\vartheta}(s_{t+1})\underset{\omega}\max{}Q_\Omega(s_{t+1},\omega)\right) gt=rt+1+γ((1−βωt,ϑ(st+1))QΩ(st+1,ωt)+βωt,ϑ(st+1)ωmaxQΩ(st+1,ω))
价值函数 V Ω ( s t + 1 ) V_\Omega(s_{t+1}) VΩ(st+1)基于贪心策略给出,即为 max ω Q Ω ( s t + 1 , ω ) \underset{\omega}\max{}Q_\Omega(s_{t+1},\omega) ωmaxQΩ(st+1,ω)。如果后继状态是终止状态,估计目标 g t = r t + 1 g_t=r_{t+1} gt=rt+1。
Q Ω ( s , ω ) Q_\Omega(s,\omega) QΩ(s,ω)则直接由 Q U ( s , ω , a ) Q_U(s,\omega,a) QU(s,ω,a)和 π ω , θ ( a ∣ s ) \pi_{\omega,\theta}(a|s) πω,θ(a∣s)计算,并跟随二者同步更新
Q Ω ( s , ω ) = ∑ a π ω , θ ( a ∣ s ) Q U ( s , ω , a ) Q_\Omega(s,\omega)=\sum_a\pi_{\omega,\theta}(a|s)Q_U(s,\omega,a) QΩ(s,ω)=a∑πω,θ(a∣s)QU(s,ω,a)
内部策略 π ω , θ \pi_{\omega,\theta} πω,θ和终止函数 β ω , ϑ \beta_{\omega,\vartheta} βω,ϑ则分别由内部选项策略梯度和终止梯度更新。终止梯度计算所需的优势函数在梯度更新时计算如下
A Ω ( s ′ , ω ) = Q Ω ( s ′ , ω ) − max ω ′ Q Ω ( s ′ , ω ′ ) A_\Omega(s',\omega)=Q_\Omega(s',\omega)-\underset{\omega'}\max{}Q_\Omega(s',\omega') AΩ(s′,ω)=QΩ(s′,ω)−ω′maxQΩ(s′,ω′)
OC算法的伪代码如下:
- 初始化策略网络参数 θ , ϑ \theta,\vartheta θ,ϑ;
- 初始化 Q U ( s , ω , a ) Q_U(s,\omega,a) QU(s,ω,a)并计算 Q Ω ( s , ω ) Q_\Omega(s,\omega) QΩ(s,ω);
- 初始化学习率 α , α θ , α ϑ \alpha,\alpha_\theta,\alpha_\vartheta α,αθ,αϑ;
- 对每一幕循环:
- 初始化 s ← s 0 s\leftarrow s_0 s←s0;
- 根据 ϵ \epsilon ϵ-贪心策略选择选项 ω \omega ω;
- 循环直到
s
′
s'
s′是终止状态:
- 根据内部策略 π ω , θ \pi_{\omega,\theta} πω,θ选择动作 a a a;
- 执行动作 a a a,观测到后继状态 s ′ s' s′和收益 r r r;
- 计算TD误差 δ \delta δ;
- Q U ( s , ω , a ) ← Q U ( s , ω , a ) + α δ Q_U(s,\omega,a)\leftarrow Q_U(s,\omega,a)+\alpha\delta QU(s,ω,a)←QU(s,ω,a)+αδ;
- θ ← θ + α θ ∇ θ Q Ω ( s , ω ) \theta\leftarrow\theta+\alpha_\theta\nabla_\theta Q_\Omega(s,\omega) θ←θ+αθ∇θQΩ(s,ω);
- ϑ ← ϑ + α ϑ ∇ ϑ U ( ω , s ′ ) \vartheta\leftarrow\vartheta+\alpha_\vartheta\nabla_\vartheta U(\omega,s') ϑ←ϑ+αϑ∇ϑU(ω,s′);
- 更新 Q Ω ( s , ω ) Q_\Omega(s,\omega) QΩ(s,ω);
- 如果
β
ω
,
ϑ
\beta_{\omega,\vartheta}
βω,ϑ在
s
′
s'
s′终止:
- 根据 ϵ \epsilon ϵ-贪心策略选择新选项 ω \omega ω;
- 更新 s ← s ′ s\leftarrow s' s←s′。

















 1690
1690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









