




自MAXQ算法(1999)提出后的十余年间,分层强化学习领域的发展长期受限于两大瓶颈:
- 层次结构严重依赖专家知识进行人工设计;
- 算法以表格型为主,难以处理高维或连续状态空间。
这些局限极大地制约了方法的泛化性与可扩展性,直至深度强化学习的兴起,分层强化学习才迎来了取得实质性突破的转机。
UVFA
UVFA(Universal Value Function Approximators,通用值函数逼近器)引入目标作为值函数的计算模型并交由神经网络学习。其初衷是利用神经网络实现目标的泛化,让单一智能体能完成多种任务,并共享任务间的知识,却间接成为了分层强化学习思想与深度强化学习相结合的奠基性工作。
带目标的值函数
传统的值函数逼近器V(s∣θ)V(s|\theta)V(s∣θ)主要依赖状态空间S\mathcal SS的结构来学习观测状态的值,并将其泛化到未观测状态。而在强化学习中,任务目标ggg通常也体现为期望的状态或状态转移,因此目标空间G\mathcal GG往往与状态空间S\mathcal SS具有相似的结构特性。基于这一洞察,UVFA将值函数逼近器的输入扩展到为状态sss和目标ggg两个维度,构建出通用值函数逼近器V(s,g∣θ)V(s,g|\theta)V(s,g∣θ)。一个训练充分的UVFA能够识别并利用状态与目标之间的联合结构,从而学习到任意状态sss在任意目标ggg下的价值。
UVFA中,伪奖励函数和奖励折扣的实现更加灵活,它提出对于目标ggg和策略π\piπ,含目标的值函数计算定义如下
Vg,π(s)=˙Eπ[∑t=0∞(Rg(st+1,a,st)∏k=0tγg(sk))∣s0=s] V_{g,\pi}(s)\dot=\mathbb E_\pi\left[\left.\sum^\infty_{t=0}\left(R_g(s_{t+1},a,s_t)\prod^t_{k=0}\gamma_g(s_k)\right)\right|s_0=s\right] Vg,π(s)=˙Eπ[t=0∑∞(Rg(st+1,a,st)k=0∏tγg(sk))s0=s]
Qg,π(s,a)=˙Eπ[Rg(s,a,s′)+γg(s′)Vg,π(s′)] Q_{g,\pi}(s,a)\dot=\mathbb E_\pi[R_g(s,a,s')+\gamma_g(s')V_{g,\pi}(s')] Qg,π(s,a)=˙Eπ[Rg(s,a,s′)+γg(s′)Vg,π(s′)]
其中
- Rg(s,a,s′)R_g(s,a,s')Rg(s,a,s′)为伪奖励函数,通常设计为参数化函数R(s,a,s′∣wg)R(s,a,s'|w_g)R(s,a,s′∣wg)。wgw_gwg可以是
- 状态sss的加权系数,表示对不同状态量的偏好;
- 目标ggg的某种表示,例如用ggg的坐标根据当前位置到ggg的距离给予奖励;
- 目标ggg的判断条件,例如为状态sss设置阈值,根据其是否在阈值范围内给予奖励。
- γg(s)\gamma_g(s)γg(s)为伪折扣系数,其具有两个作用
- 奖励折扣,能够根据状态sss和目标ggg灵活调整对未来的规划深度,可以考虑由神经网络学习,但通常我们采取简单的人为设计,并对大部分情况采取统一的外部折扣γext\gamma_{ext}γext;
- 软终止,当状态sss实现目标ggg时,令γg(s)=0\gamma_g(s)=0γg(s)=0以截断回报计算。
得益于深度学习强大的表示与学习能力,目标ggg的定义方式也更为灵活多样,具体可包括以下形式:
- 状态子集:指期望达到的某个特定状态,例如目标位置的坐标;
- 状态属性:指状态所需满足的某种属性,例如机器人是否抓持物体;
- 状态映射:指与状态空间相关的另一空间中的表示,例如当状态空间为机器人关节空间时,目标空间可为末端执行器的笛卡尔空间;
- 伪奖励函数:指需要最大化的奖励信号,例如游戏中的金币数量或经验值。
为了将目标ggg作为神经网络的输入,我们还需对其进行合理表示,常用的输入形式包括:
- 原始表示:当目标是状态子集或状态映射时,可直接使用其原始形式作为输入;
- 特征向量:当目标可由一系列属性描述时,用一个∣G∣|\mathcal G|∣G∣维向量表示(∣G∣|\mathcal G|∣G∣为属性总数),每一维对应一个属性的数值或布尔值;
- 独热编码:当目标为离散且数量有限时,用一个∣G∣|\mathcal G|∣G∣维向量表示(∣G∣|\mathcal G|∣G∣为目标总数),目标gig_igi对应的向量在第iii维为111,其余为000;
- 函数参数:对于人为设计的参数化的伪奖励函数目标,可以使用伪奖励函数的参数wgw_gwg作为输入。
总体而言,从原始表示到独热编码,表示方式的复杂性逐渐降低,但其泛化能力也随之减弱,而函数参数的泛化能力由设计方式决定。
因子分解
泛化能力好坏的关键在于相似的目标是否具有相似的表示。在独热编码下,任意目标向量之间均正交,不具有任何相似度信息,模型则无从利用部分已知的目标数据预测未知的目标数据。例如在汉语中,如果我们知道“狗”和“猫”是什么,那我们也能合理推测“狼”大概属于兽类,因为它们具有相同的偏旁,而在英语中知道“dog”和“cat”是不可能猜出“wolf”的任何信息的。但是对于复杂任务中的目标,例如“倒水”和“接水”,人为设计一个能客观反映二者相似信息的数据表示是不可能的。
向值函数引入额外输入ggg也为其学习带来了新的挑战,因为与单一的状态空间相比,状态-目标组合的数量呈指数级增长,而我们却难以进一步获取更多的数据,导致数据稀疏性问题显著加剧。一方面相应的算力、时间成本也会增加,另一方面许多状态-目标组合是无意义或不可行的。例如机器人以“在厨房”为初始状态实现“冲马桶”的目标,显然设置一个“在卫生间”的中间目标会合理得多。或者让只能水平移动的平台立起一个已经倒下的倒立摆,这违背了物理定律。
这是一个广泛存在于大规模机器学习的问题,即稀疏矩阵问题。如果以状态sss为行,目标ggg为列,值函数V(s,g)V(s,g)V(s,g)为元素,则该数据矩阵的绝大多数都为零。尽管其具有良好的可解释性,但是却给模型泛化训练带来困难,尤其是当我们的状态和目标表示本身的泛化能力就不足时。
我们无法改变数据稀疏这一客观约束(至少是从机器学习算法层面),只能从表示上的泛化入手。一个普遍方法是嵌入向量,其核心思想是利用神经网络改进人为设计的表示方法,即让神经网络将高维稀疏空间中的对象映射到一个低维稠密空间,学会从非结构化的、缺乏语义的数据表示中捕捉到隐含的语义信息和内在联系,最终输出的表示即为嵌入向量。由嵌入向量给出的数据点具有更高的信息密度,通过泛化可以弥补更多的数据空白。例如我们对世界上所有的城市进行独热编码作为模型输入来估计任意两个城市之间的距离,直接训练需要海量的测量数据,因为一对城市的距离对模型推断其他城市对的距离的帮助是极低的。但是通过引入嵌入层,模型很可能会利用嵌入层学习到每个城市的经纬度作为嵌入向量,由此算出任意城市对的距离便水到渠成了。不过实际上出于嵌入向量可解释性不足的缺点,我们完全无法知道嵌入层会学习到何种表示。
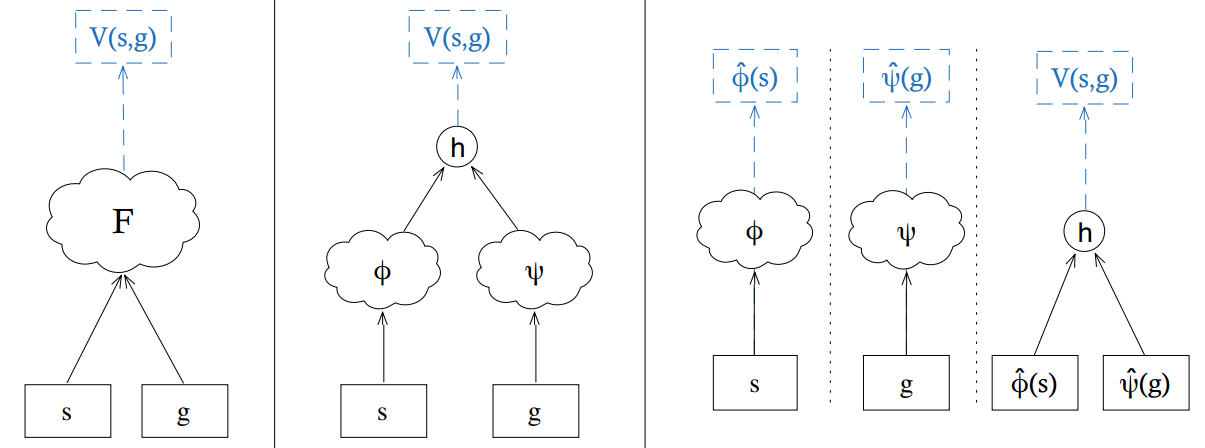
嵌入向量在UVFA中的应用被称为因子分解。原始的UVFA合并状态sss和目标ggg输入到网络FFF计算V(s,g)V(s,g)V(s,g),而因子分解先用两个独立子网络ϕ\phiϕ和ψ\psiψ的双流架构学习状态sss到状态嵌入ϕ(s)\phi(s)ϕ(s)和目标ggg到目标嵌入ψ(g)\psi(g)ψ(g)的映射,再将二者合并输入到网络hhh计算V(s,g)V(s,g)V(s,g)。嵌入网络跟随整个价值估计任务一同进行端到端的训练。论文中采用了数据矩阵的低秩分解得到嵌入向量的标签值,但这涉及矩阵分解理论,且与端到端训练效果等价,故本文不作探讨。
h-DQN
h-DQN(Hierarchical Deep Q-Network,分层深度Q网络)将UVFA的核心思想与分层强化学习相结合,设计出了元控制器-控制器双层架构。
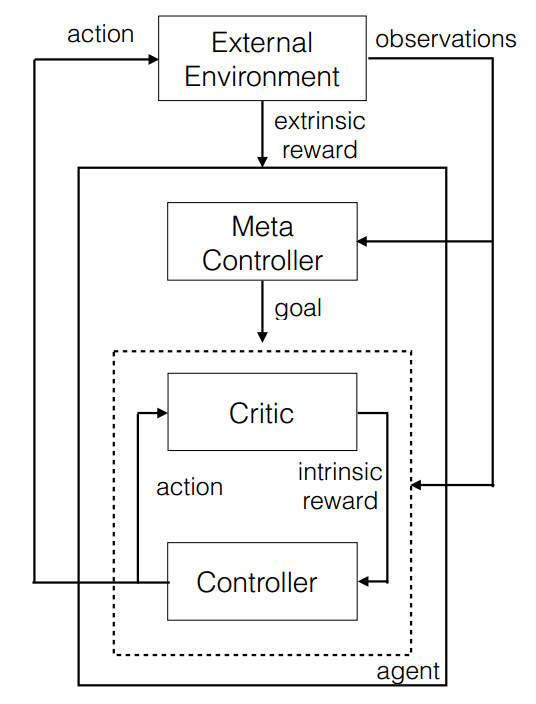
元控制器-控制器
(论文中控制器下标为111,元控制器下标为222,但博主认为按照与下标相反的顺序介绍二者更合逻辑)
元控制器负责接收状态sts_tst并为控制器由策略πg\pi_gπg选择子目标gt∈Gg_t\in\mathcal Ggt∈G,其目标函数是最大化累积环境奖励
Ft=∑t′=t∞γt′−tft′ F_t=\sum^\infty_{t'=t}\gamma^{t'-t}f_{t'} Ft=t′=t∑∞γt′−tft′
总目标即由元控制器从环境奖励中学习,由此元控制器的估计目标形式即为一般的动作价值函数,只是子目标ggg替换了动作aaa
Q2∗(s,g)=maxπgE[∑t′=tt+Nft′+γmaxg′Q2∗(st+N,g′)∣st=s,gt=g,πg] Q^*_2(s,g)=\underset{\pi_g}\max{}\mathbb E\left[\sum^{t+N}_{t'=t}f_{t'}+\gamma\underset{g'}\max{}Q^*_2(s_{t+N},g')|s_t=s,g_t=g,\pi_g\right] Q2∗(s,g)=πgmaxE[t′=t∑t+Nft′+γg′maxQ2∗(st+N,g′)∣st=s,gt=g,πg]
(该式与最大化累积环境奖励的目标不一致。累积环境奖励FtF_tFt的计算似乎是从单个时间步的尺度对ft′f_{t'}ft′进行折扣的,但是Q2∗(s,g)Q^*_2(s,g)Q2∗(s,g)的计算却对每个子目标执行过程中的ft′f_{t'}ft′简单累加,仅在子目标决策的宏观时间步进行折扣。这是h-DQN论文中一个令人费解的矛盾,文中没有任何解释,博主暂时推测其目的是为了让元控制器进一步从宏观层面学习长期的战略价值)
控制器则接收状态sts_tst,并根据元控制器下达的子目标gtg_tgt由子策略πag\pi_{ag}πag选择动作ata_tat,其目标函数是最大化累积内部奖励
Rt(g)=∑t′=t∞γt′−trt′(g) R_t(g)=\sum^\infty_{t'=t}\gamma^{t'-t}r_{t'}(g) Rt(g)=t′=t∑∞γt′−trt′(g)
控制器的估计目标也相应地采用了带目标的价值函数
Q1∗(s,a;g)=maxπagE[rt+γmaxa′Q1∗(s′,a′;g)∣st=s,at=a,gt=g,πag] Q_1^*(s,a;g)=\underset{\pi_{ag}}\max{}\mathbb E\left[\left.r_t+\gamma\underset{a'}\max{}Q^*_1(s',a';g)\right|s_t=s,a_t=a,g_t=g,\pi_{ag}\right] Q1∗(s,a;g)=πagmaxE[rt+γa′maxQ1∗(s′,a′;g)st=s,at=a,gt=g,πag]
由于DQN采取最大化操作得到最优动作价值函数,因此对于元控制器,目标空间G\mathcal GG实际上被限制为离散的,而控制器则利用来自元控制器离散的ggg点对连续的目标空间进行拟合。
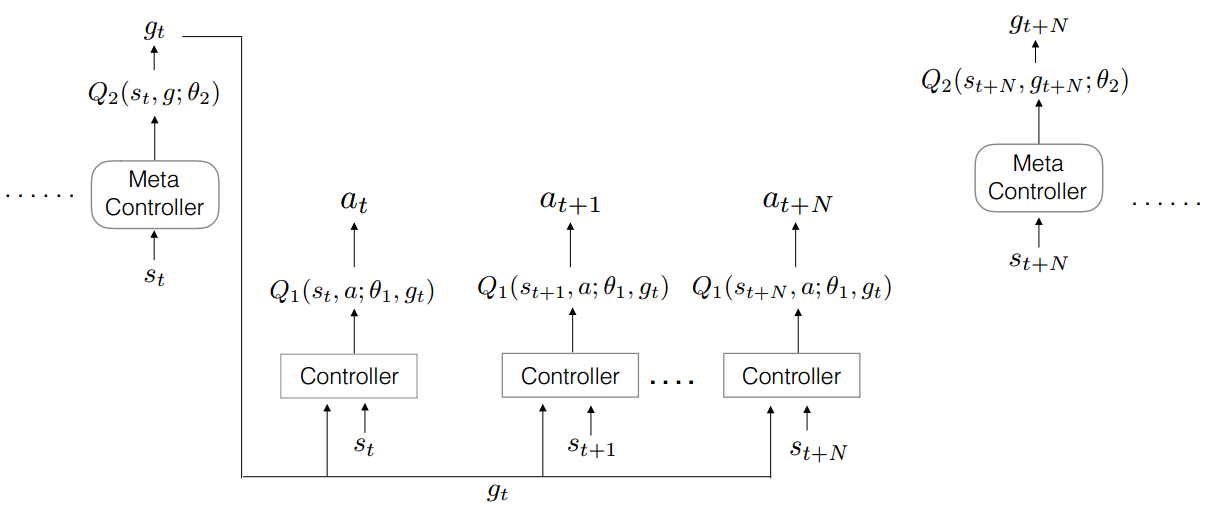
学习算法
现在,我们可以用两个Q网络Q2(s,g;θ2)Q_2(s,g;\theta_2)Q2(s,g;θ2)和Q1(s,a;θ1,g)Q_1(s,a;\theta_1,g)Q1(s,a;θ1,g)来拟合最优价值函数Q2∗(s,g)Q^*_2(s,g)Q2∗(s,g)和Q1∗(s,a;g)Q_1^*(s,a;g)Q1∗(s,a;g)。我们采用经验回放,将两个网络的经验(st,gt,ft,st+N)(s_t,g_t,f_t,s_{t+N})(st,gt,ft,st+N)和(st,at,gt,rt,st+1)(s_t,a_t,g_t,r_t,s_{t+1})(st,at,gt,rt,st+1)分别存入D2\mathcal D_2D2和D1\mathcal D_1D1,则Q1Q_1Q1的损失函数为
L1(θ1)=E(s,a,g,r,s′)∼D1[(rt+γmaxa′Q1∗(s′,a′;g)−Q1(s,a,;θ1,g))2] L_1(\theta_{1})=\mathbb E_{(s,a,g,r,s')\sim\mathcal D_1}[(r_t+\gamma\underset{a'}\max{}Q^*_1(s',a';g)-Q_1(s,a,;\theta_1,g))^2] L1(θ1)=E(s,a,g,r,s′)∼D1[(rt+γa′maxQ1∗(s′,a′;g)−Q1(s,a,;θ1,g))2]
其梯度为
∇θ1L1(θ1)=E(s,a,g,r,s′)∼D1[(rt+γmaxa′Q1∗(s′,a′;g)−Q1(s,a,;θ1,g))∇θ1Q1(s,a;θ1,g)] \nabla_{\theta_1}L_1(\theta_1)=\mathbb E_{(s,a,g,r,s')\sim\mathcal D_1}[(r_t+\gamma\underset{a'}\max{}Q^*_1(s',a';g)-Q_1(s,a,;\theta_1,g))\nabla_{\theta_1}Q_1(s,a;\theta_1,g)] ∇θ1L1(θ1)=E(s,a,g,r,s′)∼D1[(rt+γa′maxQ1∗(s′,a′;g)−Q1(s,a,;θ1,g))∇θ1Q1(s,a;θ1,g)]
(论文在后续伪代码中又将D1\mathcal D_1D1中的样本不严谨地记为({s,g},a,r,{s′,g})(\{s,g\},a,r,\{s',g\})({s,g},a,r,{s′,g}),博主只能理解为后继状态中的ggg实际上为后继目标g′g'g′)
Q2Q_2Q2的损失函数及其梯度的形式与Q1Q_1Q1相似。
h-DQN采取ϵ\epsilonϵ-贪心策略进行探索,其中ϵ\epsilonϵ相当于探索率。控制器和元控制器采用不同的探索率ϵ1,g\epsilon_{1,g}ϵ1,g和ϵ2\epsilon_2ϵ2,并且初始值均设为111。元控制器的探索率ϵ2\epsilon_2ϵ2随时间推移减小(退火),而控制器的探索率ϵ1,g\epsilon_{1,g}ϵ1,g的退火则依赖于达到特定子目标ggg的平均成功率,平均成功率越高,则可以降低探索率以稳定现有策略,反之则继续维持高探索率。
h-DQN算法的伪代码如下:
- 初始化经验回放缓存区{D1,D2}\{\mathcal D_1,\mathcal D_2\}{D1,D2}和网络参数{θ1,θ2}\{\theta_1,\theta_2\}{θ1,θ2};
- 初始化控制器对所有目标的探索率和元控制器的探索率ϵ1,g=ϵ2=1\epsilon_{1,g}=\epsilon_2=1ϵ1,g=ϵ2=1;
- 对每一幕循环:
- 初始化当前状态sss;
- 根据ϵ2\epsilon_{2}ϵ2-贪心选择子目标ggg;
- 循环直到sss为终止状态:
- 初始化累积环境奖励F=0F=0F=0;
- 初始化初始状态s0=ss_0=ss0=s;
- 循环直到sss为终止状态或实现目标ggg:
- 根据ϵ1,g\epsilon_{1,g}ϵ1,g-贪心选择动作aaa;
- 执行aaa,获得后继状态s′s's′和环境奖励fff;
- 从内部评估器获得内部奖励r(s,a,s′)r(s,a,s')r(s,a,s′);
- 存储经验({s,g},a,r,{s′,g′})(\{s,g\},a,r,\{s',g'\})({s,g},a,r,{s′,g′})到D1\mathcal D_1D1;
- 从D1\mathcal D_1D1中随机抽取小批量对θ1\theta_1θ1进行梯度下降;
- 从D2\mathcal D_2D2中随机抽取小批量对θ2\theta_2θ2进行梯度下降;
- 更新累积环境奖励F←fF\leftarrow fF←f;
- 更新当前状态s←s′s\leftarrow s's←s′。
- 存储经验(s0,g,F,s′)(s_0,g,F,s')(s0,g,F,s′)到D2\mathcal D_2D2;
- 如果sss不是终止状态:
- 根据ϵ2\epsilon_{2}ϵ2-贪心选择子目标ggg。
- 对ϵ2\epsilon_2ϵ2进行退火,并根据达到目标ggg的平均成功率对ϵ1,g\epsilon_{1,g}ϵ1,g进行自适应退火。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









