







目录
零、Pytorch并行模块
1、Data_parallel
单机多卡:数据并行的方式,网络的input数据一般要求IId,被切割成子集,不同子集作为不同device的输入(device指gpu,上面的model都是一样的)。然后计算的loss一般放到nn.DataParallel()的output_device设备上,导致该设备内存占用相比更大。
代码:
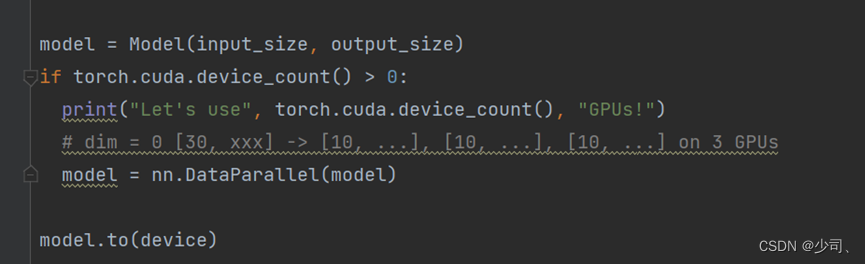
2、多进程封装方式
(1)torch.multiprocessing里面的process,这种方式有点类似在终端执行两次python train.py &。这里是要加&符号的。
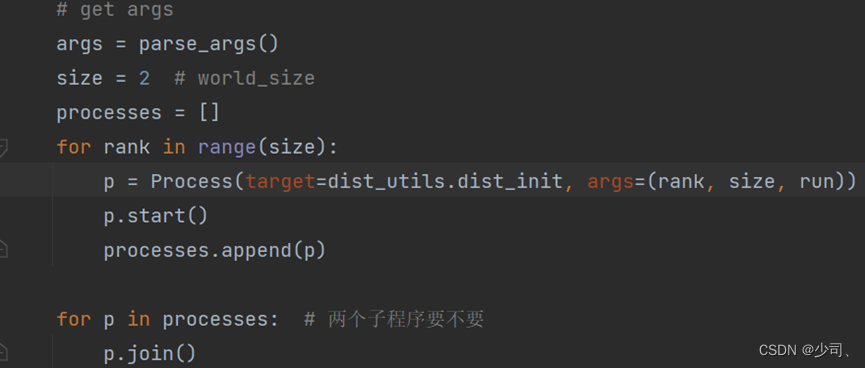
在终端启用。每个torch.distributed.launch会启动n个进程,并给每个进程一个--local_rank=i的参数。有多少台机器:--nnodes;当前是哪台机器:--node_rank;每台机器有多少个进程:--nproc_per_node;高级参数(多机模式)通讯的address和通讯的port
(3)torch.multiprocessing.spawn
mp.spawn和process有点类似,如下

一、实验目的和实验内容
了解并掌握分布式算法中的集体通信和参数聚合策略
|
1.1实验介绍
本次实验是在单机模拟分布式系统,通过多进程来模拟多节点,使用Pytorch的DDP模块来进行分布式任务。
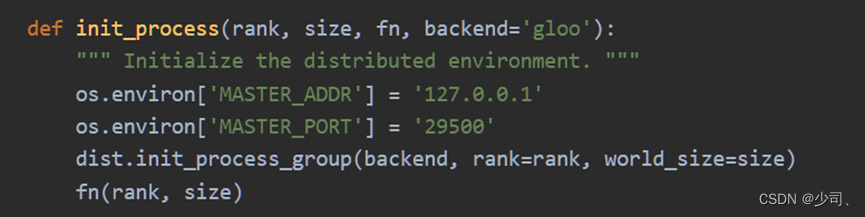
创建DDP模块,首先正确设置过程组,初始化分布式环境。

Init_process确保每个进程都可以使用相同的 IP 地址和端口通过主机进行协调,包括设置
torch.distributed支持点对点通信和集合通信,数据从一个进程到另一个进程的传输称为点对点通信,这些是通过send和recv函数或其直接对应部分isend和irecv实现的。
与点对点通信相反,集合允许跨组中所有进程的通信模式。Pytorch提供4中运算符和7个集合体。

任务是通过pytorch的通信原语来实现参数的广播、收集和聚合。
二、实验设计
2.1对model实现参数的广播、收集和聚合
(1)对不同进程的model进行同一参数的初始化
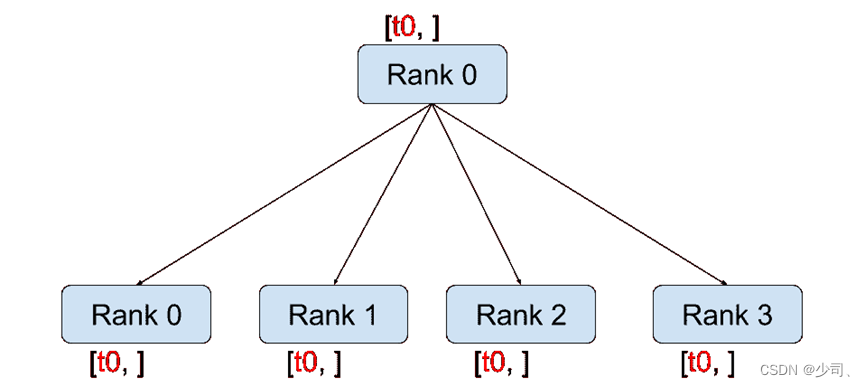
使用boardcast来操作,0代表进程rank 0,就是第一个进程的model参数复制到其他进程的model里。
(2)训练过程里,还需要对不同进程的参数进行聚合,例如使用all_reduce来聚合模型的参数。
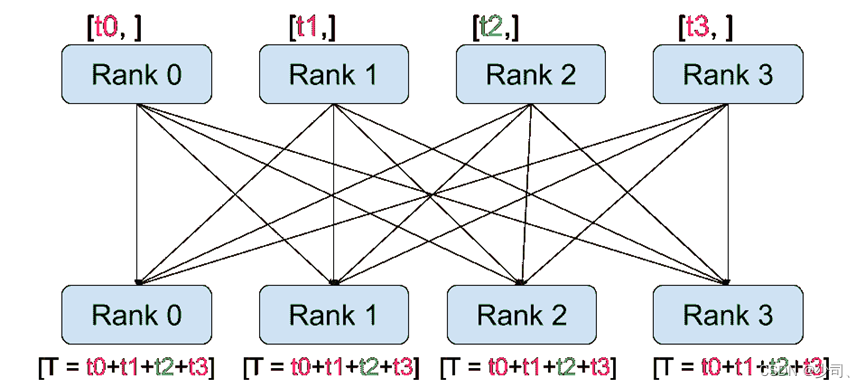
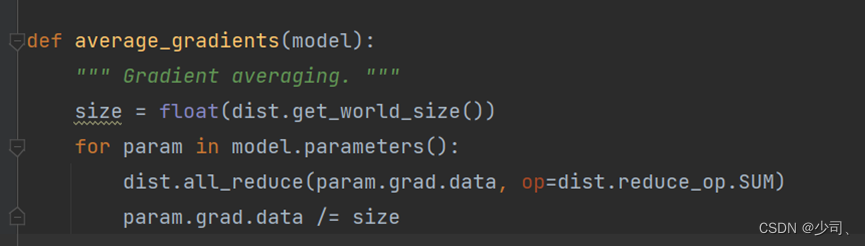
这里的实现主要是对grad做的,采用SUM运算符。
对于参数聚合,处理all_reduce以外,采用reduce+boardcast实现all_reduce相同的功能。
| 通信原语 | Rank数 | Train_time | ||
| All_reduce | 2 | 12.083552837371826 | ||
| Reduce+boardcast | 2 | 12.250021696090698 | ||
| All_reduce | 1 | 14.21995210647583 | ||
| Reduce+boardcast | 1 | 14.708715438842773 |
2.2设置瓶颈节点
对rank=1进程设置sleep,查看运算时间
| 瓶颈节点实验 | 参数聚合方式 | Sleep | ||
| Exp_name | All_reduce | Rank 0 | Rank 1 | Train_time |
| 1 | 是 | 不 | 不 | 10.395909786224365 |
| 2 | 是 | 不 | Rank启动时sleep 0.001秒 | 12.336158275604248 |
| 3 | 是 | 不 | 每次聚合时sleep 0.01秒 | 36.61159658432007 |
| 4 | 是 | 不 | 每次loss.backward sleep 6s | |
2.2.1 聚合时间瓶颈
为了查看一次参数聚合不同时间的影响,我打印了聚合前后的时间。
Rank1 使用sleep 0.5s

正常聚合时间是:
2.2.2 梯度计算时间瓶颈
聚合操作需要考虑所有rank的梯度,这一过程里面sleep,根据pytorch的提示应该是会wait的。
对rank1的loss.backward后加上sleep可以看见,
再打印聚合参数完成的时间: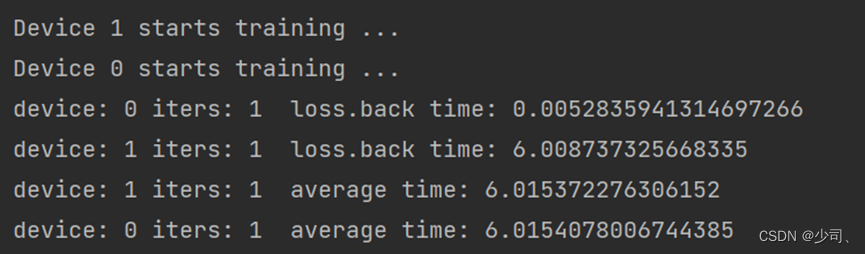
通过上图可以看见,参数聚合的过程是需要所有rank一同时间的。前面的loss. Backward的计算梯度过程时间的差异会体现在模型参数聚合过程。
可以理解,因为想loss计算、梯度计算和梯度更新,在pytorch里面都是针对当前进程的。















 4950
4950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









