






1 概述
由于工作原因,需要把期货品种的交易数据以板块分类,然后统计出来。每次在Excel上做虽然不难,但也繁琐,遂想把这一工作写成脚本,一劳永逸。
实现效果如下:
对数据分类和统计倒是不难,但使用了第三方库 #Webio来交互,#Pyecharts来显示,#Pyinstaller来打包,尤其是打包过程颇费心力。趁着热乎劲儿记到这里,即为自己以后查看,也为有需要的人提供借鉴。
直接贴上代码:
#!/usr/bin/env python
# coding: utf-8
import warnings
import pandas as pd
from pywebio.input import file_upload
from pyecharts.charts import Bar #导入需要使用的图表
from pyecharts import options as opts #导入配置项
from pyecharts.globals import ThemeType
from pywebio.output import put_column, put_html
warnings.filterwarnings("ignore")
# 读取文件函数
def read_in():
file = file_upload('请选择需要加载的数据')
df1 = pd.read_excel(file['content'])
df2 = (df1['合约'].str.extract(r'(?P<品种>.*?)(?P<月份>\d+(?:\.\d+)?)')
.applymap(str.strip))
data = pd.concat([df1, df2], axis=1).drop('合约', axis=1)
return data
# 计算函数
def process(data):
# 读入数据
data = data
data['板块'] = '---'
# 根据类别打标签
for i in range(len(data)):
if data['品种'][i] in 贵金属: data['板块'][i] = '贵金属'
if data['品种'][i] in 有色: data['板块'][i] = '有色'
if data['品种'][i] in 煤焦钢矿: data['板块'][i] = '煤焦钢矿'
if data['品种'][i] in 非金属建材: data['板块'][i] = '非金属建材'
if data['品种'][i] in 能源: data['板块'][i] = '能源'
if data['品种'][i] in 化工: data['板块'][i] = '化工'
if data['品种'][i] in 谷物: data['板块'][i] = '谷物'
if data['品种'][i] in 油脂油料: data['板块'][i] = '油脂油料'
if data['品种'][i] in 软商品: data['板块'][i] = '软商品'
if data['品种'][i] in 农副产品: data['板块'][i] = '农副产品'
if data['品种'][i] in 金融期货: data['板块'][i] = '金融期货'
# 构造输出结果
result = pd.DataFrame(columns=['多头市值', '多头市值占比', '空头市值', '空头市值占比', '轧差市值'], index=sector)
# 根据源数据计算多头空头市值
for i in range(len(sector)):
result.loc[sector[i]].多头市值 = data[(data['板块'] == sector[i]) & (data['卖持仓'] == 0)].sum().持仓市值 # 多头
result.loc[sector[i]].空头市值 = data[(data['板块'] == sector[i]) & (data['买持仓'] == 0)].sum().持仓市值 # 空头
# 计算总市值
TMV = result.多头市值.sum() - result.空头市值.sum() # TMV:Total Market Value
# 计算市值占比和轧差市值
result.多头市值占比 = pd.DataFrame.abs(result.多头市值 / TMV)
result.空头市值占比 = pd.DataFrame.abs(result.空头市值 / TMV)
result.轧差市值 = result.多头市值 - result.空头市值
long = []
short = []
for i in range(len(result.多头市值.tolist())):
long.append(round(float(result.多头市值占比.tolist()[i]), 2))
short.append(round(float(result.空头市值占比.tolist()[i]), 2))
result.多头市值占比 = pd.DataFrame.abs(result.多头市值 / TMV).map(lambda x: format(x, '.0%'))
result.空头市值占比 = pd.DataFrame.abs(result.空头市值 / TMV).map(lambda x: format(x, '.0%'))
return result, long, short
# 画柱状图函数
def create_bar(bar_dict):
# 建立百分比的柱状图
bar_item = bar_dict['item']
bar_head = bar_dict['head']
bar_data = bar_dict['data']
bar = (
Bar(init_opts=opts.InitOpts(height="400px", width="600px", theme=ThemeType.WHITE))
.add_xaxis(bar_item)
)
for i in range(len(bar_head)):
bar.add_yaxis(bar_head[i], bar_data[i], label_opts=opts.LabelOpts(formatter="{c} %"))
bar.set_global_opts(
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter="{value} %"), interval=10))
bar.set_global_opts(title_opts=opts.TitleOpts(title='板块市值占比'),
xaxis_opts=opts.AxisOpts(name_rotate=60, name="板块", axislabel_opts={"rotate": 45}),
yaxis_opts=opts.AxisOpts(name="市值占比(%)"))
return bar
# 获取数据函数
def get_data_dict():
# 这里获取要显示的数据 , 可以改成连接数据库
data_a = [round(n * 100, 2) for n in long]
data_b = [round(n * 100, 2) for n in short]
pdt_list = sector.tolist()
data_dict = {'data': [data_a, data_b], 'head': ['多头市值', '空头市值'], 'item': pdt_list}
return data_dict
# 分类方法
贵金属 = ['au', 'ag']
有色 = ['al', 'pb', 'ni', 'zn', 'sn', 'cu', 'bc']
煤焦钢矿 = ['SM', 'SF', 'i', 'jm', 'hc', 'ss', 'wr', 'j', 'rb']
非金属建材 = ['FG', 'bb', 'v', 'fb']
能源 = ['pg', 'lu', 'sc', 'fu', 'ZC']
化工 = ['MA', 'eg', 'TA', 'UR', 'eb', 'PF', 'l', 'bu', 'sp', 'nr', 'pp', 'ru', 'SA']
谷物 = ['WH', 'c', 'rr', 'RI', 'JR', 'LR', 'PM']
油脂油料 = ['y', 'a', 'RM', 'p', 'RS', 'OI', 'm', 'b', 'PK']
软商品 = ['CF', 'CY', 'SR']
农副产品 = ['CJ', 'jd', 'cs', 'AP', 'lh']
金融期货 = ['T', 'TS', 'TF', 'IF', 'IH', 'IC', 'IM']
# 板块分类
sector = pd.Series(['贵金属', '有色', '煤焦钢矿', '非金属建材', '能源', '化工', '谷物', '油脂油料', '软商品', '农副产品', '金融期货'])
if __name__ == "__main__":
data = read_in() # 读取数据
result, long, short = process(data) #
data_dict = get_data_dict()
bar = create_bar(data_dict)
put_column([
put_html(bar.render_notebook()),
put_html(result.to_html(border=0)),
]).show()2 说一下值得记录的点:
2.1 根据字符和数字分列
原数据是这样的格式:
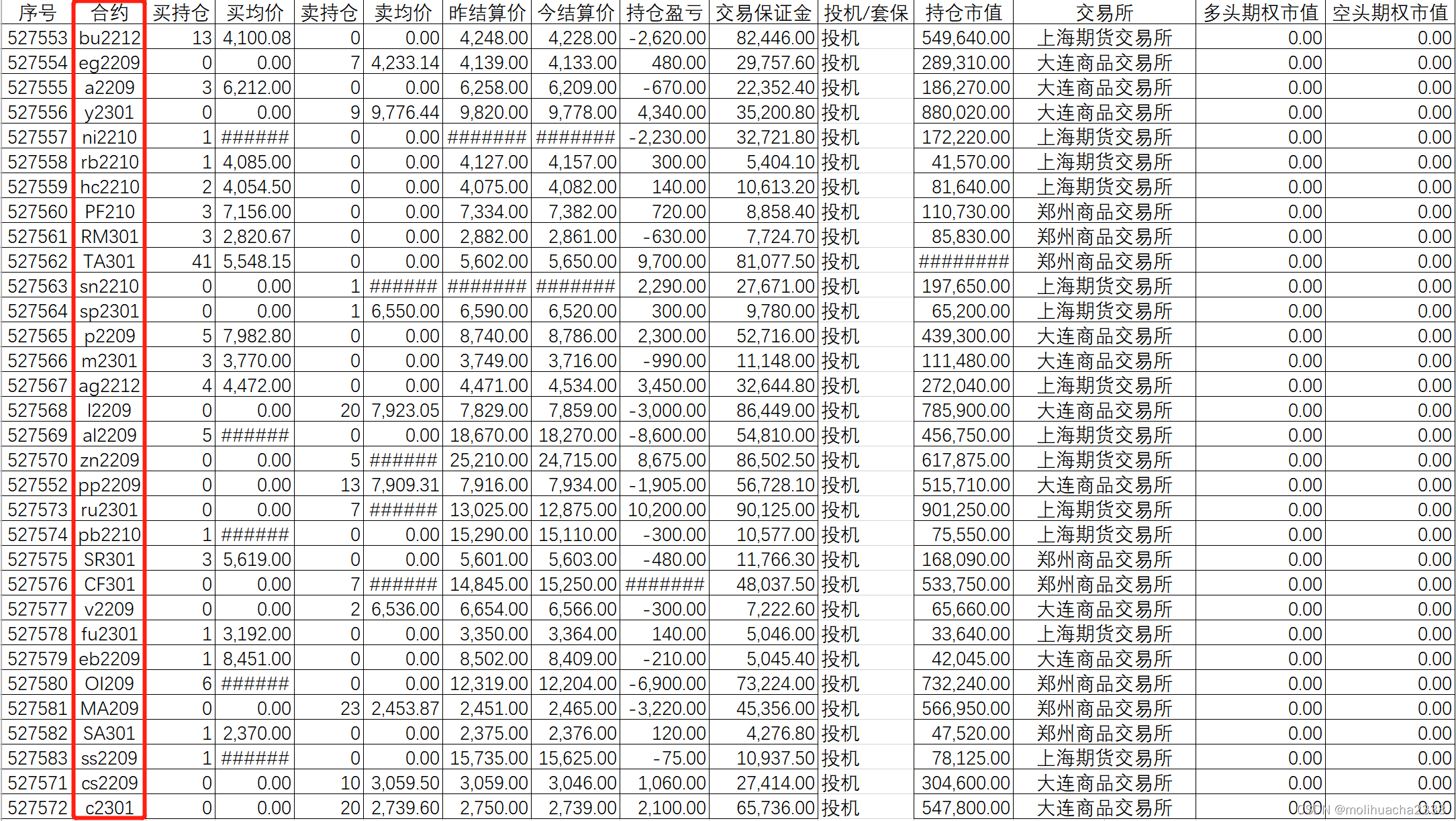
其中【合约】由前半部分的字符和后半部分的数字组成,为了处理方便需要将二者分开,然后放到不同的列里。此动作的核心代码如下:
df2 = (df1['合约'].str.extract(r'(?P<品种>.*?)(?P<月份>\d+(?:\.\d+)?)')
.applymap(str.strip))1.2 Pyecharts生成带百分比的柱状图
本来Pyecharts画图不难,但生成百分比的标签有些繁琐,核心代码如下:
# 画柱状图函数
def create_bar(bar_dict):
# 建立百分比的柱状图
bar_item = bar_dict['item']
bar_head = bar_dict['head']
bar_data = bar_dict['data']
bar = (
Bar(init_opts=opts.InitOpts(height="400px", width="600px", theme=ThemeType.WHITE))
.add_xaxis(bar_item)
)
for i in range(len(bar_head)):
bar.add_yaxis(bar_head[i], bar_data[i], label_opts=opts.LabelOpts(formatter="{c} %"))
bar.set_global_opts(
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter="{value} %"), interval=10))
bar.set_global_opts(title_opts=opts.TitleOpts(title='板块市值占比'),
xaxis_opts=opts.AxisOpts(name_rotate=60, name="板块", axislabel_opts={"rotate": 45}),
yaxis_opts=opts.AxisOpts(name="市值占比(%)"))
return bar
麻烦的关键点在于数字格式只能是小数,百分比格式只能是字符串。
这是因为Pyecharts对输入数据的要求比较苛刻,要求规整的【list】形式,且【list】内的元素必须是【int】。
笔者用Pandas构造的DataFrame,使用to_list命令后虽然可以得到【list】格式,但其中的元素却是【numpy.int64】,所以一直识别不了,卡住了很久。
所以使用下述函数对数据进行规整:
# 获取数据函数
def get_data_dict():
# 这里获取要显示的数据 , 可以改成连接数据库
data_a = [round(n * 100, 2) for n in long]
data_b = [round(n * 100, 2) for n in short]
pdt_list = sector.tolist()
data_dict = {'data': [data_a, data_b], 'head': ['多头市值', '空头市值'], 'item': pdt_list}
return data_dict原理就是遍历旧list后放到新列表中,以待输入画图函数中。
2.3 使用Pywebio库输入和输出
这是个蛮有趣的库,可以利用浏览器进行数据交互,既可以做本地脚本,也可以部署到网络。本项目只是用了基础的脚本模式,做到输入和输出。
2.3.1 输入
输入还是比较简单的,只需要使用file_upload函数唤起浏览器即可。
唤起的浏览器输入页面如下,直接选择对应的文件就好,笔者这里的文件是Excel.xls格式。
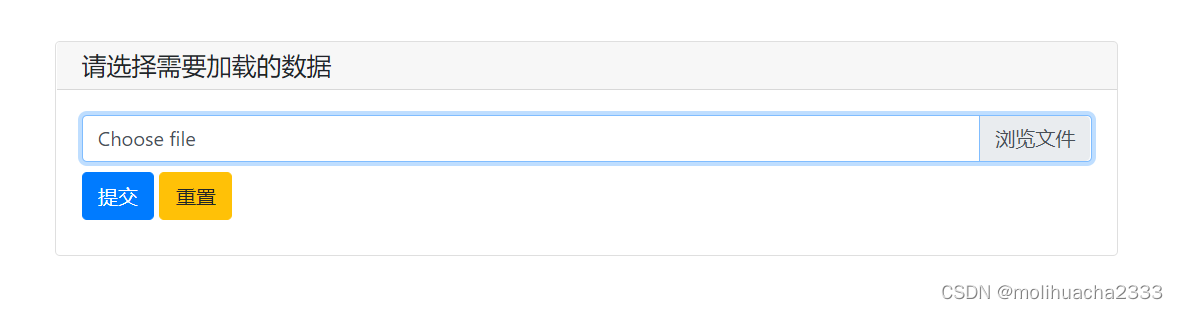
核心代码如下:
file = file_upload('请选择需要加载的数据')
df1 = pd.read_excel(file['content'])2.3.2 输出
输出过程也只用到了基础的部分,本来想做成横向排版,但排版总不合适,最终选择的是竖向排列。输出的结果是一个图和一个表,其中表格是DataFrame格式转换成Html格式后输出的。
效果如下:
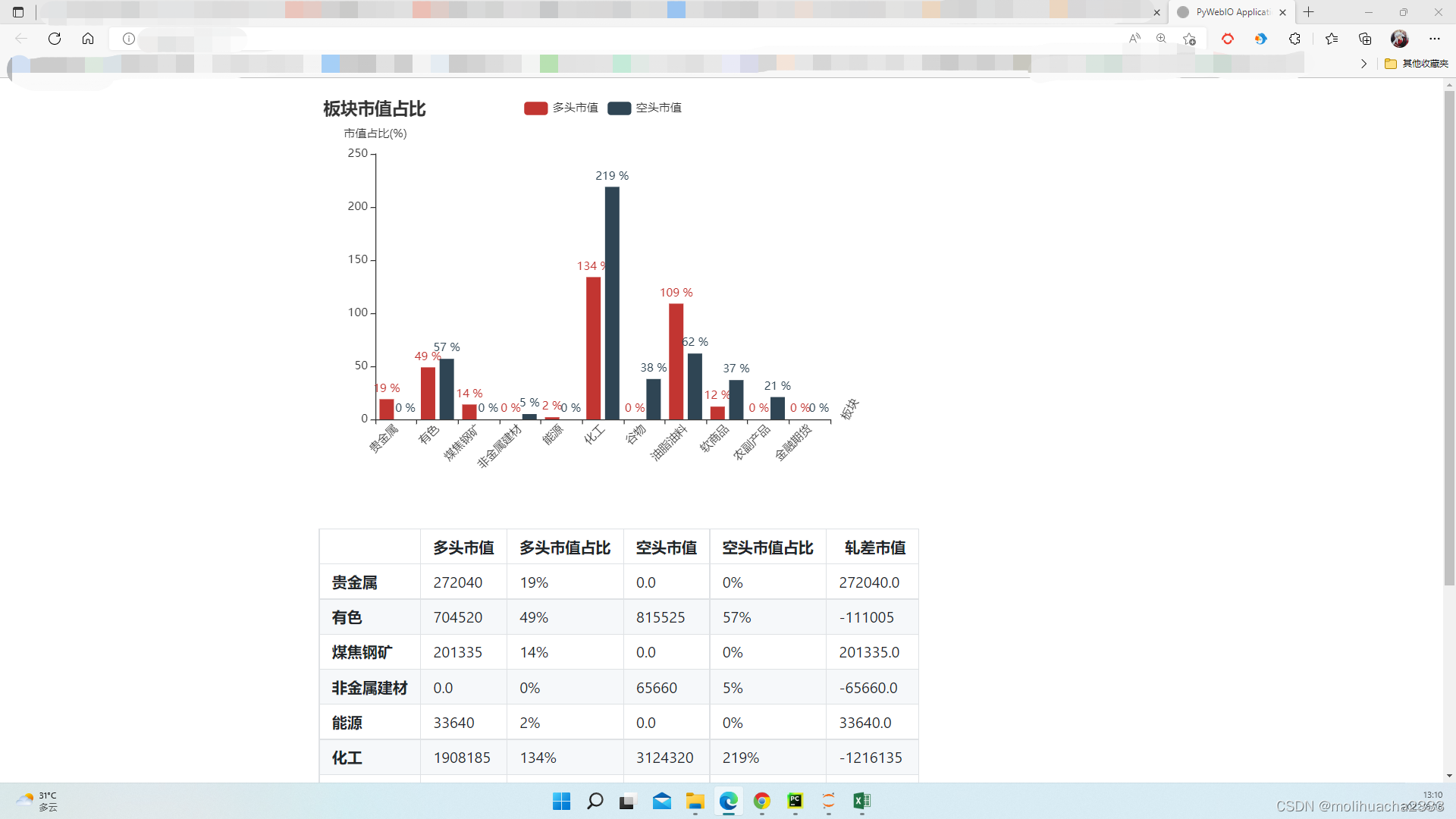
可以看到左右留白还是很多的,如果是横向排版会更合适,就先留着日后深化吧。
核心代码如下:
put_column([
put_html(bar.render_notebook()),
put_html(result.to_html(border=0))可以看到不管是输入还是输出,Pywebio的代码实现都相当简洁,这里要给开发者点个大大的赞!
2.4 打包
打包真的很麻烦,尤其是对Pywebio和Pyecharts的打包试了很多次都不行。这方面笔者还不太懂,这里只是将自己的排错过程放到这里仅供参考。
2.4.1 首先在工作目录下使用如下命令生成spec文件:
pyi-makespec -c -F main.py其中“main.py”应该改成实际要打包的脚本名字。
2.4.2 然后在相应目录中找到spec文件并打开,进行以下编辑:
from pywebio import STATIC_PATH
a = Analysis(
...
datas=[(STATIC_PATH, 'pywebio/html'), (STATIC_PATH+'/../platform/tpl', 'pywebio/platform/tpl')],
...
)2.4.3 接着使用以下命令打包:
pyinstaller main.spec打包完成后会在dist文件夹里找到.exe可执行文件,然后并没有完事大吉,运行此文件会发现报错,报错原因是“No Such File...”之类的,找不到的文件是Pywebio和Pyecharts里的东西,我也不管到底是什么了,就直接把这两个库copy到缺失的地方,然后再运行,就终于完事大吉啦!
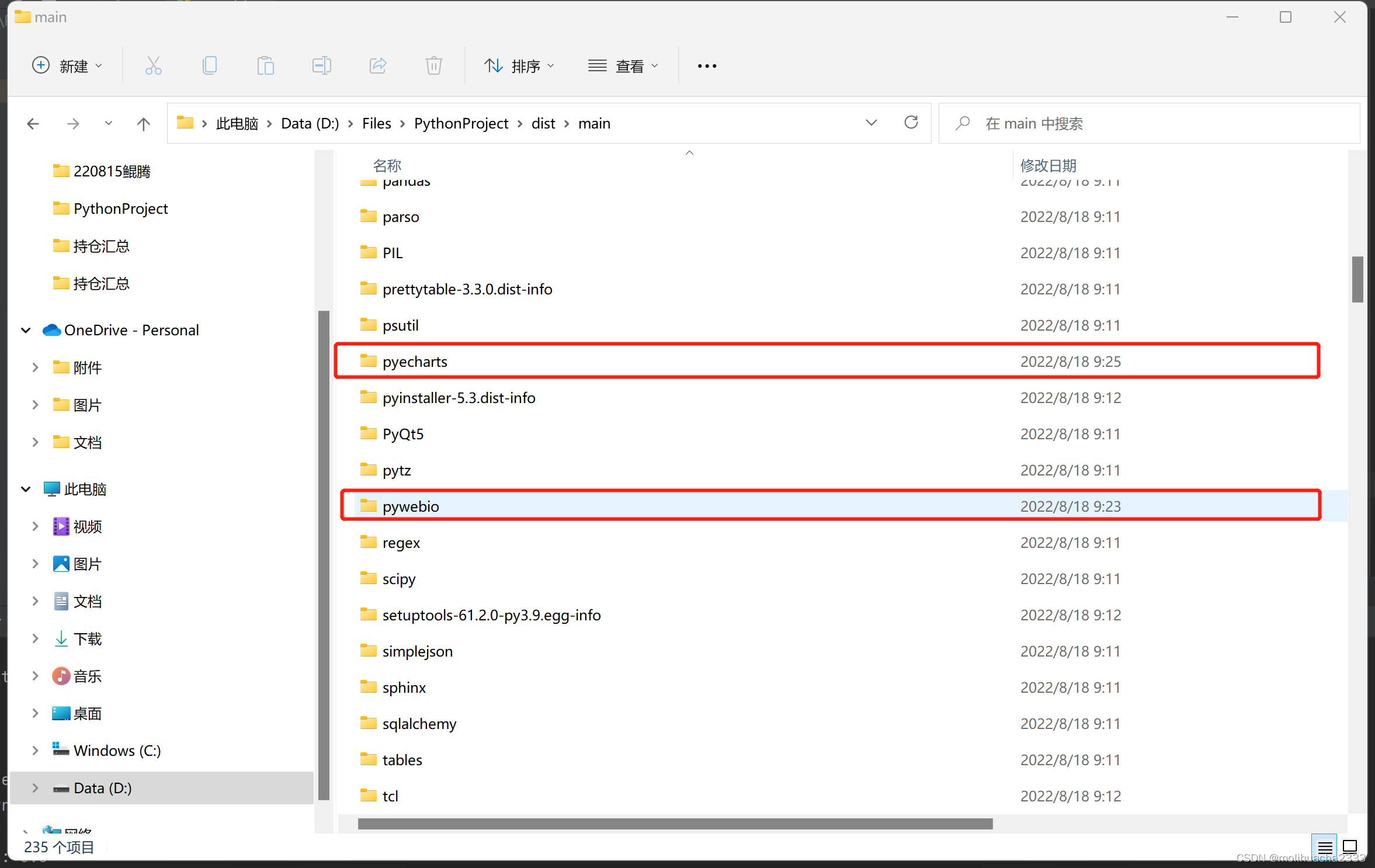
手动Copy补充的文件夹如上所示~
至此才终于走到Final...
3 结语
从写好这个小脚本到打包成可执行文件花了三天左右的时间,其中几乎一半都花在打包上,真可谓血泪满满,菜又爱玩。
目前的项目还很不成熟,下一步的完善方向是:
- 对脚本功能进行扩展。目前可以做的任务只是简单的分板块统计市值,以后还可以有更多方向,对有需求的画图任务还可以增加,具体的有灵感再说~
- 对代码和函数进行整理,争取写的更精炼~
- 试试看能不能减小打包后的体积~
- 尝试线上发布,这样大家就都可以使用我的小脚本啦,但笔者不懂网络这些,尚且不知道难度如何,总之先挖个坑吧~
最后希望疫情早点过去,世界和平~
Reference
【1】字母和数字分列:https://www.coder.work/article/2020734
【3】带百分比的柱状图,数据规整:https://blog.csdn.net/seakingx/article/details/105135110















 6888
6888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









