







1 二分类SVC的进阶
1.1 SVC用于二分类的原理复习
1.2 参数C的理解进阶
有一些数据,可能是线性可分的,但在线性可分状况下训练准确率不能达到100%,即无法让训练误差为0。这种数据被称为“存在软间隔的数据”。这时需要决策边界能够忍受一小部分训练误差,而不能单纯地寻求最大边际。
因为对于软间隔的数据来说,边际越大被分错的样本也就会越多,因此需要找出一个“最大边际”与“被分错的样本数量”之间的平衡。因此,引入松弛系数 ζ \zeta ζ和松弛系数的系数 C C C作为一个惩罚项,来惩罚对最大边际的追求。
**参数 C C C如何影响决策边界?**在硬间隔时,决策边界完全由两个支持向量和最小化损失函数(最大化边际)来决定,而支持向量是两个标签类别不一致的点,即分别是正样本和负样本。然而在软间隔时,边际依然由支持向量决定,但此时支持向量可能就不再是来自两种标签类别的点了,而是分布在决策边界两边的同类别的点。

此时虚线超平面 w ⋅ x i + b = 1 − ζ i \textbf{w}\cdot\textbf{x}_i+b=1-\zeta_i w⋅xi+b=1−ζi是由混杂在红色点中间的紫色点所决定的,因此这个紫色点就是现在的支持向量。所以软间隔让决定两条虚线超平面的支持向量可能是来自于同一个类别的样本点,而硬间隔时两条虚线超平面必须是由来自两个不同类别的支持向量所决定的。而C值会决定究竟是依赖红色点作为支持向量(只追求最大边界),还是要依赖软间隔中混杂在红色点中的紫色点来作为支持向量(追求最大边界和判断正确的平衡)。如果C值设定比较大,那么SVC可能会选择边际较小的,能够更好地分类所有训练样本点的决策边界,不过模型的训练时间也会更长。如果C的设定值较小,那么SVC会尽量最大化边际,尽量将掉落在决策边界一方的样本点预测正确,决策功能会更简单,但代价是训练的准确度,因为此时会有更多红色点被分类错误。换句话说,C在SVM中的影响就像正则化参数对逻辑回归的影响。
所有可能影响超平面的样本都可能会被定义为支持向量,所以支持向量就不再是所有压在虚线超平面上的点,而是所有可能影响超平面位置的那些混杂在彼此类别中的点。
1.3 二分类SVC中的样本不均衡问题:重要参数class_weight
样本不均衡会带来很多问题。**首先,分类模型天生会倾向于多数的类,让多数类更容易被判断正确,少数类被牺牲掉。**因为对于模型而言,样本量越大的标签可以学到的信息越多,算法就会更加依赖于从多数类中学到的信息来进行判断。如果希望捕获少数类,模型就会失效。其次,模型评估指标会失去意义。这种分类状况下,即便模型什么也不做,把全部样本都分到多数类中,准确率也能非常高,这使得模型评估指标accuracy变得毫无意义,根本无法达到识别少数类的建模目的。
所以,首先要让算法意识到数据的标签是不均衡的,通过施加一些惩罚或者改变样本本身,来让模型向着捕获少数类的方向建模。然后改进模型评估指标,使用更加针对于少数类的指标来优化模型。
要解决第一个问题,可以使用上采样、下采样。但这些采样方法会增加样本的总数,对于支持向量机这个样本总是对计算速度影响巨大的算法而言,不能轻易增加样本数量。况且,支持向量机中的决策仅仅受到决策边界的影响,而决策边界又仅仅受到参数C和支持向量的影响,单纯地增加样本数量不仅会增加计算时间,可能还会增加无数对决策边界无影响的样本点。因此在支持向量机中,要大力依赖调节样本均衡的参数:SVC类中的class_weight和接口fit中可以设定的sample_weight。
在逻辑回归中,参数class_weight默认为None,此模式表示假设数据集中的所有标签是均衡的,即自动认为标签的比例是1:1。所以当样本不均衡的时候,可以使用形如{“标签的值1”:权重1,“标签的值2”:权重2}的字典来输入真实的样本标签比例,来让算法意识到样本是不均衡的。或者使用“balanced”模式,直接使用n_samples/(n_classes*np.bincount(y))作为权重,可以比较好的修正样本不均衡的情况。
但在SVM中,分类判断是基于决策边界的,而最终决定究竟使用怎样的支持向量和决策边界的参数是参数C,所以所有的样本均衡都是通过参数C来调整的。
- SVC的参数:class_weight
可输入字典或者“balanced”,可不填,默认为None。对SVC,将类 i i i的参数C设置为class_weight[i] ∗ * ∗C,如果没有给出具体的class-weight,则所有类都被假设为占有相同的权重1,模型会根据数据原本的状况去训练。如果希望改善样本不均衡状况,需要输入形如{“标签的值1”:权重1,“标签的值2”:权重2}的字典,则参数C将会自动被设为:(标签的值1的C:权重1C,标签的值2的C:权重2C)。
或者,可以使用“balanced”模式,这个模式使用y的值自动调整与输入数据中的类频率成反比的权重为n_samples/(n_classes*np.bincount(y))。 - SVC的接口fit的参数:sample_weight
数组,结构为(n_samples,),必须对应输入fit中的特征矩阵的每个样本。每个样本在fit时的权重,让权重 ∗ * ∗每个样本对应的C值来迫使分类器强调设定的权重更大的样本。通常,较大的权重加在少数类的样本上,以迫使模型向着少数类的方向建模。
通常来说,class_weight和sample_weight,这两个参数只选取一个来设置。如果同时设置了两个参数,则C会同时受到两个参数的影响,即class_weight中设定的权重 ∗ * ∗sample_weight中设定的权重 ∗ * ∗C。
接下来看看如何使用class_weight参数。首先自建一组样本不平衡的数据集,在这组数据集上建两个SVC模型,一个设置有class_weight参数,一个不设置class_weight参数。对这两个模型分别进行评估并画出决策边界,以此观察参数class_weight带来的效果。
#导入需要的库和模块
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs
#创建样本不均衡的数据集
class_1 = 500#类别1有500个样本
class_2 = 50#类别2只有50个
centers = [[0.0,0.0],[2.0,2.0]]#设定两个类别的中心
clusters_std = [1.5,0.5]#设定两个类别的方差,通常来说,样本量比较大的类别会更加松散
x,y = make_blobs(n_samples = [class_1,class_2]
,centers = centers
,cluster_std = clusters_std
,random_state = 0
,shuffle = False)
#看看数据集长什么样
plt.scatter(x[:,0],x[:,1],c = y,s=10,cmap = "rainbow")
#其中红色点事少数类,紫色点是多数类

#在数据集上分别建模
#不设定class_weight
clf = svm.SVC(kernel = "linear",C=1.0)
clf.fit(x,y)
#结果:SVC(kernel='linear')
#设定class_weight
wclf = svm.SVC(kernel = "linear",class_weight = {
1:10})
wclf.fit(x,y)
#结果:SVC(class_weight={1: 10}, kernel='linear')
#给两个模型分别打分看看,分数是accuracy准确度
clf.score(x,y)
#结果:0.9418181818181818
wclf.score(x,y)
#结果:0.9127272727272727
#绘制两个模型下数据的决策边界
#首先要有数据分布
plt.figure(figsize = [6,5])
plt.scatter(x[:,0],x[:,1],c = y,cmap = "rainbow",s=10)
ax = plt.gca()#获取当前的子图,如果不存在,则创建新的子图
#绘制决策边界的第一步:要有网格
xlim = ax.get_xlim()
ylim = ax.get_ylim()
xx = np.linspace(xlim[0],xlim[1],30)
yy = np.linspace(ylim[0],ylim[1],30)
yy,xx = np.meshgrid(yy,xx)
xy = np.vstack([xx.ravel(),yy.ravel()]).T
#第二步:找出样本点到决策边界的距离
z_clf = clf.decision_function(xy).reshape(xx.shape)
a = ax.contour(xx,yy,z_clf,colors = "black",levels = [0],alpha = 0.5,linestyles=["-"])
z_wclf = wclf.decision_function(xy).reshape(xx.shape)
b = ax.contour(xx,yy,z_wclf,colors = "red",levels = [0],alpha = 0.5,linestyles = ["-"])
#第三部:画图例
plt.legend([a.collections[0],b.collections[0]],["non weighted","weighted"],loc = "upper right")
plt.show()
#图例中的详细说明
a.collections#调用这个等高线对象中的画的
#结果:<a list of 1 mcoll.LineCollection objects>
#用{*}把它打开看看
[*a.collections]#返回了一个linecollection对象,其实就是等高线里所有的线的列表
#结果:[<matplotlib.collections.LineCollection at 0x2735e6dd550>]
#现在只有一条线,所以可以使用索引0来锁定这个对象
a.collections[0]
#结果:<matplotlib.collections.LineCollection at 0x2735e6dd550>
#plt.legend([对象列表],[图例列表],loc)
#只要对象列表和图例列表相对应,就可以显示出图例

从图像上可以看出,灰色是做样本平衡之前的决策边界,灰色线上方的点被分为一类,下方的点被分为另一类。可以看到,大约有一半少数类(红色)被分错,多数类(紫色点)几乎都被分类正确了。红色是做样本平衡之后的决策边界,同样红色线上方一类,红色线下方一类,可以看到,做了样本平衡后,少数类几乎全部都被分类正确了,但是多数类有许多被分错了。
但从准确率的角度来看,不做样本平衡时准确率反而更高,做了样本平衡准确率反而变低了,这是因为做了样本平衡后,为了要更有效的捕捉少数类,模型误伤了许多多数类样本,而多数类被分错的样本数量大于少数类被分类正确的样本数量,使得模型整体的准确率下降。如果目的是模型整体的准确率,那就要拒绝样本平衡,使用class_weight被设置之前的模型。
然而在现实中,往往都是在追求捕捉少数类,因为在很多情况下,将少数类判断错的代价是巨大的。希望不惜一切代价来捕获少数类,或者希望捕捉出尽量多的少数类,那就必须使用class_weight设置后的模型。
2 SVC的模型评价指标
如果目标是尽量捕获少数类,那么准确率这个模型评估指标就逐渐失效了,需要新的模型评估指标。简单来看,只需要查看模型在少数类上的准确率就好,只要能够将少数类尽量捕捉出来,就能够达到目的。但问题是对多数类判断错误后,会需要人工甄别或者更多的业务上的措施来一一排除判断错误的多数类,这种行为往往伴随着很高的成本。
也就是说,单纯地追求捕捉出少数类,就会成本太高,而不顾及少数类,又会无法达成模型的效果。所以在现实中,往往在寻找捕获少数类的能力和将多数类判错后需要付出的成本的平衡。如果一个模型在能够尽量捕获少数类的情况下,还能够尽量对多数类判断正确,则这个模型就非常优秀了。为了评估这样的能力,将引入新的模型评估指标:混淆矩阵和ROC曲线。
2.1 混淆矩阵(Confusion Matrix)
混淆矩阵是二分类问题的多维衡量指标体系,在样本不平衡时极其有用。在混淆矩阵中,将少数类认为是正例,多数类认为是负例。在决策树、随机森林这些普通的分类算法里,即是说少数类是1,多数类是0。在SVM中,就是认为少数类是1,多数类是-1。普通的混淆矩阵,一般使用{0,1}来表示。
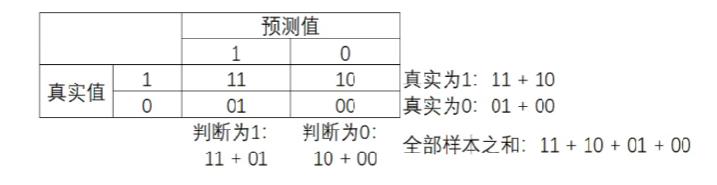
混淆矩阵中,永远是真实值在前,预测值在后。很容易看出,11和00的对角线就是全部预测正确的,01和10的对角线就是全部预测错误的。基于混淆矩阵,有六个不同的模型评估指标,这些评估指标的范围都在[0,1]之间,所有以11和00为分子的指标都是越接近1越好,所有以01和10为分析的指标都是越接近0越好。对于所有的指标,用橙色表示分母,用绿色表示分子。
2.1.1 模型整体效果:准确率(Accuracy)
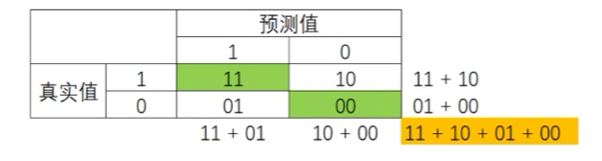
A c c u r a c y = 11 + 00 11 + 10 + 01 + 00 Accuracy = \frac{11+00}{11+10+01+00} Accuracy=11+10+01+0011+00
准确率Accuracy就是所有预测正确的所有样本除以总样本,通常来说越接近1越好。
2.1.2 捕捉少数类的艺术:精确度(Precision)、召回率(Recall)和F1 score
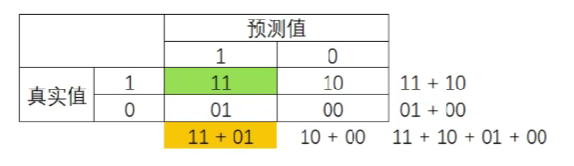
P r e c i s i o n = 11 11 + 01 Precision = \frac{11}{11+01} Precision=11+0111
精确度Precision,又叫查准率,表示所有被预测为少数类的样本中,真正的少数类所占的比例。在支持向量机中,精确度又可以被形象地表示为决策边界上方的所有点中,红色点所占的比例。精确度越高,代表捕捉正确的红色点越多,对少数类的预测越精确。精确度越低,则代表误伤了过多的多数类。精确度是“将多数类判错后所需付出成本”的衡量。
#所有判断正确并确实为1的样本/所有被判断为1的样本
#对于没有class_weight,没有做样本平衡的灰色决策边界来说
(y[y == clf.predict(x)] == 1).sum()/(clf.predict(x) == 1).sum()
#结果:0.7142857142857143
#对于有class_weight,做了样本平衡的红色决策边界来说
(y[y == wclf.predict(x)] == 1).sum()/(wclf.predict(x) == 1).sum()
#结果:0.5102040816326531
可以看到,做了样本平衡之后,精确度是下降的。因为很明显,样本平衡之后,有更多的多数类紫色点被误判了。精确度可以帮助我们判断,是否每一次对少数类的预测都精确,所以又被称为“查准率”。在现实的样本不平衡问题中,当每一次将多数类判断错误的成本非常高昂的时候,会追求高精确度。精确度越低,对多数类的判断就会越错误。当然,如果目标是不计一切代价捕获少数类,那并不需要在意精确度。
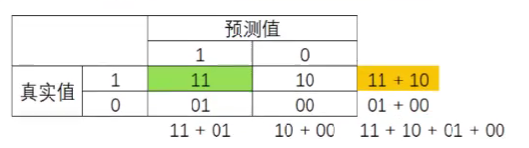
R e c a l l = 11 11 + 10 Recall = \frac{11}{11+10} Recall=11+1011
召回率Recall,又被称为敏感度(sensitivity)、真正率、查全率,表示所有真实为少数类的样本中,被预测正确的样本所占的比例。在支持向量机中,召回率可以被表示为,决策边界上方的所有红色点占全部样本中的红色点的比例。召回率越高,代表尽量捕捉出越多的少数类,召回率越低,代表没有捕捉出足够的少数类。
#所有predict为1且确实为1的点/全部确实为1的点的比例
#对于没有class_weight,没有做样本平衡的灰色决策边界来说
(y[y == clf.predict(x)]==1).sum()/(y == 1).sum()
#结果:0.6
#对于有class_weight,做了样本平衡的红色决策边界来说
(y[y == wclf.predict(x)]==1).sum()/(y == 1).sum()
#结果:1.0
可以看出,做样本平衡之前,只成功捕捉了60%左右的少数类点,而做了样本平衡之后的模型捕捉出了100%的少数类点。从图像上来看,红色决策边界的确捕捉出了全部的少数类,而灰色决策边界只捕捉到了一半左右。召回率可以帮助判断,是否捕捉出了全部的少数类,所以又叫做查全率。如果希望不计一切代价,找出少数类,那么就会追求高召回率,相反如果目标不是尽量捕获少数类,则不需要在意召回率。
注意召回率和精确度的分子是相同的,只是分母不同,而召回率和精确度是此消彼长的,两者之间的平衡代表了捕获少数类的需求和尽量不要误判多数类的需求的平衡。究竟要偏向于哪一方,取决于业务需求:究竟是误伤多数类的成本更高,还是没有捕获少数类的代价更高。
为了同时兼顾精确度和召回率,创造了两者的调和平均数作为考量两者平衡的综合性指标,称之为F1 score。两个数之间的调和平均倾向于靠近两个数中比较小的那一个数。因此追求尽量高的F1 score,能够保证精确度和召回率都比较高。F1 score在[0,1]之间分布,越接近1越好。
F 1 s c o r e = 2 1 P r e c i s i o n + 1 R e c a l l = 2 ∗ P r e c i s i o n ∗ R e c a l l P r e c i s i o n + R e c a l l F1\ score=\frac{2}{\frac{1}{Precision}+\frac{1}{Recall}}=\frac{2*Precision*Recall}{Precision+Recall} F1 score=Precision1+Recall12=Precision+Recall2∗Precision∗Recall
从Recall延出来的另一个评估指标称为假负率(False Negative Rate),它等于1-Recall,用于衡量所有真实为1的样本中,被误判为0的,通常用得不多。
F N R = 10 11 + 10 FNR = \frac{10}{11+10} FNR=11+1010
2.1.3 判错多数类的考量:特异度(Specificity)与假正lv
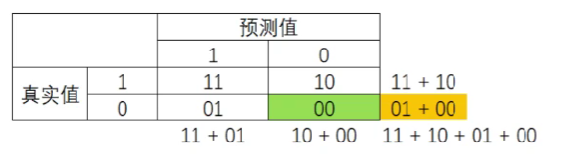
S p e c i f i c i t y = 00 01 + 00 Specificity=\frac{00}{01+00} Specificity=01+0000
**特异度(Specificity)**表示所有真实为多数类的样本中,被正确预测为多数类的样本所占的比例。在支持向量机中,可以形象地表示为,决策边界下方的点占所有紫色点的比例。
#所有确实为0且被正确预测为0的样本/所有确实为0的样本
##对于没有class_weight,没有做样本平衡的灰色决策边界来说
(y[y == clf.predict(x)] == 0).sum()/(y == 0).sum()
#结果:0.976
#对于有class_weight,做了样本平衡的红色决策边界来说
(y[y == wclf.predict(x)] == 0).sum()/(y == 0 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









