









从零编写linux0.11 - 第九章 文件系统(一)
编程环境:Ubuntu 20.04、gcc-9.4.0
代码仓库:https://gitee.com/AprilSloan/linux0.11-project
linux0.11源码下载(不能直接编译,需进行修改)
本章目标
完成文件系统的部分功能。能够读取文件,打印输出。
1.qemu
接下来的章节将使用 qemu 模拟器运行程序。为什么使用 qemu 而不使用 bochs 呢?
1.bochs 无法看 C 语言源码。只看汇编代码调试 C 语言程序还是挺麻烦的。使用 gdb-dashboard 插件后,可以同时查看 C 语言源码、编译后的汇编代码和寄存器,十分不错,就是看内存有点麻烦。
2.bochs 运行程序出错。bochs 读取软盘扇区时会发生奇怪的错误,让我百思不得其解,同样的代码在 qemu 上却能运行。
综上,最终决定使用 qemu。不过 qemu 也有些问题,它没法调试 main 函数之前的汇编代码。
首先,我们需要安装 qemu。运行下面的指令。
sudo apt-get install gcc-multilib qemu-system-x86
接下来要修改 Makefile。
CC =gcc
CFLAGS =-Wall -g -O -m32 -fomit-frame-pointer -fno-stack-protector -no-pie -fno-pic -Iinclude
all: run
Image: clean mkimg boot/bootsect.bin boot/setup.bin system
objcopy -O binary -R .note -R .comment system kernel.bin
dd if=boot/bootsect.bin of=kernel.img bs=512 count=1 conv=notrunc
dd if=boot/setup.bin of=kernel.img bs=512 count=4 seek=1 conv=notrunc
dd if=kernel.bin of=kernel.img bs=512 count=384 seek=5 conv=notrunc
rm kernel.bin -f
run: Image
qemu-system-i386 -m 32 -k en-us -rtc base=localtime -device cirrus-vga -fda kernel.img -fdb rootimage -boot a
debug: Image
qemu-system-i386 -m 32 -k en-us -rtc base=localtime -device cirrus-vga -fda kernel.img -fdb rootimage -boot a -s -S
gdb:
gdb -n -x .gdbinit
根目录 Makefile 的 CFLAGS 才有-O选项,其他目录中的 Makefile 都删掉-O,尽量不优化代码。-g是生成调试信息,不然用 gdb 调试时无法看到 C 语言源码。-no-pie -fno-pic能够方便我们在 gdb 中查看局部变量。
qemu-system-i386 的-m 32指定内存大小为 32M,-k en-us选择英文键盘映射方式,-rtc base=localtime设置虚拟 RTC 匹配本地时间,-device cirrus-vga定义 VGA 视频卡,-fda kernel.img指定操作系统在0号软盘,-fdb指定文件系统在1号软盘,-boot a设置软盘启动,-s指定 gdb 调试端口为1234,-S让 CPU 在开始时就暂停,等待调试。
.gdbinit 中有 gdb 的设置和 gdb-dashboard 插件,我自己做了一些小小的修改。
如何运行和调试操作系统?
在目录中打开终端,执行make即可运行操作系统。运行结果如下:

在目录中打开两个终端,一个执行make debug,另一个执行make gdb即可调试操作系统。运行结果如下:
在右侧的终端输入c并回车,就会运行到 main 函数。

在 System.map 中找到 init 的地址是 0x6532,输入并执行b *0x4006532和c就可以运行到 init 函数。请注意,如果想在某个地址打断点,要在地址前加*。为什么我们查到的地址是 0x6532,而打断点的地址是 0x4006532呢?init 函数运行在第二个进程中,第二个进程的地址空间的首地址是 0x4000000。
介绍一些 qemu 的操作。鼠标点到 qemu 黑色窗口区域,鼠标会消失,按下 Ctrl+Alt 会重新显示鼠标。Ctrl+Alt+2 会切换到 qemu 的操作台,输入并执行q会退出 qemu(当然也可以通过点击右上的 x 关闭 qemu)。Ctrl+Alt+1 又会回到操作系统运行窗口。
接下来是 gdb 的一些简单命令。
- b + 行号/函数名/*地址:打断点
- s:单步执行一条 C 语句
- n:单步跳过一条 C 语句
- si:单步执行一条汇编语句
- ni:单步跳过一条汇编语句
- l:查看 C 语言源码
- c:继续执行
- info b:查看断点编号
- d + 断点编号:删除断点
- print + 变量:查看变量值
- x/5x + 地址:查看从该地址开始的5个数据
- x/5i + 地址:查看从该地址开始的5条指令
- q:退出调试
2.文件系统结构介绍
这一节来讲讲文件系统的结构。现在存在着许多的操作系统,你可以用下面这条指令看看linux中支持的操作系统。
cat /proc/filesystems
不同的文件系统的结构不同。接下里就介绍我们要使用的文件系统。
linux0.11 的文件系统用的是 minix1.0 的文件系统(minix 也是一个操作系统)。它的结构如图所示:
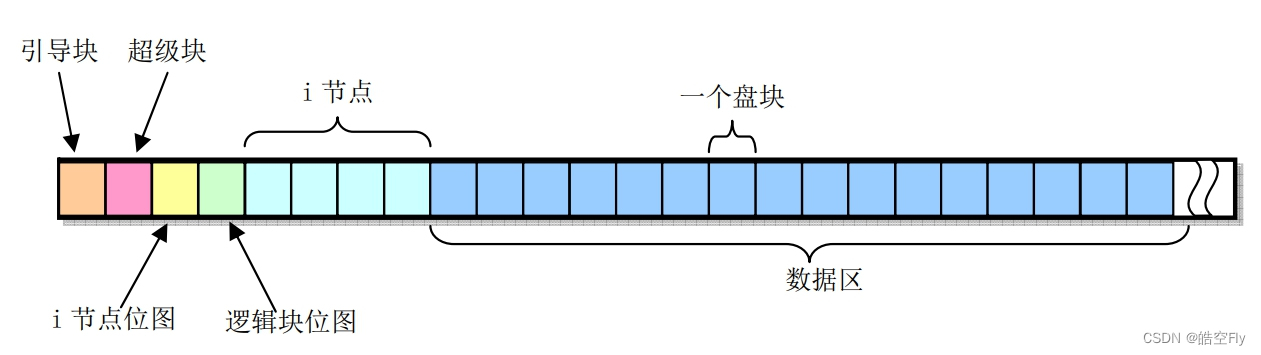
可以看到 minix1.0 文件系统一共分为6部分,分别是引导块、超级块、inode 位图、逻辑块位图、inode、数据区。每个逻辑块大小为 1KB。
引导块存放操作系统的 bootloader,大小为 1KB。
超级块存放盘设备上文件系统的结构信息,占用 1KB 空间,其内容如下所示。虽然占用 1KB 空间,但是其实只有18个字节有用。
// fs.h
struct d_super_block {
unsigned short s_ninodes; // inode数
unsigned short s_nzones; // 逻辑块数
unsigned short s_imap_blocks; // inode位图所占块数
unsigned short s_zmap_blocks; // 逻辑块位图所占块数
unsigned short s_firstdatazone; // 数据区第一个逻辑块的块号
unsigned short s_log_zone_size; // log2(数据块数/逻辑块)
unsigned long s_max_size; // 最大文件长度
unsigned short s_magic; // 文件系统魔数
};
一个 inode 与一个文件或目录相对应,记录文件或目录的信息。文件能否被读、写或执行?文件属于谁?文件有多大?文件最近什么时候被修改过?文件的数据在哪个逻辑块上?
// fs.h
struct d_inode {
unsigned short i_mode; // 文件的类型和属性(rwx)
unsigned short i_uid; // 文件所有者的用户id
unsigned long i_size; // 文件长度(字节)
unsigned long i_time; // 修改时间(从1970.1.1:0时算起,单位:秒)
unsigned char i_gid; // 文件所有者的组id
unsigned char i_nlinks; // 链接数
unsigned short i_zone[9]; // 文件占用的逻辑块的块号
// zone[0]-zone[6]是直接块号
// zone[7]是一级间接块号
// zone[8]是二级间接块号
};
inode 位图表示 inode 的使用情况。以创建文件为例,我们需要知道哪些 inode 没有被使用,将没有被使用的 inode 与新文件关联起来。位图可以很好的节省空间。
一个字节有八个位,用一个位来表示一个 inode 的使用情况,这就是位图的使用方法。逻辑块位图中也是用一个位表示一个逻辑块的使用情况。
数据区用来存放文件的数据。
可以使用 bless 或 ghex 等工具打开 rootimage,查看里面的数据,如下所示。超级块从 0x400 开始。
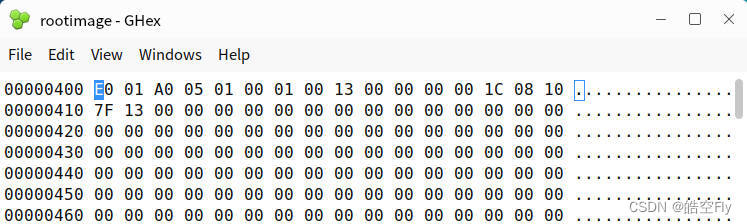
为了提高效率,一般会把文件数据读到内存中,当不需要这些数据时,再将内存中的数据写到软盘上。我们也不会一口气将文件所有数据都读入内存,这方面的算法和缺页中断类似,需要哪个逻辑块的数据,就读取哪个逻辑块的数据。我们将文件数据保存到 buffer_head 的 b_data 成员中,b_blocknr 表示是从哪个逻辑块读取的数据。
// fs.h
// 缓冲头结构体,用于保存从逻辑块读取的数据
struct buffer_head {
char *b_data; // 指向数据块(1KB)的指针
unsigned long b_blocknr; // 逻辑块号
unsigned short b_dev; // 设备号,0-空闲
unsigned char b_uptodate; // 是否更新
unsigned char b_dirt; // 脏位,0-未修改,1-修改过
unsigned char b_count; // 使用此结构的用户数
unsigned char b_lock; // 0 - 未上锁,1 - 上锁
struct task_struct *b_wait; // 指向该缓冲区解锁的任务
struct buffer_head *b_prev; // hash队列的上一块
struct buffer_head *b_next; // hash队列的下一块
struct buffer_head *b_prev_free; // 空闲表上一块
struct buffer_head *b_next_free; // 空闲表下一块
};
缓冲头结构体我们在第四章就已经讲过了,不过这里要添加一个成员 b_wait,需要在 buffer_init 中进行初始化。
之后我们主要围绕这三种结构体及其变体来写文件系统,这一节只是简单的介绍,详细的内容之后慢慢说明。
这节最后,留给大家几个问题。
1.该文件系统的数据区有多少个逻辑块?
2.该文件系统中能存放一个 512MB 大小的文件吗?为什么?
3.你能通过 d_inode 的 i_zone 成员计算出文件最大长度吗?
4.(思考题)目录 a 中有一个文件 b,如何在文件系统中表示 a 和 b 的关系?
3.读取超级块
我们首先要改变设备号。0x21c 是 kernel.img 软盘的设备号,0x21d 是 rootimage 软盘的设备号 。
; bootsect.s
ROOT_DEV equ 0x21d
在第八章,我们使用 ll_rw_block 函数来读取扇区,但是需要自己设置缓冲头结构体的值,不太方便。于是,又添加了一个函数,把设备号和逻辑块号作为参数传入函数。
// buffer.c
struct buffer_head *bread(int dev, int block)
{
int i;
struct buffer_head *bh = free_list;
bh->b_dev = dev;
bh->b_blocknr = block;
ll_rw_block(READ, bh);
for (i = 0; i < 18; i++) {
printk("%x ", (unsigned char) bh->b_data[i]);
}
printk("\r\n");
wait_on_buffer(bh);
if (bh->b_uptodate)
return bh;
return NULL;
}
buffer_init 中将所有缓冲头结构体串成一个循环链表,free_list 指向其中一个成员。
ll_rw_block 会提交读请求,然后就是十分熟悉的流程了,执行驱动程序添加定时器,一定时间后,设置 DMA 通道,发送读命令和参数,DMA 读取数据结束后,触发中断,执行 rw_interrupt 函数,开始下一个请求或结束软盘操作。
这里会出现一个问题,我们不知道 DMA 什么时候才能读完数据。在 ll_rw_block 后打印 b_data 的数据就会发现,b_data 中没有软盘的数据。因为 DMA 还没有把数据读到 b_data 中。
应该要怎么解决这个问题呢?linux0.11采用的方法是,当进程发送请求后,将其睡眠。当读取结束后,在中断中唤醒睡眠的进程。
缓冲头结构体中的 b_lock 就是为此而定义的。一开始,b_lock 的值为0,在提交请求的过程中,将 b_lock 的值设置为1,ll_rw_block 函数结束后,如果 b_lock 的值为1任务进入休眠。当 DMA 读取数据结束后,在 rw_interrupt 函数中将 b_lock 的值设置为0,然后唤醒任务,之后任务就可以继续执行了。
具体代码如下所示。
// buffer.c
static inline void wait_on_buffer(struct buffer_head *bh)
{
cli();
while (bh->b_lock)
sleep_on(&bh->b_wait);
sti();
}
// ll_rw_block.c
static inline void lock_buffer(struct buffer_head *bh)
{
cli();
while (bh->b_lock)
sleep_on(&bh->b_wait);
bh->b_lock = 1;
sti();
}
// blk.h
static inline void unlock_buffer(struct buffer_head *bh)
{
if (!bh->b_lock)
printk(DEVICE_NAME ": free buffer being unlocked\n");
bh->b_lock = 0;
wake_up(&bh->b_wait);
}
static void make_request(int major, int rw, struct buffer_head *bh)
{
struct request *req;
if (rw != READ && rw != WRITE)
panic("Bad block dev command, must be R/W/RA/WA");
lock_buffer(bh);
...
}
static inline void end_request(int uptodate)
{
DEVICE_OFF(REQUEST->dev); // 设置驱动器电动机停止的时间
if (REQUEST->bh) {
REQUEST->bh->b_uptodate = uptodate;
unlock_buffer(REQUEST->bh);
}
if (!uptodate) {
printk(DEVICE_NAME " I/O error\n\r");
printk("dev %04x, block %d\n\r", REQUEST->dev, REQUEST->bh->b_blocknr);
}
wake_up(&wait_for_request); // 唤醒等待的任务
REQUEST->dev = -1;
REQUEST = REQUEST->next;
}
当我们要修改 buffer_head 的 b_data 的时候,都要在前面加上 lock_buffer,只能由当前进程修改 b_data 。当修改 b_data 完毕后,都要使用 unlock_buffer ,让所有进程都可以读写 b_data。这是同步互斥的思想。
读取扇区、修改 b_data 之前都会运行 make_request 函数,读取扇区结束、修改 b_data 之后都会运行 end_request 函数。所以,要在 make_request 中调用 lock_buffer,在 end_request 中调用 unlock_buffer。
bread 中调用 wait_on_buffer,等待数据同步完成(等待 DMA 将数据读取完毕)。
rw_interrupt 会调用 end_request 函数,将 b_lock 设置为0,唤醒 lock_buffer 函数休眠的任务。如果读取成功,还会将 b_uptodate 设置为1,表示缓冲头中已经有数据了。
end_request 函数之前并没有参数,添加了参数后需要在调用 end_request 的地方添加参数。读取出错的地方,它的参数为0。读取成功的地方,它的参数为1。此处就不列出代码了。
// fs.h
#define SUPER_MAGIC 0x137F
// super.c
struct d_super_block ds;
static struct d_super_block *read_super(int dev)
{
struct d_super_block *s = &ds;
struct buffer_head *bh;
bh = bread(dev, 1);
if (!bh)
return NULL;
__asm__("cld"::); // 不加这句,结构体赋值会出错
*s = *((struct d_super_block *) bh->b_data);
if (s->s_magic != SUPER_MAGIC)
return NULL;
return s;
}
这里定义了一个全局的 d_super_block 结构体变量,用来保存读取的超级块的信息。
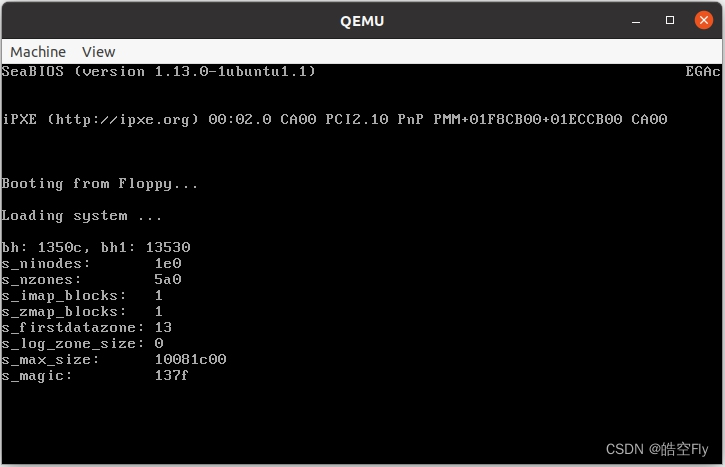
超级块的逻辑块号是1,我们用 bread 读取超级块的内容。读取成功后,使用结构体赋值方法为相应的结构体成员赋值。
minix1.0 文件系统魔数为 0x137f,我们也需要检查一下读错没有。
void mount_root(void)
{
struct d_super_block *p;
p = read_super(ROOT_DEV);
if (!p)
panic("Unable to read super block");
printk("s_ninodes: %x\r\n", p->s_ninodes);
printk("s_nzones: %x\r\n", p->s_nzones);
printk("s_imap_blocks: %x\r\n", p->s_imap_blocks);
printk("s_zmap_blocks: %x\r\n", p->s_zmap_blocks);
printk("s_firstdatazone: %x\r\n", p->s_firstdatazone);
printk("s_log_zone_size: %x\r\n", p->s_log_zone_size);
printk("s_max_size: %x\r\n", p->s_max_size);
printk("s_magic: %x\r\n", p->s_magic);
}
读取超级快数据后,把数值打印出来。
// hd.c
int sys_setup(void)
{
static int callable = 1;
if (!callable)
return -1;
callable = 0;
mount_root();
return (0);
}
最后重新写一些 sys_setup。setup 用于初始化文件系统,并且只能运行一次。这里设置了静态变量来保证只会运行一次。
运行结果如下:
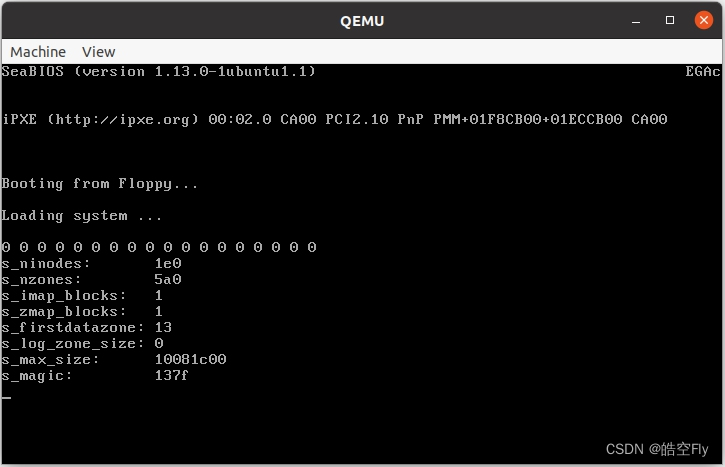
屏幕中的一排0是运行 ll_rw_block 之后从 b_data 读取的内容,此时超级块的数据还没有被读到 b_data 中。之后的输出是在运行 wait_on_buffer 之后从 b_data 读取的内容,此时数据已经从软盘读取到内存。
打印的数值与 rootimage 中的数值是一样的。我们读取超级块成功了。
那么这个程序有什么缺陷吗?我们可以用 bread 读取一个逻辑块,但是,如果想读取第二个逻辑块,我们会使用同一个缓冲头结构体,导致会覆盖掉之前读取的数据。这可不行,得好好处理一下。
4.修改文件数据缓冲
对于上一节的问题,需要一个什么样的功能来解决它呢?我们想获得一个空闲的缓冲头结构体。从哪里获得呢?从 free_list 指向的双向循环链表中获得,这个链表共有307个可使用的缓冲头结构体。一旦一个缓冲头结构体被分配出去,就将它移动到链表的末尾。
// buffer.c
static struct task_struct *buffer_wait = NULL;
struct buffer_head *getblk(int dev, int block)
{
struct buffer_head *bh;
repeat:
bh = get_hash_table(dev, block);
if (bh) // 如果已经读取过这个逻辑块的数据
return bh;
for (bh = free_list->b_next_free; bh != free_list; bh = bh->b_next_free) {
if (bh->b_count)
continue;
break;
}
if (!bh) { // 如果没有可用的缓冲头结构体
sleep_on(&buffer_wait);
goto repeat;
}
bh->b_count = 1; // 读取一个逻辑块
bh->b_dirt = 0; // 数据还未被修改
bh->b_uptodate = 0; // 还未加载数据
remove_from_queues(bh); // 从链表中移出
bh->b_dev = dev;
bh->b_blocknr = block;
insert_into_queues(bh); // 插入到链表末尾
return bh;
}
这个函数用于获得一个未被使用的缓冲头结构体,以设备号和逻辑块号为参数。我们遍历 free_list 指向的链表,寻找一个可用的缓冲头结构体,找到后,设置缓冲头结构体的成员,并将缓冲头结构体移动到链表的末尾。如果没找到可用的缓冲头结构体,就休眠当前任务,被唤醒后再次查找有无可用的缓冲头结构体。
// buffer.c
#define _hashfn(dev, block) (((unsigned)(dev ^ block)) % NR_HASH)
#define hash(dev, block) hash_table[_hashfn(dev, block)]
static inline void remove_from_queues(struct buffer_head *bh)
{
// 将bh移出哈希链表
if (bh->b_next)
bh->b_next->b_prev = bh->b_prev;
if (bh->b_prev)
bh->b_prev->b_next = bh->b_next;
if (hash(bh->b_dev, bh->b_blocknr) == bh)
hash(bh->b_dev, bh->b_blocknr) = bh->b_next;
if (!(bh->b_prev_free) || !(bh->b_next_free))
panic("Free block list corrupted");
// 将bh移出free_list循环链表
bh->b_prev_free->b_next_free = bh->b_next_free;
bh->b_next_free->b_prev_free = bh->b_prev_free;
if (free_list == bh)
free_list = bh->b_next_free;
}
static inline void insert_into_queues(struct buffer_head *bh)
{
// 将bh加入到free_list循环链表的末尾(free_list为头节点)
bh->b_next_free = free_list;
bh->b_prev_free = free_list->b_prev_free;
free_list->b_prev_free->b_next_free = bh;
free_list->b_prev_free = bh;
bh->b_prev = NULL;
bh->b_next = NULL;
// 在执行该函数前会设置b_dev的值,如果为0,说明这个设备不可用
if (!bh->b_dev)
return;
// 将bh加入到哈希链表
bh->b_next = hash(bh->b_dev, bh->b_blocknr);
hash(bh->b_dev, bh->b_blocknr) = bh;
if (bh->b_next)
bh->b_next->b_prev = bh;
}
hash_table 是一个哈希链表,用于更快速地找到已使用缓冲头结构体。我们只需要设备号和逻辑块号就能知道这个逻辑块是否已经加载到内存中。
为了方便理解,下面举一个例子。
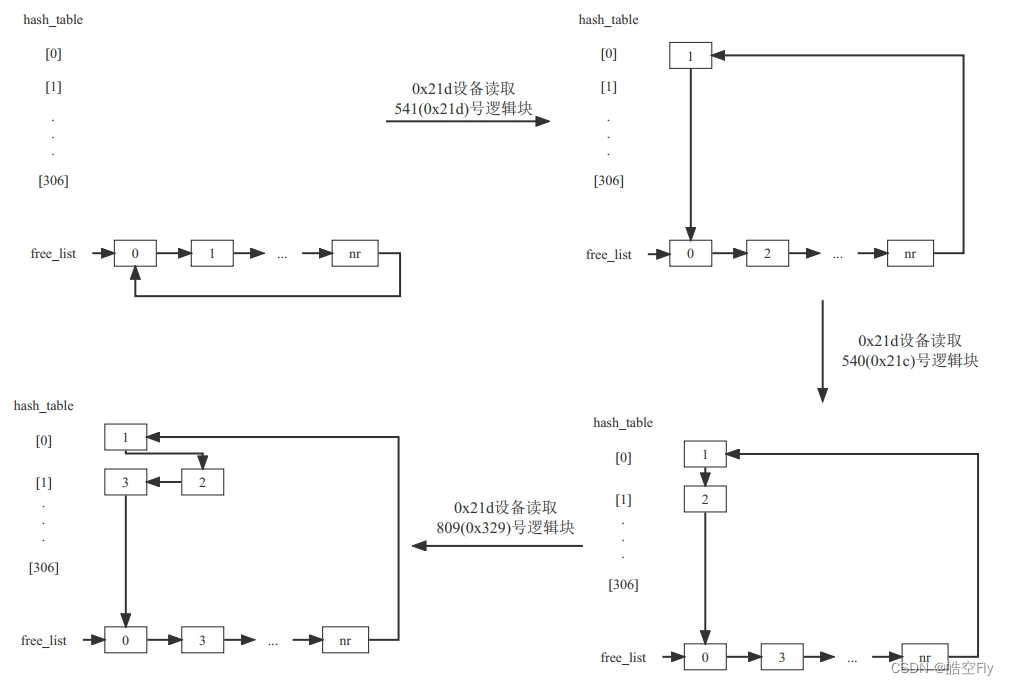
一开始哈希表中元素都为 NULL。当读取541号逻辑块时,找到一个可用的缓冲头结构体,将它放在链表的末尾,然后插入到哈希链表0中((0x21d ^ 0x21d) % 307 = 0)。当读取540号逻辑块时,也会把缓冲头结构体放到链表的末尾,并插入到哈希链表1中((0x21d ^ 0x21c) % 307 = 1)。
假如逻辑块的数据已经被读入缓冲头结构体,我们自然不必要再读一次,只需要在哈希链表中搜索就可以了。
// buffer.c
static struct buffer_head *find_buffer(int dev, int block)
{
struct buffer_head *tmp;
for (tmp = hash(dev, block); tmp != NULL; tmp = tmp->b_next)
if (tmp->b_dev == dev && tmp->b_blocknr == block) // 对比链表中的元素
return tmp;
return NULL;
}
struct buffer_head *get_hash_table(int dev, int block)
{
struct buffer_head *bh;
while (1) {
bh = find_buffer(dev, block);
if (!bh) // 逻辑块还没被读过
return NULL;
bh->b_count++;
wait_on_buffer(bh); // 如果正在读取数据,需要等待
if (bh->b_dev == dev && bh->b_blocknr == block)
return bh;
bh->b_count--;
}
}
b_count 表示使用此缓冲头结构体的用户数,如果为0,说明无人使用这个缓冲头结构体,里面的数据可以被其他数据覆盖掉。在读取软盘数据时 b_count 被设置为1。
// buffer.c
void brelse(struct buffer_head *buf)
{
if (!buf)
return;
wait_on_buffer(buf);
if (!(buf->b_count--))
panic("Trying to free free buffer");
wake_up(&buffer_wait);
}
struct buffer_head *bread(int dev, int block)
{
struct buffer_head *bh;
bh = getblk(dev, block);
if (!bh)
panic("bread: getblk returned NULL\n");
if (bh->b_uptodate)
return bh;
ll_rw_block(READ, bh);
wait_on_buffer(bh);
if (bh->b_uptodate)
return bh;
brelse(bh);
return NULL;
}
在 bread 函数中使用 getblk 函数获得一个可使用的缓冲头结构体,如果读取数据不成功,使用 brelse 释放掉该缓冲头结构体,如果有等待缓冲头结构体的任务,还需要唤醒该任务。
每当我们不再使用缓冲头结构体的数据时,就使用 brelse 函数释放掉缓冲头结构体,这样缓冲头结构体就可以被反复使用。
为了测试程序,修改了如下代码。读取两次逻辑块,缓冲头结构体的地址应该不同。
// super.c
static struct d_super_block *read_super(int dev)
{
struct d_super_block *s = &ds;
struct buffer_head *bh, *bh1;
bh = bread(dev, 1);
if (!bh)
return NULL;
bh1 = bread(dev, 2);
if (!bh1)
return NULL;
printk("bh: %x, bh1: %x\n\r", bh, bh1);
__asm__("cld"::); // 不加这句,结构体赋值会出错
*s = *((struct d_super_block *) bh->b_data);
if (s->s_magic != SUPER_MAGIC)
return NULL;
return s;
}
代码运行起来并没有问题。你也可以读同一个逻辑块,看 b_count 是否发生了变化。
最后,提出一个问题:缓冲头结构体中 b_uptodate、b_count 和 b_lock 的作用分别是什么?
5.获得根目录inode
在读取根目录 inode 之前,我们还需要对超级块做一些修改。
系统中可能存在多个含有文件系统的软盘,我们需要把这些软盘的超级块都读取到内存中,为了区分超级块属于哪个软盘,我们需要向超级块结构体中添加一个成员——设备号。
// fs.h
#define NR_SUPER 8
struct super_block {
unsigned short s_ninodes;
unsigned short s_nzones;
unsigned short s_imap_blocks;
unsigned short s_zmap_blocks;
unsigned short s_firstdatazone;
unsigned short s_log_zone_size;
unsigned long s_max_size;
unsigned short s_magic;
/* These are only in memory */
unsigned short reserved;
unsigned short s_dev; // 设备号
};
// super.c
struct super_block super_block[NR_SUPER];
并不是直接向 d_super_block 中添加成员,而是重新定义了一个结构体,因为我们还需要用 d_super_block 来进行赋值。在汇编中结构体赋值是以4字节为单位进行的,不加 reserved 的话,会导致赋值后 s_dev 的值变为0。(调试了好久才发现了这个 bug)
另外还定义了一个 super_block 结构体数组,用于记录软盘的超级块信息。
添加了上面的代码,我们需要修改一下 read_super 函数的代码。
// fs.h
#define NR_SUPER 8
// super.c
struct super_block super_block[NR_SUPER];
static struct super_block *read_super(int dev)
{
struct super_block *s;
struct buffer_head *bh;
if (!dev)
return NULL;
s = get_super(dev);
if (s) // 如果超级块信息已经被读入内存
return s;
for (s = super_block; ; s++) {
if (s >= NR_SUPER + super_block)
return NULL; // 如果没有空闲的超级块结构体
if (!s->s_dev)
break;
}
s->s_dev = dev;
bh = bread(dev, 1);
if (!bh) {
s->s_dev = 0;
return NULL;
}
__asm__("cld"::); // 不加这句,结构体赋值会出错
*(struct d_super_block *)s = *((struct d_super_block *)bh->b_data);
brelse(bh);
if (s->s_magic != SUPER_MAGIC) { // 超级块的数据有问题
s->s_dev = 0;
return NULL;
}
return s;
}
get_super 通过设备号查找超级块信息,如果该设备的超级块还未被读入,就返回 NULL;否则,返回超级块的指针。
如果设备的超级块还未被读入,我们需要找到一个空闲的超级块,将超级块信息读入内存,然后对相应的超级块结构体成员赋值。当然,我们需要检查超级块的魔数,如果魔数不对,说明文件系统出问题了。最后将这个超级块返回。
// super.c
struct super_block *get_super(int dev)
{
struct super_block *s;
if (!dev)
return NULL;
s = super_block;
while (s < NR_SUPER + super_block)
if (s->s_dev == dev)
return s;
else
s++;
return NULL;
}
get_super 的代码很简单,就是遍历超级块数组,找到一个和参数相同设备号的超级块。没找到就返回 NULL。
接下来讲讲与 inode 相关的内容。
我们读取 inode,需要知道它来自哪个设备,节点号是多少,于是也需要向 inode 结构体中添加成员。
// fs.h
#define NR_INODE 32
struct m_inode {
unsigned short i_mode; // 文件的类型和属性(rwx)
unsigned short i_uid; // 文件所有者的用户id
unsigned long i_size; // 文件长度(字节)
unsigned long i_mtime; // 修改时间(从1970.1.1:0时算起,单位:秒)
unsigned char i_gid; // 文件所有者的组id
unsigned char i_nlinks; // 链接数
unsigned short i_zone[9]; // 文件占用的逻辑块的块号
// zone[0]-zone[6]是直接块号
// zone[7]是一次间接块号
// zone[8]是二次间接块号
/* these are in memory also */
unsigned short i_dev; // 设备号
unsigned short i_num; // inode号
};
// inode.c
struct m_inode inode_table[NR_INODE]={{0, }, };
同样,我们需要定义一个 inode 数组保存读取的 inode,方便我们在之后的操作中使用。
// fs.h
#define NR_INODE 32
#define INODES_PER_BLOCK ((BLOCK_SIZE) / (sizeof(struct d_inode)))
// inode.c
struct m_inode inode_table[NR_INODE]={{0, }, };
struct m_inode *iget(int dev, int nr)
{
struct m_inode *inode;
if (!dev)
panic("iget with dev == 0");
inode = inode_table;
inode->i_dev = dev;
inode->i_num = nr;
read_inode(inode);
return inode;
}
static void read_inode(struct m_inode *inode)
{
struct super_block *sb;
struct buffer_head *bh;
int block;
sb = get_super(inode->i_dev);
block = 2 + sb->s_imap_blocks + sb->s_zmap_blocks + (inode->i_num - 1) / INODES_PER_BLOCK; // 计算inode所在的逻辑块
bh = bread(inode->i_dev, block);
if (!bh)
panic("unable to read i-node block");
__asm__("cld"::);
*(struct d_inode *)inode = ((struct d_inode *)bh->b_data)[(inode->i_num - 1) % INODES_PER_BLOCK];
brelse(bh);
}
系统中第一个 inode 对应于根目录,它的 inode 号是1。
iget 的代码写得比较简单,直接粗暴地分配了一个 inode 结构体。如果再次调用 iget 函数,就会将之前的信息覆盖掉。这个 bug 等下一节在修改吧。
read_inode 用于读取 inode。之前讲过,minix1.0 文件系统分为6个部分:引导区,超级块,inode 位图,逻辑块位图,inode,数据区。引导区和超级块共占用2个逻辑块,s_imap_blocks 代表 inode 位图占用的逻辑块数量,s_zmap_blocks 代表逻辑块位图占用的逻辑块数量,最后再通过 inode 号计算出 inode 所在的逻辑块。INODES_PER_BLOCK 代表一个逻辑块中 inode 的个数。
将逻辑块读入内存,对 inode 成员进行赋值。由于之后不再使用 bh,所以最后要释放它。
最后,我们要读出根目录的 inode。
// super.c
void mount_root(void)
{
struct super_block *p;
struct m_inode *mi;
p = read_super(ROOT_DEV);
if (!p)
panic("Unable to mount root");
mi = iget(ROOT_DEV, ROOT_INO);
if (!mi)
panic("Unable to read root i-node");
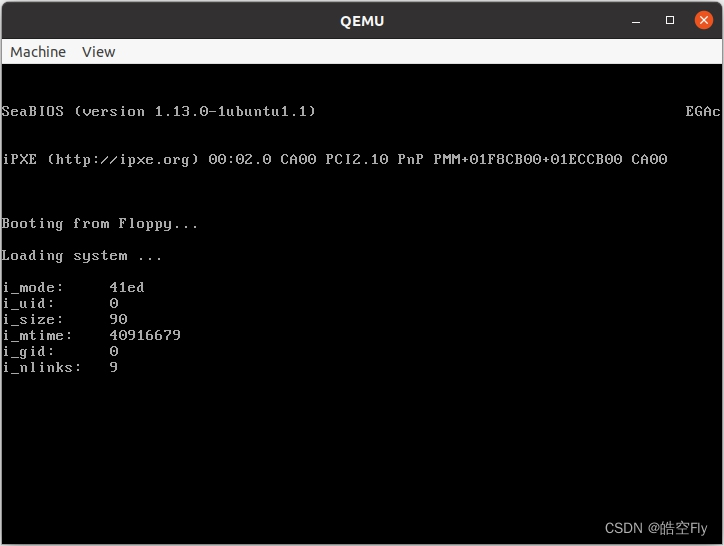
printk("i_mode: %x\r\n", mi->i_mode);
printk("i_uid: %x\r\n", mi->i_uid);
printk("i_size: %x\r\n", mi->i_size);
printk("i_mtime: %x\r\n", mi->i_mtime);
printk("i_gid: %x\r\n", mi->i_gid);
printk("i_nlinks: %x\r\n", mi->i_nlinks);
}
来看看运行结果吧。
6.读取文件系统信息
如果想要创建文件,需要知道哪些 inode 和逻辑块没有被使用,那么如何知道呢?通过 inode 位图和逻辑块位图。我们需要将这些数据从磁盘读取到内存中。
为了在之后的代码中使用位图,我们将相关的结构放在超级块结构体中。这样就可以通过超级块知道软盘的 inode 和逻辑块的使用情况。
// fs.h
struct super_block {
unsigned short s_ninodes;
unsigned short s_nzones;
unsigned short s_imap_blocks;
unsigned short s_zmap_blocks;
unsigned short s_firstdatazone;
unsigned short s_log_zone_size;
unsigned long s_max_size;
unsigned short s_magic;
/* These are only in memory */
unsigned short reserved;
struct buffer_head *s_imap[8]; // inode位图
struct buffer_head *s_zmap[8]; // 逻辑块位图
unsigned short s_dev; // 设备号
};
接下来是读取 inode 位图和逻辑块位图的代码。
// fs.h
#define I_MAP_SLOTS 8
#define Z_MAP_SLOTS 8
// super.c
static struct super_block *read_super(int dev)
{
struct super_block *s;
struct buffer_head *bh;
int i, block;
...
for (i = 0; i < I_MAP_SLOTS; i++)
s->s_imap[i] = NULL;
for (i = 0; i < Z_MAP_SLOTS; i++)
s->s_zmap[i] = NULL;
block = 2; // 2号逻辑块是inode位图
for (i = 0; i < s->s_imap_blocks; i++) { // 读取inode位图
s->s_imap[i] = bread(dev, block);
if (s->s_imap[i])
block++;
else
break;
}
for (i = 0; i < s->s_zmap_blocks; i++) { // 读取逻辑块位图
s->s_zmap[i] = bread(dev, block);
if (s->s_zmap[i])
block++;
else
break;
}
if (block != 2 + s->s_imap_blocks + s->s_zmap_blocks) {
// 如果读取的数量出现问题,将读取的数据释放掉
for(i = 0; i < I_MAP_SLOTS; i++)
brelse(s->s_imap[i]);
for(i = 0; i < Z_MAP_SLOTS; i++)
brelse(s->s_zmap[i]);
s->s_dev = 0;
return NULL;
}
return s;
}
第13-16行初始化相关数据结构。
第17-31行读取 inode 位图和逻辑块位图。
如果读取的逻辑块数量出现问题,释放掉 buffer_head 结构体,返回 NULL。
如果没有问题,就返回超级块指针。
现在来解决上一节关于 m_inode 结构体分配的问题。
// inode.c
struct m_inode *iget(int dev, int nr)
{
struct m_inode *inode, *empty;
if (!dev)
panic("iget with dev == 0");
inode = inode_table;
// 查看inode是否已被读入
while (inode < NR_INODE + inode_table) {
if (inode->i_dev != dev || inode->i_num != nr) {
inode++;
continue;
}
inode->i_count++;
return inode;
}
// 查找一个未被使用的inode结构体
empty = get_empty_inode();
if (!empty)
return NULL;
inode = empty;
inode->i_dev = dev;
inode->i_num = nr;
read_inode(inode); // 将数据读到这个结构体中
return inode;
}
我们已经定义了一个 inode 数组,当需要从软盘读取 inode 时,首先查看该 inode 是否被已被读取,如果没有被读取过,再从 inode 数组中找到一个未被使用的成员,将 inode 数据读取到这个成员中。
// string.h
static inline void *memset(void *s, int c, unsigned int count)
{
__asm__("cld\n\t"
"rep\n\t"
"stosb"
:: "a"(c), "D"(s), "c"(count));
return s;
}
// inode.c
struct m_inode *get_empty_inode(void)
{
struct m_inode *inode;
static struct m_inode *last_inode = inode_table;
int i;
do {
inode = NULL;
// 遍历查找未使用的结构体
for (i = NR_INODE; i; i--) {
if (++last_inode >= inode_table + NR_INODE)
last_inode = inode_table;
if (!last_inode->i_count) {
inode = last_inode;
break;
}
}
// 如果结构体都被使用了
if (!inode) {
for (i = 0; i < NR_INODE; i++)
printk("%04x: %6d\t", inode_table[i].i_dev,
inode_table[i].i_num);
panic("No free inodes in mem");
}
} while (inode->i_count);
memset(inode, 0, sizeof(*inode));
inode->i_count = 1;
return inode;
}
查找一个未被使用的 inode 结构体的办法很简单,通过遍历数组元素即可。如果数组元素都被使用,就报错。
上面的函数中 m_inode 结构体使用了一个新成员——i_count。当 i_count 为0时,表示该结构体未被使用。当 i_count 从1变为0时,需要将该 inode 写回软盘中。
// fs.h
struct m_inode {
unsigned short i_mode; // 文件的类型和属性(rwx)
unsigned short i_uid; // 文件所有者的用户id
unsigned long i_size; // 文件长度(字节)
unsigned long i_mtime; // 修改时间(从1970.1.1:0时算起,单位:秒)
unsigned char i_gid; // 文件所有者的组id
unsigned char i_nlinks; // 链接数
unsigned short i_zone[9]; // 文件占用的逻辑块的块号
// zone[0]-zone[6]是直接块号
// zone[7]是一次间接块号
// zone[8]是二次间接块号
/* these are in memory also */
unsigned short i_dev; // i 节点号
unsigned short i_num; // 设备号
unsigned short i_count; // 引用计数
};
最后我们来计算一下,有多少未使用的 inode 和逻辑块。
// super.c
#define set_bit(bitnr,addr) ({ \
register int __res ; \
__asm__("bt %2, %3\n\tsetb %%al":"=a"(__res): "a"(0), "r"(bitnr), "m"(*(addr))); \
__res; })
void mount_root(void)
{
int i, free;
struct super_block *p;
struct m_inode *mi;
...
mi = iget(ROOT_DEV, ROOT_INO);
if (!mi)
panic("Unable to read root i-node");
free = 0;
i = p->s_nzones; // 逻辑块数
while (--i >= 0)
if (!set_bit(i & 8191, p->s_zmap[i >> 13]->b_data))
free++;
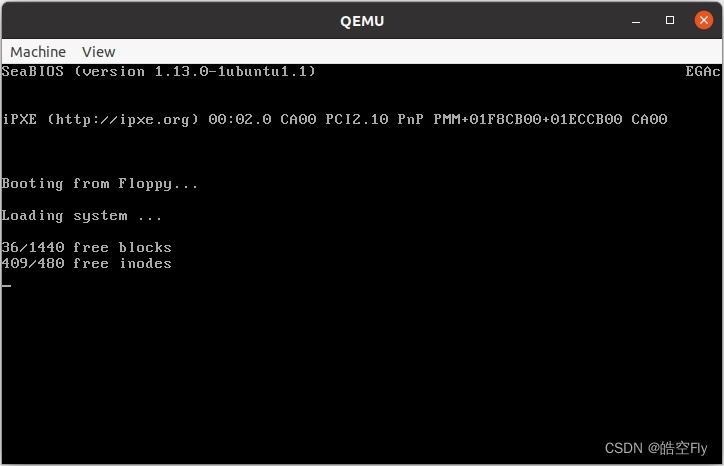
printk("%d/%d free blocks\n\r", free, p->s_nzones);
free = 0;
i = p->s_ninodes + 1; // inode数
while (--i >= 0)
if (!set_bit(i & 8191, p->s_imap[i >> 13]->b_data))
free++;
printk("%d/%d free inodes\n\r", free, p->s_ninodes);
}
汇编指令bt用于位测试,这个指令会更改 CF 的值。假设 ax 的值为 0x81,bt $2, %ax会检查 ax 的 bit2 是否为1,0x81 的 bit2 位为0,因此会使得 CF=0。而bt $0, ax会使得 CF=1,因为 ax 的 bit0 为1。
i >> 13 用于指定逻辑块或 inode 所属的位图。1个逻辑块有1024字节(byte),即8192个位(bit)。i & 8191 用于取得位图的第几位。
第19-21行会遍历所有逻辑块位图的所有位,如果对应的位为0,表示该逻辑块未被使用,空闲逻辑块数加1。
在统计 inode 个数时,并没有算上0号 inode(根目录是1号 inode),第24行加1,就是把0号 inode 也算上。
最后来看看执行结果。
7.open - 寻找文件所在目录
这一节开始介绍 open 函数的实现过程,open 函数的内容较多,将会拆分成几个部分进行介绍。而这一节,主要讲如何通过文件路径找到文件所在目录的 inode和逻辑块。
首先,要在 task_struct 里添加两个 inode 指针,root 代表根目录的 inode,pwd 代表当前目录的inode。并将第一个进程的这两个指针设置为 NULL。
// sched.h
struct task_struct {
...
int tty; // 进程使用的tty的子设备号。-1表示没有使用
unsigned short umask; // 文件创建属性屏蔽位
struct m_inode *pwd; // 当前目录的inode
struct m_inode *root; // 根目录的inode
unsigned long close_on_exec; // 运行可执行文件时关闭文件句柄位图
struct desc_struct ldt[3]; // 任务局部描述符表。0-空,1-代码段,2-数据和堆栈段
struct tss_struct tss; // 进程的任务状态段信息
};
#define INIT_TASK \
...
/* tty etc */ -1,0022,NULL,NULL,0, \
...
}
添加这两个指针是为了方便查找文件的 inode 和逻辑块。比如,文件的路径是/dev/tty0,文件系统会以根目录–>dev–>tty0 的顺序依次查找文件。我们必须知道根目录的 inode。又比如,文件的路径是./Desktop/main.c,文件系统会以当前目录–>Desktop–>main.c 的顺序依次查找文件。此时也必须知道当前目录的 inode。
在 task_struct 中添加了成员,在 fork、exit 中也要对其进行设置。
// fork.c
int copy_process(int nr, long ebp, long edi, long esi, long gs,
long none, long ebx, long ecx, long edx,
long fs, long es, long ds, long eip,
long cs, long eflags, long esp, long ss)
{
...
if (current->pwd)
current->pwd->i_count++;
if (current->root)
current->root->i_count++;
// 设置新任务的tss和ldt描述符
set_tss_desc(gdt + (nr << 1) + FIRST_TSS_ENTRY, &(p->tss));
set_ldt_desc(gdt + (nr << 1) + FIRST_LDT_ENTRY, &(p->ldt));
p->state = TASK_RUNNING; // 将任务设置为可运行状态
return last_pid;
}
// exit.c
int do_exit(long code)
{
...
current->pwd = NULL;
current->root = NULL;
current->state = TASK_ZOMBIE;
current->exit_code = code;
tell_father(current->father);
schedule();
return (-1);
}
fork时,子进程会继承父进程的 root 和 pwd,并将它们的引用计数加1。exit时,会将 root 和 pwd 设置为 NULL。
在第5节中,我们获得了根目录的 inode,这之后,需要设置当前进程的 root 和 pwd。
// super.c
void mount_root(void)
{
...
mi = iget(ROOT_DEV, ROOT_INO);
if (!mi)
panic("Unable to read root i-node");
mi->i_count += 1;
current->pwd = mi;
current->root = mi;
...
}
pwd 和 root 都使用 mi,mi 的 i_count 应该为2。调用 iget 后 mi 的 i_count 变为1,第8行加1就是2。
好了,做完这些工作,我们就可以尝试寻找文件所在的目录的 inode 了。假设给定的路径是/dev/tty0,我们可以很容易地找到根目录的 inode,通过 inode,我们能够找到根目录的逻辑块。目录的逻辑块中保存了文件名和文件的 inode 号,其结构如下所示。
// fs.h
#define NAME_LEN 14
struct dir_entry {
unsigned short inode;
char name[NAME_LEN];
};

上图是 rootimage 中根目录的逻辑块。第一个文件是".“,代表当前目录。第二个文件是”…",代表上一级目录。第三个文件是 bin(inode 号是2),以此类推。inode 号为0表示没有文件或文件被删除。
了解这些信息后,就可以开始设计算法了。仍以/dev/tty0为例。
(1)根据根目录的 inode 找到根目录的逻辑块
(2)在根目录的逻辑块找到名为 dev 的文件,获得它的 inode 号
(3)根据 dev 的 inode 号找到 dev 的逻辑块
(4)在 dev 的逻辑块中找到名为 tty0 的文件
当然,这个流程还是太简单了,下面的流程图将寻找文件的流程一般化,相信能让大家更容易理解。
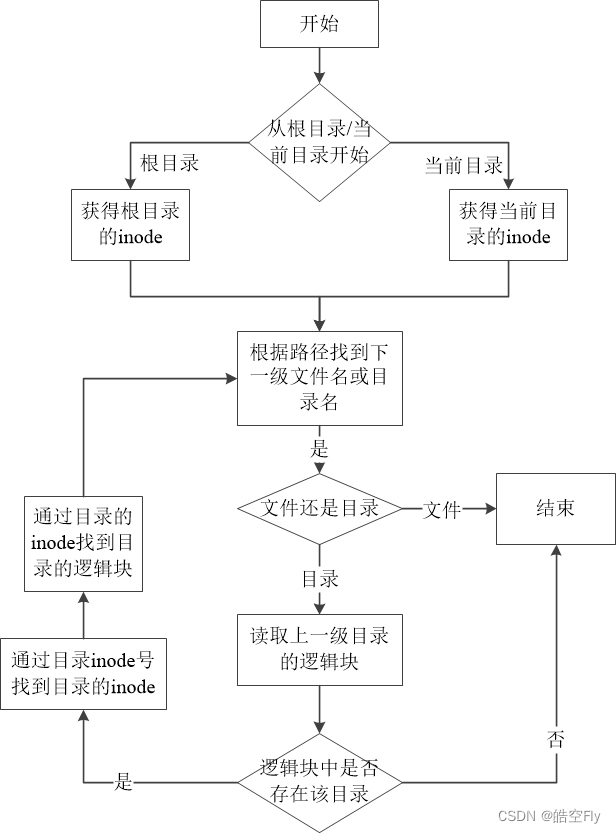
我承认,我这个图确实有点丑,但不妨碍理解。下面就是用代码实现流程图的逻辑。
// fs/open.c
int sys_open(const char *filename, int flag, int mode)
{
return open_namei(filename);
}
// namei.c
static struct m_inode *dir_namei(const char *pathname)
{
return get_dir(pathname);
}
int open_namei(const char *pathname)
{
struct m_inode *dir;
dir = dir_namei(pathname);
if (!dir)
return -ENOENT;
return 0;
}
原本在 linux0.11 中,这三个函数有不少内容,我只保留了最基础的部分,在之后的章节填充。
// namei.c
static struct m_inode *get_dir(const char *pathname)
{
char c;
const char *thisname;
struct m_inode *inode;
struct buffer_head *bh;
int namelen, inr, idev, i;
struct dir_entry *de;
if (!current->root || !current->root->i_count)
panic("No root inode");
if (!current->pwd || !current->pwd->i_count)
panic("No cwd inode");
c = get_fs_byte(pathname);
if (c == '/') { // 第一个字符是/,说明是绝对路径
inode = current->root;
pathname++;
}
else if (c) // 相对路径
inode = current->pwd;
else
return NULL;
while (1) {
thisname = pathname;
if (!S_ISDIR(inode->i_mode) || !permission(inode, MAY_EXEC))
return NULL;
c = get_fs_byte(pathname++);
for(namelen = 0; c && (c != '/'); namelen++)
c = get_fs_byte(pathname++);
if (!c)
return inode;
for (i = 0; i < namelen; i++)
printk("%c", thisname[i]);
bh = find_entry(&inode, thisname, namelen, &de);
if (!bh)
return NULL;
inr = de->inode;
idev = inode->i_dev;
brelse(bh);
inode = iget(idev, inr);
if (!inode)
return NULL;
}
}
get_dir 会返回文件所在目录的 inode。
第16-24行:判断是从根目录还是从当前目录开始查找文件。
第28行:读取的 inode 必须是目录且目录没有可执行权限。
第31-35行代码解析下一级文件名或目录名。如果 c 为 ‘/’,说明这是一个目录;如果 c 为0,说明路径解析完成,返回文件所在目录的 inode。不过这里并没有判断目录中是否存在该文件,这是下一节的内容。
第37-38行:打印解析的目录名。
第40行:读取上一级目录的逻辑块,并查找是否存在刚才解析的目录。假设路径是/dev/tty0,我们解析的目录名是 dev,这里读取的是根目录的逻辑块,并在根目录的逻辑块中查找是否有 dev。
第44-49行:将解析的目录的inode读取到内存中。
permission 函数会检查进程是否有文件的权限。suser() 返回1代表当前进程属于超级用户,超级用户拥有所有的权限。
// namei.c
static int permission(struct m_inode *inode, int mask)
{
int mode = inode->i_mode;
if (inode->i_dev && !inode->i_nlinks) // 链接数至少为1
return 0;
else if (current->euid == inode->i_uid) // 当前进程属于创建文件的用户
mode >>= 6;
else if (current->egid == inode->i_gid) // 当前进程所属的用户与创建文件的用户在同一用户组
mode >>= 3;
if (((mode & mask & 0007) == mask) || suser())
return 1;
return 0;
}
i_mode 的低9位是不同用户对文件的读/写/执行权限,如下图所示。也可以通过它得知文件是普通文件、目录、字符设备等等。
接下来看看 find_entry 中读取逻辑块和查找目录的操作。
// namei.c
static struct buffer_head *find_entry(struct m_inode **dir,
const char *name, int namelen, struct dir_entry **res_dir)
{
int entries;
int block, i;
struct buffer_head *bh;
struct dir_entry *de;
if (!namelen)
return NULL;
if (namelen > NAME_LEN)
namelen = NAME_LEN;
entries = (*dir)->i_size / (sizeof(struct dir_entry));
*res_dir = NULL;
block = (*dir)->i_zone[0];
if (!block)
return NULL;
bh = bread((*dir)->i_dev, block);
if (!bh)
return NULL;
i = 0;
de = (struct dir_entry *) bh->b_data;
while (i < entries) {
if (match(namelen, name, de)) {
*res_dir = de;
return bh;
}
de++;
i++;
}
brelse(bh);
return NULL;
}
第10-13行:检查目录名长度是否有问题,名字过长会被截掉一部分。假如路径是/dev//,dev 的下一级目录的长度为0,这也是不行的。
第15行:计算上一级目录存在多少个文件。
第18行:找到上一级目录的第一个逻辑块号。
第22-24行:通过逻辑块号读取相应的逻辑块到内存中。
第26-35行:不断循环对比文件名。如果不存在该文件,则返回 NULL。这一段代码还不够完善。一个逻辑块最多存储64个目录项,假设一个目录有128个文件,文件名保存在两个逻辑块中,如果要读取的文件名在第二个逻辑块,那么就可能出现错误。这个错误的完善也会放在之后的章节来完成。
文件名对比的函数比较简单。由于 linux0.11 自带的 strncmp 有点小问题,所以我自己实现了一个。
// string.h
static inline int strncmp(const char *cs, const char *ct, int count)
{
char *base = (char *)cs;
for (; cs - base < count && *cs == *ct; cs++, ct++)
if (!*cs)
return 0;
return cs - base == count ? 0 : (*cs - *ct);
}
// namei.c
static int match(int len, const char *name, struct dir_entry *de)
{
if (!de || !de->inode || len > NAME_LEN)
return 0;
if (len < NAME_LEN && de->name[len]) // 解析的文件名长度比目录项的文件名长度小
return 0;
return strncmp(name, de->name, len) == 0;
}
接下来要完善用户使用的系统调用。
// unistd.h
#define __NR_open 5
// lib/open.c
#define __LIBRARY__
#include <unistd.h>
#include <stdarg.h>
int open(const char * filename, int flag, ...)
{
register int res;
va_list arg;
va_start(arg, flag);
__asm__("int $0x80"
:"=a" (res)
:"0" (__NR_open), "b" (filename), "c" (flag),
"d" (va_arg(arg, int)));
if (res >= 0)
return res;
errno = -res;
return -1;
}
// sys.h
extern int sys_open();
fn_ptr sys_call_table[72] = {sys_setup, sys_exit, sys_fork, 0, 0, sys_open, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, sys_pause};
最后是在 main.c 中调用 open 函数。
// main.c
#include <fcntl.h>
void init(void)
{
setup();
open("/dev/tty0", O_RDWR, 0);
while (1);
}
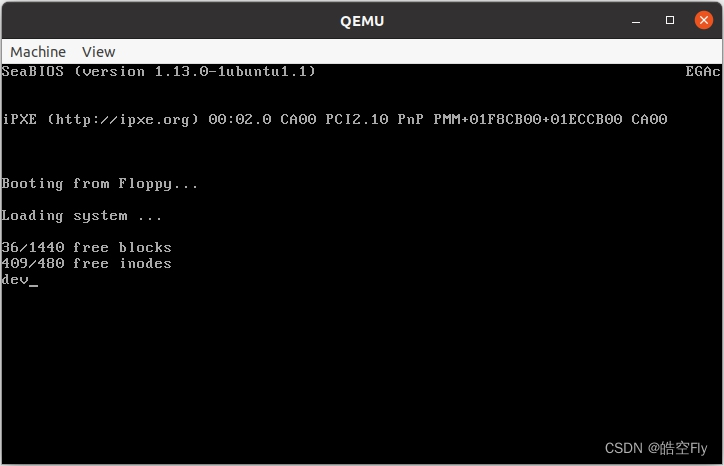
运行结果如下。可以看到,最下方打印了 dev。
8.open - 读取文件信息
为了方便查找已打开的文件,使用数组管理所有打开的文件。同时,也会在进程中添加一个结构来管理文件,这可以很方便地知道进程打开了那些文件,方便进行资源的管理。
我们应该用怎样的数据结构去描述一个文件呢?我们不仅要知道文件的信息,还要知道对文件做什么操作。
struct file {
unsigned short f_mode; // 文件操作模式
unsigned short f_flags; // 文件打开和控制的标志
unsigned short f_count; // 引用计数
struct m_inode *f_inode; // 文件对应的inode
off_t f_pos; // 文件内的读写偏移值
};
通过 f_inode 主要用来找文件的逻辑块号。通过 f_flags 可以知道进程对文件的操作权限,比如创建(O_CREAT)、只读(O_RDONLY)、只写(O_WRONLY)等。f_mode 的信息与 inode 中的 i_mode 一样,可以知道文件的信息,用户对文件的访问权限等。f_count 代表使用该文件的次数。f_pos 是当前读写的位置,可以参考 lseek 函数了解该功能。
然后要将它添加到进程中,每个进程最多只能打开20个文件。
// fs.h
#define NR_OPEN 20
// sched.h
struct task_struct {
...
struct m_inode *pwd; // 当前目录的inode
struct m_inode *root; // 根目录的inode
unsigned long close_on_exec; // 运行可执行文件时关闭文件句柄位图
struct file *filp[NR_OPEN]; // 进程打开的文件
struct desc_struct ldt[3]; // 任务局部描述符表。0-空,1-代码段,2-数据和堆栈段
struct tss_struct tss; // 进程的任务状态段信息
};
#define INIT_TASK \
...
/* tty etc */ -1,0022,NULL,NULL,0, \
/* filp */ {NULL,}, \
...
}
添加到进程后应该做什么?没错,又要改 fork。
// fork.c
int copy_process(int nr, long ebp, long edi, long esi, long gs,
long none, long ebx, long ecx, long edx,
long fs, long es, long ds, long eip,
long cs, long eflags, long esp, long ss)
{
struct task_struct *p;
int i;
struct file *f;
p = (struct task_struct *) get_free_page();
if (!p)
return -EAGAIN;
task[nr] = p;
...
for (i = 0; i < NR_OPEN; i++) {
f = p->filp[i];
if (f)
f->f_count++;
}
if (current->pwd)
current->pwd->i_count++;
if (current->root)
current->root->i_count++;
...
}
子进程会继承父进程打开的文件。第14行会把父进程的文件指针拷贝到子进程,第20行会增加数据结构的引用计数。
现在来完善 sys_open 函数。
// file_table.c
#include <linux/fs.h>
struct file file_table[NR_FILE];
// open.c
#include <errno.h>
#include <linux/sched.h>
int sys_open(const char *filename, int flag, int mode)
{
struct m_inode *inode;
struct file *f;
int i, fd;
for(fd = 0; fd < NR_OPEN; fd++)
if (!current->filp[fd])
break;
if (fd >= NR_OPEN)
return -EINVAL;
f = 0 + file_table;
for (i = 0 ; i < NR_FILE; i++, f++)
if (!f->f_count)
break;
if (i >= NR_FILE)
return -EINVAL;
current->filp[fd] = f;
i = open_namei(filename, flag, mode, &inode);
if (i < 0) {
current->filp[fd] = NULL;
return i;
}
f->f_mode = inode->i_mode;
f->f_flags = flag;
f->f_count = 1;
f->f_inode = inode;
f->f_pos = 0;
printk("open file successfully!\n");
return (fd);
}
file_table 用于管理所有打开的文件。sys_open 的 mode 参数用于创建文件,现在不使用。
第15-19行:查找进程的文件数组中是否有空闲项,没有就不能打开文件。
第21-26行:查找 file_table 中是否有空闲项,没有就不能打开文件。
第28行:找到 file_table 中空闲项后,将其记录在进程中。
第30-34行:open_namei 返回负数代表出错,此时清除进程中的文件信息,并返回错误值。在 open_namei 返回正常的情况下,inode 变量保存了目标文件的 inode。
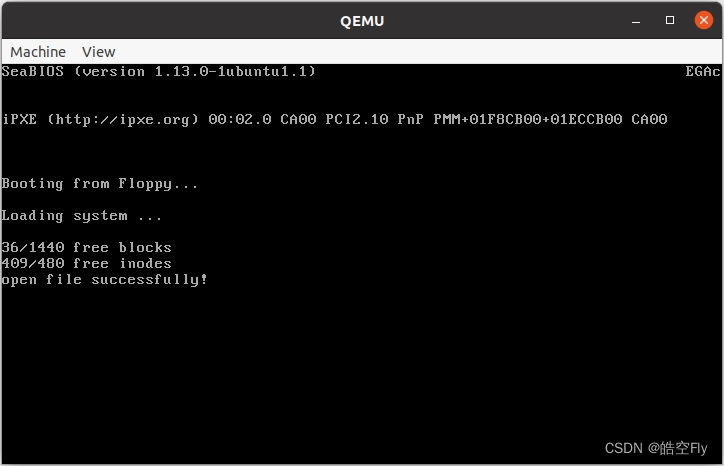
第36-42行:对文件结构进行赋值,并返回文件描述符。如果打开文件成功就会打印上面的语句。
这一节的 open_namei 需要读取文件的 inode,修改如下:
// namei.c
int open_namei(const char *pathname, int flag, int mode, struct m_inode **res_inode)
{
const char *basename;
int inr, dev, namelen;
struct m_inode *dir, *inode;
struct buffer_head *bh;
struct dir_entry *de;
dir = dir_namei(pathname, &namelen, &basename);
if (!dir)
return -ENOENT;
if (!namelen)
return -EISDIR;
bh = find_entry(&dir, basename, namelen, &de);
if (!bh)
return -ENOENT;
inr = de->inode;
dev = dir->i_dev;
brelse(bh);
inode = iget(dev, inr);
if (!inode)
return -EACCES;
inode->i_atime = CURRENT_TIME;
*res_inode = inode;
return 0;
}
// sched.h
#define CURRENT_TIME (startup_time + jiffies / HZ)
open_namei 的返回值用于判断是否出现问题。但是我们又想获得文件的 inode 指针,这怎么办呢?很简单,如果我们想修改 inode 成员的值,将 inode 的指针传入就行了。那么我们想要修改 inode 指针的值,将 inode 指针的指针作为参数就行了。
第10-14行:dir_namei 会返回文件所在目录的 inode,通过路径解析出文件名和文件名长度。如果路径中的目录不存在,或是路径中只有目录没有文件名,就会出错。
第16-18行:find_entry 中会通过目录的 inode 找到逻辑块,然后查找文件名。如果目录中不存在该文件就会报错。
第20-22行:获取文件的 inode 号和文件所在设备的设备号。bh 是目录的文件缓冲区,由于之后不会再使用它,所有这里会释放该缓冲区。
第24-26行:读取文件的 inode。
第28行修改文件最近的访问时间。i_atime 是 m_inode 结构体中新的成员。
第29行设置 res_inode,以供调用 open_namei 的函数使用。
最后返回0。
dir_namei 的改动不大,仅仅是找到文件名和算出文件名长度。
// namei.c
/**
* 通过路径名找到文件名、文件所在目录的inode,计算出文件名长度
* @param pathname 文件的路径(绝对路径或相对路径)
* @param namelen 通过指针得到文件名的长度
* @param name 通过指针得到文件名
* @return NULL:没有找到文件的目录;其他:文件目录的inode
*/
static struct m_inode *dir_namei(const char *pathname, int *namelen, const char **name)
{
char c;
const char *basename;
struct m_inode *dir;
dir = get_dir(pathname);
if (!dir)
return NULL;
basename = pathname;
do {
c = get_fs_byte(pathname++);
if (c == '/')
basename = pathname;
} while (c);
*namelen = pathname - basename - 1; // 计算文件名长度
*name = basename; // 计算文件名起始地址
return dir;
}
最后看看运行的结果。
9.write - 字符设备文件
本来是要先写 close 的,但是我发现没有 printf 真的很不方便,printf 的实现需要用到 write,所以就先写 write 了。
printf 中要写的文件是 /dev/tty0。没错,就是上面打开的那个文件,这是个字符设备文件。在 open 的时候本来应该对字符设备文件做一些特殊处理,但我们这是一个简单的内核,现在还不做这些功能。
按照 C 库标准,0号文件描述符代表标准输入(stdin),1号文件描述符代表标准输出(stdout),2号文件描述符代表标准错误输出。
我们上一节打开的文件的文件描述符是0,代表 stdin。而 printf 中的 write 是对 stdout 输出,那我们怎么搞出新文件呢?这就需要使用 dup 系统调用了。
// fcntl.c
#include <errno.h>
#include <linux/sched.h>
static int dupfd(unsigned int fd, unsigned int arg)
{
if (fd >= NR_OPEN || !current->filp[fd])
return -EBADF;
if (arg >= NR_OPEN)
return -EINVAL;
while (arg < NR_OPEN)
if (current->filp[arg])
arg++;
else
break;
if (arg >= NR_OPEN)
return -EMFILE;
current->filp[arg] = current->filp[fd];
current->filp[arg]->f_count++;
return arg;
}
int sys_dup(unsigned int fildes)
{
return dupfd(fildes, 0);
}
我们可以使用 dup 函数复制文件描述符。
第12-18行:寻找进程中空闲的文件项。
第20-21行:可以看到,我们只是复制文件指针,并增加了文件结构体的引用计数。
最后返回新的文件描述符。
我们只需要使用 dup 复制0号文件描述符两次就可以得到 stdout 和 stderr。那为什么要把一个文件分成三个文件指针呢?好问题!我也不知道。
接下来就可以写 write 函数了。
// read_write.c
#include <sys/stat.h>
#include <errno.h>
#include <linux/kernel.h>
#include <linux/sched.h>
extern int rw_char(int rw, int dev, char *buf, int count, off_t *pos);
int sys_write(unsigned int fd, char *buf, int count)
{
struct file *file;
struct m_inode *inode;
file = current->filp[fd];
if (fd >= NR_OPEN || count < 0 || !file)
return -EINVAL;
if (!count)
return 0;
inode = file->f_inode;
if (S_ISCHR(inode->i_mode))
return rw_char(WRITE, inode->i_zone[0], buf, count, &file->f_pos);
printk("(Write)inode->i_mode=%06o\n", inode->i_mode);
return -EINVAL;
}
第15-19行:检查参数是否有问题。
第21-23行:如果是字符设备,向设备写入内容。字符设备文件的 inode 的 i_zone[0] 存储的是字符设备的设备号。
第25-26行:现在只做了字符设备的功能,如果是其他类型的文件就直接报错。
// char_dev.c
#include <errno.h>
#include <sys/types.h>
#include <linux/sched.h>
extern int tty_write(unsigned minor, char *buf, int count);
typedef int (*crw_ptr)(int rw, unsigned minor, char *buf, int count, off_t *pos);
static int rw_ttyx(int rw, unsigned minor, char *buf, int count, off_t *pos)
{
if (rw == WRITE)
return tty_write(minor, buf, count);
return -1;
}
static int rw_tty(int rw, unsigned minor, char *buf, int count, off_t *pos)
{
if (current->tty < 0)
return -EPERM;
return rw_ttyx(rw, current->tty, buf, count, pos);
}
#define NRDEVS ((sizeof(crw_table)) / (sizeof(crw_ptr)))
static crw_ptr crw_table[] = {
NULL, /* nodev */
NULL, /* /dev/mem etc */
NULL, /* /dev/fd */
NULL, /* /dev/hd */
rw_ttyx, /* /dev/ttyx */
rw_tty, /* /dev/tty */
NULL, /* /dev/lp */
NULL /* unnamed pipes */
};
int rw_char(int rw, int dev, char *buf, int count, off_t *pos)
{
crw_ptr call_addr;
if (MAJOR(dev) >= NRDEVS)
return -ENODEV;
call_addr = crw_table[MAJOR(dev)];
if (!call_addr)
return -ENODEV;
return call_addr(rw, MINOR(dev), buf, count, pos);
}
rw_char 函数中,第39-40行检查设备号是否有问题。第42-44行获得相应设备的调用函数。最后调用该函数。
rw_ttyx 和 rw_tty 的功能相似,都是 tty_write 函数输出字符。
/dev/tty0 的设备号是 0x400,所以会调用 rw_ttyx 函数。
这样一看,sys_write 的实现还是很简单的嘛(前提是我们已经完成了 tty_write)。
然后需要完善 dup 和 write 的系统调用。
// write.c
_syscall3(int, write, int, fd, const char *, buf, off_t, count)
// dup.c
_syscall1(int, dup, int, fd)
// unistd.h
#define __NR_write 4
#define __NR_dup 41
#define _syscall1(type,name,atype,a) \
type name(atype a) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(a))); \
if (__res >= 0) \
return (type) __res; \
errno = -__res; \
return -1; \
}
#define _syscall3(type,name,atype,a,btype,b,ctype,c) \
type name(atype a,btype b,ctype c) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(a)),"c" ((long)(b)),"d" ((long)(c))); \
if (__res>=0) \
return (type) __res; \
errno=-__res; \
return -1; \
}
int dup(int fildes);
int write(int fildes, const char *buf, off_t count);
// sys.h
extern int sys_write();
extern int sys_dup();
fn_ptr sys_call_table[72] = {sys_setup, sys_exit, sys_fork, 0, sys_write, sys_open, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, sys_pause, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, sys_dup};
有了 write 函数就可以写 printf 了,它的逻辑很简单。
// main.c
static char printbuf[1024];
int printf(const char *fmt, ...)
{
va_list args;
int i;
va_start(args, fmt);
i = vsprintf(printbuf, fmt, args);
write(1, printbuf, i);
va_end(args);
return i;
}
并对根目录的 Makefile 的 CFLAGS 进行修改,添加上-fno-builtin选项,防止编译器将 printf 优化成 puts,导致编译报错。
CFLAGS =-Wall -g -O -m32 -fno-builtin -fomit-frame-pointer -fno-stack-protector -no-pie -fno-pic -Iinclude
对 init 函数的修改如下:
// main.c
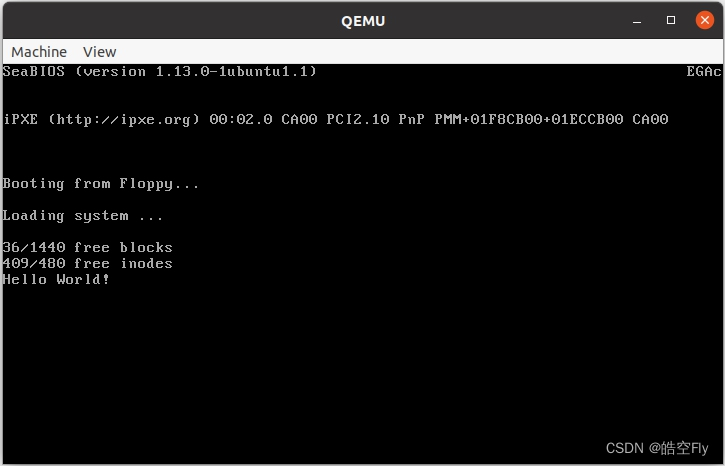
void init(void)
{
setup();
open("/dev/tty0", O_RDWR, 0);
dup(0);
dup(0);
printf("Hello World!\n");
while (1);
}
看看最后的运行结果。
10.read - 读取普通文件
这一节实现普通文件的读取。读取的文件是 /usr/root/hello.c,它的内容是一个打印 Hello World 的程序。
还是从 sys_read 函数开始说起。
// read_write.c
int sys_read(unsigned int fd, char *buf, int count)
{
struct file *file;
struct m_inode *inode;
if (fd >= NR_OPEN || count < 0)
return -EINVAL;
file = current->filp[fd];
if (!file) {
return -EINVAL;
}
if (!count)
return 0;
verify_area(buf, count);
inode = file->f_inode;
if (S_ISDIR(inode->i_mode) || S_ISREG(inode->i_mode)) {
if (count + file->f_pos > inode->i_size)
count = inode->i_size - file->f_pos;
if (count <= 0)
return 0;
return file_read(inode, file, buf, count);
}
printk("(Read)inode->i_mode=%06o\n\r", inode->i_mode);
return -EINVAL;
}
sys_read 的参数是文件描述符 fd,存储内容的指针 buf 和读取的字符数 count。
第7-14行:判断参数是否合法。
第16行:在 fork 时,子进程只是拥有了自己的页表,并没有填充页表项。verify_area 会检查进程是否有数据所在的页,如果没有就把页的内容从父进程拷贝到子进程。
第17-26行:如果文件是目录或普通文件,就读取文件;如果是其他种类的文件,就会报错,之后的章节在处理多种类型的文件。
// file_dev.c
#define MIN(a, b) (((a) < (b)) ? (a) : (b))
int file_read(struct m_inode *inode, struct file *filp, char *buf, int count)
{
int left, chars, nr;
struct buffer_head *bh;
left = count;
if (left <= 0) {
return 0;
}
while (left) {
nr = bmap(inode, (filp->f_pos) / BLOCK_SIZE);
if (nr) {
bh = bread(inode->i_dev, nr);
if (!bh)
break;
}
else
bh = NULL;
nr = filp->f_pos % BLOCK_SIZE;
chars = MIN(BLOCK_SIZE - nr, left);
filp->f_pos += chars;
left -= chars;
if (bh) {
char *p = nr + bh->b_data;
while (chars-- > 0)
put_fs_byte(*(p++), buf++);
brelse(bh);
} else {
while (chars-- > 0)
put_fs_byte(0, buf++);
}
}
inode->i_atime = CURRENT_TIME;
return (count - left) ? (count - left) : -ERROR;
}
第14行:bmap 的参数分别是文件的 inode 指针和文件的第几个逻辑块。这个函数用于查找文件第 n 个逻辑块的块号。
第15-21行:如果找到了逻辑块的块号,将逻辑块读取到内存中。
第23-26行:算出当前逻辑块最多可读取多少字符。如果当前逻辑块可读取所有字符,则无需再循环。
第28-36行:如果之前将逻辑块读取到内存中,就将数据复制到 buf 中,并释放该文件缓冲区。否则,向 buf 中填充0。
// segment.h
static inline void put_fs_byte(char val,char *addr)
{
__asm__("movb %0,%%fs:%1" ::"r"(val), "m"(*addr));
}
put_fs_byte 将内核的一个字节复制到用户进程空间中。
在看 bmap 的实现前,我们要回顾一下文件的相关信息。文件的逻辑块号保存在 inode 的 i_zone[9] 中。数组前7个元素都保存了一个逻辑块号,第8个保存了一个一级逻辑块号,第9个保存了一个二级逻辑块号。我们的思路是:先看看逻辑块号是不是在 i_zone 的前7个元素中,如果不在,那就看是不是在一级逻辑块中,如果也不在,那就去二级逻辑块找。
// inode.c
static int _bmap(struct m_inode *inode, int block, int create)
{
struct buffer_head *bh;
int i;
if (block < 0)
panic("_bmap: block < 0");
if (block >= 7 + 512 + 512 * 512) // 7个直接 + 1个一级间接 + 1个二级间接
panic("_bmap: block > big");
// 直接
if (block < 7) {
return inode->i_zone[block];
}
// 一级间接
block -= 7;
if (block < 512) {
if (!inode->i_zone[7])
return 0;
bh = bread(inode->i_dev, inode->i_zone[7]);
if (!bh)
return 0;
i = ((unsigned short *)(bh->b_data))[block];
brelse(bh);
return i;
}
// 二级间接
block -= 512;
if (!inode->i_zone[8])
return 0;
bh = bread(inode->i_dev, inode->i_zone[8]);
if (!bh)
return 0;
i = ((unsigned short *)bh->b_data)[block >> 9];
brelse(bh);
if (!i)
return 0;
bh = bread(inode->i_dev, i);
if (!bh)
return 0;
i = ((unsigned short *)bh->b_data)[block & 511];
brelse(bh);
return i;
}
int bmap(struct m_inode *inode, int block)
{
return _bmap(inode, block, 0);
}
_bmap 的 create 参数与创建文件有关,现在不使用。
第7-10行:检查参数是否合法。block 不能小于0也不能大于文件拥有逻辑块的最大值。
第13-15行:如果要读取的是文件的前7个逻辑块,就直接返回逻辑块号。
第18-28行:一级逻辑块保存了512个逻辑块号,如果要读取文件的第8-519号逻辑块,需要将一级逻辑块读入内存,我们就能够通过数组索引的方式找到逻辑块号。
第31-48行:二级逻辑块保存了512个一个逻辑块。第35-41行将二级逻辑块读入内存,找到一级逻辑块号。第43-48行将一级逻辑块号读入内存,找到逻辑块号。
OK,接下来是将 read 做成系统调用并使用。
// unistd.h
#define __NR_read 3
int read(int fildes, char *buf, off_t count);
// sys.h
extern int sys_read();
fn_ptr sys_call_table[72] = {sys_setup, sys_exit, sys_fork, sys_read, sys_write, sys_open, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, sys_pause, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, sys_dup};
// main.c
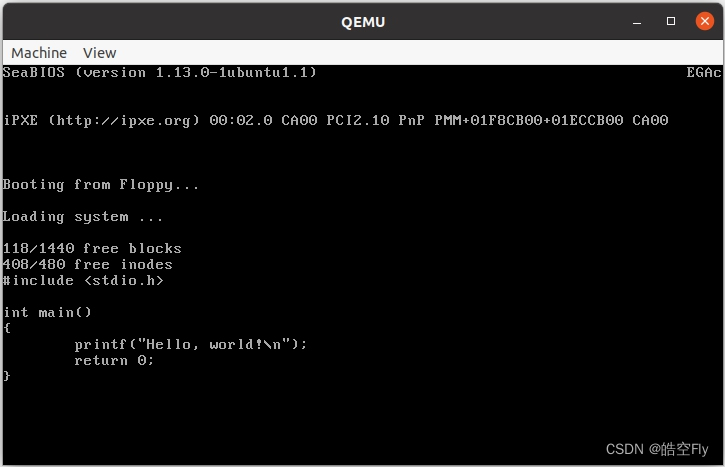
inline _syscall3(int, read, int, fd, char *, buf, off_t, count)
void init(void)
{
int fd;
static char buf[75] = {0};
setup();
open("/dev/tty0", O_RDWR, 0);
dup(0);
dup(0);
fd = open("/usr/root/hello.c", O_RDWR, 0);
read(fd, buf, 74);
printf("%s\n", buf);
while (1);
}
下面是代码运行结果:
11.close - 关闭文件回收inode
本章的最后一节是关闭文件。在关闭文件时,当文件 inode 的引用计数为0时(没有进程使用该 inode),需要回收分配出去的 inode。
// open.c
int sys_close(unsigned int fd)
{
struct file *filp;
if (fd >= NR_OPEN)
return -EINVAL;
filp = current->filp[fd];
if (!filp)
return -EINVAL;
current->filp[fd] = NULL;
if (filp->f_count == 0)
panic("Close: file count is 0");
if (--filp->f_count)
return 0;
iput(filp->f_inode);
return 0;
}
第6-10行:检查参数是否合法。
第14行:将文件指针从进程的文件数组中移除。
第15-16行:如果文件的引用计数为0,说明没有进程使用该文件,这明显是出问题了。
第17-20行:递减文件的引用计数,之后,如果文件的引用计数不等于0,说明还有进程在使用该文件,直接返回。如果等于0,说明没有进程使用该文件,这时就可以释放 inode。
我们在 open 中使用 iget 获取 inode_table 中空闲的 inode,在 close 中使用 iput 将获取的 inode 改为空闲状态。这是对 inode 的分配和回收。
// inode.c
void iput(struct m_inode *inode)
{
if (!inode)
return;
if (!inode->i_count)
panic("iput: trying to free free inode");
inode->i_count--;
}
之前 sys_close 中不是检查了引用计数吗?为什么要再次检查引用计数?因为 iput 不只是 sys_close 在用,其他函数在调用 iput 之前可能不会检查引用计数,这一步就得由 iput 完成。
最后递减 i_count。当 inode 的 i_count 为0时,表示这个 inode 未被使用。
接着,我们需要在已有的函数中不再需要 inode 的地方添加 iput,释放 inode。
第一步,我们需要找到使用过 m_inode 结构体的函数。有 file_read、read_inode、_bmap、bmap、iput、get_empty_inode、iget、read_inode、permission、find_entry、get_dir、dir_namei、open_namei、sys_open、sys_read、sys_write、mount_root、sys_close、do_exit、fork。
第二步,去掉以 m_inode 结构体指针为参数的函数,这些函数只会涉及到对 m_inode 结构体成员的访问,释放操作在其他函数进行。剩下的函数有 get_empty_inode、iget、get_dir、dir_namei、open_namei、sys_open、sys_read、sys_write、mount_root、sys_close、do_exit、fork。
第三步,对第二步中剩余的函数逐个分析。get_empty_inode 函数只是对 inode_table 进行遍历,不需要。目前,iget 函数会读取 inode,没有释放 inode 的地方,不需要。get_dir 函数会读取inode,在解析文件路径出错时,应该释放读取的 inode,需要。open_namei 函数在不能获取文件的 inode 时,会释放文件所在目录的 inode,需要。sys_open、dir_namei 函数中关于 inode 的操作都在 get_dir 中,不需要。sys_read、sys_write 函数只是访问 inode 的成员,不需要。mount_root 是获取 inode 和对 inode 赋值,不需要。sys_close 在上面说过,需要。do_exit 会释放进程的 root 和 pwd,需要。fork 只是对 inode 的赋值,不需要。
综上,需要 iput 的函数有 get_dir,open_namei,do_exit 和 sys_close。sys_close 的代码已在上面给出。
// exit.c
int do_exit(long code)
{
iput(current->pwd);
current->pwd = NULL;
iput(current->root);
current->root = NULL;
current->state = TASK_ZOMBIE;
current->exit_code = code;
tell_father(current->father);
schedule();
return (-1);
}
在清理进程的 pwd 和 root 之前,释放 pwd 和 root,递减它们的 i_count(在 fork 时,子进程会拷贝父进程的 pwd 和 root,并递增它们的 i_count)。
// namei.c
static struct m_inode *get_dir(const char *pathname)
{
...
inode->i_count++;
while (1) {
thisname = pathname;
if (!S_ISDIR(inode->i_mode) || !permission(inode, MAY_EXEC)) {
iput(inode);
return NULL;
}
c = get_fs_byte(pathname++);
for(namelen = 0; c && (c != '/'); namelen++)
c = get_fs_byte(pathname++);
if (!c)
return inode;
bh = find_entry(&inode, thisname, namelen, &de);
if (!bh) {
iput(inode);
return NULL;
}
inr = de->inode;
idev = inode->i_dev;
brelse(bh);
iput(inode);
inode = iget(idev, inr);
if (!inode)
return NULL;
}
}
当解析文件路径出错或读取新的 inode 时,需要释放原来的 inode。iput 会使 inode 的 i_count 减1,iget 会使 inode 的 i_count 加1。我们要保证在 get_dir 函数运行结束后,除文件所在目录以外,其他目录的 inode 的 i_count 保持不变。
// namei.c
int open_namei(const char *pathname, int flag, int mode, struct m_inode **res_inode)
{
...
dir = dir_namei(pathname, &namelen, &basename);
if (!dir)
return -ENOENT;
if (!namelen) {
iput(dir);
return -EISDIR;
}
bh = find_entry(&dir, basename, namelen, &de);
if (!bh) {
iput(dir);
return -ENOENT;
}
inr = de->inode;
dev = dir->i_dev;
brelse(bh);
iput(dir);
inode = iget(dev, inr);
if (!inode)
return -EACCES;
inode->i_atime = CURRENT_TIME;
*res_inode = inode;
return 0;
}
在 open_namei 函数中,我们需要保证只有目标文件的 inode 的 i_count 加1,目录的 i_count 保持不变。
接下来完善 close 系统调用。
// sys.h
extern int sys_close();
fn_ptr sys_call_table[72] = {sys_setup, sys_exit, sys_fork, sys_read, sys_write, sys_open, sys_close, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, sys_pause, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, sys_dup};
// unistd.h
#define __NR_close 6
int close(int fildes);
// close.c
#define __LIBRARY__
#include <unistd.h>
_syscall1(int, close, int, fd)
// main.c
void init(void)
{
int fd;
static char buf[75] = {0};
setup();
open("/dev/tty0", O_RDWR, 0);
dup(0);
dup(0);
fd = open("/usr/root/hello.c", O_RDWR, 0);
read(fd, buf, 74);
printf("%s\n", buf);
close(fd);
while (1);
}
这一节没有测试结果。
这一章的内容到此为止,需要掌握和理解的知识点有很多,需要大家多看看代码。















 908
908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









