









一、Mysql基本架构
这个问题没太有人问,笔者也是浅尝辄止,但是了解一个中间件一定要从架构开始,上来就背八股文那就没意思了。
从下图可以看到Mysql的包括网络连接、服务、数据存储和系统文件(日志)四大部分。

数据连接:客户端连接器(Client Connectors):提供与MySQL服务器建立的支持;
服务:又包括了sql接口,sql解析器,查询优化器,缓存等模块,主要是把sql进行解析和处理;
数据存储:主要是存储引擎,常用的就是MyISAM和InnoDB;
系统文件和日志:负责将数据库的数据和日志存储在文件系统之上,并完成与存储引擎的交互,是文件的物理存储层。主要包含日志文件,数据文件,配置文件,pid 文件,socket 文件等
二、MySQL运行机制
其实可以理解成一个一条sql语句的执行过程。
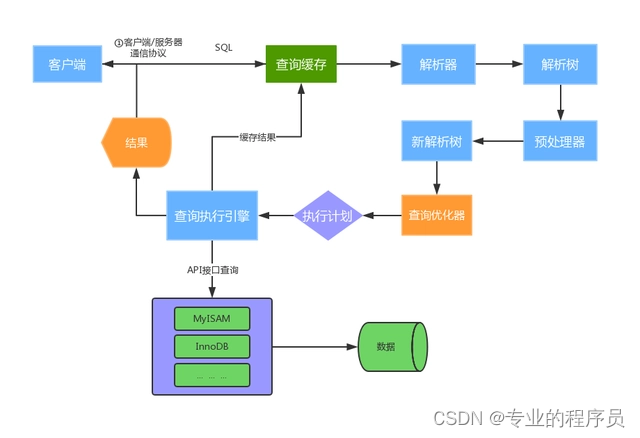
1、通过数据连接把一条sql语句传输到服务端;
2、首先要查询缓存,如果有缓存结果就直接返回了,如果没有就进入sql解析,sql解析要把sql变成一个解析树,这个过程还包括了一个预处理,就是检查sql语句是否正确,表是否存在,字段是否存在等等,最生成一课解析树给到查询优化器。(什么是解析树,比如select )
3、根据“解析树”生成最优的执行计划,这里会对解析树进行一些变换,加快执行引擎的处理速度。
4、查询执行引擎负责执行 SQL 语句,这里最终还是会从磁盘中拉取数据;
三、InnoDB和MyISAM对比
哈,又是一个常见的八股文问题,说实话,我也没用过MyISAM,怎么对比呢?这里我们要简答的了解一下InnoDB和MyISAM的架构区别。
架构区别
-
事务和外键 InnoDB支持事务和外键,具有安全性和完整性,适合大量insert或update操作 MyISAM不支持事务和外键,它提供高速存储和检索,适合大量的select查询操作
-
锁机制 InnoDB支持行级锁,锁定指定记录。基于索引来加锁实现。 MyISAM支持表级锁,锁定整张表。
-
索引结构 InnoDB使用聚集索引(聚簇索引),索引和记录在一起存储,既缓存索引,也缓存记录。 MyISAM使用非聚集索引(非聚簇索引),索引和记录分开。
-
并发处理能力 MyISAM使用表锁,会导致写操作并发率低,读之间并不阻塞,读写阻塞。 InnoDB读写阻塞可以与隔离级别有关,可以采用多版本并发控制(MVCC)来支持高并发
-
存储文件 InnoDB表对应两个文件,一个.frm表结构文件,一个.ibd数据文件。InnoDB表最大支持64TB; MyISAM表对应三个文件,一个.frm表结构文件,一个MYD表数据文件,一个.MYI索引文件。从MySQL5.0开始默认限制是256TB。
适用场景
MyISAM:不需要事务支持(不支持),并发相对较低(锁定机制问题),数据修改相对较少,以读为主,数据一致性要求不高
InnoDB:需要事务支持(具有较好的事务特性),行级锁定对高并发有很好的适应能力,数据更新较为频繁的场景,数据一致性要求较高。硬件设备内存较大,可以利用InnoDB较好的缓存能力来提高内存利用率,减少磁盘IO
这里肯定有人问了,既然InnoDB啥都有,我为什么要用MyISAM呢?我们要看到MyISAM最大的优点是高速存储和检索,那么对于某些对数据一致性要求不高且写入后基本不变的场景,可以选择MyISAM当做数据中心。那么哪些场景算是这种场景呢?其实有很多,比如工业领域内记录某台机器的震动频度,比如每秒钟记录一次,目的就是监控震动的曲线监控,并为了后面大数据功能做准备。这里首先比如少了几秒的记录没关系,写入后也不可能改了,但是数据量很大,且查询频度高,就可以选择MyISAM。当然实际上获取有很多别的数据库可供选择。
四、InnoDB存储结构
InnoDB引擎架构如下:
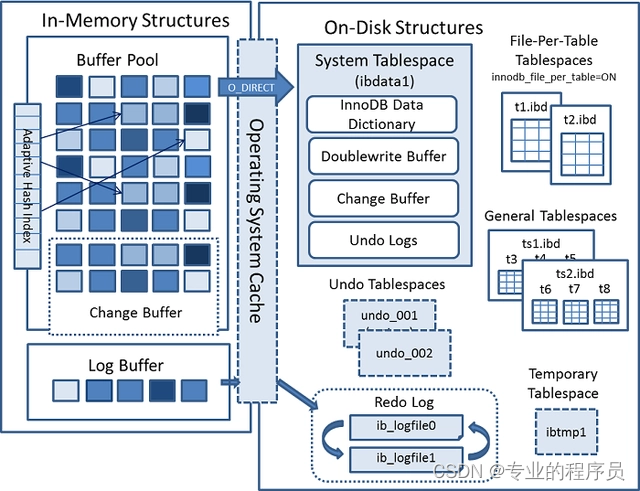
内存结构主要包括Buffer Pool、Change Buffer、Adaptive Hash Index和Log Buffer四大组件。
Buffer Pool:缓冲池,简称BP。BP以Page页为单位,默认大小16K,BP的底层采用链表数据结构管理Page。在InnoDB访问表记录和索引时会在Page页中缓存,以后使用可以减少磁盘IO操作,提升效率。
Change Buffer:写缓冲区,简称CB。在进行DML操作时,如果BP没有其相应的Page数据,并不会立刻将磁盘页加载到缓冲池,而是在CB记录缓冲变更,等未来数据被读取时,再将数据合并恢复到BP中。ChangeBuffer占用BufferPool空间,默认占25%,最大允许占50%,可以根据读写业务量来进行调整。参数innodb_change_buffer_max_size;当更新一条记录时,该记录在BufferPool存在,直接在BufferPool修改,一次内存操作。如果该记录在BufferPool不存在(没有命中),会直接在ChangeBuffer进行一次内存操作,不用再去磁盘查询数据,避免一次磁盘IO。当下次查询记录时,会先进性磁盘读取,然后再从ChangeBuffer中读取信息合并,最终载入BufferPool中。
Adaptive Hash Index:自适应哈希索引,用于优化对BP数据的查询。InnoDB存储引擎会监控对表索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应。InnoDB存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。
Log Buffer:日志缓冲区,用来保存要写入磁盘上log文件(Redo/Undo)的数据,日志缓冲区的内容定期刷新到磁盘log文件中。日志缓冲区满时会自动将其刷新到磁盘,当遇到BLOB或多行更新的大事务操作时,增加日志缓冲区可以节省磁盘I/O。LogBuffer主要是用于记录InnoDB引擎日志,在DML操作时会产生Redo和Undo日志。LogBuffer空间满了,会自动写入磁盘。可以通过将innodb_log_buffer_size参数调大,减少磁盘IO频率innodb_flush_log_at_trx_commit参数控制日志刷新行为,默认为1
-
0 : 每隔1秒写日志文件和刷盘操作(写日志文件LogBuffer-->OS cache,刷盘OScache-->磁盘文件),最多丢失1秒数据
-
1:事务提交,立刻写日志文件和刷盘,数据不丢失,但是会频繁IO操作
-
2:事务提交,立刻写日志文件,每隔1秒钟进行刷盘操作
InnoDB磁盘结构
包含Tablespaces,InnoDB Data Dictionary,Doublewrite Buffer、Redo Log和Undo Logs。
Tablespaces:表空间,用于存储表结构和数据。表空间又分为系统表空间、独立表空间、通用表空间、临时表空间、Undo表空间等多种类型;
Data Dictionary:数据字典,由内部系统表组成,这些表包含用于查找表、索引和表字段等对象的元数据。元数据物理上位于InnoDB系统表空间中;
Doublewrite Buffer:位于系统表空间,是一个存储区域。在BufferPage的page页刷新到磁盘真正的位置前,会先将数据存在Doublewrite 缓冲区。如果在page页写入过程中出现操作系统、存储子系统或mysqld进程崩溃,InnoDB可以在崩溃恢复期间从Doublewrite 缓冲区中找到页面的一个好备份。在大多数情况下,默认情况下启用双写缓冲区,要禁用Doublewrite 缓冲区,可以将innodb_doublewrite设置为0。
Redo Log:重做日志是一种基于磁盘的数据结构,用于在崩溃恢复期间更正不完整事务写入的数据。MySQL以循环方式写入重做日志文件,记录InnoDB中所有对Buffer Pool修改的日志。当出现实例故障(像断电),导致数据未能更新到数据文件,则数据库重启时须redo,重新把数据更新到数据文件。读写事务在执行的过程中,都会不断的产生redo log。默认情况下,重做日志在磁盘上由两个名为ib_logfile0和ib_logfile1的文件物理表示。
Undo Logs:撤消日志是在事务开始之前保存的被修改数据的备份,用于例外情况时回滚事务。撤消日志属于逻辑日志,根据每行记录进行记录。撤消日志存在于系统表空间、撤消表空间和临时表空间中。
五、日志文件
Undo Log
Undo log顾名思义就是已撤销为目的,返回某个指定状态的操作。
Undo log:数据库事务开始之前,会将要修改的数据写入到undo log日志中,当事务回滚或者事务崩溃的时候,可以利用Undo log将数据恢复到事务开始前的情况;
Undo Log产生和销毁:Undo Log在事务开始前产生;事务在提交时,并不会立刻删除undo log,innodb会将该事务对应的undo log放入到删除列表中,后面会通过后台线程purge thread进行回收处理;
Undo log的内容:一般是相反的日志,比如执行一条insert,就写入一条delete,执行一条update,记录一条相反的update;
Undo log的存储:采用段的方式管理和记录。在innodb数据文件中包含一种rollback segment回滚段,内部包含1024个undo log segment。
Undo log的作用:主要为了实现Mysql的原子性;
Redo Log
Redo log就是重做日志,用于数据库崩溃后的数据恢复。
Redo log写入机制:为了实现事务的持久性而出现的产物。Redo log有很多个,以顺序循环的方式写入,所有的有写满了,就回到第一个文件,覆盖写入。每个InnoDB存储引擎至少有1个重做日志文件组(group),每个文件组至少有2个重做日志文件,默认为ib_logfile0和ib_logfile1。
Redo Buffer 持久化到 Redo Log 的策略,可通过 Innodb_flush_log_at_trx_commit 设置:
-
0:每秒提交 Redo buffer ->OS cache -> flush cache to disk,可能丢失一秒内的事务数据。由后台Master线程每隔 1秒执行一次操作。
-
1(默认值):每次事务提交执行 Redo Buffer -> OS cache -> flush cache to disk,最安全,性能最差的方式。
-
2:每次事务提交执行 Redo Buffer -> OS cache,然后由后台Master线程再每隔1秒执行OS cache -> flush cache to disk 的操作。
一般建议选择取值2,因为 MySQL 挂了数据没有损失,整个服务器挂了才会损失1秒的事务提交数据。
Binlog日志
Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志,不会记录SELECT和SHOW这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。开启Binlog日志有以下两个最重要的使用场景。
-
主从复制:在主库中开启Binlog功能,这样主库就可以把Binlog传递给从库,从库拿到Binlog后实现数据恢复达到主从数据一致性。
-
数据恢复:通过mysqlbinlog工具来恢复数据。
文件记录模式
STATEMENT、ROW和MIXED三种。
-
ROW(row-based replication, RBR):日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。 优点:能清楚记录每一个行数据的修改细节,能完全实现主从数据同步和数据的恢复。 缺点:批量操作,会产生大量的日志,尤其是alter table会让日志暴涨。
-
STATMENT(statement-based replication, SBR):每一条被修改数据的SQL都会记录到master的Binlog中,slave在复制的时候SQL进程会解析成和原来master端执行过的相同的SQL再次执行。简称SQL语句复制。 优点:日志量小,减少磁盘IO,提升存储和恢复速度 缺点:在某些情况下会导致主从数据不一致,比如last_insert_id()、now()等函数。
-
MIXED(mixed-based replication, MBR):以上两种模式的混合使用,一般会使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择写入模式。
Redo Log和Binlog区别
1、Redo log是innoDB下的,Binlog是全局的。
2、Redo log属于物理日志,记录该数据页更新状态内容,Binlog是逻辑日志,记录更新过程。
3、Redo log是循环写入,会覆盖,Binlog是追加写入,不会覆盖
4、Redo log是用于服务崩溃后恢复,Binlog为了主从复制还有启动后的数据恢复。















 5512
5512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









