






 文章介绍了仿射映射量化作为解决数据量化过程中数据分布不均匀和不对称问题的方法。通过设定零点z和量化步长s,将实数d映射到整数q,确保量化点与原始数据分布尽可能重合。在高斯分布的例子中,展示了如何根据数据的均值和方差选择合适的量化范围和参数。
文章介绍了仿射映射量化作为解决数据量化过程中数据分布不均匀和不对称问题的方法。通过设定零点z和量化步长s,将实数d映射到整数q,确保量化点与原始数据分布尽可能重合。在高斯分布的例子中,展示了如何根据数据的均值和方差选择合适的量化范围和参数。
仿射映射量化

利用定点数格式近似表示浮点数的过程可以看做对原始数据的“量化”或者“稀疏化”过程。
仿射映射量化解决待量化数据和数据量化表示范围不匹配问题
利用定点数能够表达的数据在数轴上离散均匀分布,并且中心在0处,如下图S1.2定点数格式能够表达的数据在数轴上的位置,相邻2个量化数据对应的数值间隔固定为0.25,能够表示的数据范围为[-2, 1.75]。

实际上应用中会遇到需要量化的数据分布非中心对称,对称点不为0,并且可能不是均匀分布的情况,这时我们希望量化的结果能够和数据匹配,即量化数对应的“离散点”能够覆盖量化数据的数值范围
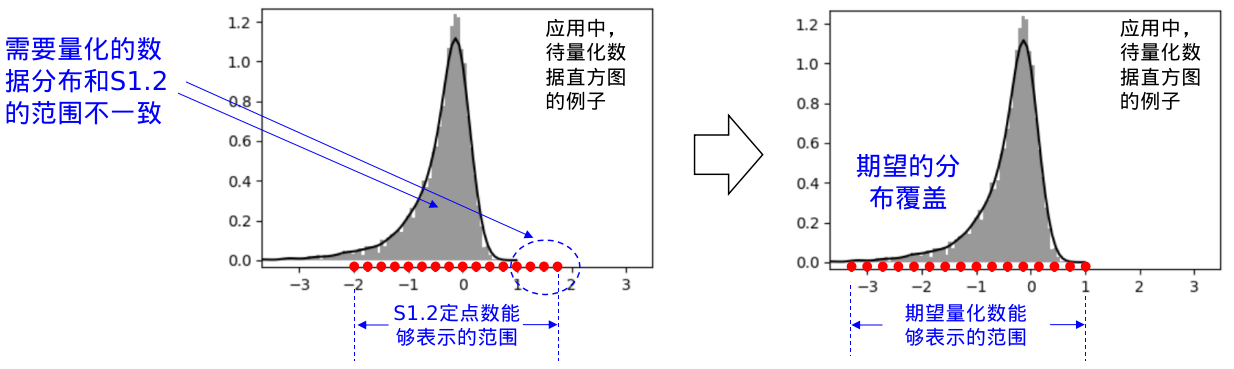
为了能让量化数据对应的量化点和需要量化的原始数据分布区间尽可能重合,我们可以使用仿射映实现量化
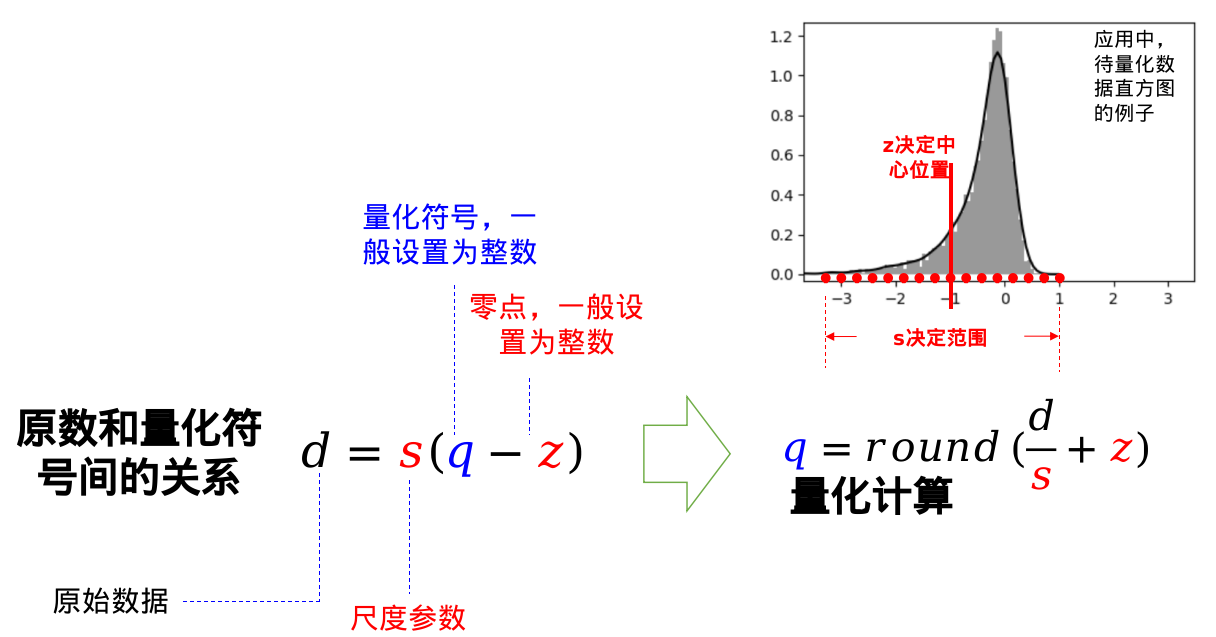
d = s ( q − z ) d = s(q - z) d=s(q−z)
其中,d 是实数,q是整数,是d的量化表示,z 是零点,代表实数0的量化表示,通常也用整数表示,s 是量化步长,代表上述量化数能够表示的两个实数数值的最小间隔。
根据实数求量化数q
仿射映射量化过程就是根据 (s,z)计算量化符号q, 使得 s(q - z) 和 d 最接近,具体算法如下
q
=
r
o
u
n
d
(
d
s
+
z
)
q = round(\frac{d}{s}\ + z)
q=round(sd +z)
代码为:
QMIN,QMAX=0,255 # 量化表示的最大最小值
## 数据量化,计算:dq=round(d/s+z)
def calc_quant_data(d,s,z):
dq=d/s+z
dq=np.round(np.clip(dq,QMIN,QMAX)).astype(int)
return dq
代码中QMIN, QMAX是量化符号q能够表达的整数范围,比如q 为 16位整数时 Q M I N = − 2 15 QMIN = -2^{15} QMIN=−215
Q M A X = 2 15 − 1 QMAX = 2^{15} - 1 QMAX=215−1
根据d 和 q 的范围求 (s, z)
s = d m a x − d m i n q m a x − q m i n s = \frac{d_{max} - d_{min}}{q_{max} - q_{min}} s=qmax−qmindmax−dmin
z = r o u n d ( q m i n − d m i n s ) z = round(q_{min} - \frac{d_{min}}{s}) z=round(qmin−sdmin)
其中 round 指四舍五入取整。
Example:
某个训练得到的卷积神经网络的卷积核数据直方图如下
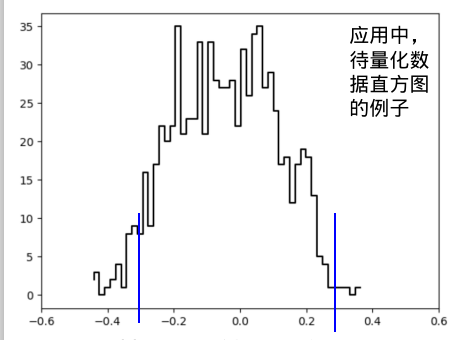
计算它的方差和均值,并用高斯分布近似。
是上述是数据对应的均值μ = -0.02654, 方差 σ = 0.1539。可以选择仿射映射量化方案覆盖 [μ - 2σ, μ + 2σ]取值范围,实际范围为[-0.334, 0.281],并用8位整数表示量化符号q
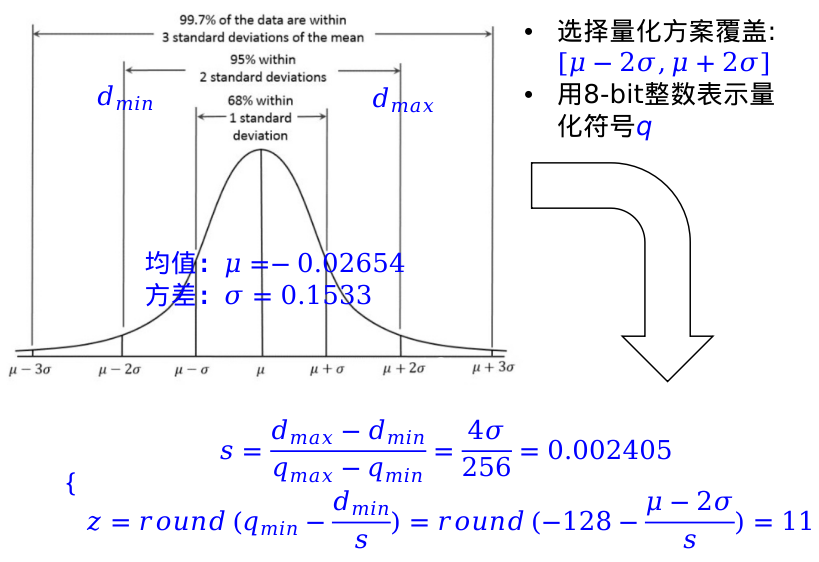
根据 d = s(q - z)计算出来该量化方案实际能够表示的数值范围:
最小值:=s(−128−z)=−0.3343
最大值:=s(127−z)=0.2790
这里最大值存在偏差,因为8位整数q能够表达的整数个数比负数少1
def gauss_quant(data,n=1,qmin=-128,qmax=127):
print('[INF] Gaussian quant')
sigma=np.std(data.flatten())
mu=np.mean(data.flatten())
print('[INF] mean:',mu)
print('[INF] var:',sigma)
dmax,dmin=mu+sigma*n,mu-sigma*n
print('[INF] (dmin,dmax):',(dmin,dmax))
sd=(dmax-dmin)/(qmax-qmin)
zd=np.round(qmin-dmin/sd)
print('[INF] (sd,zd):',(sd,zd))
print('[INF] (vmin,vmax):',(sd*(qmin-zd),sd*(qmax-zd)))
return sd,zd
对于高斯分布,选择区间,对应不同的覆盖范围:
- [μ - σ, μ + σ]:覆盖68.3%数据
- [μ - 2σ, μ + 2σ]:覆盖95.4%数据
- [μ - 3σ, μ + 3σ]:覆盖99.7%数据
欢迎关注公众号【三戒纪元】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









