









关于决策树
- 决策树是随机森林的基本组成单位,随机森林是由很多的树组成的。
- 决策树的作用就是在特征条件中 划分信息熵最高的
信息熵: 能提供最大不确定性的条件,如有所有同学中有两个条件,男和女,打游戏和不打游戏,
明显:男和女是最能减少不确定性的条件
香龙在文中指出,它的准确信息量应该是:
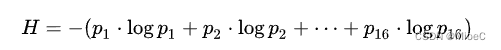
其中[公式]表示以2为底的对数, p1, p2, p3为每个条件的概率。
对于一个随机的变量X, 他的信息熵应该是
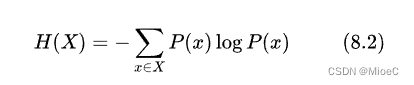
如我们的二分类问题, p(x) = p1 p(y) = 1-p1 其中, 0<p1<1
所以,Hx = -(p1logp1 + (1-p1)log(1-p1)
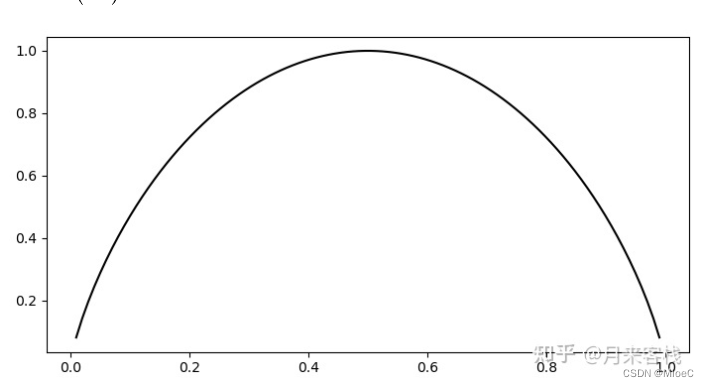
我们可以画出函数的图像,看的出来, 在0.5的时候, 熵取到最大
也就是说此时的不确定性最大,要把这件事搞清楚所需要的信息量也就越大。并且这也很符合我们的常识,例如“明天下雨和不下雨的概率都是50%”,那么这一描述所存在的不确定性是最大的
条件熵
条件熵就是在特定条件下,减少信息熵的条件,如,引入某个条件,如所有男女中,引入条件-身高180的人,可以减少特定的人群, 这叫部分条件熵, 而引入条件,身高120以上的, 就属于完全条件熵,
则
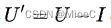
信息增益
在引入特定条件后,能使得目前的不确定性,即u的数值达到最大,那这就是最大信息增益。
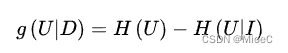
三种决策方式已经讲解完毕了, 接下来就是在树每次划分时,采用最大信息熵的方式进行划分,达到最优决策树。
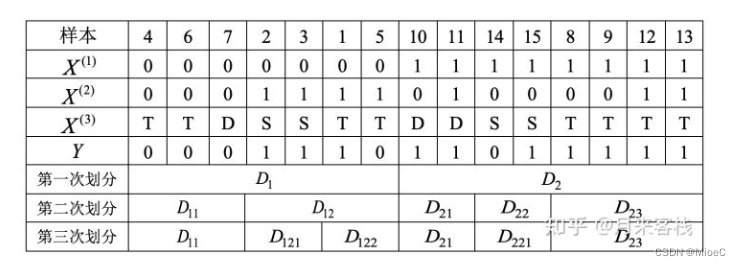
实例
接下来看个实例用来计算三个熵
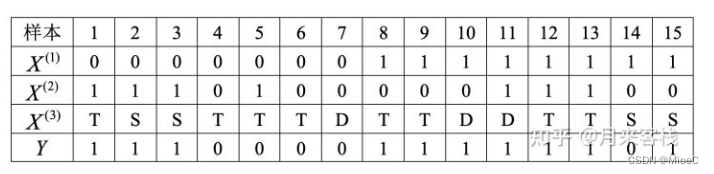
其中,x1表示是否有房, x2表示是否有工作, x3表示学历条件,Y是预测结果, 表示是否通过贷款申请。
熵的计算
Hy = - (5/15log5/15 + 10/15log10/15) = 0.918
条件熵的计算:
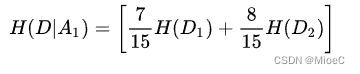
Hy|x1 = - (7/15 (3/7log3/7+ 4/7log4/7) - 8/15(1/8log1/8 +7/8log7/8) = 0.75
Hy|x2 = -8/15(4/8log4/8 +4/8log4/8) - 7/15(6/7log6/7 + 1/7log1/7) = 0.81
Hy|x3 = -8/15(5/8log5/8 + 3/8log3/8) - 4/15(3/4log3/4 + 1/4log1/4) - 3/15(2/3log2/3 + 1/3log1/3) = 0.91
则条件熵信息增益分别为
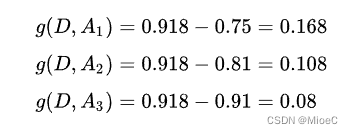
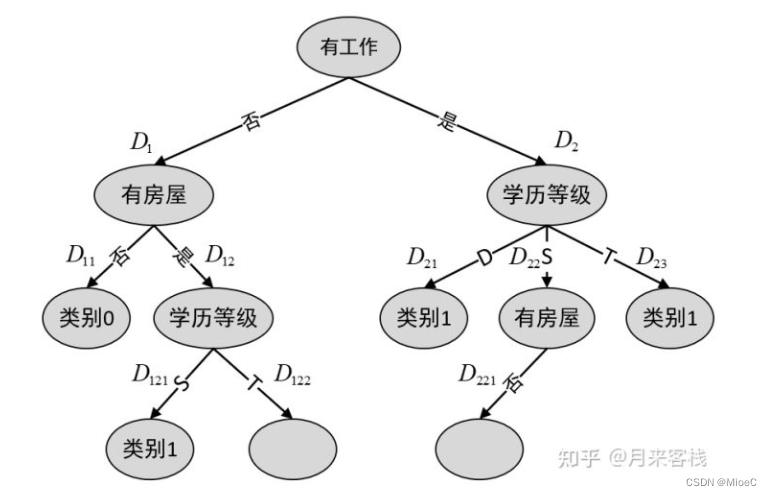
ID3算法
每次都以最大信息增益熵为划分依据,
第一次以A1为条件进行划分
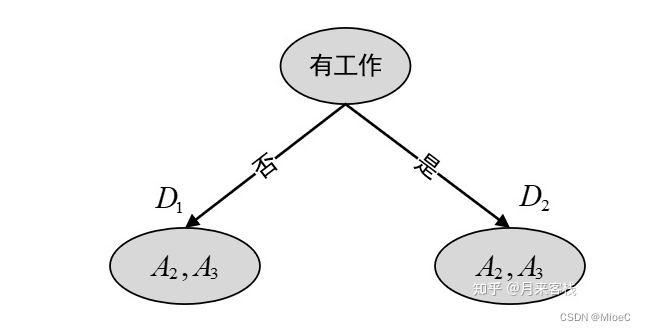
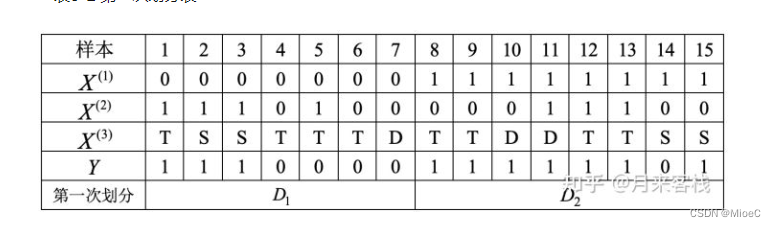
划分完再次计算信息熵
如HD1|A2 = -3/7(3/3log3/3 + 0) - 4/7(1/4log1/4 + 3/4log3/4) = 0.464
HD1|A3 = -3/7(1/3log1/3 +2/3log2/3) - 4/7(1/4log1/4+3/4log3/4) = 0.464
所以划分不妨以A2进行划分
而D2的熵增益为
HD2|A2 = -5/8(4/5log4/5 + 1/5log1/5) - 3/8 * 0 = 0.451
HD2|A3 = - 4/8(4/4log4/4 + 0 ) - 2/8(0) - 2/8(1/2log1/2 + 1/2log1/2) = 0.25
所以再次划分
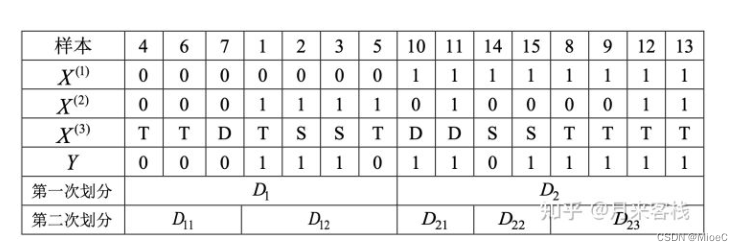
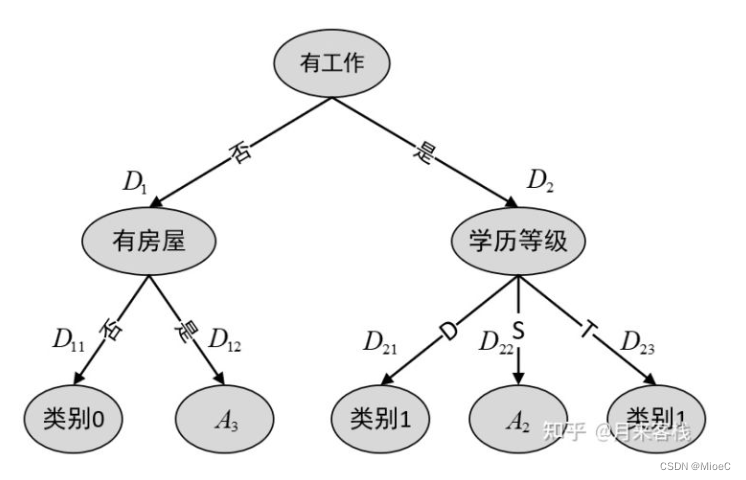
继续按条件划分
缺点:由于每次划分都选择最大信息量进行划分,所以很快就划分完毕,并且容易产生特征偏差,即一个子树都是A2的情况,容易产生又矮又胖的情况, 产生过拟合现象。所以还有另一种划分方式。下面将介绍C4.5的划分 方式
C4.5 即在原本划分的方式上, 将节点划分方式改成增益比的方式进行划分,即
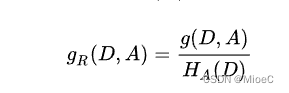
下篇将 介绍如何用python 的sklearn 方法实现决策树并进行可视化
















 1835
1835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











