






背景
本文翻译自Best practices for caching in Spark SQL,该文章也是对学习spark SQL逻辑计划的同学应该关注的很好的细节点
译文
深入理解spark的数据持久化
David Vrba 2020.7.20
在spark sql中,数据缓存是重利用计算的一种常见的技术,通过复用同一种数据,能够加速查询,但是如果想实现性能优化,这里也有些应该注意的细节。在这篇文章中,我们来分析一下spark 缓存内部的运行机制,揭开跟spark数据持久化的神秘面纱
使用DataFrame API
在DataFrame API中,有两种函数能够用于缓存一个dataframe,cache()和persis()
df.cache() #see in pyspark docs
df.persist()
他们几乎是相等的,不同的是persist有个可选的参数storageLevel,该参数可以指定数据存储在哪里,默认情况下是MEMORY_AND_DISK,数据先会存储在内存中,如果内存满了,将会存储到磁盘,这里可以查看其他的存储级别
缓存是一种延迟的transformation,因此调用该函数什么都不会改变,但是改逻辑计划会增加一种操作-InMemoryRelation,所以只有当其他的action被调用的时候,这个InMemoryRelation才会被query exection用到,如果对应的数据存在,spark将会从缓存层读取。如果读取不到,则spark会缓存该数据,以便后续操作复用。
Cache Manager
Cache manager用来追踪记录对于当前查询计划哪些计算已经被缓存了。当缓存函数被调用的时候,Cache Manager被直接调用,并且把被调用的dataFrame从逻辑计划中脱离出来,从而储存在名为cachedData的顺序结构中
cache manager阶段是逻辑计划的一部分,作用在sql分析器之后,sql优化器之前。
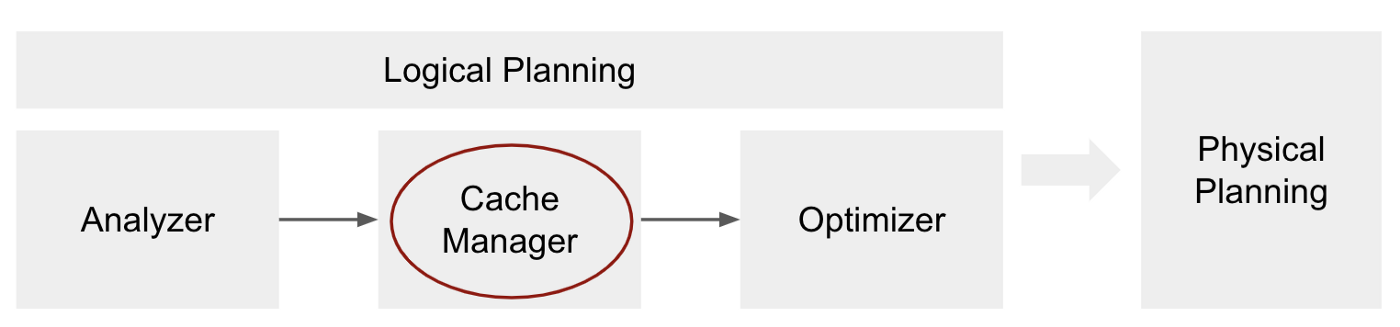
当我们触发一个query的时候,查询计划将会被处理以及转化,在处理到cachemanager阶段(在优化阶段之前)的时候,spark将会检查分析计划的每个子计划是否存储在cachedData里。如果存在,则说明同样的计划已经被执行过了,所以可以重新使用该缓存,并且使用InMemoryRelation操作来标示该缓存的计划。InMemoryRelation将在物理计划阶段转换为InMemoryTableScan
df = spark.table("users").filer(col(col_name) > x).cache
df.count() # now check the query plan in Spark UI
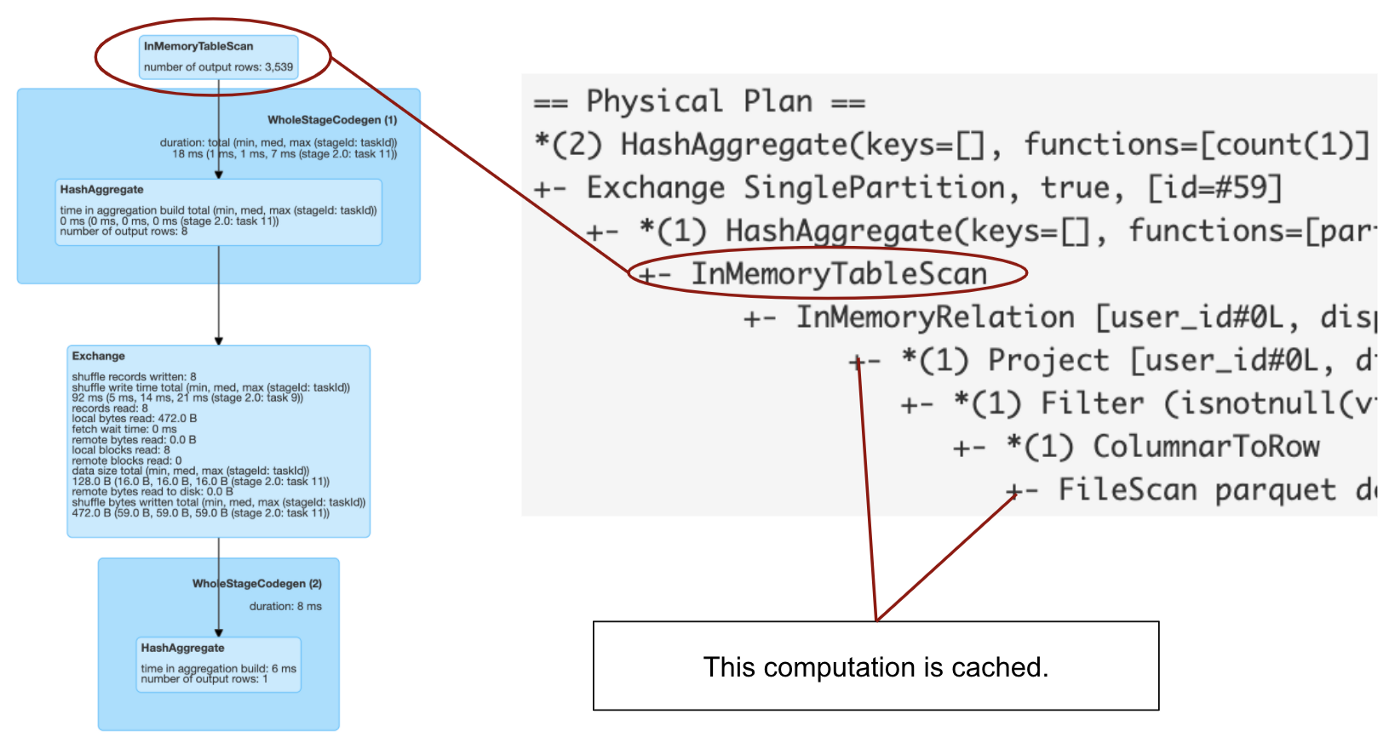
从以上图片我们看到一个使用缓存的图形字符代表的查询。为了能够看到是什么转换被缓存,你需要进一步查看一下该计划的字符串,因为从图形表示并不能看出什么
Basic example
我们来用一个例子更好的理解Cache Manager的工作原理:
df = spark.read.parquet(data_path)
df.select(col1, col2).filer(col2 > 0).cache()
看一下下面三种查询,那个语句将会复用缓存数据:
1) df.filter(col2 > 0).select(col1, col2)
2) df.select(col1, col2).filter(col2 > 10)
3) df.select(col1).filter(col2 > 0)
最主要的因素是分析计划。如果和缓存的分析计划是一致的话,对于语句1,你可能会说该计划和缓存的计划是一致的,因为filter会被优化器下推。但是实际这个解释是不精确的。有一点很重要,那就是Cache Manager阶段发生在优化器之前,优化之后的计划可能一样,但是分析计划不一样,所以对于语句1来说是不会复用缓存的,因为分析计划不一样
对于语句2,你可能又要说会复用,因为该filter比缓存语句的filrer限制更严格。我们看看缓存的查询数据,因为分析计划不一样,所以spark也不会复用改查询数据,因为这次是过滤条件不一样,如果想要使用查询的数据,我们做一下修改:
df.select(col1, col2).filter(col2 > 0).filter(col2 > 0)
咋一看,col2 > 0的过滤条件似乎没用,但是该部分分析计划和缓存的计划是相等的,所以Cache Manager能够使用InMemoryRelation

对于查询语句3,咋一看好像和缓存的分析计划也是不一样的,因为查询语句都不一样–我们只查询了col1列。过滤条件使用的是col2,而该col1列并不在查询语句中,因此分析器将会调用ResolveMissingRefecences规则,就会将col2增加到查询语句中,因此语句3最终的分析计划和缓存的计划是一样的,所以会复用缓存计划
Best practices
我们列举了一些跟缓存相关的准则:
- 当缓存一个DataFrame的时候,创建一个新的变量cacheDF = df.cache()。这个将会避开我们刚才所说的那个问题,有时候分析计划并不是很直观,并不知道实际缓存计划是什么。当你调用cacheDF.select(…),他就会复用改缓存的数据
- 使用cacheDF.unpersist()释放不用的缓存的计划。如果缓存层满了的话,spark将会使用最近最少使用的原则进行驱逐数据。因此使用unpersist()去控制哪些数据应该被驱逐是推荐的选项,当然,内存剩余空间越大,spark能使用的计算内存就越大,如构建hash maps 等等
- 在缓存之前,确保只缓存你需要的部分数据,例如,假如第一查询中将使用(col1, col2, col3),第二个查询将使用(col2, col3, col4).选择这些列的超集:cacheDF = df.select(col1, col2, col3, col4).cache()。 而如果是调用cacheDF = df.cache(),且df包含了很多列,这样的话就只有小部分列被用到,这样就不是很有效率
- 使用有意义的缓存,也就是说缓存的计算能够被使用多次,因为把缓存的计算放到内存中会涉及到overhead,所以在某些场景下,就如以下会提到的,重新跑计算可能更快
Faster than caching
某些情况下,缓存并不能提高效率,反而会降低执行的效率。这是跟是否是基于大数据集的列文件格式有关的,这些支持列裁剪以及谓词下推,如parquet格式。我们举例如下,我们缓存了整个数据集,然后进行查询,我们使用如下的数据以及集群配置:
dataset size: 14.3GB in compressed parquet sitting on S3
cluster size: 2 workers c5.4xlarge (32 cores together)
platform: Databricks (runtime 6.6 wit Spark 2.4.5)
首先,我们测试一下没有缓存下的执行时间:
df = spark.table(table_name)
df.count() # runs 7.9s
df.filter(col("id") > xxx).count() # runs 18.2s
现在,使用缓存运行同样的查询(整个数据并不缓存在内存中,30%的缓存在磁盘)
df = spark.table(table_name).cache()
# this count will take long because it is putting data to memory
df.count() # runs 1.28min
df.count() # runs 14s
df.filter(col("id") > xxx).count() # runs 20.6s
第一次count() 花费了1.3min,因为这里有把数据放进内存的开销。然而,第二个conut()和带有过两次的count()花费了比不带缓存的更长的时间。这主要有两个原因:第一个是parquet文件的属性–基于parquet top的查询比基于自身要快。在读parqut的时候,spark将只会读取文件的元数据而去得到count的值,而不需要去遍历整个数据集。对于带有过滤的查询,spark将会使用列裁剪,只会遍历id列。而当我们从缓存中读取数据的时候,spark将会读取整个数据集。这可以从spark ui上可以看到。
第二个原因是数据集很大,并不是全部在RAM中,部分数据储存在磁盘,从磁盘读取数据比从RAM中慢很多
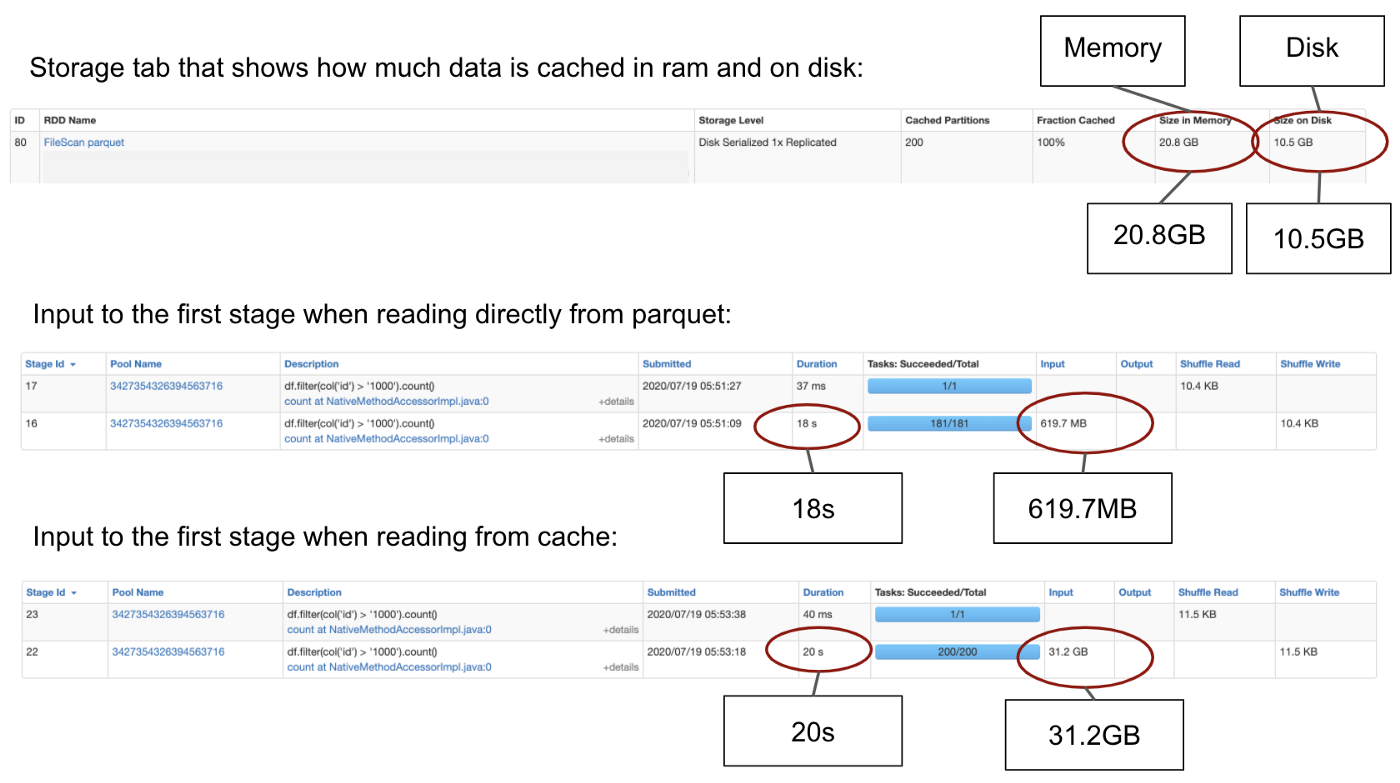
Caching in SQL
如果你更倾向于使用sql而不是DataFrame DSL的话,你仍然可以使用缓存,但是这个是有不同的:
spark.sql("cache table table_name")
最主要的不同点在于使用sql进行缓存是立马执行的。但是我们可以使用lazy关键字:
spark.sql("cache lazy table table_name")
如果要移除缓存,仅仅如下调用:
spark.sql("uncache table table_name")
See the cached Data
有时候,你想只要到是否数据已经被缓存了。一个方法是查看Spark UI,这上面提供了集群级别缓存的基本信息:
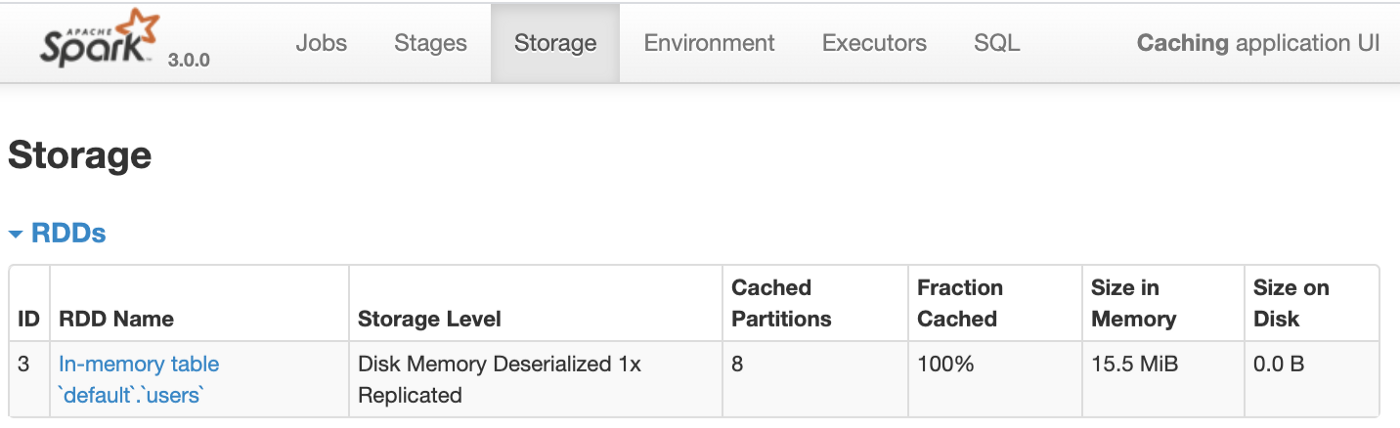
图中每一个缓存的数据集,可以看到内存和磁盘中分别占用多少,甚至你可以点击表记录,查看每个分区的细节信息。
我们可以通过如下语句查看是否真个表被缓存了:
spark.catalog.isCache("table_name")
也可以移除缓存中的所有数据:
spark.catalog.clearCache()
scala API 中,你可以使用cache Manager的内部函数,如查询是否cache Manager为空:
// In scala API
val cm = spark.sharedState.cacheManager
cm.isEmpty
Other Possibilities for data persisitence
缓存对于计算复用是一项很重要的技术,除了缓存,也有checkpointing和exchange复用
checkpointing在由于数据太大需要中断的场景下是很有用的。大的查询计划可能成为driver端的瓶颈。因为大的计划将会跨度很大的时间,checkpoint将会中断该计划,并且进行物化该查询。对于下一次转化,spark将会构建新的计划。checkpointing主要跟两个函数有关:checkpoint和localCheckpoint,两者在数据存储上是不同的:
exchange-reuse用在spark持久化shuffle 磁盘输出的,是内部特性,不直接受api函数的控制的,在一些特殊的场景下,能够通过重写查询来进行间接的控制,查看这篇文章,这里描述的很细致。















 3516
3516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









