







计算机只能识别0,1;ASCII编码中 默认最大8bit (1111111即最大255);远不够老美以外其他国家的使用;
中国添加了GB2312,其他国家也设计了自己的编码格式;于是各有自己标准就造成了混乱局面,Unicode诞生;
Unicode(16bit 还是32bit不确定,总之足够大了),可以满足各个国家语言加起来使用。弊端就是unicode编码占用存储空间更大了,不过有一点好处,一样的长度可以在内存中处理更加简单;utf-8可变长编码,解决了存储空间占用大的问题,但是在内存中处理不如unicode方便。
python在内存中使用unicode编码。
py2测试
C:\Users\houyang>python
Python 2.7.13 (v2.7.13:a06454b1afa1, Dec 17 2016, 20:42:59) [MSC v.1500 32 bit (
Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> s = 'wo爱你'
>>> s.encode('utf-8')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xb0 in position 2: ordinal
not in range(128)
>>> su = u'wo爱你'
>>> su.encode('utf-8')
'wo\xe7\x88\xb1\xe4\xbd\xa0'
>>> s.decode("gb2312").encode("utf-8")
'wo\xe7\x88\xb1\xe4\xbd\xa0'
>>>
总结:python2 调用encode('utf-8')前,编码必须转为unicode;
可以在字串前加u,也可以先decode(decode按xx解码;encode:按xx编码)
注意:在windows下 decode("gb2312"),但在linux下应该是decode("utf8")后再encode
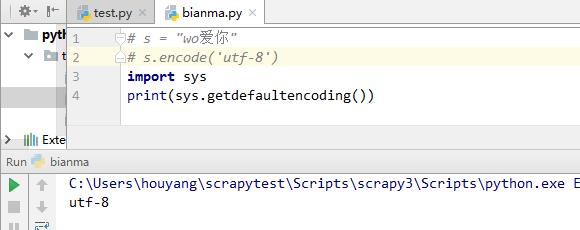
s = "wo爱你"
s.encode('utf-8')
上述代码在python3中可以直接执行成功,在代码开头也无需指定utf-8编码,py3默认全都采用了unicode编码,所以可以直接encode直接使用.encode是采用默认编码,可以查看py2的默认编码如下:
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
默认是ascii,所以出现中文时在解释器中默认识别不了,所以py2老在第一行指定 #-*-coding:utf-8-*-py3的默认编码如下:
自己总结的,有误的地方,欢迎指正














 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









