






翻译: 默难 ( monnand@gmail.com ). DriftingLeaves ( driftingleaves@yahoo.com )
原文参见: http://citeseer.ist.psu.edu/zhang05coolstreamingdonet.html
本文其他部分参见: http://blog.csdn.net/monnand/category/261378.aspx
摘要 ( 本节翻译: DriftingLeaves )
本文描述了 DONet - - - 一种用于流媒体的数据驱动网络. DONet 的核心操作非常简单 : 每一个结点与一组伙伴周期性地交换数据可用性信息, 从一个或多个伙伴那里接收自己所没有的数据, 并把自己所拥有的数据提供给需要的伙伴. 我们将着重分析这种数据驱动设计的三种突出特性:(1) 易于实现, 它不需要构建或维护一个复杂的全局结构; (2) 高效,数据的传递方向是依照数据的可用性信息而动态改变的, 而不是被限制在特定的方向上; (3) 健壮, 允许结点的伙伴关系在众多提供者中作出适应变化的快速转换. 这篇文章将会通篇分析 DONet 在有限延迟下的可扩展性, 而且也会考虑到实现 DONet 时所面临的一些实际挑战, 并在此基础上提出一个有效的成员关系和伙伴关系管理算法, 以及一个能完成实时且连续播放流内容的智能调度算法.
通过 Planetlab 已经在大范围内评估了 DONet 的性能. 这些实验几乎包括了 Planetlab 的所有有效结点. 实验结果表明 DONet 甚至能够在复杂的网络条件下达到很好的流质量. 此外, 控制所带来的额外开销和传输延迟都可以保持在很低的水平上.
在2004年5月30日, 一个基于Internet 的 DONet 的实现 - - - CoolStreaming v.0.9发布了. 它已经吸引了超过30000的用户并且在一些高峰时间创下了4000人同时在线的记录. 这篇论文将会讨论关于 CoolStreaming 设计的关键问题, 并且描述一些这次大范围测试中的有趣现象. 具体来说, 网络范围越大, 被传送的流的质量将会越好.
I. 概述 ( 本节翻译: DriftingLeaves )
随着宽带接入的普及化, 多媒体服务对用户来说变得日益重要, 并且已经成为今天 Internet 流量的重要组成部分. 许多诸如网络电视, 新闻广播的多媒体应用都涉及到把流媒体从源头传送给大量用户的过程. 对这些应用来说, IP 多播也许是最有效的途径; 然而它的扩展却因为许多现实上的和政治上的因素而受到限制, 例如缺乏动力去安装具有多播能力的路由来承担多播流量. 因此研究者们开始关注应用层上的解决方案 - - - 通过参与者的合作来建立一个在单播通道之外的重叠网络, 这些参与者也被称作重叠网络结点 ( Overlay Node ), 那么在此基础上, 就可以通过结点之间的数据依赖关系, 实现所谓的多播.
作为 IP 多播的替代方案, 开始时许多网络构建算法大多使用树结构来实现数据传递. 虽然这种方案能够像 IP 多播一样, 与专用基础路由 ( Dedicated Infrastructure Routers ) 很好的搭配, 但是却经常会与带有动态结点的应用层网络搭配错误. 而且自主网络结点会轻易地崩溃或离开, 因此树结构是高度易损的. 而这一问题在对带宽和连续性都有很高要求的流传输中, 显得更加严重. 同时虽然像网孔和森林这样的复杂结构能部分地解决问题, 但其本身的实现却过于复杂, 而且经常缺乏可扩展性.
从另一个角度讲, 把多播功能移植到应用层同样会导致更大的弹性; 具体来说, 所有的结点都有很强的缓冲能力并且能够灵活, 智能地决定数据的传输方向. 因此文章中提出了一个以数据为中心的 ( Data-centric ) 设计方案- - - 一个结点总是向那些需要数据的结点传送数据, 而它们之间没有诸如父子关系, 内部外部关系和上行流下行流关系. 换句话说, 是数据的可用性信息引导着数据的流向, 而不是一个特殊的网络结构约束了数据的流向.这种数据中心的设计将会更加适应具有高动态的结点的网络. 尤其是考虑到一个半静态的结构, 无论多么有效, 总是会因为结点的动态而处于次优的状态.
基于这样的目标, 本文描述了DONet - - - 一个数据驱动的重叠网络, 而其中的核心操作非常简单: 每一个结点与一组伙伴周期性地交换数据可用性信息, 从一个或多个伙伴那里接收自己所没有的数据, 并把自己所拥有的数据提供给需要的伙伴. 我们将着重分析这种数据驱动设计的三种突出特性:(1) 易于实现, 它不需要构建并维护一个复杂的全局结构; (2) 高效,数据的传递方向是依照数据的可用性信息而动态改变的, 而不是被限制在特定的方向上; (3) 健壮的, 有弹性的, 允许结点的伙伴关系在众多提供者中作出适应变化的快速转换. 此外, 关于结果的分析显示出了网络半径与网络大小的逻辑关系, 这也说明了 DONet 能够在有限延迟的情况下进行扩展.
为了实现传输实时流媒体的数据驱动网络 , 大量的实际问题需要考虑 . 在本文中 , 将要讨论 DONet 中的若干关键问题 . 包括伙伴关系的建立 , 数据可用性信息的编码和交换 , 以及视频数据是如何在伙伴间被提供和获得的 . 这里将要提出一套可扩展的成员关系和伙伴关系的管理算法和一个智能调度算法 , 这些方案将会在使用较低控制开销的情况下 , 为中高带宽用户提供高效连续的流传输 , 同时平稳地将传输负载分配到正在参与的结点中 , 并使结点与异构网络相适应 .
通过 Planetlab 已经在大范围内评估了 DONet 的性能. 这些实验几乎动用了 Planetlab 跨越五大洲的所有可用结点. 实验结果表明 DONet 在流速率和播放连续性上能达到很高的要求. 此外, 控制所带来的额外开销和传输延迟都可以保持在很低的水平上. 根据当前掌握的材料, 全球范围的实验很少在文献中提及. 为此文章中列出了在实验当中遇到的几个典型问题. 并讨论了影响实验结果和可能在将来影响 PlanetLab 发展的因素.
最后,在2004年5月30日, 一个公开的, 基于Internet 的 DONet 实现 - - - CoolStreaming v.0.9发布了, 它已经能够播放由一个免费视频服务器所提供的实时体育节目, 这个软件最初只吸引了20个用户, 但是截至本文发布, 超过30000的用户 ( 从独立IP的统计上看 ) 已经使用过这个流媒体软件, 在一些高峰时间甚至达到4000多用户同时在线. 先前的统计结果和用户的反馈是十分鼓舞人心的, 这也说明了两个有趣的事实 : 第一, 现在的 Internet 已经有足够的带宽来支持电视质量的数据流 ( 450 Kbps ); 第二, 数据驱动网络越大, 所传送的数据流质量将会越好. 这两点都再一次说明了本文所提出的数据驱动重叠网络是用来解决多播视频分配的可靠方案.
II. 相关工作 ( 本节翻译: DriftingLeaves )
在过去的十年里, 出现过一些基于IP多播视频的重要研究, 可以参考 [18]. 最近,又提出了许多有关网络多播 ( Overlay Multiply System ) 的系统, 它们大体上分为两类: 基于代理协助 ( Proxy-assisted ) 的和基于 P2P 的. 在传统意义上, 通常事先安排一整套服务或应用层上的代理, 然后在这些锚点 ( Anchor Node ) 的协助下建立起一个高质量的网络[1],[2],[24],[26],[28]. DONets属于第二类, 它不依赖于专用结点 ( Dedicated node ) , 但是能在自组织的自动结点 ( Autonomous Nodes ) 的基础之上建立起一个网络. 在这一部分中, 我们将对现行的几种网络流协议作简略介绍, 重点将放在那些完全遵循 p2p 模式的协议上.
A. 基于树结构的网络及其扩展
像前面所提到的, 许多网络流协议采用基于IP多播的树状结构. 在网络结点之间构建并维护一个高效的分布式树结构, 是这类系统的关键. 在CoopNet 中, 视频源作为树结构的根, 收集所有结点的信息, 用于树的构造及维护. 因此集中式的算法将会非常有效. 但这样的作法必须依赖于一个功能强大的专用根结点. 同时, 像 SpreadIt[10], NICE[12]和ZIGZAG[11], 使用分布式算法通过一系列结点, 实现构建和路由功能. 在大规模网络中, 这些算法采用层次聚类 ( Hierarchical Clustering ) 的方式来达到最小的延迟 (从树的高度上讲 ) 或边界结点的工作量 (从扇出度 ( Fanout Degree ) 上讲 ) . 但是, 一个树结构中的内部结点会有较大的负载, 因此它的离开或崩溃, 将会在很大范围内导致后代结点的缓冲区不足. 虽然已经设计出了一些树结构的修复算法来适应结点的动态变化 [12],[11],[23]; 但是树的结构仍会在高动态的网络环境中遭到频繁破坏.
还存在许多用来解决树结构负载不均衡或易损性的其他方案. 例如建立以网孔为基础的树结构 ( Narada 及它的扩展 [14], Bullet [20]) , 维护一个多分布式树结构 ( SplitStream [19]), 或者在分层编码 ( PALS [29]) 和多重描述编码 ( CoopNet [3]) 之间权衡. DONet 通过引入一种简单明了的数据驱动方案, 来弥补这些缺陷. 它并不需要维护一个更复杂的结构, 或者依赖于先进的编码技术, 虽说后一点也会在这个方案中起到一定作用.
B. 以 闲谈 ( Gossip ) 为基础的协议
最近, 闲谈 ( 或传染病 ) 算法已经成为 P2P 系统中信息多播传播的流行解决方案 [13], [22]. 在一个典型的闲谈算法中, 一个结点将新信息发给一组随机选择的结点; 这些结点会在下一轮中作相似的事情, 直到所有结点都收到信息. 闲谈对象的随机选择, 能使系统加强对随机发生的意外退出的弹性, 并且能够进行非中心式的操作. 与 [16] 相似, DONet 的成员管理中使用了闲谈协议. DONet 中的数据传输方法也部分受到闲谈概念的影响. 但无论如何, 不能将闲谈机制直接用于流传输, 因为随机的传送数据会带来大量的冗余, 而这对于有高带宽需求的流应用来说更加严重. DONet 中, 使用了一个有力伙伴的选择算法, 和一个低开销的调度算法, 以便于在大量减少冗余的情况下, 智能地从众多伙伴中接收数据.
先前进行的一些有关 P2P 的请求式流传输 ( 例如, [4], [5], [6], [7], [8], [9]) 的工作与闲谈机制紧密相关, DONet 也是如此. 在这样的机制中, 视频数据由一些种子结点在有异步需求的结点中传播. 同时, 一个或多个结点, 能够一起为一个新结点提供缓冲数据, 并能随着提供者的增多, 增强系统的能力. DONet 的目标是通过半同步的结点, 达到实时流媒体传输, 这就需要不同的解决方法. 然而, 在实际的Internet 实现中, DONet 的能力有很大的增强, 这也证明了那些在 P2P 请求式流传输研究中的论证.
III. DONet的设计与优化 ( 本节翻译: 默难 )
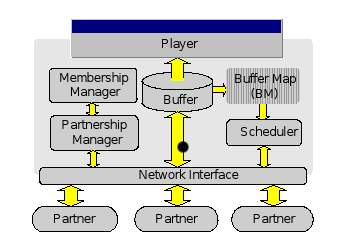
Fig-1 一个DONet结点的系统架构图
Fig-1 是一个 DONet 结点中的系统架构图. 其中有三个重要模块: (1) 成员管理模块 ( Membership Manager ). 负责维护网络中一部分结点的相关信息; (2) 伙伴管理模块 ( Partnership Manager ). 负责与网络中的其他结点建立并维护伙伴关系 ( 译者注: 原文中的``Member''一词此处被翻译为``成员''; ``Partner''被译为``伙伴''. 二者区别为: 网络中的一个结点被称为这个网络中的成员; 网络中两个直接相连的结点互为伙伴. ); (3) 调度器 ( Scheduler ). 负责视频数据传输过程的调度工作. 一个 DONet 结点的角色相对于视频流中的每一个分段 ( Segment ), 既可以是分段的接收者 ( Receiver ), 也可以是提供者 ( Supplier ), 或二者皆是. 结点角色的确定会根据分段的可用性信息 ( Segment's Availability Information ), 动态地调整. 分段的可用性信息会在结点及其伙伴之间周期性地传递. ( 译者注: 原文中使用的是 ``periodically exchanged between the node and its partners''. 翻译为``周期性地在结点及其伙伴间传递''. 但是译者认为, 这种传递并非是严格地周期性动作, 即, 两次信息交换之间的时间间隔不一定是个常数. 因此, 此处翻译为``周期性地'' 似乎欠妥 ) 但是最初提供资源的结点 ( Source Node ) 是个例外 --- 它的角色永远是分段的提供者. 在此, 这种结点被称为``源结点'' ( Origin Node ). 它可以是一个专用于提供视频服务的服务器, 也可以是网络中一个运行了视频服务程序的计算机.
本节中, 将讨论模块间的交互以及设计问题. 并给出了当前的一些解决方案. 它们分别被应用于基于PlanetLab的和基于因特网的实现中.
A. 结点的加入和成员的管理
每个 DONet 结点都有自己的一个唯一标识符 ( Unique Identifier ) --- 比如可以是它的IP地址 --- 并且维护着一个缓存, 用来存储 DONet 网络中一部分活跃成员的标识符 ( 以下称该缓存为mCache ). 在一个简单的结点添加算法中, 一个新加入的结点首先去和源结点联系. 源结点会随机地从自己的 mCache 中挑选出一个代理结点 ( Deputy Node ), 并将新加入的结点连接重定向到这个代理结点上. 新结点会从代理结点上获得一个成员的列表, 把其中的成员视为候选伙伴. 之后, 与这些候选伙伴建立连接, 由此确定了自己在网络中的伙伴关系.
总体来说, 这一添加过程是可行的. 因为源结点会在整个流的传输过程中始终存在, 并且它的标识符/地址是众所周知的. 重定向的过程使得新结点可以更加均匀地选择伙伴 ( 译者注: 此处原文为 `` The redirection enables more uniform partner selections for newly joined nodes''. 该句的翻译有些过分生硬. 需再斟酌 ), 同时很大程度上减少了源结点的负载. 本节的最后, 会对这个添加算法的改进进行一些深入探讨.
实践中, 此处遇到的一个关键问题是: 如何建立并更新 mCache. 为了适应网络的动态变化, 每个结点周期性地产生一个成员信息 ( Membership Message ) 用以声明自己的存在; 每个信息包含四项: <seq_num, id, num_partner, time_to_live>. 其中, seq_num 表示该信息的序号; id 表示结点的标识符; num_partner 表示结点当前拥有的伙伴数量; time_to_live 表示本条信息剩余的生存时间. DONet网络中, 成员信息的传递使用了 Scalable Gossip Membership 协议, 即SCAM. 关于这个协议的具体细节, 参考 [21]. 此处, 仅强调它所具有的三条重要性质: 可扩展 ( Scalable ), 轻量级 ( Light-weight )并且每个结点仅掌握部分信息 ( Uniform Partial View at Each Node ). 当结点收到一个新的成员信息时, 它会在 mCache 中找到对应 id 的成员信息记录, 如果seq_num大于记录中的seq_num, 则更新此条记录. 如果没有找到对应 id 的记录, 则在 mCache 中添加一条记录存储该成员信息. mCache 中, 每条成员信息记录包含五项: <seq_num, id, num_partner, time_to_live, last_update_time>. 前四项与成员信息中对应项的意义相同, 是从收到的成员信息中拷贝来的. 第五项记录了最后一次更新该记录的本地时间.
以下两种事件同样可能引起 mCache 中记录的更新: (1) 在会话 ( gossip ) 过程中, 某条记录即将被传递给其他结点; (2) 一个代理结点即将把某条记录传递给新加入的结点. 在这两种情况下, 结点会把相应记录的 time_to_live 减去 current_local_time - last_update_time . 如果计算结果小于等于零, 则该条记录会被删除, 并且不会被传递, 也不会被加入到伙伴列表. 否则, 对于第二种情况, 代理结点会把该条记录中的num_partner项加一.
B. 缓存映像的表示和交换
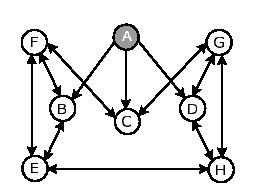
Fig-2 DONet 中的伙伴关系实例 ( A为源结点 )
Fig-2 是 DONet 中伙伴关系的一个例子. 如前所述, 在 DONet 网络中, 伙伴关系和数据传输方向都不是固定的. 一个视频流被分解为多个定长的分段. 结点缓存中各个分段的可用性信息被表示为一个缓存映像 ( Buffer Map, BM ). 每个结点会和它的伙伴不断地交换各自的BM. 之后, 通过调度算法, 确定从哪个伙伴处接收哪个分段.
对于实时的多媒体流来说, DONet 结点中的媒体播放过程是一个半同步 ( semi-synchronized) 的过程 ( 译者注: ``半同步'' 一词似乎有些前后矛盾. 从字面上看, 翻译为``半步'' 更佳. 但是为了便于理解, 这种``矮高粱'' 似的词汇还是保留了下来). 分析的结果表明, DONet 中分段传输的平均延时被限制在了一定范围之内. 实验的结果更近一步指出了, 结点之间的迟延很少高于一分钟. 假设每个分段包含了一秒钟的视频信息, 一个具有 120 个分段长度的滑动窗口便可以有效地构成一个缓存, 而滑动窗口以外的分组则不在结点的考虑范围之内. 如此, 在实现中, 便可以使用120比特来表示一个BM. 如果其中的某位被置一, 则表明该比特对应的分段有效, 即, 该分段已经被存储在了缓存中; 反之, 若某比特被置零, 则表明该比特对应的分段无效. 滑动窗口中第一个分段的序号 ( seq_num ) 存储在额外的两个字节中. 对于一个非常长的视频节目来说, 这个序号可能会由于溢出而被归零 ( 这样的视频节目至少应该大于24小时 ).
C. 调度算法
给定了一个结点和它伙伴的BM信息, 调度算法则可以用来确定从哪个伙伴处获得所需的分段. 对于一个同构 ( Homogenous ), 静态 ( Static )的网络, 循环鲁棒 ( Round-robin ) 式的调度便足以. 但是对于一个动态 ( Dynamically ) 并且异构 ( Heterogeneous ) 的网络来说, 更加智能的算法就显得尤为重要了. 一个调度的结果会受到两个约束条件的影响: 每个分段的截止时间 ( Deadline ), 以及与各个伙伴间的传输带宽. 第一个约束条件表明, 超过截止时间到达的分段数量应该控制在最小. 这个问题实际上是 `` 并行计算机调度问题 ''( Parallel Machine Scheduling ) 的一个变种, 属于NP类问题 [25]. 因此很难找到一个最优解. 从实际角度出发, 调度算法必须能够快速地适应高度动态的网络环境. 因此, 我们采取了一种简单且能够快速响应的启发式 ( Heuristic ) 算法.
这个启发式算法中, 首先计算出资源的潜在提供者 ( Potential Supplier ) 的数量 ( 即, 拥有所需分段的伙伴的数量 ). 因为一个分段如果对应着较少的潜在提供者, 那么将意味着这个分段会很难在截止时间之前到达. 算法会从仅有一个潜在提供者的分组开始确定某一分组的提供者. 之后是对应有两个潜在提供者的分组, 以此类推. 如果一个分组对应着多个潜在提供者, 那么具有最高带宽并且具有更长可用时间的提供者会被选中. Fig-3 列出了这个算法的伪码. 对于每个结点, 都将会执行该算法. 它的时间复杂度为 O( W * B * M ). 在具体的实现中, 每次执行仅需15ms. 计算的额外开销并不高. 因此, 它可以比较频繁地运行, 从而更新调度策略.

Fig-3 每个DONet结点调度算法的伪码
( 译者注: 个人认为, 该伪码包含部分打印错误:
自Scheduling: 一行起, 向下四行, 有: T[j,i]. 个人认为应该改为: t[j,i]
第一个if语句中的for循环, 包含一个循环控制条件, 原文为: j>k. 个人认为应该改为 j>i
再向下五行, 原文为 supplier[n]. 个人认为应该改为 supplier[i]
最后一个for循环, 包含一个循环控制条件, 原文为: j>k. 个人认为应该改为 j>i
以上纯属个人臆断, 一切仍以原文为准 )
结点通过调度算法的计算获得调度策略, 把需要从同一个伙伴处获得哪些分段的信息存储在一个类似 BM 的位序列中. 之后, 将这个位序列发送给相应的伙伴. 该伙伴会把位序列中所对应的分段通过一个实时的传输协议发送给结点. DONet 并不依赖于某个特定的协议. 和其他系统一样, 目前所采用的是 TFRC ( TCP-Friendly Rate Control ) 协议 [31]. BM 信息和调度策略信息可以随数据一并传输. 这样可以快速更新并且减少额外开销.
源结点在此始终作为资源提供者. 并且所有的分段都存储在它的缓存中. 为了防止源结点过载, 这里给出了一个适应度较高的调度算法. 如果需要, 它还可以通过对外公布保留的缓存映射来控制负载. 例如, 一个源结点拥有 M 个伙伴, 那么它可以把传递给第 k 个伙伴的 BM 设置为:
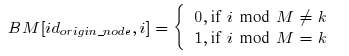
这就是说, 只有第 ( i mod M ) 个伙伴才会从源结点处获得第 i 个分段. 其他的分段则来自别的伙伴.
D. 错误的恢复和伙伴的筛选
在 DONet 网络中, 一个结点可以在事先声明后退出, 或由于崩溃而意外退出. 这两种情况都可以在TFRC空转一段时间或者BM信息传递过程中被检测出来. 结点同时离开的概率很小, 受到离开结点影响的结点会立即做出反应 --- 根据剩下伙伴的 BM 信息重构调度策略. 除了这个恢复机制以外, 下面提出的操作也同样用于增强系统的恢复能力.
声明后退出: 即将退出的结点会提交一个退出消息. 这个信息的格式与成员信息一样, 只是num_partner这一项被设为-1.
意外退出: 一个结点的意外退出会被它的伙伴检测到. 这个伙伴会代替退出的结点来发布退出消息.
退出消息的传递方式与成员信息的传递方式一样. 如果结点是意外退出的, 冗余的退出消息也许会被退出结点的多个伙伴发布. 但是只有第一个收到的退出消息会被允许继续在网络上传播, 其他的相同信息传播则会被抑制. 每个收到消息的结点会删除各自 mCache 中对应于退出结点的记录.
最后, 每个结点会定期地从它的 mCache 中随机选择出结点并与之建立伙伴关系. 这一操作的目的有两个: 第一, 它使得每个结点可以在一些伙伴退出的情况下, 维护一定数量的伙伴; 第二, 它使得结点可以寻找到更高质量的伙伴. 在实现中, 一个结点 i 评估它的伙伴结点 j, 使用函数 max{ si,j, sj,i}. 其中, si,j 表示单位时间内, 结点 i 收到来自结点 j 的分段的平均数量. 直觉上看, 一个具有更大上传带宽和更多可用分段的伙伴会获得更高的评估分数. 由于一个结点既可以是资源提供者, 也可以是接收者, 因此需要计算两个方向上的最大值. 在寻找到新的伙伴后, 为了保持伙伴数量的稳定, 伙伴列表中具有最低分数的伙伴将会被抛弃. 伙伴的数量, M , 是一个很重要的设计参数. 它的影响将会在之后的理论分析和实验中做具体介绍.















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









