







别看本小节的标题较为炫酷,实际上是这就是通过让机器通过学习攻击样本,自动生成XSS攻击载荷,与本书第三章中使用的SequenceGenerator原理相同,具体可参考我之前的笔记。
《Web安全之深度学习实战》笔记:第三章 循环神经网络_mooyuan的博客-CSDN博客
一、扫描器
漏洞扫描主要就是基于扫描器,扫描器是安全领域非常重要的一个工具,大多数安全公司都会有自己的扫描器产品。扫描器的原理非常简单,如图12-1所示,扫描器通过对目标网站发送攻击请求,根据应答内容判断是否存在漏洞,整个过程就是模拟黑客踩点和渗透的过程。常见的开源扫描器有Nikto、WebScarab、Burpsuite等。
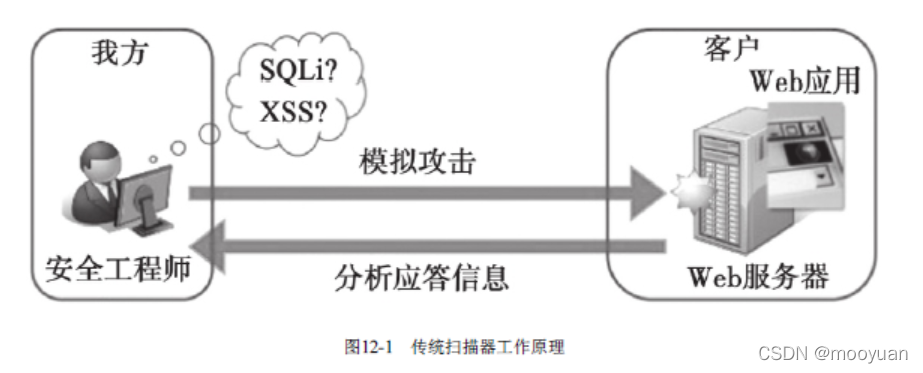
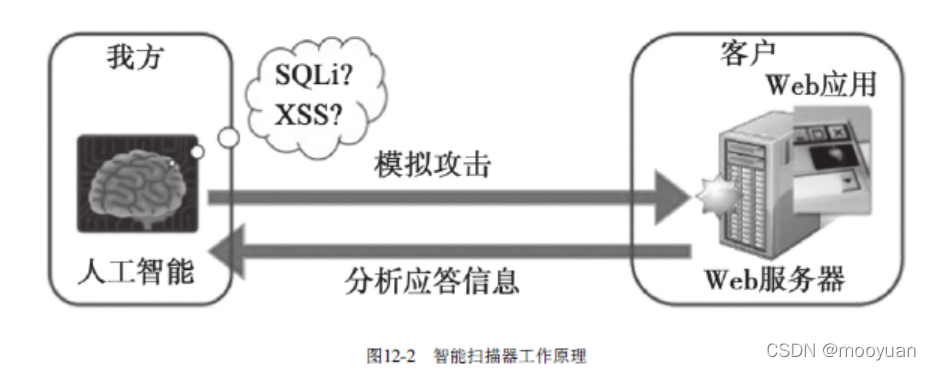
传统扫描器基于事先配置好的规则模板,发送攻击请求,然后分析应答内容,从而进一步判断是否存在漏洞。扫描器的漏洞发现能力取决于规则的丰富程度,一旦出现规则集合中不覆盖的漏洞,就无法检出,这是传统安全产品的通病。在实际的工作中,我们经常发现人工渗透可以发现大量扫描器无法发现的漏洞,排除扫描器本来就难以支持的业务逻辑漏洞,即使是常见的XSS和SQL注入漏洞也会有不少遗漏 [1] 。对比人工渗透和扫描器的扫描过程,主要差异点在于,安全工程师通过学习Web漏洞的原理,根据以往的经验,结合具体网站的实际情况展开渗透测试,人工渗透具有很强的灵活性,不像扫描器只会死板地照套模板规则。智能扫描器就可以学习人工渗透过程,如图12-2所示。
二、数据集
本节将使用常见的XSS攻击载荷数据集,数据集的获取方法是使用常见的Web扫描器对我们的靶场进行扫描,搜集扫描日志,提取XSS的攻击载荷,然后去重即可。
xss_data_file="../data/aiscanner/xss.txt"三、模型构建
def generator_xss():
global char_idx
global xss_data_file
global maxlen
if os.path.isfile(char_idx_file):
print('Loading previous xxs_char_idx')
char_idx = pickle.load(open(char_idx_file, 'rb'))
X, Y, char_idx = \
textfile_to_semi_redundant_sequences(xss_data_file, seq_maxlen=maxlen, redun_step=3,
pre_defined_char_idx=char_idx)
#pickle.dump(char_idx, open(char_idx_file, 'wb'))
g = tflearn.input_data([None, maxlen, len(char_idx)])
g = tflearn.lstm(g, 32, return_seq=True)
g = tflearn.dropout(g, 0.1)
g = tflearn.lstm(g, 32, return_seq=True)
g = tflearn.dropout(g, 0.1)
g = tflearn.lstm(g, 32)
g = tflearn.dropout(g, 0.1)
g = tflearn.fully_connected(g, len(char_idx), activation='softmax')
g = tflearn.regression(g, optimizer='adam', loss='categorical_crossentropy',
learning_rate=0.001)
m = tflearn.SequenceGenerator(g, dictionary=char_idx,
seq_maxlen=maxlen,
clip_gradients=5.0,
checkpoint_path='chkpoint/model_scanner_poc')
seed='"/><script>'
m.fit(X, Y, validation_set=0.1, batch_size=128,
n_epoch=2, run_id='scanner-poc')
print("-- TESTING...")
print("-- Test with temperature of 0.1 --")
print(m.generate(32, temperature=0.1, seq_seed=seed))
print("-- Test with temperature of 0.5 --")
print(m.generate(32, temperature=0.5, seq_seed=seed))
print("-- Test with temperature of 1.0 --")
print(m.generate(32, temperature=1.0, seq_seed=seed))这里面textfile_to_semi_redundant_sequences函数会报错,提示gbk无法解码
UnicodeDecodeError: 'gbk' codec can't decode byte 0x9d in position 67564: illegal multibyte sequence我是这样解决的,我直接修改了textfile_to_semi_redundant_sequences函数,将open函数增加了使用utf-8编码,具体处理如下
def textfile_to_semi_redundant_sequences(path, seq_maxlen=25, redun_step=3,
to_lower_case=False, pre_defined_char_idx=None):
""" Vectorize Text file """
text = open(path,encoding='utf-8').read()
if to_lower_case:
text = text.lower()
return string_to_semi_redundant_sequences(text, seq_maxlen, redun_step, pre_defined_char_idx)
以及
def random_sequence_from_textfile(path, seq_maxlen):
text = open(path,encoding='utf-8').read()
return random_sequence_from_string(text, seq_maxlen)
四、总结
本小节实际上就是本书第三章最后一个示例在网络安全中的一个应用,较容易理解,难度不高。
















 3549
3549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











