







 本文提出一种基于稀疏注意力的上下文感知神经机器翻译方法,采用分层注意力机制选择性关注文档上下文中的相关句子及其关键词,提高了翻译质量和效率。
本文提出一种基于稀疏注意力的上下文感知神经机器翻译方法,采用分层注意力机制选择性关注文档上下文中的相关句子及其关键词,提高了翻译质量和效率。
 https://zhuanlan.zhihu.com/p/434123470
https://zhuanlan.zhihu.com/p/434123470背景
此文和前一篇【随笔5】都属于“如何利用上下文信息”系列,但比【随笔5】中的层次丰富,导致结合方式更复杂一点。
正文
0. 摘要(Abstract)
虽然当前的研究在句子级别的神经机器翻译(Neural Machine Translation,NMT)取得了进展,但是当前的系统们仍然无法实现对于完整文档的流畅、高质量翻译。最近的上下文感知NMT的一些工作只考虑前面的几个句子作为上下文,可能无法扩展到整个文档。为此,此文提出了一个新颖的、可扩展的自上而下的上下文感知NMT分层注意力方法,其使用稀疏注意力来选择性地关注文档上下文中的相关句子,然后关注这些句子的关键词。此文还提出了基于上下文中句子或词级别信息的单级注意力方法。由这些注意力模块产生的文档级别的上下文表示,被集成到Transformer模型的编码器或者解码器中,具体情况,取决于使用的是单语还是双语的上下文。实验表明,此文提出的选择性注意力方法不仅显著地优于上下文无关的方法,也在大多数情况下超过了其他上下文感知的方法。
1. 引言(Introduction)
近年来,神经机器翻译发展迅速,从简陋的基于RNN的编码-解码器模型,到最先进的Transformer架构。这些模型中的大多数依赖于注意力机制作为主要组件,它涉及关注序列的不同部分来计算新地表示,并且已被证明在提高翻译质量方面非常有效。然而,这些模型都有一个固有的问题:翻译是在逐句地基础上进行的,因此忽略了在翻译话语现象(“discourse phenomena”)是可能有用的长范围依赖。
With the term 'discourse phenomena', we mean linguistic elements and constructions that typically occur in oral speech and help to manage the organization, flow and outcome of communication(cf. Schiffrin 1987, Du Bois 2003).
说白了,这里有点像在检测时只用了局部信息,没有结合全局信息。而只居于局部信息的单点检测,在某些情况下会出现歧义或者两者皆可、举棋不定的现象,此时,则可借助于全局信息来予以滤除。
最近,上下文感知NMT已经从研究社区中获得了显著的吸引力,大多数研究工作都是过去两年中推出的。其中大部分侧重于使用前几个句子作为上下文,并且忽略了文档的剩余部分。只有一项工作尝试去考虑完整的文档上下文,从而提出了一种更通用的文档级的NMT方法。然而,这个模型是有限制的,因为文档级别的注意力是基于句子的和静态的(对于被翻译的句子只计算一次)。更近期的一项工作提出了分层注意力网络(hierarchical attention network,HAN),来使用词级和句子级的抽象,以结构化的方式对上下文进行建模。然而,它使用有限数量的过去源句和目标句作为上下文,并且不能扩展到整个文档。
此文提出了一种选择性注意力的方法,首先,选择性的关注全局的文档上下文中的相关句子,然后,关注这些句子中的关键词,同时,忽略其余部分。为实现这一目标,此文使用稀疏注意力(sparse attention),实现对上下文的高效和可扩展使用。这背后的直觉是,人类翻译包含歧义词的句子的方式。他们可能会在整个文档中寻找包含相似词的句子,然后只关注那些用于翻译的句子。这种注意力,此文称之为分层注意力,是为每个查询词动态计算的。此外,此文提出了一种基于上下文中的句子或者词级信息的扁平注意力。此文将这些注意力模块产生的文档级的上下文表示集成到Transformer模型的编码器或者解码器中,具体方式,取决于考虑的是单语(源端)的上下文,还是双语(源端和目标端)的上下文。
文中的选择性注意力“selective attention”一词,来源于认知科学,其被定义为在一段时间内,专注于特定对象,同时忽略正在发生的无关信息的行为。(Dayan et al., 2000)
此文创新点如下:
- 为上下文感知NMT,提出了一个新颖且高效的自上而下分层注意力的方法;
- 对比了选择性注意力的变体和上下文无关、以及上下文感知的方法;
- 在三个数据集(TED Talks, News-Commentary and Europarl)上,进行了线上(仅含有过去上下文)和离线(含有过去和将来的上下文)实验,显示了方法的有效性。
2. 相关背景(Background)
2.1. 神经机器翻译(Neural Machine Translation)
通用的NMT模型基于编码器-解码器结构,编码器读取由表示的源句 ,并将其映射到连续表示 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/524eb39ab25a7a40826f20cecea0aa82.png) 。给定 ,注意力解码器以从左到右的方式,一次一个单词产生目标翻译
。给定 ,注意力解码器以从左到右的方式,一次一个单词产生目标翻译 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/56151f71c4866c0e204ce3d096379823.png) 。
。
2.2. 文档级机器翻译(Document-level Machine Translation)
一般来说,给定原文档 的文档翻译 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/ce020eb98bb704a4d4bd27920c72fe8b.png) 的概率由下式1给出:
的概率由下式1给出:
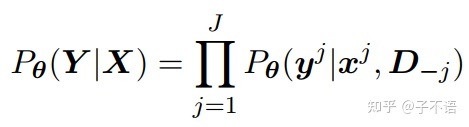
其中, 和 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/1c05c0529e1bcd521379f14dd0e83039.png) 分别表示第
分别表示第 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/ebe2c52df33e9163198c974359a197f2.png) 个目标句和源句。
个目标句和源句。 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/30b745825c5d2dc1ffdbd14c7351855e.png) 是源文档和目标文档中所有其他句子的集合。由于通用NMT模型每次翻译一个词,所以上式变成了式2:
是源文档和目标文档中所有其他句子的集合。由于通用NMT模型每次翻译一个词,所以上式变成了式2:
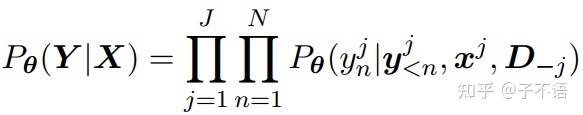
其中 是第个 目标句子的第 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/ce59f55893efd960f1dbdfcd5c192a96.png) 个词,
个词, 是之前产生的词。
训练 文档依赖的NMT模型 是基于神经架构实现的,通常分两步来训练。第一步是预训练一个标准的句子级的NMT模型,第二步是优化整个模型的参数,及文档级和句子级的参数。
解码 为了根据文档机器翻译模型生成完整文档的最佳翻译,两边迭代解码策略被用来解决最大化式1的问题。首先,使用基于句子的NMT模型初始化每个句子的翻译;然后,使用上下文感知的NMT模型来更新每一个翻译,与之相对的固定其他句子的翻译此时是固定的。
3. 提出的方法(Proposed Approach)
3.1. 文档级上下文层(Document-level Context Layer)
上下文 是由一个文档级上下文层建模的,其包含两个子层:1)多头上下文注意力子层(Multi-Head Context Attention sub-layer);2)前向子层。多头上下文注意力子层由一个自上而下的分层注意力模块或者一个扁平注意力模块组成。
3.1.1. 分层注意力(Hierarchical Attention)
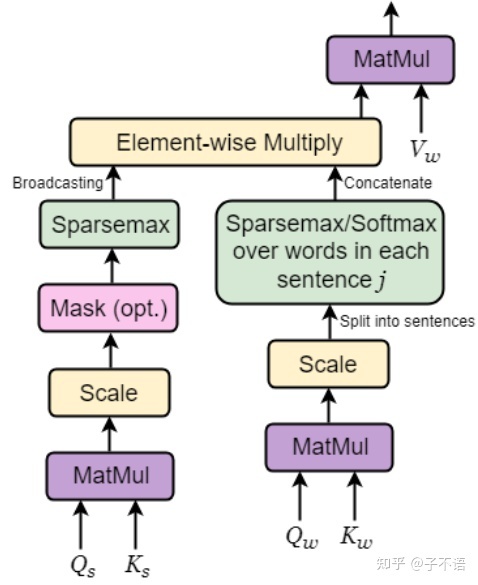
图 1:分层上下文注意力模块
图1中提出的模块,大意是在原始的点乘attention计算前,将句级的Q、K和词级的Q、K分别先算相似度,然后将根据相似度信息得到的句级的注意力,与词级的注意力相乘,得到每一个词最后的注意力,然后根据这些注意力值,来调整词的权重。
分层注意力模块有5个输入 ,由两种类型的键和查询组成,句子和单词各一个,然而值 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/8cb737f1e21afc008282dd3332f8f874.png) 仅基于上下文中的单词。分层注意力有4种操作:
仅基于上下文中的单词。分层注意力有4种操作:
1)句子级的键匹配
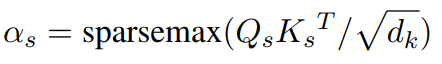
这里使用了sparsemax,而不是softmax,因为sparsemax提供了预期的选择性注意力行为,即识别可能与当前句子相关的关键句子,从而使得模型更有效地压缩其存储。另一方面,softmax注意力仍然可以为句子分配低概率,形成长尾分布并吸收着显著的概率质量(probability mass),并且它不能完全的忽略这些句子。在sparsemax操作前,一个附加掩码被用于屏蔽当前句子或当前和将来的句子,来设置不同的在线和离线训练。
2)词级别的键匹配
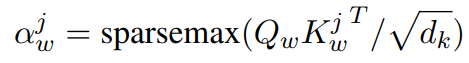
这里可以使用softmax代替sparsemax来进行粗略的键匹配。
3)重新调整注意力权重
词级的注意力由对应的句级的注意力进一步调整,这样文档中的第 个句子的概率由下式给出:
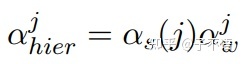
因此,重新加权产生了一个缩放的注意力向量 ,其中的每个条目对应于文档中特定单词的注意力权重。
4)值的读取
词级的值的集合被打包为矩阵,输出的矩阵由给出。这种与sparsemax注意力相结合的乘法,允许修剪层次结构。
这句话说的有点模糊,不清不楚,我也不明白作者想说什么。是修剪什么的层次结构?文中提出的上下文注意力模块?
参考Transformer中的mult-head机制,作者也提出了多头注意力:

3.1.2. 扁平注意力(Flat Attention)
对上下文 建模的另一种方式,是通过重用Scaled Dot Product Attention来完成单个级别的注意力,
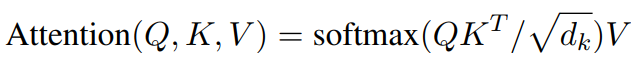
这里的注意力有两种计算方式:
- 句级 K, V为文档中的句子计算的;
- 词级 K, V为文档中的单词计算的。
前一个模块类似另一个文章种的存储网络架构(Memory Networks architecture ),因为它使用句级的信息。然而,两点关键不同在于,此文使用了多头注意力,还有,此文中的上下文注意力是动态的,因此对于每个查询词都有单独的注意力。
3.2. 上下文门控(Context Gating)
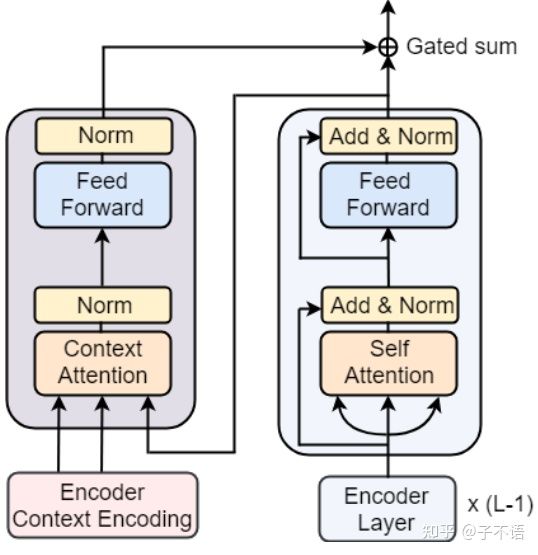
图 2:编码器侧的上下文集成。(Monolingual context integration in Encoder.)
一个类似残差的结构,可简化为 H(x)=(1-a)*F(x)+a*x,x是编码器的输出,F(x)是图2左侧模块的输出,Gated Sum为门控求和。
Note:残差本质是y=x+f(x),激活后f(x)>=0,在求梯度时为1+f’(x),保证梯度始终在1附近,这样两式一起就保证了“就算没学到有用的东西,也不会产生不利的信息,避免了梯度消失” [1]
如图2所示,对于第 个词,
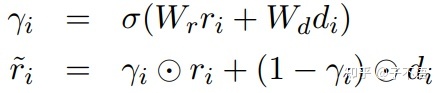
其中, 是可学习的参数, ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/f6aa5ff23f58c585a457881fb224e485.png) 是编码器或解码器对于第个词的输出,
是编码器或解码器对于第个词的输出, ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/1be7c77a15e06e8bb61f16509eb182f0.png) 是上下文层对于第个词的输出,
是上下文层对于第个词的输出, ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/1bba5e0bb0b07c6ff87352983c843915.png) 是最终地隐藏层的表示。
是最终地隐藏层的表示。
3.3. 集成模型
上下文模块可以集成到 NMT 模型的编码器或解码器中,具体取决于它是单语还是双语。
此文没有在编码器和解码器中都用上下文模块,因为这样会带来冗余信息,还会增加模型的运算负担。
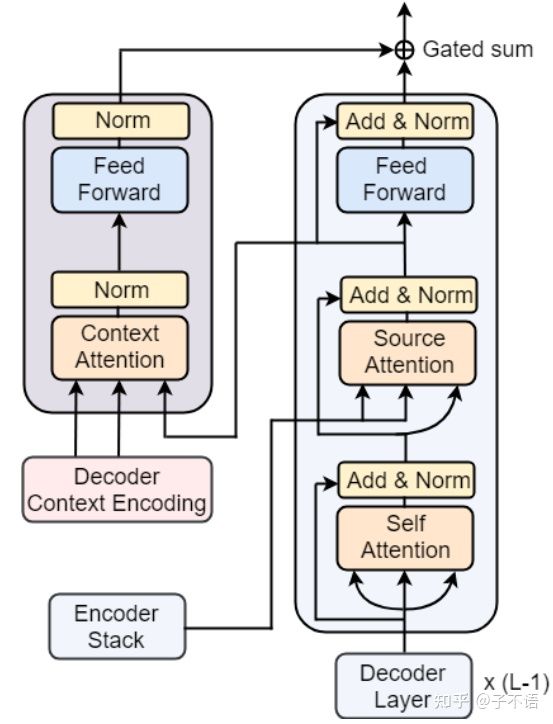
图 3:编码器侧的上下文集成。(Bilingual context integration in Decoder.)
不同于Transformer的Decoder部分,作者在图3中去掉了mask机制,因为作者设计的模型是可以正向和反向翻译,因此不需要mask机制来维持信息的顺序性。
特别说明的是,不论是Transformer还是本作者提出的模型,解码器(Decoder Stack)部分均为自回归模型,输入则为已经预测的单词(通常为上一个单词的向量),输出则为一个概率分布,表示单词库中每个单词的概率。 [2]
至此,本文的方法及创新部分结束。
4. 结论(Conclusion)
此文提出了一种基于稀疏注意力的上下文感知NMT分层注意力方法,该方法可扩展且高效。定性分析表明,句子级别的稀疏性允许提出的模型识别文档上下文中的关键句子,单词级别的稀疏性允许它专注于这些句子中的关键词,从而有效地压缩记忆。 在未来的工作中,作者们计划在上下文感知 NMT 模型的可解释性方面,更深入地挖掘稀疏注意力的好处。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









