







目录
一、Xpath介绍
xpath是一套用于解析XML/HTML的语法,它使用路径表达式来选取XML/HTML中的节点或节点集。Xpath常用语法和实例如下表所示
xpath使用的第三方库为lxml
使用lxml提取网页内容的方法:
#1.导入etree类
from lxml import etree
#2.使用html生成etree类对象
etree.HTML()
#3.提取页面目标元素
xpath()XPATH语法如下所示

路径表达式:

谓语
什么是谓语?
谓语用来查找某个特定节点或者包含某个指定节点,位于被镶嵌在方括号中

二、检查Xpath有无错误的方法
下面教大家一个简单的方法来探究你写的xpath语法有无错误的方法
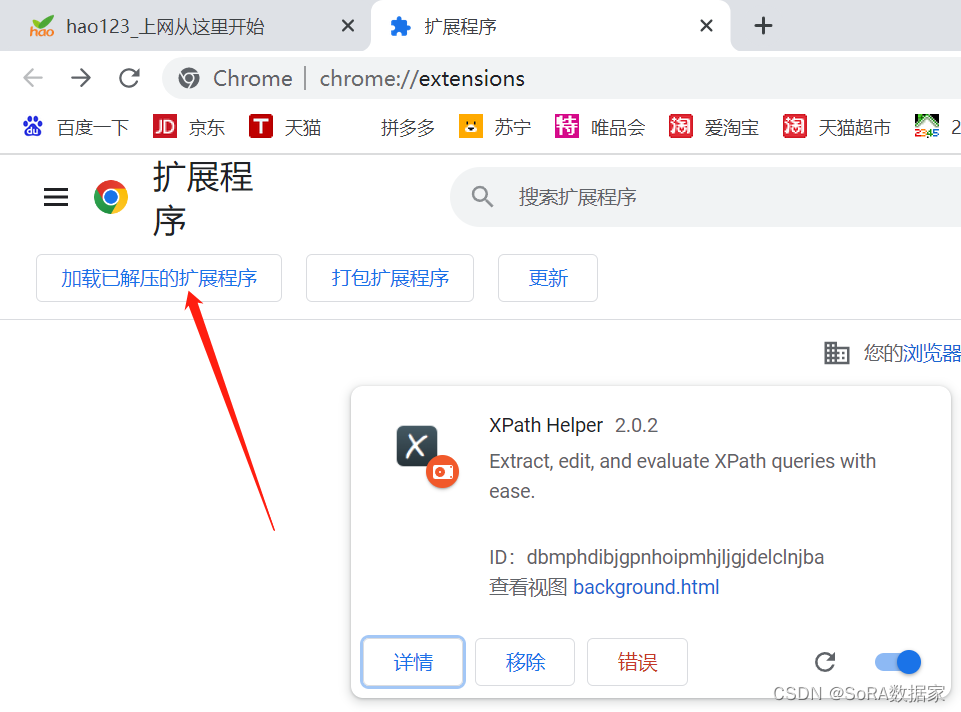
1.打开浏览器(这里使用的是google chrome)
2.选择右上角的竖状三点——更多工具——扩展程序

3.点击——加载已解压的扩展程序
 链接:https://pan.baidu.com/s/1WaIn2MTqzimyxLFijqst5Q
链接:https://pan.baidu.com/s/1WaIn2MTqzimyxLFijqst5Q
提取码:phvs
压缩包程序链接我放这,下载后解压即可,添加到扩展程序就可以使用了
三、扩展程序使用方法
以www.baidu.com网站为例,提取“百度一下”四个字
1.快捷键Ctrl+Shift+X,打开xpath黑色下拉框

2.F12打开网页,输入xpath语法查看是否能打出“百度一下”,能则证明xpath正确

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









