







前言
这是一次补记录,那天接到基友一个临时任务。根据他给的文件,分析并获取CPU天梯榜的分数,然后进行分级。
下面开始我们的思路拆解:
数据处理部分
如果有多份文件,也都是按照这个思路处理。
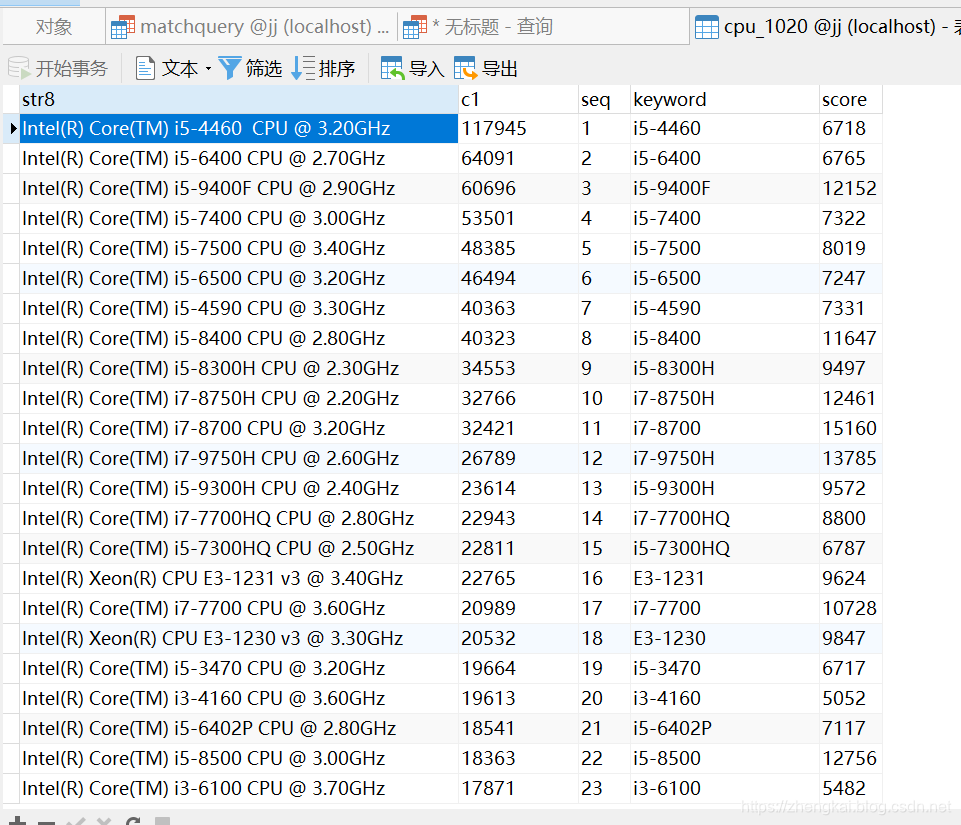
原始CPU数据:
- 首先是excel文件,为每一列添加一个
序列seq,并另存为CSV。例如cpu_1020.xlsx另存为cpu_1020.csv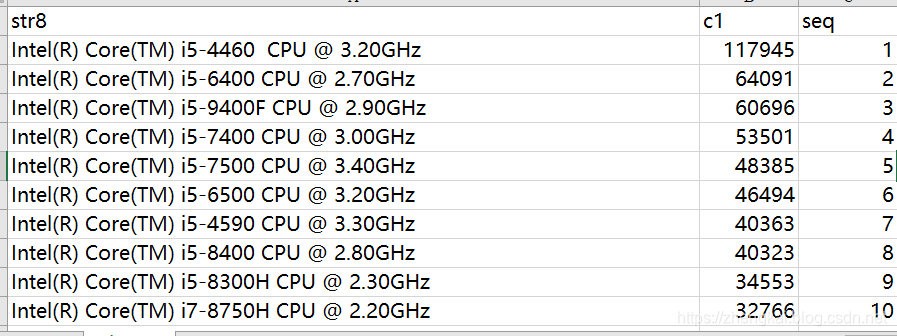
- 然后通过navicat的
导入向导功能,可以导入为数据库表。cpu_1020表.
- 导入后应该是三列信息,可以修改一下字段名为
str8,c1,seq。添加一个score用于保存天梯分数,添加keyword用于保存关键字提取数据。 - 获取对应的DDL语句
CREATE TABLEcpu_1020(str8varchar(255) DEFAULT NULL,c1varchar(255) DEFAULT NULL,seqvarchar(255) DEFAULT NULL,scorevarchar(255) DEFAULT NULL,keywordvarchar(255) DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=utf8; - 到 Spring Boot Code Generator 进行转换,可以生成需要的JPA entity和repository等文件。
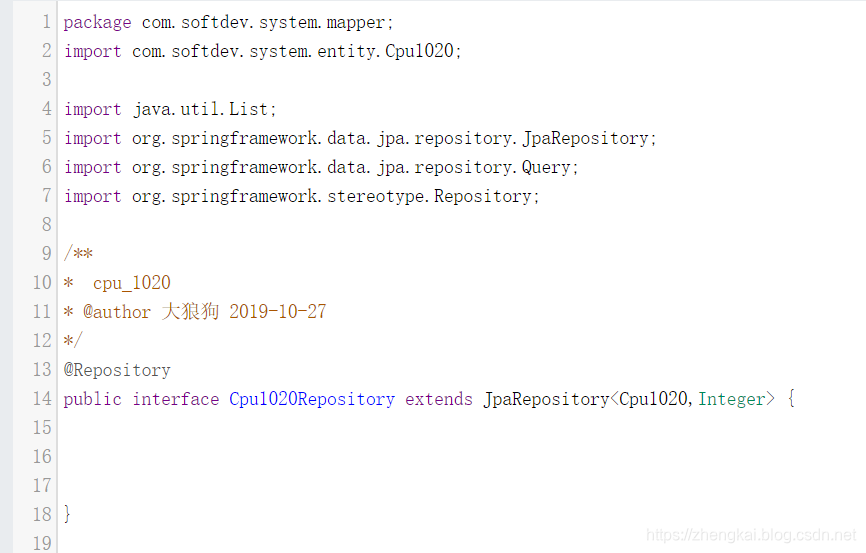
- JPA的话,需要修改seq字段为
@Id,str8可能会存在重复或者非法内容,不适合做id,这也就是加seq的原因之一,另一个是方便知道后面排序后的数据是之前文件的第几行,总之还是不错的。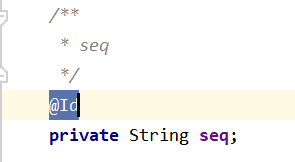
天梯数据部分:
- 到新浪APP的CPU性能排名榜http://itianti.sinaapp.com/index.php/cpu 获取记录。
- 借助Chrome的
F12功能,删除掉不必要的元素,整个topbar,footer,title,titletip,right这五个可以删除掉。然后就得到一个干净的表格了,可以直接copy到excel。
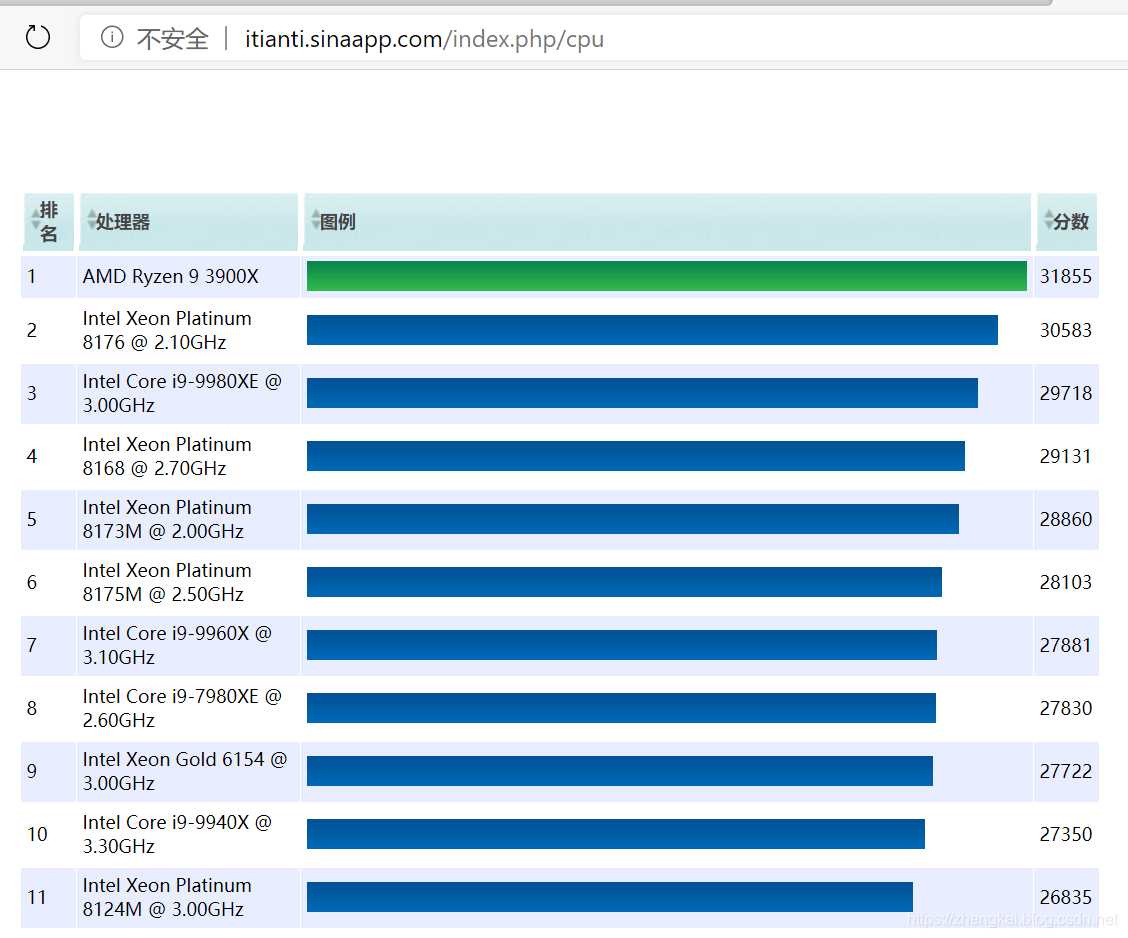
- 惯例,加上seq列,处理一下excel文件,保存为csv格式
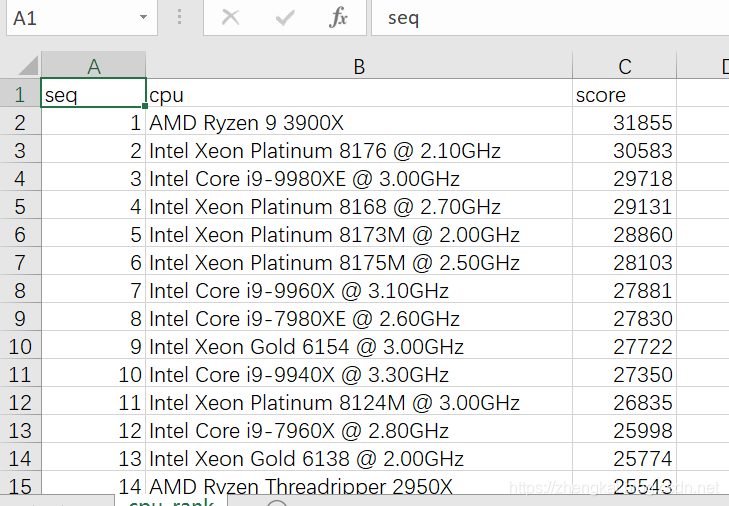
10.导入mysql为cpu_rank表,依旧加上keyword,并且到http://java.bejson.com/generator生成为需要的JPA文件。
正则表达式分析:
可以到 正则表达式在线测试工具 进行分析。
根据我对CPU的理解,一般,CPU分为三个阵营,Intel,AMD,VIA(out了)。
然后型号方面,一般都是 i3/5/7-xxxx ,也就是3到10位的数字或者字母或者-。带的后缀,也就是6400T低功耗/6500U低压/9100F无核显/9700K超频/G5600奔腾金牌/P6000奔腾/移动的4610M/4790S节能/3900X(AMD)/4700XM移动高端/E3E5E7的E/打桩机的2990WX/E5-2697A/E5-2618L/Xeon D-2143IT
最后得到一个精华的表达式[F,H,Q,P,E,K,U,S,T,P,M,W,X,A,L,0-9,i-]{3,10}
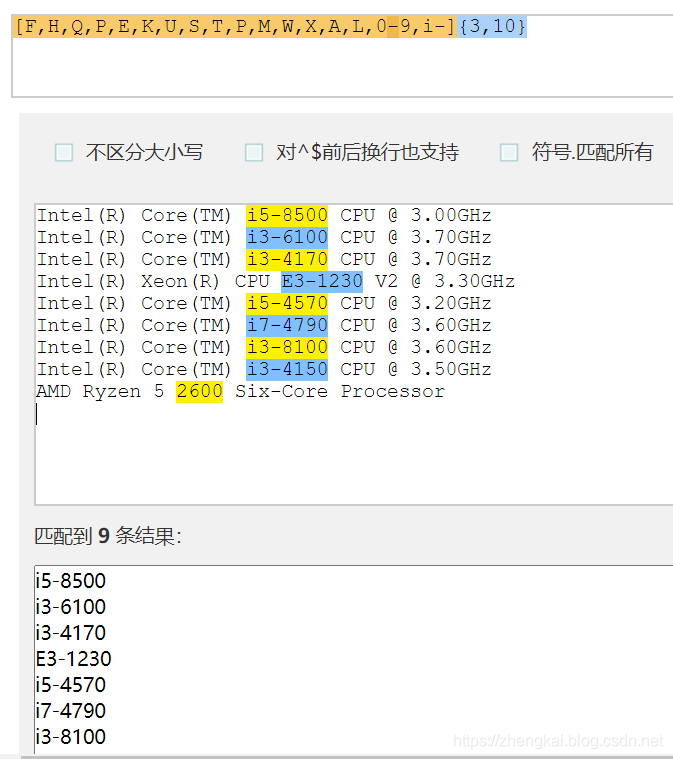
JAVA部分
提取分析keyword并且保存到数据库表的keyword字段,包括原始数据cpu_1020和CPU天梯表cpu_rank也分析一下。
@RequestMapping("/deal")
public Object dealCpu1(){
String patternString = "[F,H,Q,P,E,K,U,S,T,P,M,W,X,A,L,0-9,i-]{3,10}";
Pattern pattern = Pattern.compile(patternString);
List<Cpu1020> cpuList = cpu1020Repository.findAll();
for (Cpu1020 cpu1020:cpuList){
if(!StringUtils.isBlank(cpu1020.getStr8())){
Matcher matcher = pattern.matcher(cpu1020.getStr8());
//System.out.println(cpu1020.getStr8());
if(matcher.find()){
String name= matcher.group();
System.out.println("match->"+name);
cpu1020.setKeyword(name);
cpu1020Repository.save(cpu1020);
}
}
}
return null;
}
MYSQL匹配分数部分
处理一下即可。
UPDATE cpu_1020 t1
SET t1.score =(
SELECT
t2.score
FROM
cpu_rank t2
WHERE
INSTR( t2.keyword, t1.keyword )> 0
ORDER BY
LENGTH( t2.keyword )
LIMIT 1
);
优化思路
AMD和Intel的U,型号其实有一小部分是串号的,如果有时间,可以Intel和AMD分开计算,就比较准确了,至于最后一些没有匹配到的坑爹型号则要大致根据类型,去匹配一个差不多的分数了。。。
当然,后来发现原始CPU数据都有问题,所以就需要提前处理一下,有些没用的数据或者错误的非法的数据可以去掉。懒的话也可以后面在count一下没用分数的cpu,然后选择性的处理,删除或者补分数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









