









大语言模型微调 Large Language Model Finetune
框架推荐
适用于学习 https://github.com/tloen/alpaca-lora
适用于学习 https://github.com/brevdev/notebooks
适用于使用 https://github.com/hiyouga/LLaMA-Factory
注意点
大模型输入的信息包括:
- 问题
- 提示词
- 模型用于区分输入和输出结束的符号(每种大模型是不一样的,如果不加会影响性能)
例如llama2:
<s>[INST] <<SYS>>\n{your_system_message}\n<</SYS>>\n\n{user_message_1} [/INST]
system_message
一般用于描述需要完成的任务,例如: You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don’t know the answer to a question, please don’t share false information.
user_message
一般用于表达想问的问题和提示词,例如:今天星期几?
https://gpus.llm-utils.org/llama-2-prompt-template/
注意力机制 attention
什么是attention?
例如一张图片中,人对不同区域的关注度,有的地方高,有的地方低(拟人)。
进一步说,对于重要的数据,我们要使用,对于不重要的数据,我们不太想使用。
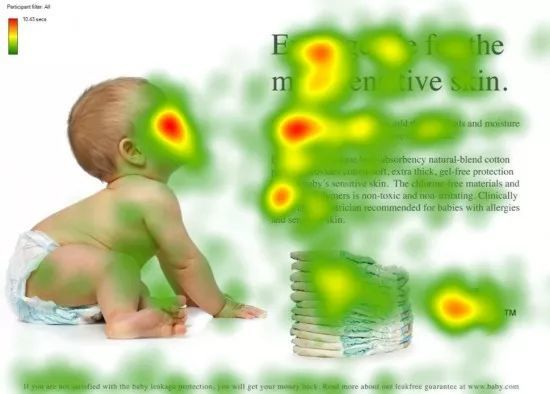
怎么做到的?
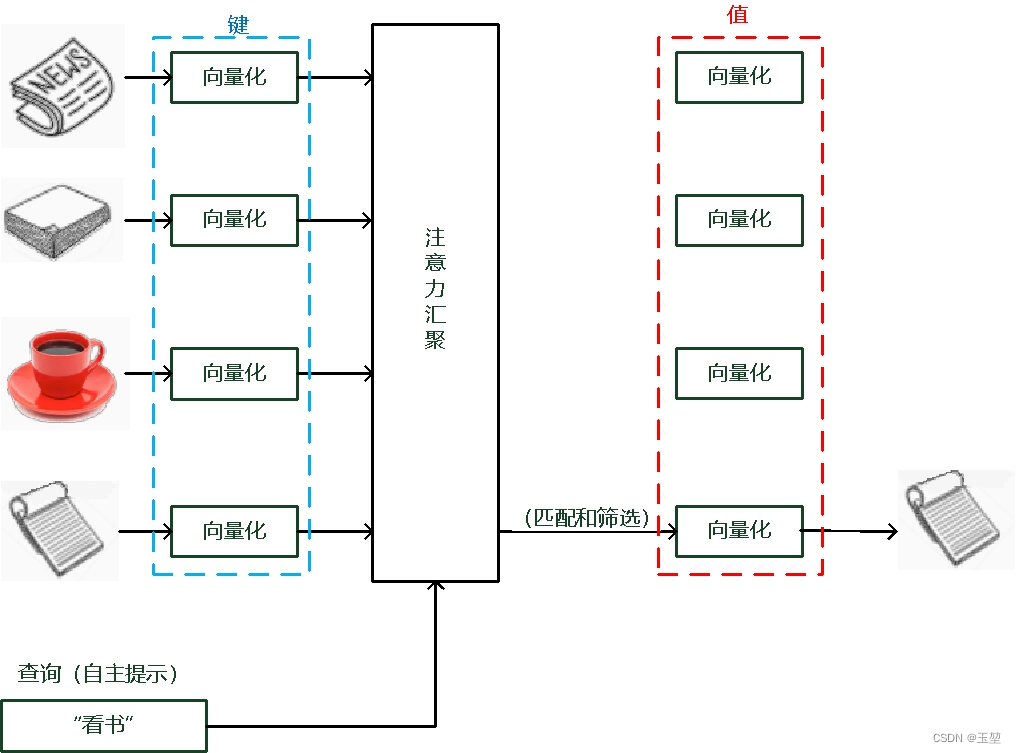
假设:我(查询对象 Q),这张图(被查询对象 V)
目标:去计算 Q 和 V 里的事物的重要度;
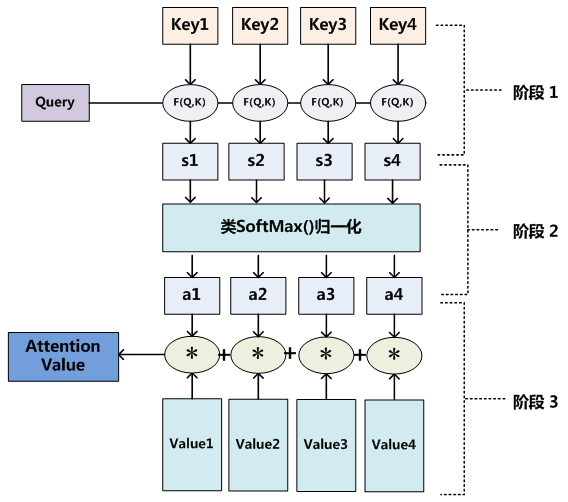
stage 1:
每个key代表图像的位置,query代表每个位置的查询结果,
(
s
1
,
.
.
.
,
s
n
)
(s_1 ,..., s_n)
(s1,...,sn)代表n个位置的查询结果(权重);
stage 2 :
softmax 归一化操作,将
(
s
1
,
.
.
.
,
s
n
)
(s_1 ,..., s_n)
(s1,...,sn)变成和为1的
(
a
1
,
.
.
.
,
a
n
)
(a_1,...,a_n)
(a1,...,an)的概率;
stage 3 :
(
a
1
,
.
.
.
,
a
n
)
∗
(a_1,...,a_n)*
(a1,...,an)∗(v_1,…,v_n) =
(
a
1
∗
v
1
,
.
.
.
,
a
n
∗
v
n
)
=
V
n
e
w
(a_1*v_1,...,a_n*v_n) =V_{new}
(a1∗v1,...,an∗vn)=Vnew
更新为values,后不断迭代
学术定义图
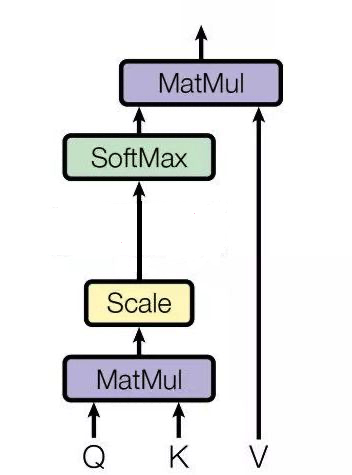
从本质上理解,Attention是从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
多头注意力机制 multi-head attention(importance)
单一注意力汇聚,只会建立一种查询和键的依赖关系。而我们常希望可以基于相同的注意力汇聚方法学习到不同的依赖关系,然后将这些依赖关系组合起来,实现捕获序列内各种范围的依赖关系。例如,机器翻译任务,以 " I like fishing because it can relax my mind " 要翻译为 " 我喜欢钓鱼,因为可以放松心灵 " 为例,我们以"放松"为Query,对英文句子中每个单词的Key进行注意力汇聚,结果获取"放松"和"relax"的依赖关系。
以上是单头注意力的结果,如果我们进行多次注意力汇聚,则可能捕获"放松"和"fishing", "I"等单词的依赖关系。这样,我们将多个结果进行融合就可以得到更为全面,复杂的依赖关系,这对于深度学习下游任务,例如目标检测,语义分割等都具有很大帮助。
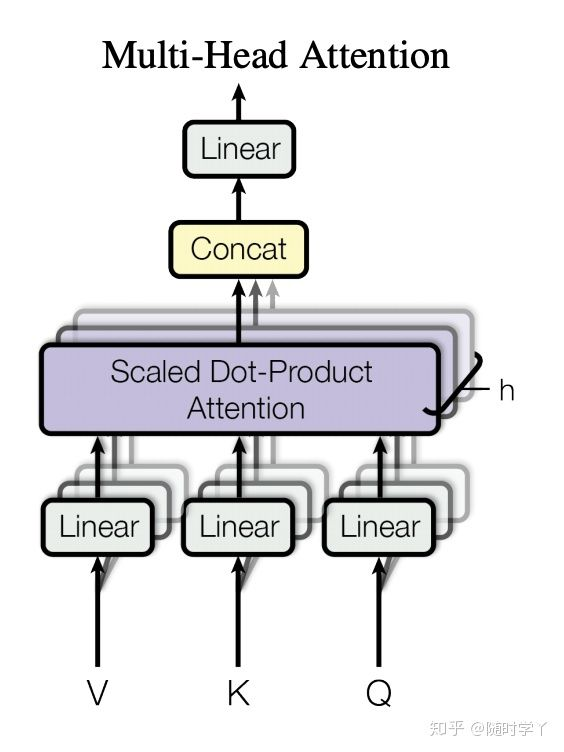
具体流程如下:
- 将查询,键和值通过多组全连接层来获取对应的特征向量。由于每个全连接层的参数都是可学习的,因此,经过独立学习可以获取多组不同特征的查询,键和值的特征向量。
- 对多组查询,键和值的特征向量进行注意力汇聚,从而获得多个不同注意力汇聚运算结果。
- 将所有的注意力汇聚运算结果进行拼接,再经过一个全连接层,就可以映射出所需的最后输出。
注:
其中每一个注意力汇聚都被称作一个头(head)。由于有多个注意力汇聚,因此才被称为多头注意力。
自注意力机制
自注意力机制和注意力机制的区别就在于,注意力机制的查询和键是不同来源的,例如,在Encoder-Decoder模型中,键是Encoder中的元素,而查询是Decoder中的元素。在中译英模型中,查询是中文单词特征,而键则是英文单词特征。而自注意力机制的查询和键则都是来自于同一组的元素,例如,在Encoder-Decoder模型中,查询和键都是Encoder中的元素,即查询和键都是中文特征,相互之间做注意力汇聚。也可以理解为同一句话中的词元或者同一张图像中不同的patch,这都是一组元素内部相互做注意力机制,因此,自注意力机制(self-attention)也被称为内部注意力机制(intra-attention)。
理解:自注意力机制的作用是学习Query对其他所有Key的依赖关系。即每个特征信息都是组内其他所有特征信息的关系组合。
举例说明:在一句话中,通过自注意力机制可以使每个单词不光包含自己的主体信息,还会包含和其他单词的关系信息(主谓,指代等)。因此,每个单词都具备和其他所有单词的依赖关系。再从图像中来讲,就是每个patch(图像会划成不同的块,每个块称为patch)都包含有其他patch的关系信息。其实也可以理解为建立了全局感受野。
优点:可以建立全局的依赖关系,扩大图像的感受野。相比于CNN,其感受野更大,可以获取更多上下文信息。
缺点:自注意力机制是通过筛选重要信息,过滤不重要信息实现的,这就导致其有效信息的抓取能力会比CNN小一些。
https://www.cnblogs.com/nickchen121/p/16470710.html
https://blog.csdn.net/weixin_43610114/article/details/126684999
Encode and Decode
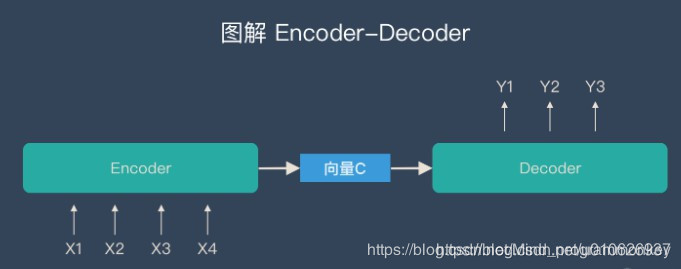
Encoder-Decoder是一个模型构架,是一类算法统称,并不是特指某一个具体的算法,在这个框架下可以使用不同的算法来解决不同的任务。首先,编码(encode)由一个编码器将输入序列转化成一个固定维度的稠密向量,解码(decode)阶段将这个激活状态生成目标译文。
几点说明
- 不论输入和输出的长度是什么,encode和decode中间的“向量”长度都是固定的(这是它的缺陷所在)。
- 根据不同的任务可以选择不同的编码器和解码器(例如,CNN、RNN、LSTM、GRU等)
- Encoder-Decoder的一个显著特征就是:它是一个end-to-end的学习算法。
- 只要符合这种框架结构的模型都可以统称为Encoder-Decoder模型。
信息丢失的问题
基础的Encoder-Decoder是存在很多弊端的,最大的问题就是信息丢失。
通过上文可以知道编码器和解码器之间有一个共享的向量(上图中的向量c),来传递信息,而且它的长度是固定的。但是这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,还有就是先输入的内容携带的信息会被后输入的信息稀释掉。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息,那么解码的准确度自然也就要打个折扣了。
Encoder将输入编码为固定大小的向量的过程实际上是一个“信息有损的压缩过程”,如果信息量越大,那么这个转化向量的过程对信息的损失就越大,同时,随着序列长度(sequence length)的增加,意味着时间维度上的序列很长,RNN模型就会出现梯度弥散的问题。由于基础的Encoder-Decoder模型链接Encoder和Decoder的组件仅仅是一个固定大小的状态向量,这就使得Decoder无法直接无关注输入信息的更多细节。为了解决这些缺陷,后又引入了Attention机制以及Bidirectional encoder layer等。
https://blog.csdn.net/u010626937/article/details/104819570

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











