







Bug产生
今天使用token完成用户登录信息的存储的时候被卡了大半天。
因为登录的功能写的已经很多了,所以今天就没有写一点验一点,而是在写完获取博客列表功功能,验证完它的后端后,了解完令牌的基本使用以及Jwt的基本使用方式——生成Key签名—>生成令牌环–>解析令牌环—>校验令牌环,直接写登录的前后端代码,一起做的验证,这一试可把试到快怀疑人生了!
好嘛,在浏览器登录,输完用户名密码,直接输入框清空,自己刷新了一下,连blog_list.html界面都进不去了!我整个人就是呆住的状态…
尝试解决思路
1.首先就是怀疑前后端交互的问题(因为我后端已经验证过了,正确的和错误的),接着就是在控制台的js代码上打断点调试。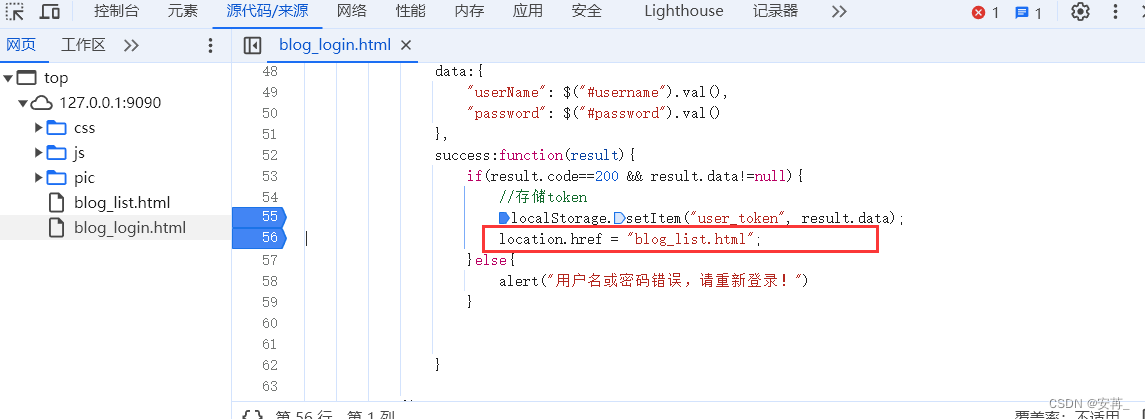
当时就是一整个满心期待的看着localStorage.setItem本地存储设置成功,对应的code已经为200了,马上就要跳转页面了,还以为之前是没触发这个跳转的代码,可是马上被打脸,直接又是清空(疑似就是强制登录,又重定向到了blog_login.html界面),不死心,反复又调试了几次发现现象还是这样。===》查看拦截器的配置代码
2. 此时来带到后端代码这里,一开始仍然觉得没有问题,这里与我之前书香阁做的强制登录的代码写的是一样的,对于静态html页面都是只放行登录界面(此时还没有做注册功能)。但是后来反反复复看前端代码,看后端代码,看抓包结果(发现此时获取不到blog_list.html界面),尝试着放行了所有的html界面,果然可以了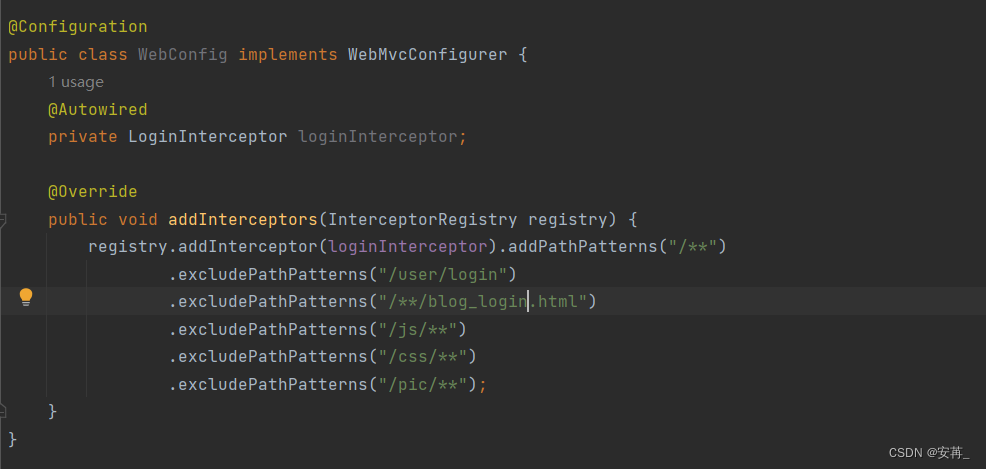
对于这个现象,我自己的思考是,原来的书香阁的拦截器代码之所以可以只设置login.html这一个静态页面放行,是因为那里的登录机制使用的是session,session会当我们登录完之后,赋值之后,session是header里边默认有的KV,执行到success部分,尝试跳转时,请求对应的html资源,header里边会有session就能通过拦截器。
但是我们这里不一样,我们使用的是token,虽然可以在每次请求发送前进行包装,自定义一个键值对,并把它添加到header里边,但是这里的common.js是在请求发起时才能执行到,是页面已经加载出来了才能添加,目前我们连骨架html都没有,根本就没可能走到这一步,所以这个项目的html必须全部放行!!!!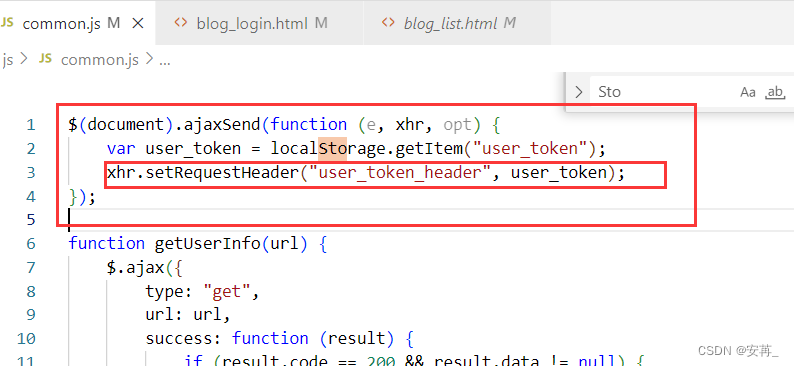
本来以为到这问题就结尾了,就想着做最后一次验证,看后端打印的获取的token日志是否有且不为空,诡异的事情又发生了!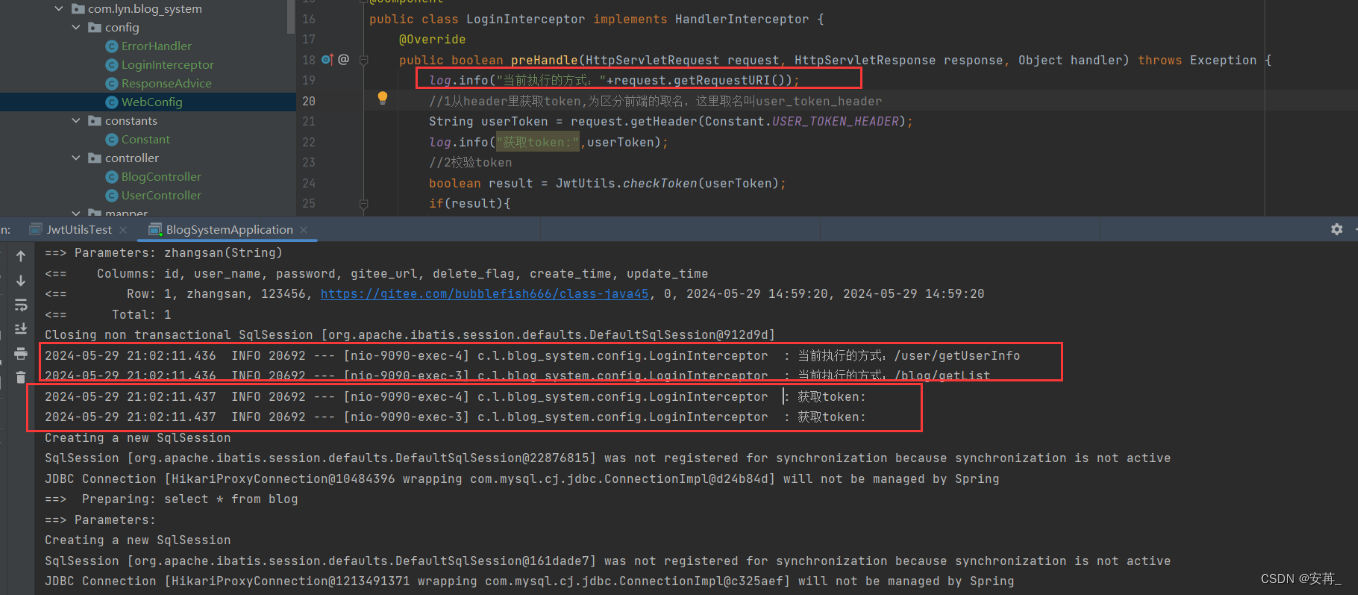
我前端已经加载出页面了,但是打印不出来token???
3. 这里我就先考虑了缓存的问题,因为我实在想不出前后端代码都“正确”的前提下,(排除数据库问题,另外此处也不涉及配置的问题)除了缓存还有其他问题会导致我打印不出来变量值的日志,idea,后端,浏览器全部清理,然而,并没有卵用。。。
对着发呆了一会之后,我尝试多加几条打印日志之后发现:有了!
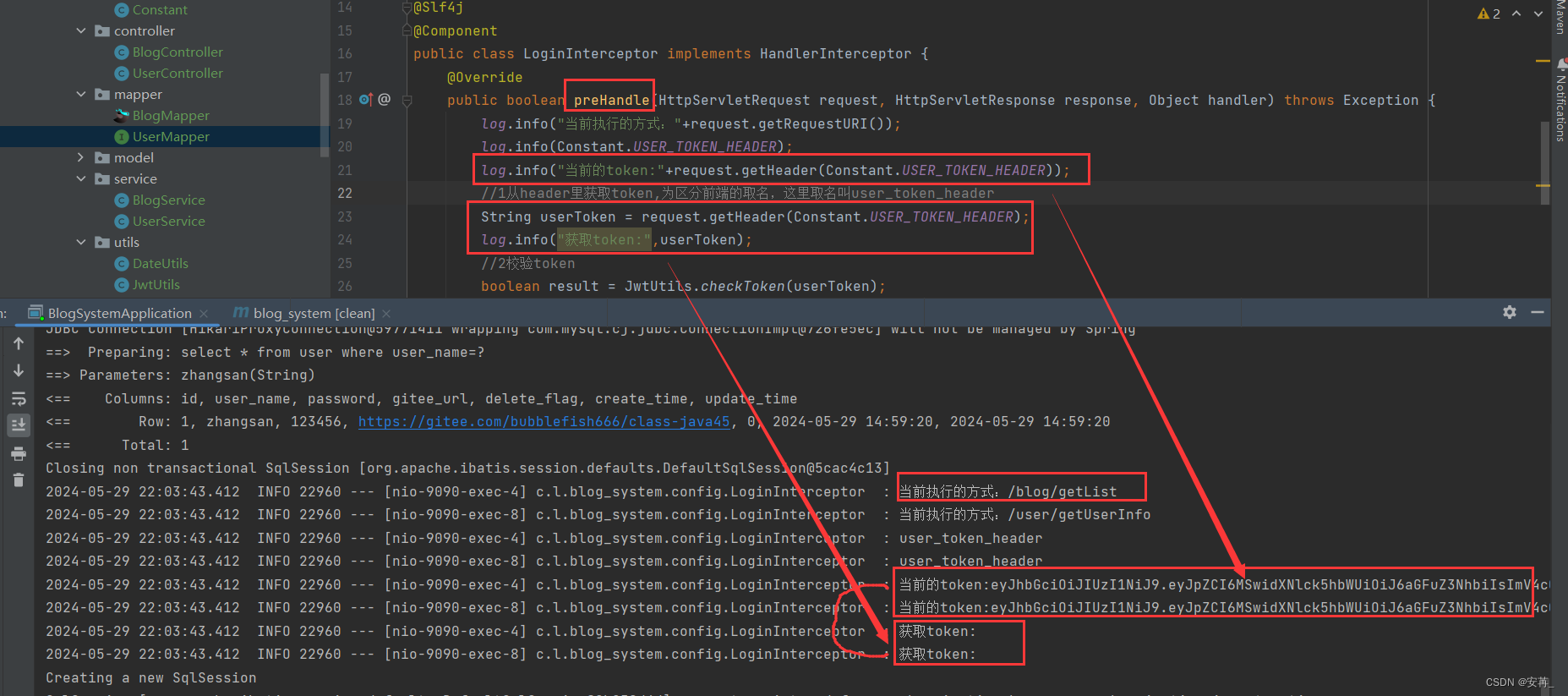
再次尝试修改,为+号后,发现下边那方式也能打印出来token了。
在Java中,log.info(“获取token:”,userToken);和log.info(“获取token:”+userToken);的区别在于:
log.info(“获取token:”,userToken);:这种方式使用了参数化日志,它可以避免字符串连接的性能损耗。日志框架会在运行时将userToken的值插入到日志消息中。这种方式更加高效,特别是在需要记录大量日志时。
log.info(“获取token:”+userToken);:这种方式通过字符串连接将userToken的值添加到日志消息中。这可能会导致性能损耗,因为每次调用log.info()时都需要创建一个新的字符串对象。在需要记录大量日志时,这种方式可能会影响性能。
总结:使用log.info(“获取token:”,userToken);方式更加高效,尤其是在需要记录大量日志时。
最终解决办法心得体会
- 当使用token作为登录机制时放行所有静态文件
- 当打印日志时,最好使用+而不是,方便看效果















 8331
8331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









