







目录
一、图解Adaboost(自适应提升算法)知识图谱
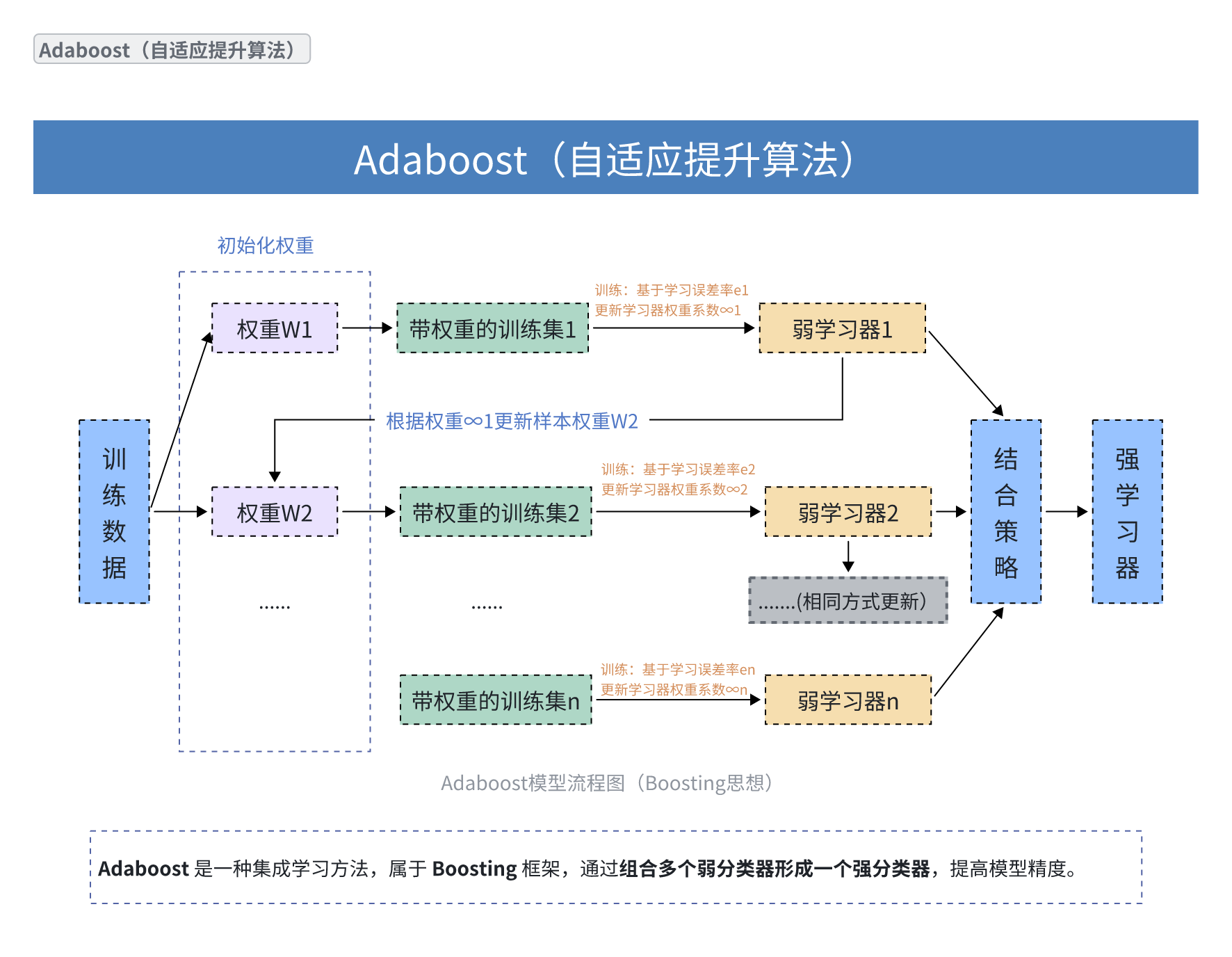
这张图清晰地展示了Adaboost算法的核心思想:通过迭代训练一系列弱学习器,并根据它们的性能动态调整样本权重和弱学习器权重,最终将它们组合成一个强大的集成模型。这正是Boosting算法的精髓所在。
流程图的每个步骤如下:
1.训练数据(左侧蓝色框): 这是算法开始的基础,所有训练样本都从这里开始。
2.初始化权重(蓝色虚线框):
-
首先,为每个训练样本初始化一个权重 W1。通常,在第一次迭代中,所有样本的权重都是相等的。
3.带权重的训练集(绿色框):
-
根据当前的权重,创建一个带权重的训练集1。这意味着在训练过程中,每个样本的重要性会根据其权重进行调整。
4.弱学习器1(黄色框):
-
使用带权重的训练集1来训练一个“弱学习器1”。弱学习器通常是一个简单的模型,例如决策树桩(depth-1 decision tree)。
-
在训练过程中,会基于学习误差 e1 来更新弱学习器的权重系数 α1。
5.根据权重 α1 更新样本权重 W2(箭头指向 W2):
-
弱学习器1的性能(误差 e1)会影响到下一个弱学习器的训练。具体来说,那些被弱学习器1错误分类的样本,其权重会被提高,而正确分类的样本权重会降低。这样,在训练下一个弱学习器时,它会更关注之前难以分类的样本。
6.重复上述过程(W2 到 Wn,以及弱学习器2到弱学习器n):
-
这个过程会迭代进行多次。每次迭代都会根据上一个弱学习器的表现更新样本权重,并训练一个新的弱学习器。
-
每个弱学习器 n 都会基于学习误差 en 更新其权重系数 αn。
7.结合策略(蓝色框):
-
所有训练好的弱学习器(弱学习器1到弱学习器n)会通过一个“结合策略”组合起来。
-
这个结合策略通常是加权投票,每个弱学习器的权重就是其对应的 α 值,表现好的弱学习器(误差小)会有更大的权重。
8.强学习器(最右侧蓝色框):
-
最终,所有弱学习器的加权组合就形成了最终的“强学习器”。这个强学习器的预测能力通常远超任何一个单独的弱学习器。
二、Adaboost 是什么?
Adaboost 是一种集成学习方法,属于 Boosting 框架,通过组合多个弱分类器形成一个强分类器
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











