







目录
一、图解支持向量机(SVM)知识图谱
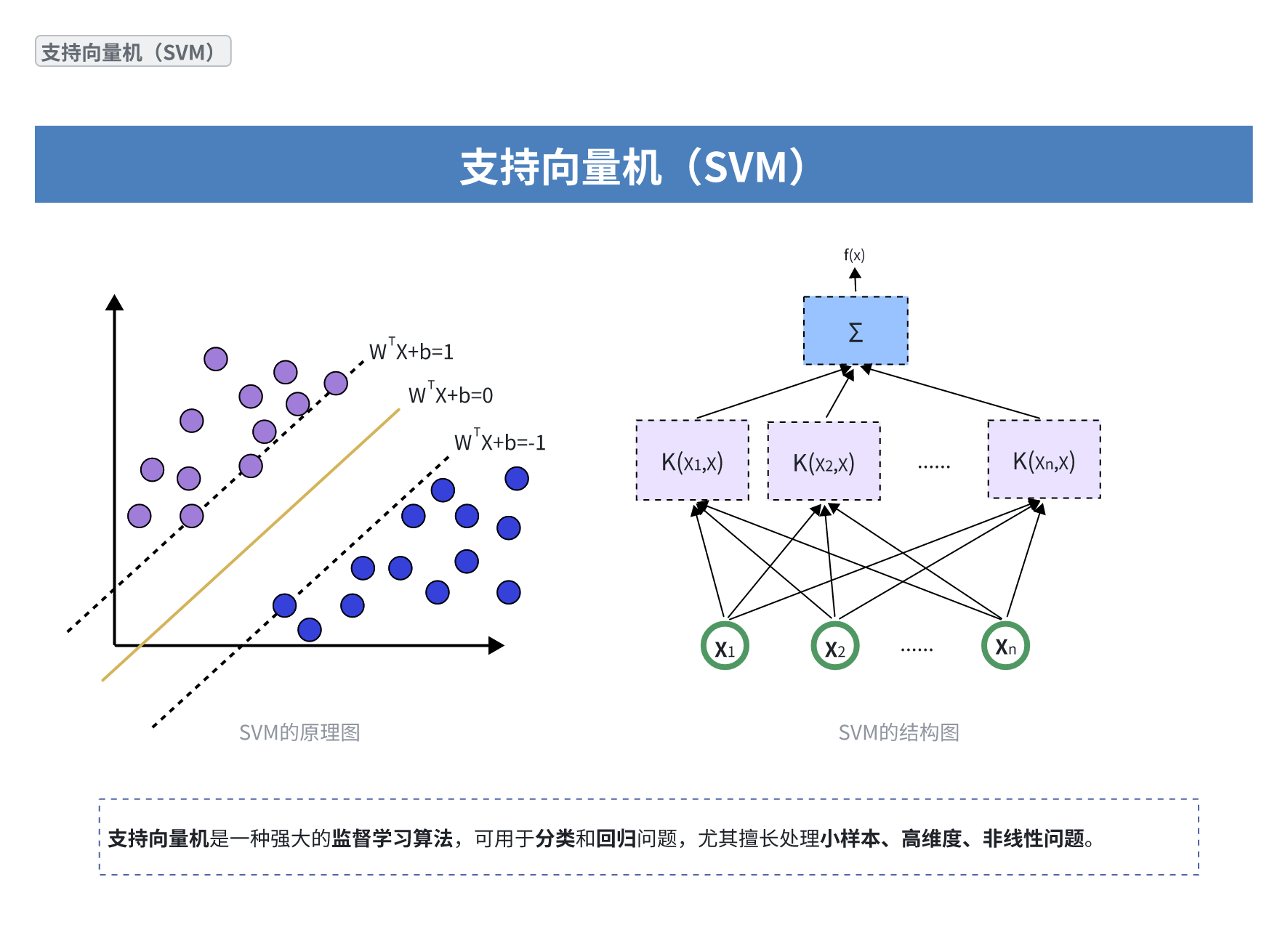
1.SVM的原理图(左侧):
-
这张图展示了SVM如何在一个二维空间中进行分类。
-
它有两类数据点,用紫色和蓝色表示。
-
中间的实线代表了分类超平面(决策边界),其方程为 WTX+b=0。
-
两条虚线表示支持向量所在的超平面,它们是 WTX+b=1 和 WTX+b=−1。这两条线之间的距离就是间隔(margin),SVM的目标是最大化这个间隔。
-
靠近虚线的数据点被称为支持向量,它们是决定分类超平面的关键点。
2.SVM的结构图(右侧):
-
这张图展示了SVM在使用核函数(Kernel Function)时的结构。
-
最底层是输入特征 X1,X2,…,Xn。
-
中间层是核函数 K(Xi,X) 的输出,它将原始特征映射到高维空间。这里 K(X1,X), K(X2,X), ..., K(Xn,X) 表示将每个支持向量 Xi 与输入 X 进行核函数计算。
-
最顶层是输出 f(x),它通常是核函数输出的加权和(通过 Σ 符号表示),并最终决定分类结果。这表明了SVM在处理非线性分类问题时,通过核技巧将其转换为高维空间的线性分类问题。
二、SVM 是什么?
支持向量机是一种强大的监督学习算法,可用于分类和回归问题,尤其擅长处理小样本、高维度、非线性问题。
✅ 本质:在特征空间中,寻找一个最优超平面,使得不同类别的样本被分开,并且边界间隔最大化。
三、SVM 的核心思想
最大间隔分类器(Margin Maximization)
-
在所有可以分开样本的超平面中,选出那个离两类数据“最远”的超平面。
-
样本点中,离超平面最近的点称为支持向量。
-
理论依据:更大的间隔意味着更强的泛化能力。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











