







对于回归问题,我们的目标是要找到一个模型,或者说hypothesis,使之能够:对于我们一个输入,能够返回我们预期的结果。也就是说,假设在我们的数据集和结论集之间存在一个完美的对应关系f使得所有数据集都能正确得出结果,那我们的模型h应该与f之间的差距尽可能的小。
所以,我们靠瞎猜来蒙到这个h肯定是不现实的。我们这时候就会想,虽然我们一开始的模型不怎么贴合f,那么能不能根据已知数据集,一点一点地修正它(具体表现就是f中有很多参数,一步一步修正这些参数,使得它更贴合f),以此达到目的?
对于线性回归问题。
假设变量是线性相关(即都是一维的)
xi代表特征/输入变量
y代表输出/目标变量
m代表训练样本的数量
n代表特征数
则 假设函数
我们定义如下式子(实际上就是很普通的最小二乘)。
这里区别一下,
这个式子反映了所有的样本通过h的映射之后与真实结果之间的差距(这里的差距指的是欧氏距离,实际上还有很多不同的反应距离的方法,例如曼哈顿距离和余弦距离balabala,先不讨论),用来判定我们的模型是好还是坏,很明显,这个式子的值越大,说明结果越烂。
要调整θ使此式尽可能的小,即与实际偏差越来越小。
实际上,这个函数叫做loss函数,损失函数或代价函数。因为它反映了模型得出的结果和真实的结果之间的差距。Loss函数应具有这样的特征:①它是凸函数,可以简单理解为边缘任意两点连接,之间的线段一定全在函数围成的形状内。这个性质保证了梯度下降之后可以达到全局最优解。②它处处可导,不然就不论什么梯度下降了。③模型得出的结果与真实结果偏差越大,loss函数值就越大,也就是说:损失越大。
给他取个名字叫J,自变量是θ(粗体代表向量),也就是那些参数。
所谓梯度下降,就是一种找到使j最小的方法。
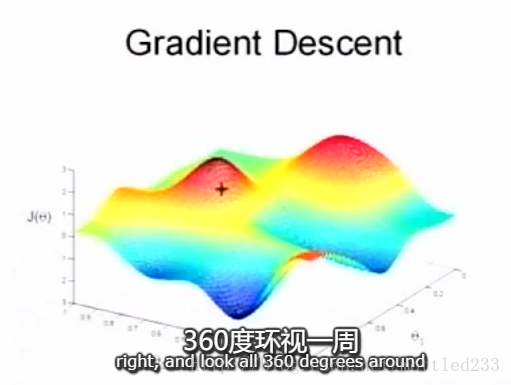
想像站在一座这样的山峰上,十字位置,此时要想最快下山,就要找到最陡峭的方向走一小步,然后再走一小步。通常,十字位置就是零向量(初始点)
梯度下降中,是通过对每个θ,计算
此式中:=是赋值,α表示学习强度(迈步的距离)学习时,会随着离最小值点越近,步子越小,此时不是α变了,而是偏导变小了
实际上
所以此式又可以化成
这种算法也叫批梯度下降法,优点是准确,缺点是对每个θi都要计算所有的样本
这样计算负载很大
另一种思路被称为随机梯度下降法,不是每次都用所有的样本去计算损失函数,而是每次更新都只使用一个样本
缺点也很明显,就是随机性大难以收敛,因为,万一有一个样本很鬼畜,就会拉远数据
所以批梯度下降是平滑地走向最低点,随机梯度下降是一会上一会下但是总体处于下降。















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









