






基础代码
import requests,re,time
from lxml import etree
url = r'https://img.dpm.org.cn/Public/static/CCP/index.html'
base_url = r'https://img.dpm.org.cn/Public/static/CCP/'
def getHtml(url):#获取网页源代码
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'}
html = requests.get(url,headers=header)
return html
def get_titleType_href(html):#获取藏品分类链接
selector = etree.HTML(html.text)
museum_type_href = selector.xpath('//map[@name="Map2"]/area/@href')#获取藏品所有品类
#print(museum_type_href)
return museum_type_href
#这个没用了
def get_collection_details(url):#获取分类列表中的藏品信息
rel_url = base_url+url#拼接url
return rel_url
# print(rel_url)
# html_next = getHtml(rel_url)
# detail_dict = {}
# selector = etree.HTML(html_next.text)
#藏品详情信息取不到
# ddd = selector.xpath('//div[@class="dbody"]/table[@class="dtabcss"]/tbody/tr/td')
# print(len(ddd))
# dd = selector.xpath('//tbody[@id="tabBodyLeft"]/tr')
# print(len(dd))

get_collection_details这个函数就是提取上图所示的藏品编号,名称,时代等信息的,但是通过xpath定位不到。爬出的源码中显示是类似document.write("…")。

定位不到“//tbody[@id=‘tabBodyLeft’]”,所有后续数据提取,清洗也完不成了。
后续
这个可能属于js运行后才显示到页面上的,不会,不清楚,就瞎搞。
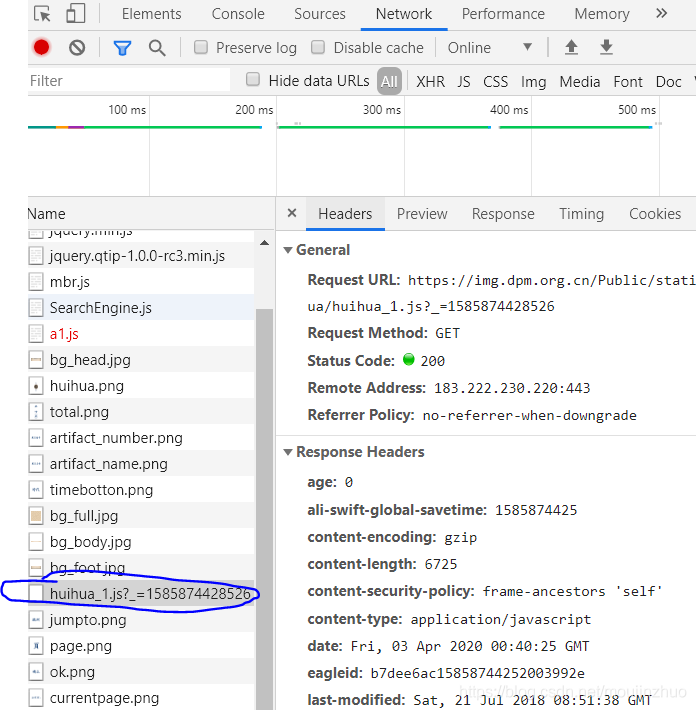
找出来了,点击response,看到它的数据:
“rname”:“任鸣凤花卉册”,“rnum”:“故00005019-2/12”},{“id”:4221760,“rera”:“清”,“rname”:“任鸣凤花卉册”,“rnum”:“故00005019-3/12”},{“id”:4221761,“rera”:“清”,“rname”:“任鸣凤花卉册”,“rnum”:“故00005019-4/12”},{“id”:4221762,“rera”:“清”,“rname”:“任鸣凤花卉册”,“rnum”:“故00005019-5/12”},{“id”:4221763,“rera”:“清”,“rname”:“任鸣凤花卉册”,“rnum”:“故00005019-6/12”},{“id”:4221764,“rera”:“清”,“rname”:“任鸣凤花卉册”,“rnum”:“故00005019-7/12”}]};
这就是其中的部分信息,很像是没有加载到页面上的信息。
那就将它的网址复制,如:https://img.dpm.org.cn/Public/static/CCP/json/huihua/huihua_1.js?_=1585874428526,

显示就是如上图所示,汉字编码格式不对,不能正确显示,但是分析其中的属性,id,rera,rname正好三个属性,对应上了。所有工作就解决了,唯一可能存在的就是字体反爬,必须找到相应文件才能解决,先不管。


分析出来,每个js文件对应页面的六页内容,而链接的其他信息相同,由此得出链接格式模板,可以对链接微调进行多页面爬取了。
总代码
所有分析汇总,加部分实现。
import requests,re,time
from lxml import etree
url = r'https://img.dpm.org.cn/Public/static/CCP/index.html'
base_url = r'https://img.dpm.org.cn/Public/static/CCP/'
def getHtml(url):#获取网页源代码
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'}
html = requests.get(url,headers=header)
return html
def get_titleType_href(html):#获取藏品分类链接
selector = etree.HTML(html.text)
museum_type_href = selector.xpath('//map[@name="Map2"]/area/@href')#获取藏品所有品类
#print(museum_type_href)
return museum_type_href
#这个没用了
def get_collection_details(url):#获取分类列表中的藏品信息
rel_url = base_url+url#拼接url
return rel_url
# print(rel_url)
# html_next = getHtml(rel_url)
# detail_dict = {}
# selector = etree.HTML(html_next.text)
#藏品详情信息取不到
# ddd = selector.xpath('//div[@class="dbody"]/table[@class="dtabcss"]/tbody/tr/td')
# print(len(ddd))
# dd = selector.xpath('//tbody[@id="tabBodyLeft"]/tr')
# print(len(dd))
if __name__=="__main__":
html = getHtml(url)
type_list = get_titleType_href(html)
collection_urls = []#藏品分类网址列表
new_type_list = []#关键字列表
for item in type_list:
collection_urls.append(get_collection_details(item))
key = item.replace('.html','')
new_type_list.append(key)
js_list = []
for i in new_type_list:
for j in range(1,11):
js_url = base_url+"json/"+i+'/'+i+'_'+str(j)+'.js'#拼接js路径
js_url = js_url.replace(' ','')
js_list.append(js_url)
for i in js_list:
try:
xi = getHtml(i).text
name = re.split('/', i)[-1]
name_1 = name.replace('.js','.txt')
with open(r"C:\Users\86188\Desktop\故宫博物馆藏品信息\%s"%(name_1),'w') as f:
f.write(xi)
print("%s写完了!!!"%name_1)
time.sleep(3)
if '9' in i:
time.sleep(10)
except:
print("这个出错了,继续吧!!!")
因为一个绘画类就500多页,由于某些原因,不好用数据库存,就只能写成txt文件,所以也没爬完。相当于每个分类就爬了60页,很多细节也没用处理。最终得到了一个文件夹。就到此结束啦!!!

















 2433
2433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









