






关注公众号,发现CV技术之美
本文为粉丝投稿,原文链接:https://zhuanlan.zhihu.com/p/641872113
本文介绍一篇我们发表于CVPR 2023的论文 《Large-scale Training Data Search for Object Re-identification》 。这篇文章主要介绍了澳大利亚国立大学新推出的训练集搜索任务,和相应的训练集搜索算法(SnP)。
论文链接: https://arxiv.org/pdf/2303.16186.pdf
源代码: https://github.com/yorkeyao/SnP
视频介绍: https://www.bilibili.com/video/BV1sN411S75q/
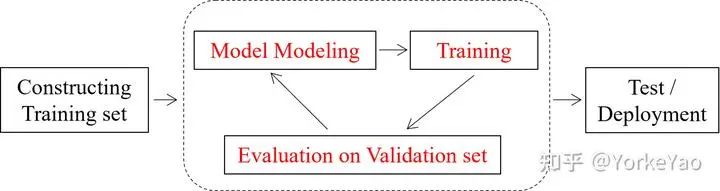
如上图所示,目前的很多研究,是可以归结为在以模型为中心的框架中的。他们的目标是:在固定源训练集和目标验证集的情况下,改进算法或模型。举个例子,对于分类或者检测任务来说,这个过程通常在 ImageNet 和 COCO 等完善的benchmark上进行。
但是试想一下,假如我们希望从头建立一个针对新目标的深度学习系统,我们可能先需要花大量的时间去收集/清理数据,然后才能去花时间配置深度学习网络。
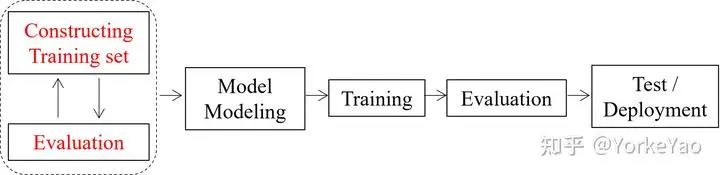
因此,在本文中,我们针对这个数据收集的过程,讨论以数据为中心的一个全新任务:我们的目标不是专注于改进模型或学习算法以提高模型在目标域上的准确度,而是提高训练集质量来实现这一目标。也就是说,在固定目标验证集下,我们的目标是改进源训练数据以提高目标性能。
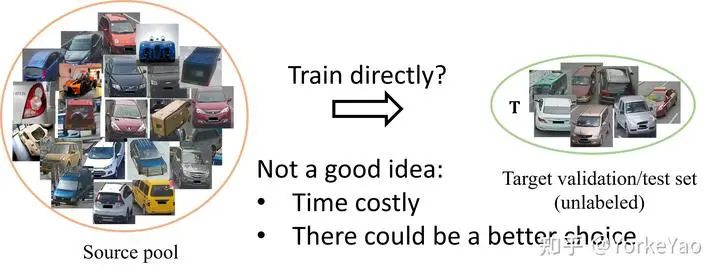
我们考虑这样一个场景:我们可以访问目标域,但无法负担在目标域上的训练数据注释。我们从而希望从大规模数据池构建替代训练集,以便获得有竞争力的模型。对于特定目标,我们指出直接在源池上训练模型可能不是一个好主意。首先,在超大规模的源池上训练模型会花费大量时间。其次,从这个源池中,我们发现我们有可能构建一个更好的训练集,对目标有更高的准确率。
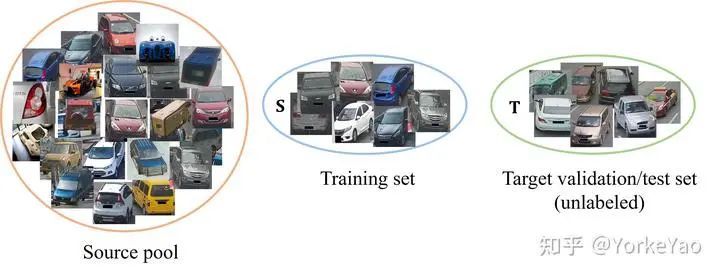
出于这样的动机,我们设定我们的任务目标:我们想从源池中提取图像以形成一个小型训练集,这个训练集虽然规模不大,但可以训练出在目标域上的高精度模型。
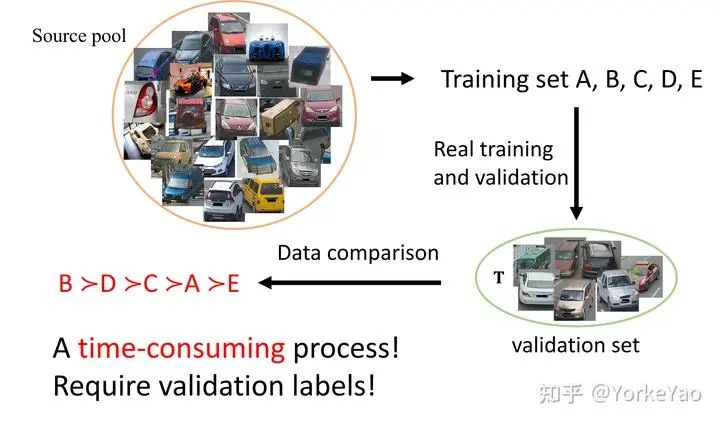
这时候,可能有人会问,我们想知道什么样的训练集比较好,直接训练一下不就可以了?的确,我们可以从真实的训练中选择训练集。如上图所示,从源池中,我们可以选择多个训练集,并进行真正的训练和验证。然后我们可以使用验证集上的准确率进行数据集比较。然而,这样的过程非常耗时,并且需要对验证集进行标记。
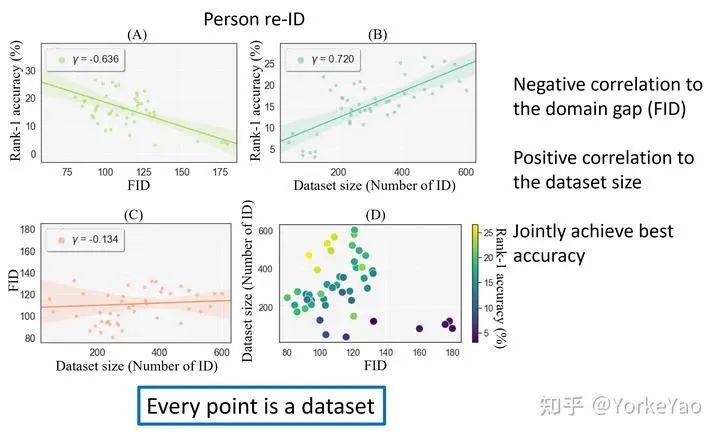
因此,如果我们能找到验证集准确率以外的指标来表明训练集的质量,我们就可以用它来执行训练集搜索。我们通过相关性研究找到了这样的指标。如上图所示,在person re-ID的实验上,我们展示了域差距(domain gap)、数据集大小和在验证集上的性能之间的关系。Pearson相关性表明域差距(domain gap)和验证集准确率之间存在较强的负相关性。数据集大小和验证集准确率之间存在正相关关系。所以,我们得出结论:域差距(domain gap)较小且数据量大的训练集,我们认为它质量更好,训练出来的模型在目标域具有较高的准确率。
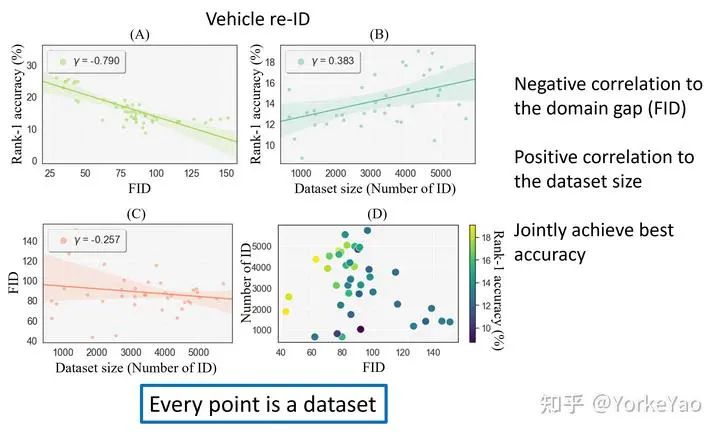
在 vehicle re-ID 上,我们观察到同样的结论 。
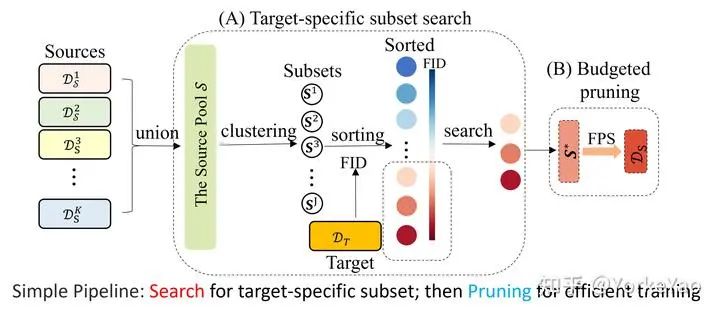
受这一发现的启发,我们在这里展示了所提出的 Search and Pruning (SnP) 方法的工作流程。假设我们有K个现有数据集组成的源池,我们的目标是从这个源池来构建一个满足预算的训练集。为了实现这一目标,我们做(A)子集搜索以获得与目标域差距小的子集,然后执行(B)依据我们对于训练集的具体预算,对A获得的子集进行进一步修剪,获得最终的训练集。
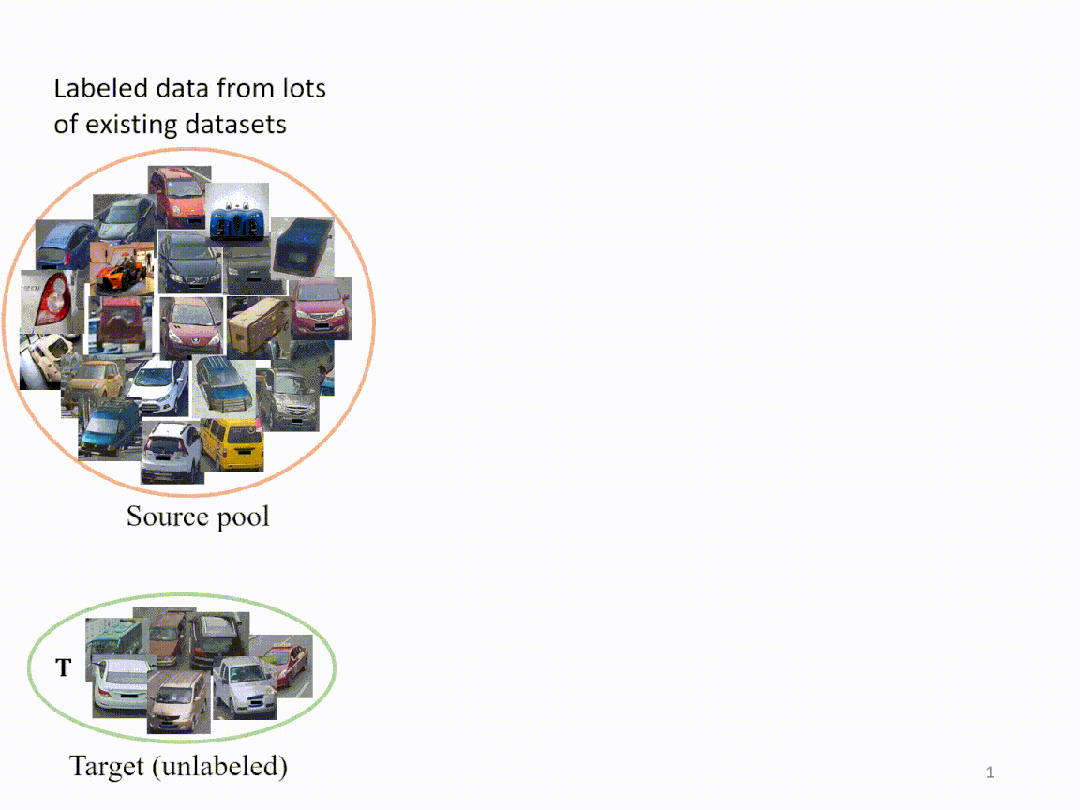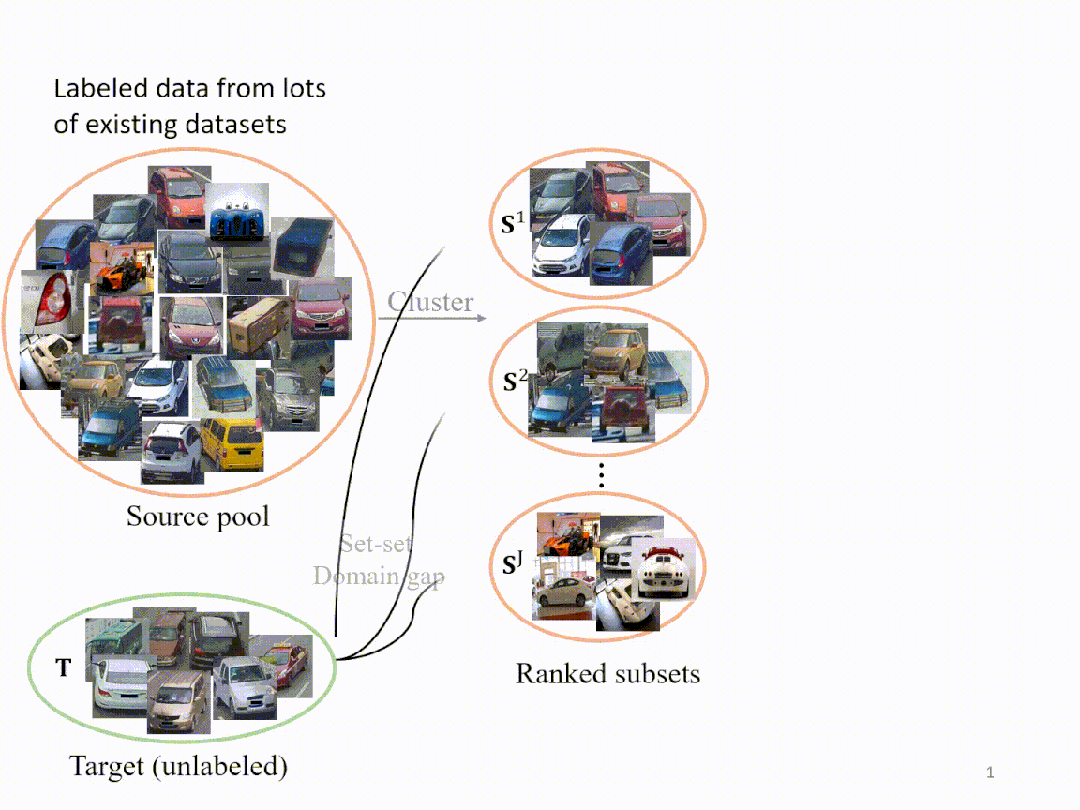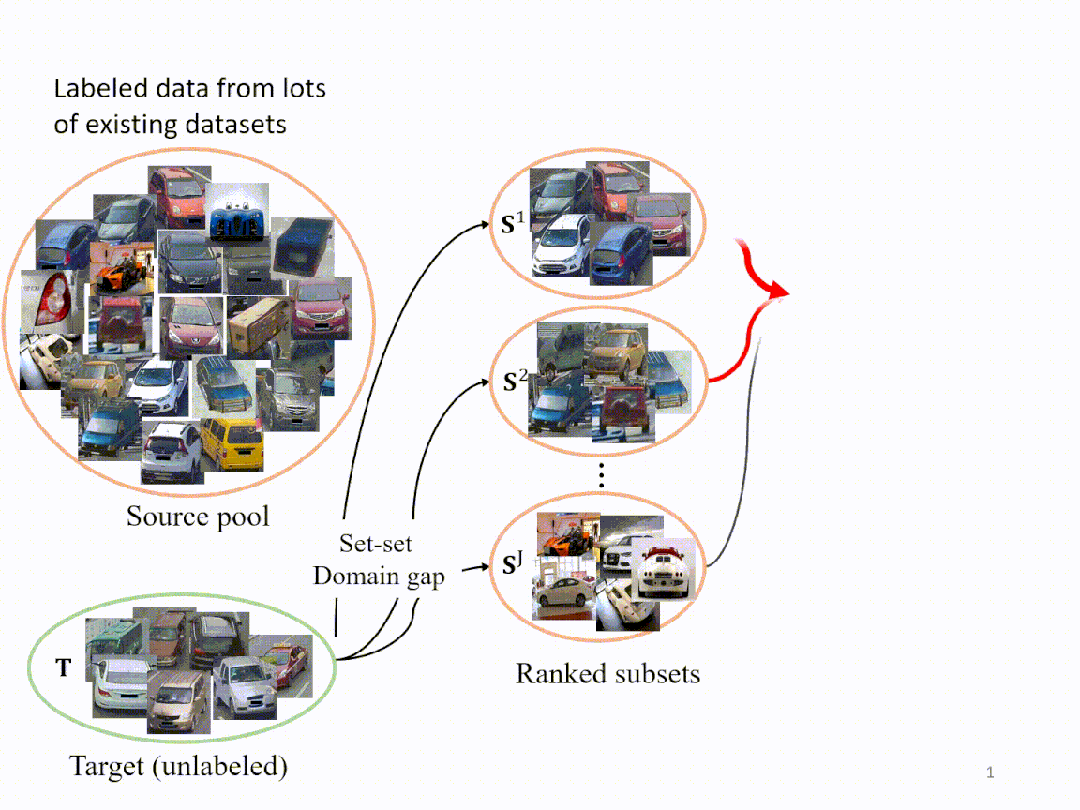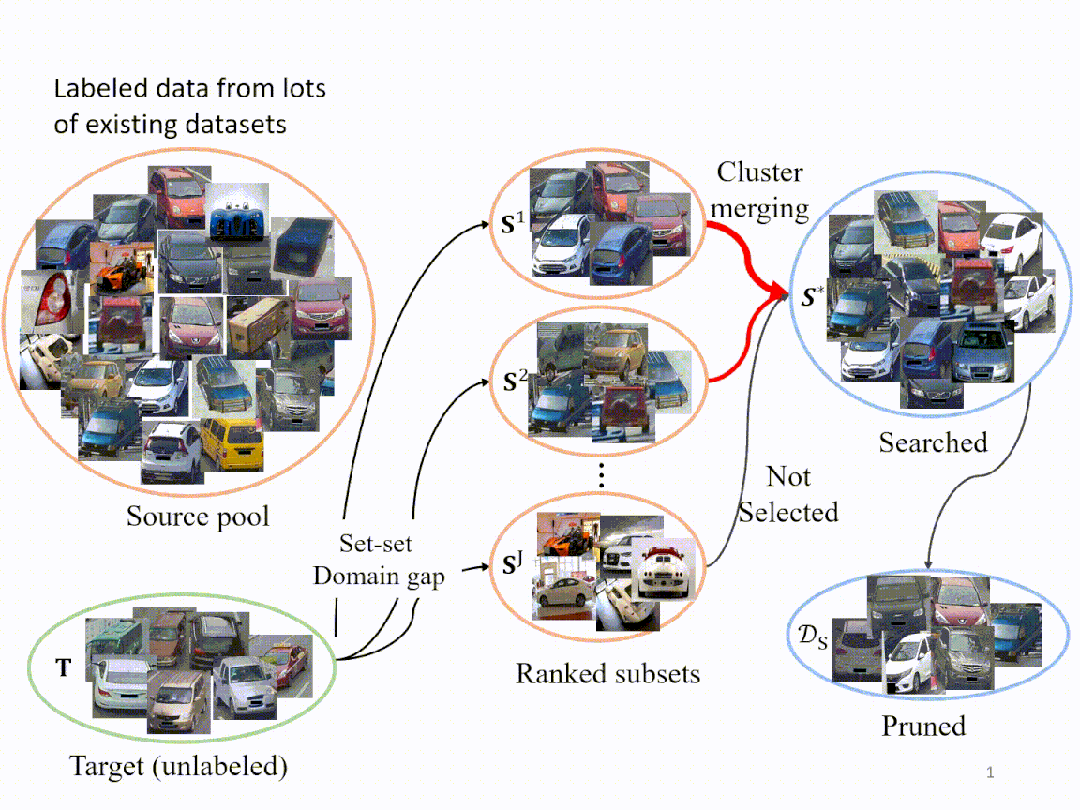
在这里,我们展示了SnP过程的可视化。我们首先从源池中执行聚类,使用 k-means 方法生成 J 个子集。其次,我们计算每个子集与目标之间的域差距(用FID衡量),并按升序对它们进行排序。为了构建搜索结果,我们只添加和合并那些和目标域之间有较低 FID 的子集,丢弃和目标域之间有FID较大的子集。搜索后,我们进行训练集修剪,形成最终的训练集。
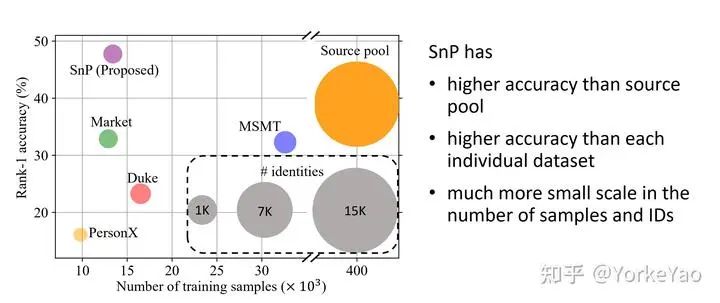
如上图所示,源池在图片数量和ID数量方面比现有的re-ID训练集大一个数量级。使用我们的方法 (SnP) ,我们可以得到比源池小 80% 的训练集,同时实现类似甚至更高的 re-ID 准确度。
具体的实现细节,更多的分析请看我们的文章,并且我们的源代码已开源。欢迎大家提出宝贵意见。

END
加入「物体重识别」交流群👇备注:重识别
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









