






关注公众号,发现CV技术之美
导语
阿联酋起源人工智能研究院(IIAI)科学家提出了一种新颖的人脸关键点检测方法PIPNet,通过融合坐标回归和热力图回归的优势,并结合半监督学习充分利用大量无标注数据提升跨域的泛化性能,最终得到一个又快又准又稳的人脸关键点检测器。相关论文已被IJCV 2021接收。

论文:https://arxiv.org/abs/2003.03771
代码:https://github.com/jhb86253817/PIPNet
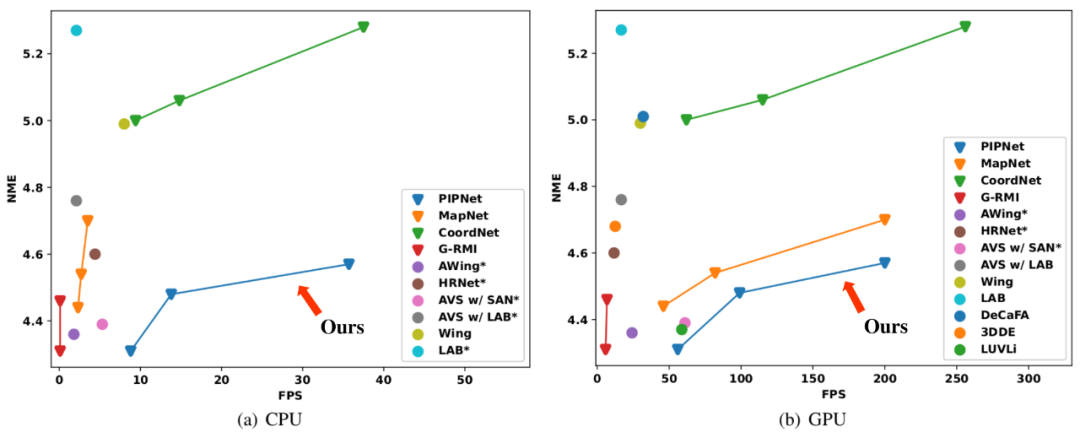
图1. 又快又准:与现有方法在WFLW上的精度与速度的平衡对比(右下角最好)
(a)
(b)
图2. 稳!视频效果图
▊ 简介
人脸关键点检测是人脸相关应用中一个重要的前置任务,而人脸应用往往具有实时性和不确定性,这使得关键点模型不仅要有较高的精度,同时也要满足计算速度快和抗干扰能力强的特点。然而,现有的方法通常无法同时满足这三个条件。
例如,基于热力图回归的方法能达到较高的精度,但往往计算量也大,且对离群样本敏感。相反地,基于坐标回归的单阶段方法速度快而且鲁棒,然而预测精度并不高。尽管坐标回归可以扩展成多阶段方法来提高精度,但其计算代价也随之上升。此外,关键点模型的跨领域泛化能力也是一项挑战。
为了得到一个适用于真实应用的人脸关键点模型,本文基于上述挑战提出嵌套网络(PIPNet)模型。该模型主要包含三个重要模块。
首先是一个新颖的检测头,称作嵌套回归(PIP regression)。该方法将关键点定位任务分解成了基于低分辨率特征图的热力图回归和局部特征图上的坐标回归,使模型在不依赖高分辨率特征图的情况下依然具有较高的精度,从而节省了计算量。
此外,我们在检测头上额外设计了近邻回归模块,通过训练每个关键点根据自己的位置定位它的近邻关键点,使得在预测时能得到局部区域的形状约束,从而提升模型的鲁棒性。
最后,我们提出一种基于自训练的半监督学习方法来充分利用大量无标注的不同场景下样本。该方法在对无标注样本估计伪标签时,首先从简单的任务开始,然后在后续迭代中逐渐增加任务的难度,直到变成标准的自训练任务,有效缓解了标准自训练方法在伪标签中引入的噪声问题。
最终,我们设计的人脸关键点检测器PIPNet达到了又快又准(见图1精度和速度对比图)又稳(见图2视频展示)的效果,特别契合实际应用。根据六个主流数据集上的实验结果,本文提出的PIPNet在三个数据集上取得了领先的预测性能。此外,该模型在精度与速度的平衡以及跨数据集测试的实验中,均达到了领先水平。
▊ 研究动机
虽然人脸关键点检测在近几年得到了快速发展,但少有工作对相关的检测头进行改进。热力图回归(heatmap regression)和坐标回归(coordinate regression)是关键点检测模型最常用的两种检测头,且它们各有利弊。
热力图回归擅长对单个关键点精准定位,但面对困难样本时,例如大面积遮挡、较大的转动角度等,热力图输出的部分关键点容易产生较大偏移,从而影响整体的预测结果。
此外,热力图回归需依赖高分辨率特征图,这给轻量级设备上的部署带来了更多计算负担。与其相反,坐标回归并不依赖高分辨率特征,且通过全局特征直接输出所有关键点的坐标,这使得它的预测具有全局形状约束,较为鲁棒,但平均每个点的精度并不高。
可以看到,这两个检测头的特点可以说是互补的,直接使用其中一个会顾此失彼。这也引发了我们的思考,有没有可能把两者的优势结合起来呢?
答案是肯定的。考虑到关键点定位和目标检测任务的相似性,既然目标检测用低分辨率特征就能准确定位,那关键点为什么不能呢?
因此,我们认为经典的热力图回归将特征图上采样是没有必要的。启发于目标检测任务,当模型认为当前位置存在目标时,可直接回归预测目标点的位置,这便是我们提出的嵌套回归(pixel-in-pixel regression, PIP regression)。
此外,考虑到坐标回归法的鲁棒性来源于特征共享,受此启发,我们提出在局部预测某个目标点偏移量的同时,也让它用同一个特征向量预测该目标点近邻的偏移量,这样就可以学到类似坐标回归的形状约束。以上便是近邻回归模块(neighbor regression module, NRM)的设计思想。图3展示了不同检测头的区别。
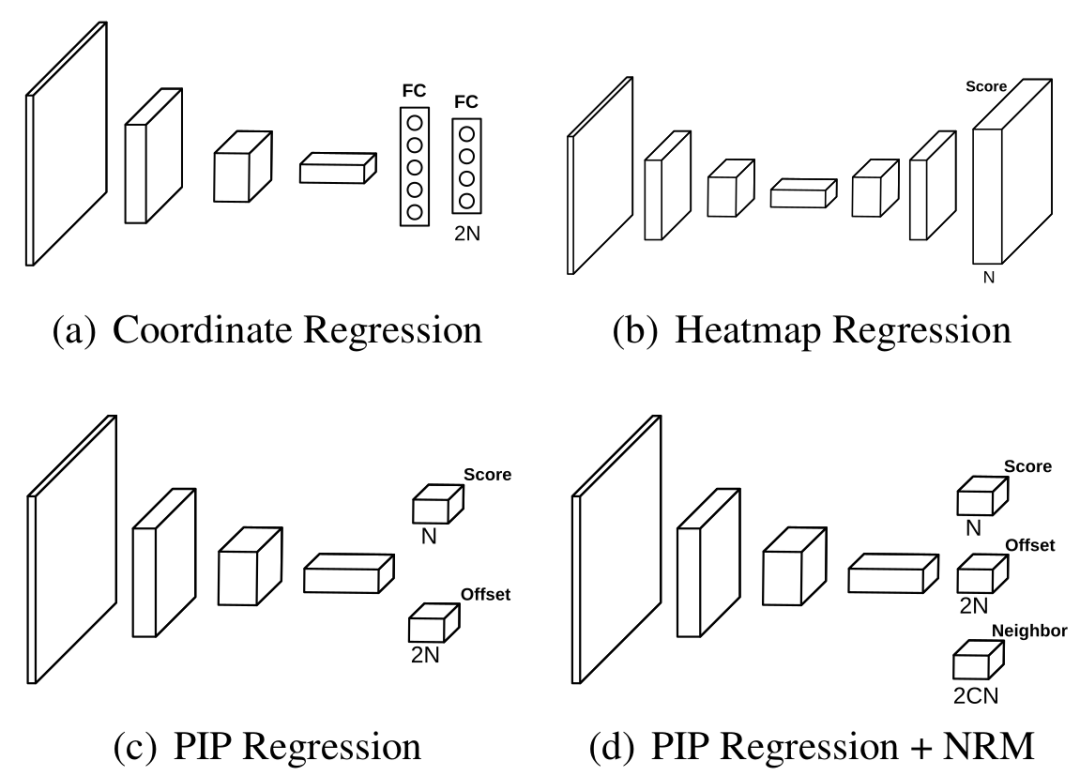
图3. 不同检测头的区别
除了速度和稳定性,跨领域泛化对关键点任务也是一项挑战。对于该问题,之前的工作一般由人工设计好模型,通过监督学习训练,最终直接在跨领域数据集测试来表明其泛化性能。我们称这种范式为可泛化的监督学习(generalizable supervised learning, GSL)。
该范式的缺点是依赖人工经验设计模块,不具有可扩展性。因此,我们提出了可泛化的半监督学习(generalizable semi-supervised learning, GSSL)范式,即利用大量跨领域的无标注数据来提升模型的跨领域泛化性能。
与GSL相比,我们提出的范式更具有扩展性,因为其是数据驱动的,且无标签数据也容易收集。图4展示了不同范式之间的区别。
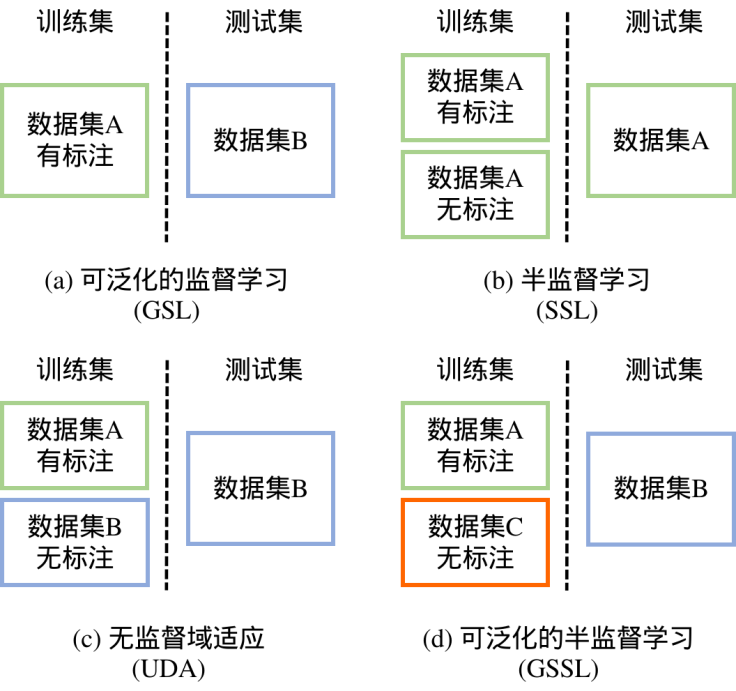
图4. 不同训练/测试范式的区别
▊ 方法介绍
嵌套回归法: 通过图3(b)和(c)的对比,可以看到嵌套回归相比于热力图回归,除了特征图分辨率的差别,其额外需要在每个位置上预测所有点在x和y轴方向上的偏移量。图5则展示了嵌套回归训练时标签的生成机制。
假设图5(a)中的红点是当前的目标关键点,我们首先根据其标注计算出该点会落到特征图的哪一个格子里,那么相应格子的分类标签设为1,其余格子均为0 (图5(2))。
其次,假设目标点在该格子内的横向位移为0.3(位移范围0到1),纵向为0.8,那么x位移图和y位移图相应的格子上的标签分别为0.3和0.8,其余格子依然为0。该检测头的损失函数由两部分组成:
1)每个格子是否包含目标点的分类损失函数;
2)每个格子内目标点偏移量的回归损失函数。
然后两者通过平衡系数相加。需要注意的是,有关偏移量的损失函数只在分类图上相应格子标签为1时才计算。具体公式请详见论文。

图5. 嵌套回归及近邻回归模块训练标签的生成机制
值得一提的是,嵌套回归可以看作是热力图回归和坐标回归的一种一般化的形式。换句话说,嵌套回归可以被看作是在全局进行热力图回归而在局部进行坐标回归,这也是其名字的由来。
近邻回归模块: 嵌套回归可以很容易地增加近邻回归模块。如图3(d)所示,只需额外在每个格子上预测每个目标点的C个近邻的偏移量即可。但是每个目标点应该预测哪C个近邻呢?
我们的做法是,根据训练标注计算出平均脸的关键点,然后根据欧氏距离找出离目标关键点最近的C个即可(不包括它自己)。对于训练时该模块的标签,假设图5(a)中的蓝点为目标点(红点)的其中一个邻居,可以看到蓝点相对红点所在格子在x、y上的偏移量为1.8(该模块偏移量可大于1)和0.7,那么近邻偏移图中相应的格子标签设为1.8和0.7,其余均为0。近邻回归模块的损失函数与目标点的偏移量类似,不再赘述。
在推断时,每个点自己的预测结果会和其他点对它的预测进行平均,从而得到最终的预测。实验显示,近邻数为10个左右性能较好。图6展示了在WFLW比较难的样本上,近邻回归模块对预测结果的改进。

(a)没有近邻回归模块

(b)有近邻回归模块
图6. 是否包含近邻回归模块在模型鲁棒性上的差别。其中,绿色点为标注,红色为预测值。
循序渐进的自训练方法: 为了更好地利用跨领域的无标注数据来提升模型性能,我们提出循序渐进的自训练方法(self-training with curriculum, STC)。
其思想为,在用自训练法估计伪标签时,一开始在较简单的任务上进行,然后逐渐增加难度直至标准的任务,这样可以减少因错误的伪标签带来的标签噪声。图7展示了适用于STC的模型框架,可由PIPNet扩展得到。
该方法的思想与课程学习(curriculum learning)类似,但不同的是,课程学习是基于样本的循序渐进而本文方法是基于任务的。
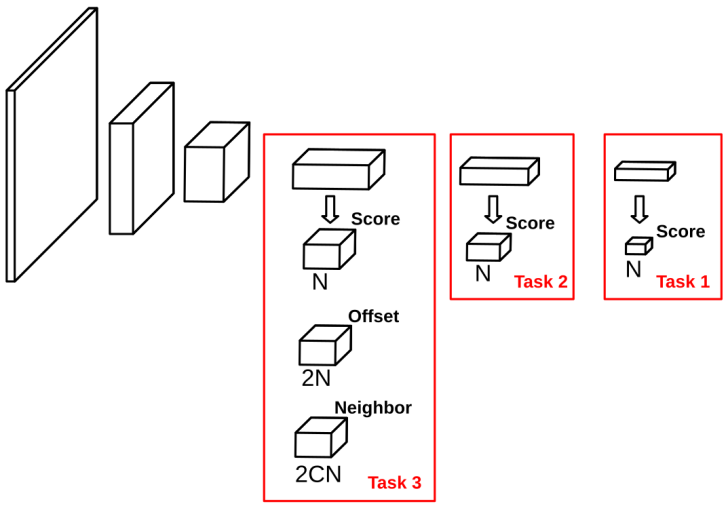
图7. 适用于STC的PIPNet架构
▊ 实验结果
监督学习:表1展示了模型与现有方法在300W,COFW和AFLW上的结果比较。可以看到,在不使用额外数据时,PIPNet在COFW和AFLW上均取得了最好的精度(NME越低,精度越高)。
表2显示,在WFLW的完整测试集上,PIPNet同样取得了最优。表3中的300VW则是一个基于视频片段的数据集,因此已有方法一般会额外利用时序信息提升性能。
由于视频关键点检测不是本文的重点,因此我们在不利用时序信息的情况下用PIPNet进行预测,可以看到,我们的模型依然取得了最好的预测结果。
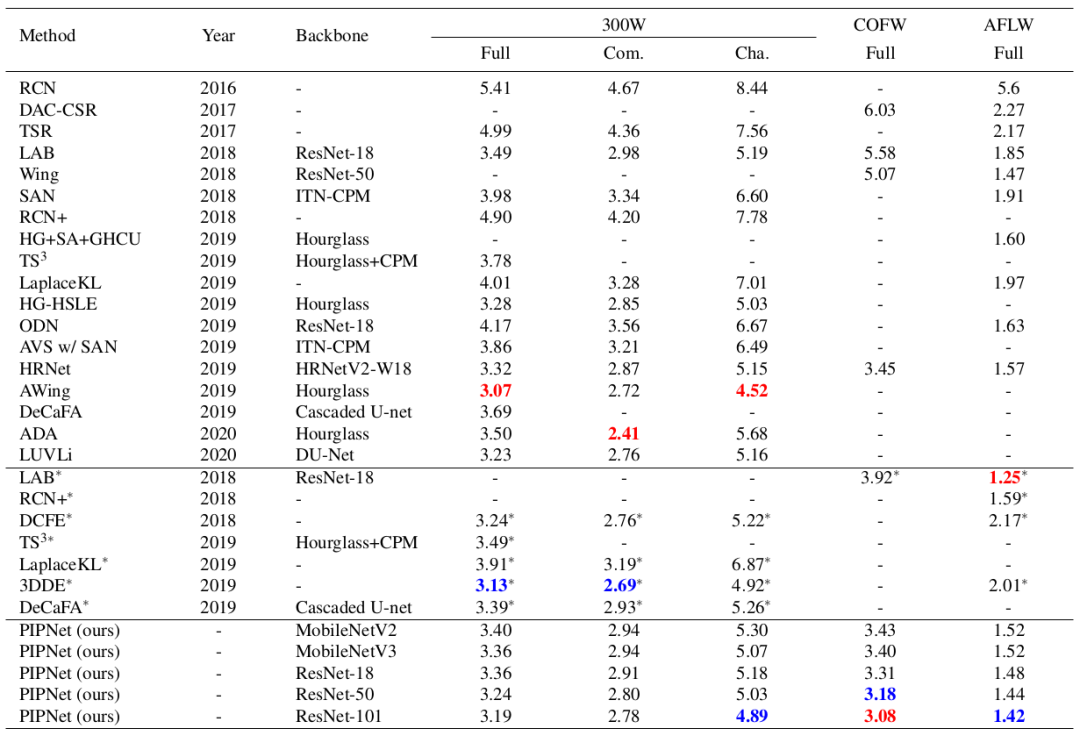
表1. 与基于监督学习的方法在300W、COFW和AFLW上的结果比较
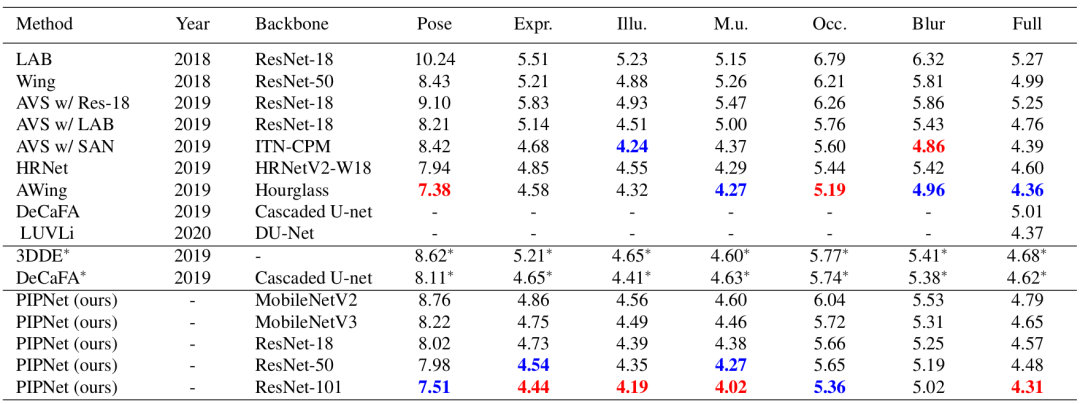
表2. 与基于监督学习的方法在WFLW上的结果比较
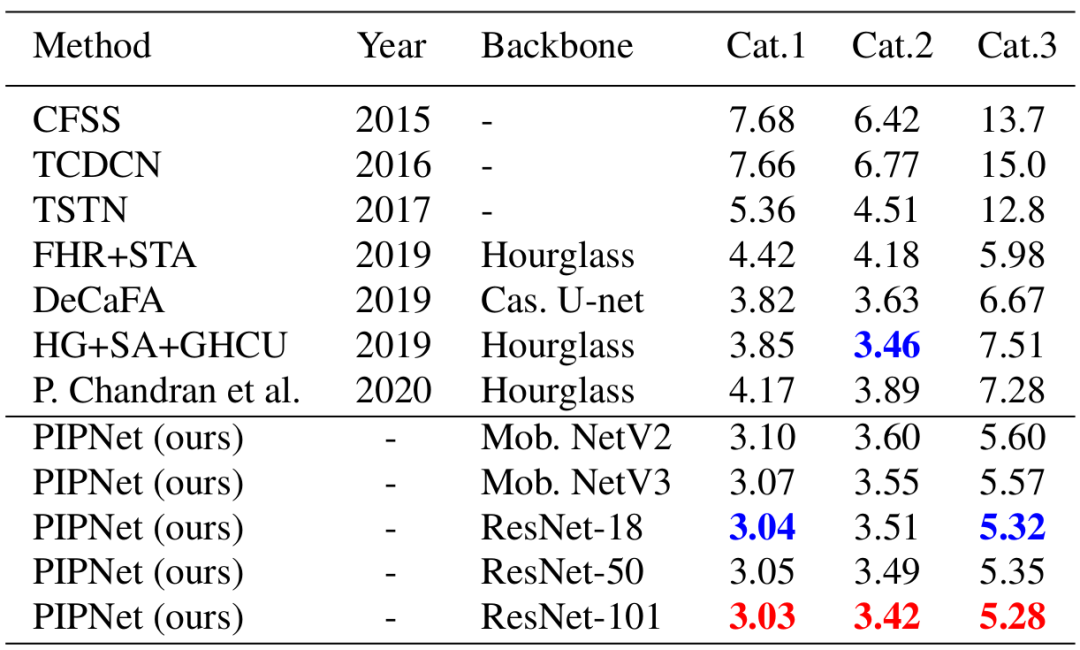
表3. 与现有方法在视频数据300VW上的结果比较
半监督学习:表4展示了STC与基线方法的比较。其中,300W的训练集带有标注,无标注数据集来自COFW和WFLW或CelebA。可以看到,STC无论是与直接跨领域测试,还是与经典的UDA方法DANN以及标准自训练法比较,均取得了更好的结果。
表5展示了与现有方法在跨领域泛化性能上的比较。之前的方法基本遵循在300W上训练,然后直接在测试集上测试(即GSL)。同样遵循这一模式,PIPNet在COFW-68上仅落后于AVS。
而当充分利用CelebA中的无标注数据后,模型在COFW-68上的跨领域性能大幅提高,并超越了AVS,这既表明了STC的有效性,也显示了GSSL范式在实际应用中的可行性。
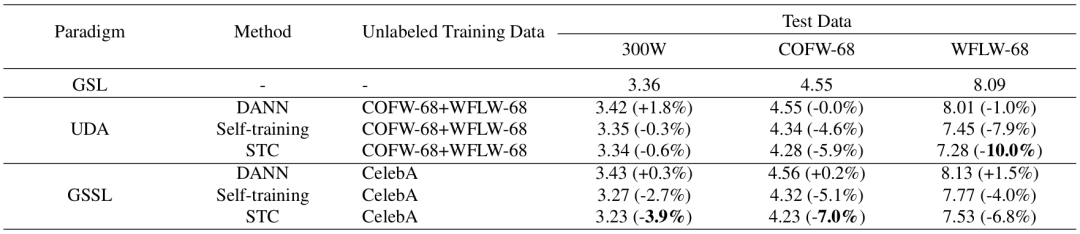
表4. STC与基线方法的比较
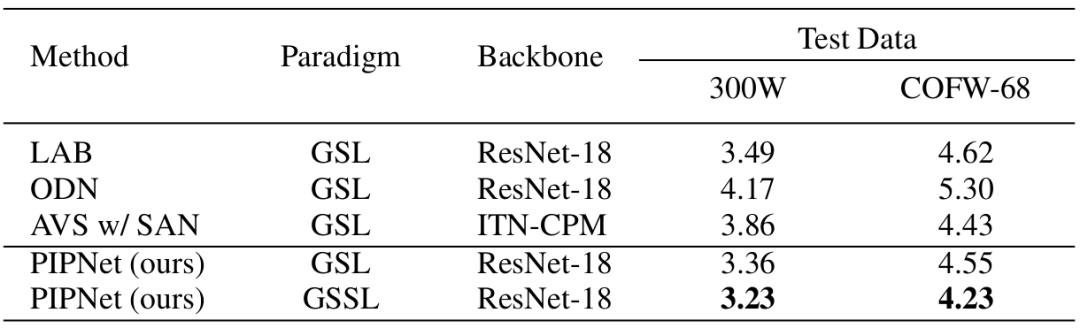
表5. STC与已有方法在同领域及跨领域测试集上的结果比较
速度:为了说明PIPNet在推断速度上的优势,我们与之前的方法比较模型在精度和速度上的平衡。如图1所示,PIPNet在CPU和GPU上均取得了最优的平衡(越靠近右下角越好),尤其是CPU上的优势更为明显。因此,PIPNet很适合计算资源受限的场景。
▊ 结语
针对实际应用场景的需求,我们在不牺牲精度的前提下,提出了一个高效且鲁棒的人脸关键点检测器。该检测器包含一个新的检测头,通过将定位任务分解成低分辨率特征图上的热力图回归和局部特征的坐标回归,减少了不必要的计算负担。
在此基础上,增加的近邻回归模块引入了局部形状约束,从而增强了鲁棒性。最后,所提出的模型通过与改进的自训练方法相结合,能利用大量跨领域的无标注数据进行半监督学习,从而提升跨领域的泛化性能。因此,本文所提出的方法为真实场景下的人脸关键点检测提供了一种可行的解决方案。

END
欢迎加入「人脸技术」交流群👇备注:人脸
















 4375
4375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









