






关注公众号,发现CV技术之美
智源和香港中文大学联合提出的 M3D 系列工作,包括 M3D-Data, M3D-LaMed, 和 M3D-Bench, 从数据集、模型和测评全方面推动 3D 医学图像分析的发展。
M3D-Data 是目前最大的 3D 医学图像数据集,包括 M3D-Cap (120K 3D 图文对), M3D-VQA (510K 问答对),M3D-Seg(150K 3D Mask),M3D-RefSeg (3K 推理分割)共四个子数据集。
M3D-LaMed 是目前最多功能的 3D 医学多模态大模型,能够解决文本(疾病诊断、图像检索、视觉问答、报告生成等),定位(目标检测、视觉定位等)和分割(语义分割、指代分割、推理分割等)三类医学分析任务。
M3D-Bench 能够全面和自动评估 8 种任务,涵盖文本、定位和分割三个方面,并提供人工校验后的测试数据。
我们最早于 2024年4月 发布了数据集、模型和代码。近期,我们提供了更小和更强的M3D-LaMed-Phi-3-4B模型,并增加了线上 demo 供大家体验!最新进展请关注 GitHub 仓库的更新 ,如果有任何疑问和建议可以及时联系,欢迎大家讨论和支持我们的工作。
论文:https://arxiv.org/abs/2404.00578
代码:https://github.com/BAAI-DCAI/M3D
模型:https://huggingface.co/GoodBaiBai88/M3D-LaMed-Phi-3-4B
数据集:https://github.com/BAAI-DCAI/M3D?tab=readme-ov-file#data
线上Demo:https://e7e9a4f07f93722d27.gradio.live/ (国内体验地址在评论区)
我们能为医学图像相关研究者提供什么?
M3D-Data, 最大的 3D 医学多模态数据集;
M3D-Seg, 整合了几乎所有开源 3D 医学分割数据集,共计 25 个;
M3D-LaMed, 支持文本、定位和分割的最多功能的 3D 医学多模态大模型,提供了简洁清晰的代码框架,研究者可以轻易魔改每个模块的设置;
M3D-CLIP,基于M3D-Cap 3D 图文对,我们训练了一个图文对比学习的 M3D-CLIP 模型,共提供其中的视觉预训练权重 3DViT;
M3D-Bench,全面和清晰的测评方案和代码。
本文涉及的所有资源全部开放,希望能帮助研究者共同推进 3D 医学图像分析的发展。
线上Demo视频
摘要
医学图像分析对临床诊断和治疗至关重要,多模态大语言模型 (MLLM) 对此的支持日益增多。然而,先前的研究主要集中在 2D 医学图像上,尽管 3D 图像具有更丰富的空间信息,但对其的研究和探索还不够。
本文旨在利用 MLLM 推进 3D 医学图像分析。为此,我们提出了一个大规模 3D 多模态医学数据集 M3D-Data,其中包含 120K 个图像-文本对和 662K 个指令-响应对,专门针对各种 3D 医学任务量身定制,例如图文检索、报告生成、视觉问答、定位和分割。此外,我们提出了 M3D-LaMed,这是一种用于 3D 医学图像分析的多功能多模态大语言模型。此外,我们引入了一个新的 3D 多模态医学基准 M3D-Bench,它有助于在八个任务中进行自动评估。
通过综合评估,我们的方法被证明是一种稳健的 3D 医学图像分析模型,其表现优于现有解决方案。所有代码、数据和模型均可在以下网址公开获取:https://github.com/BAAI-DCAI/M3D。
数据集
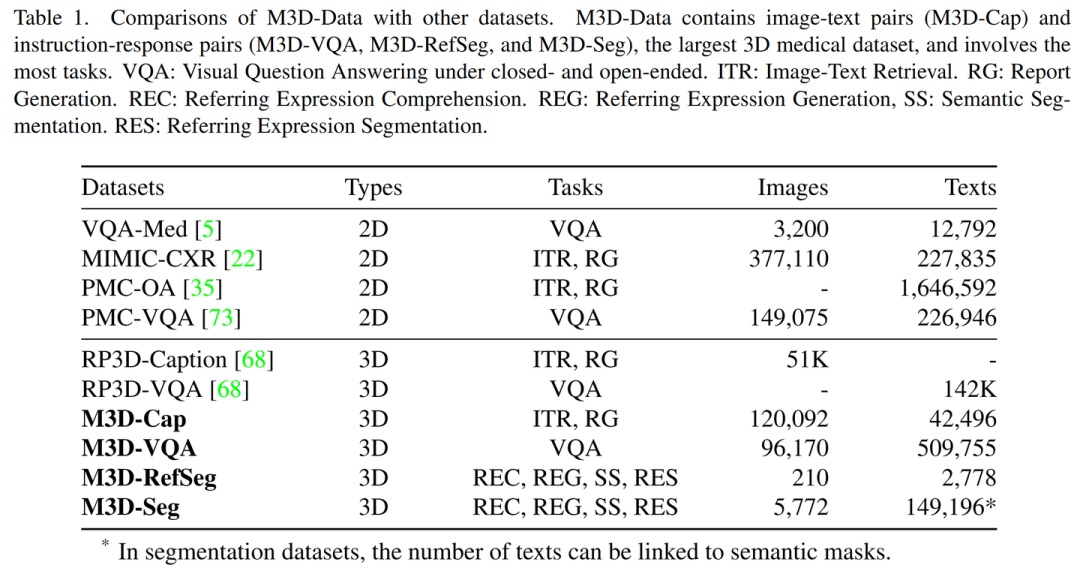
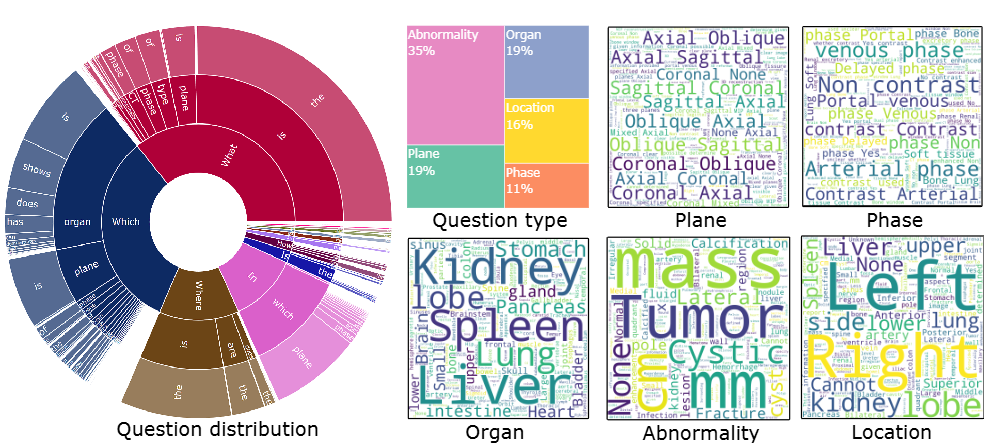
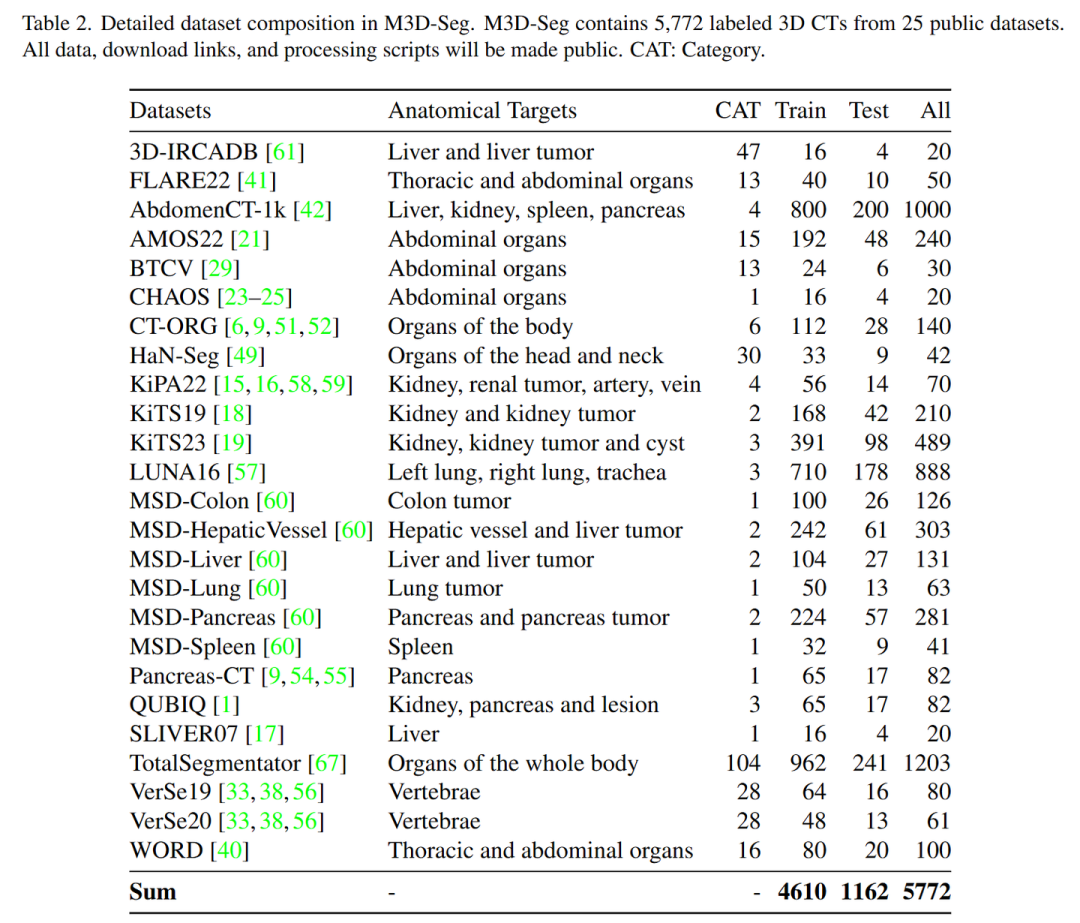
模型
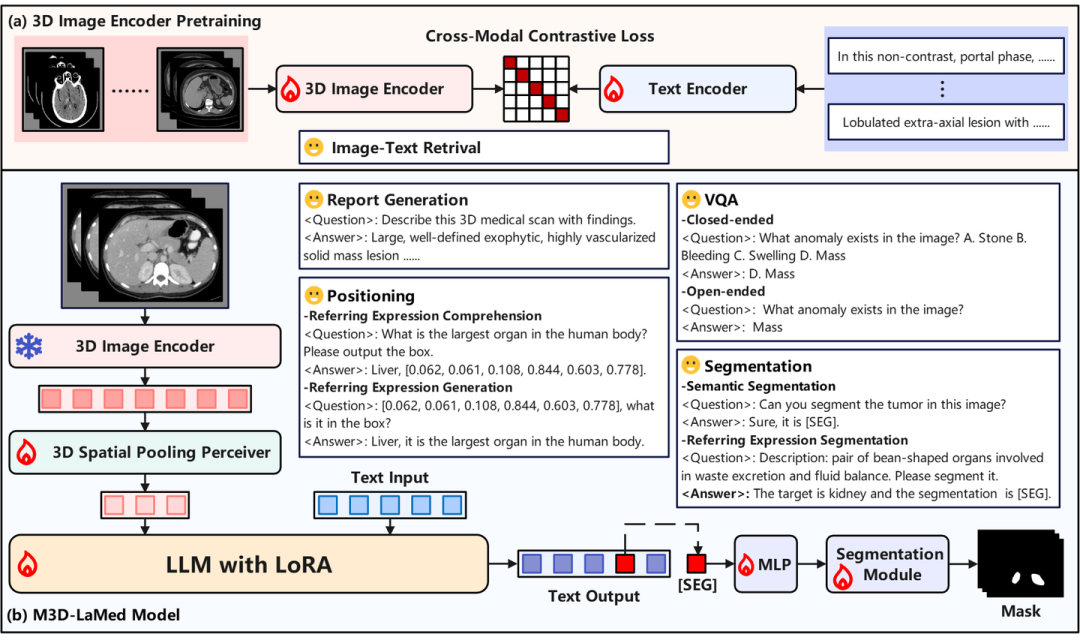
实验
图文检索
在 3D 图文检索中,模型旨在根据相似性从数据集中匹配图像和文本,通常涉及两个任务:文本到图像检索 (TR) 和图像到文本检索 (IR)。

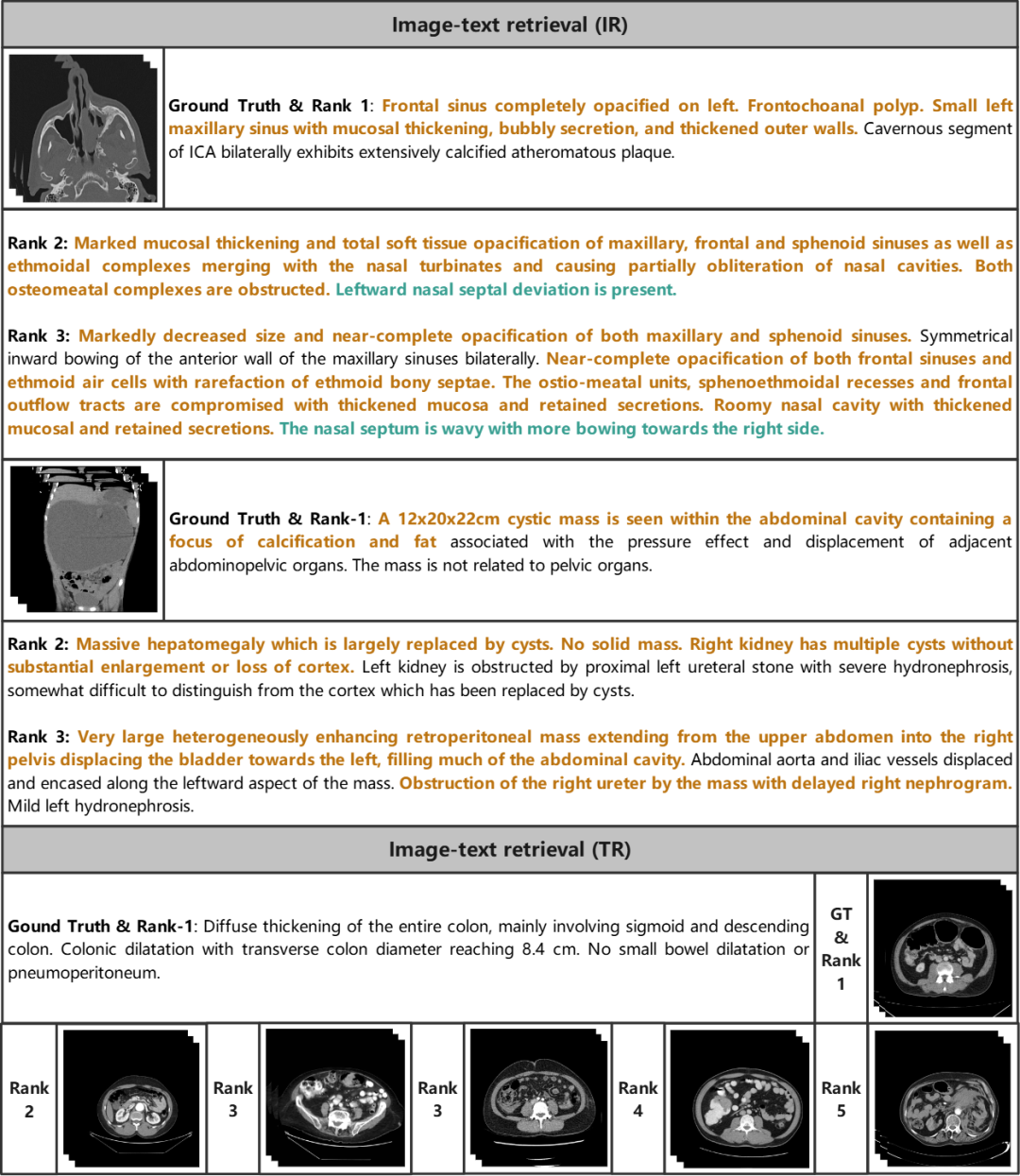
报告生成
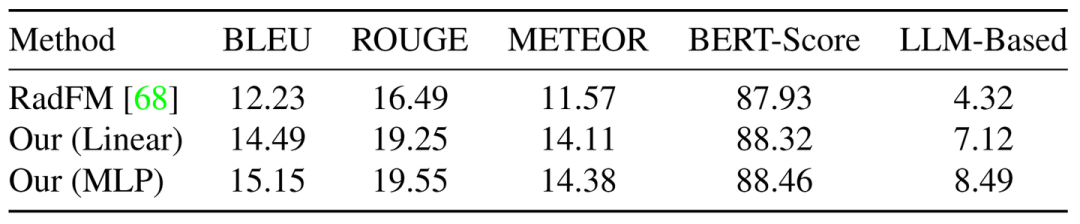
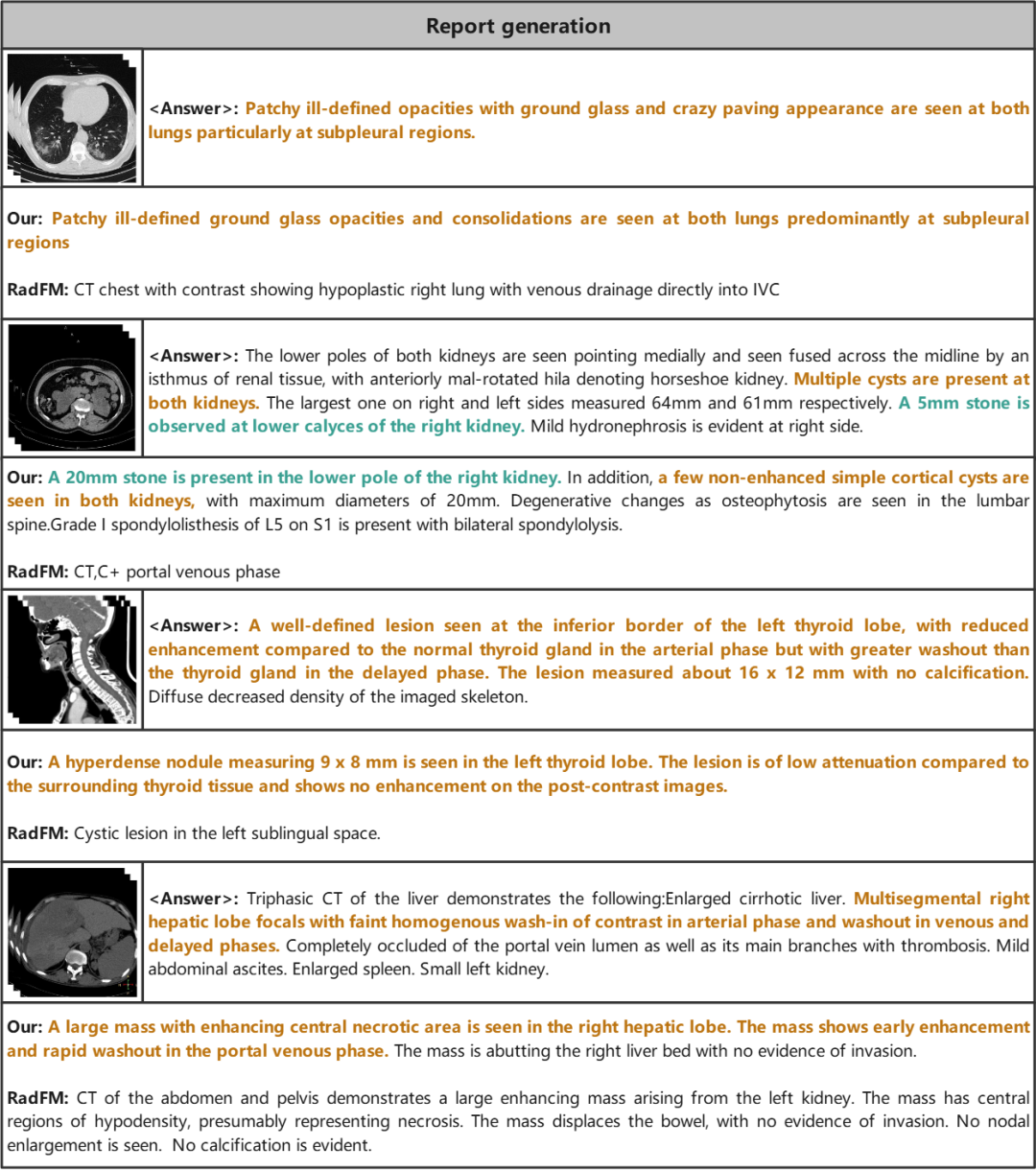
在报告生成中,该模型根据从 3D 医学图像中提取的信息生成文本报告。
封闭式视觉问答
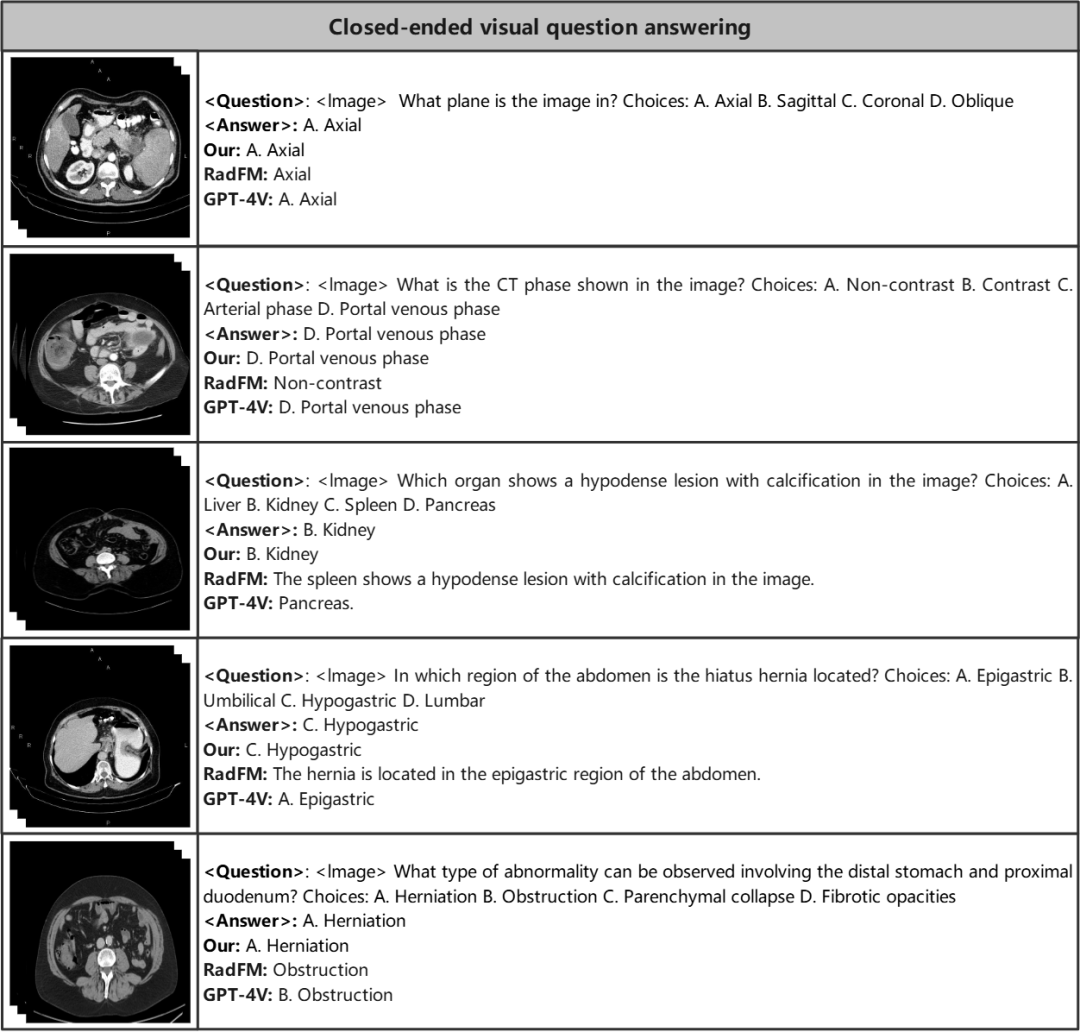
在封闭式视觉问答中,需要为模型提供封闭的答案候选,例如A,B,C,D,要求模型从候选中选出正确答案。

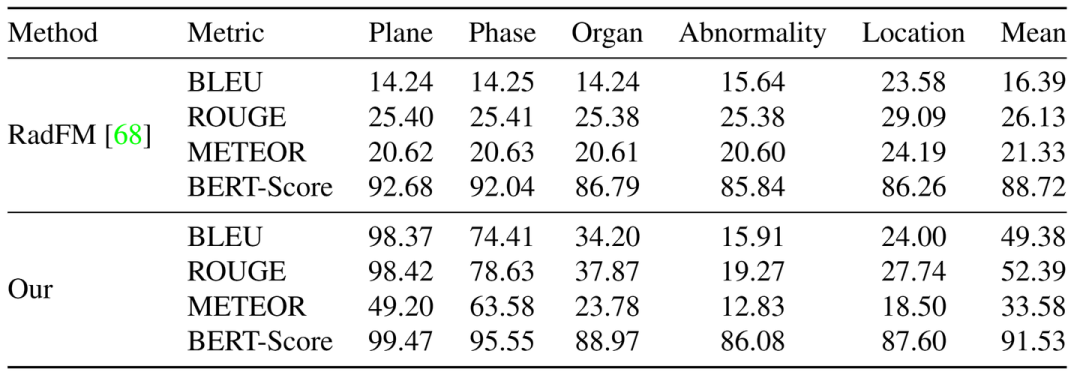
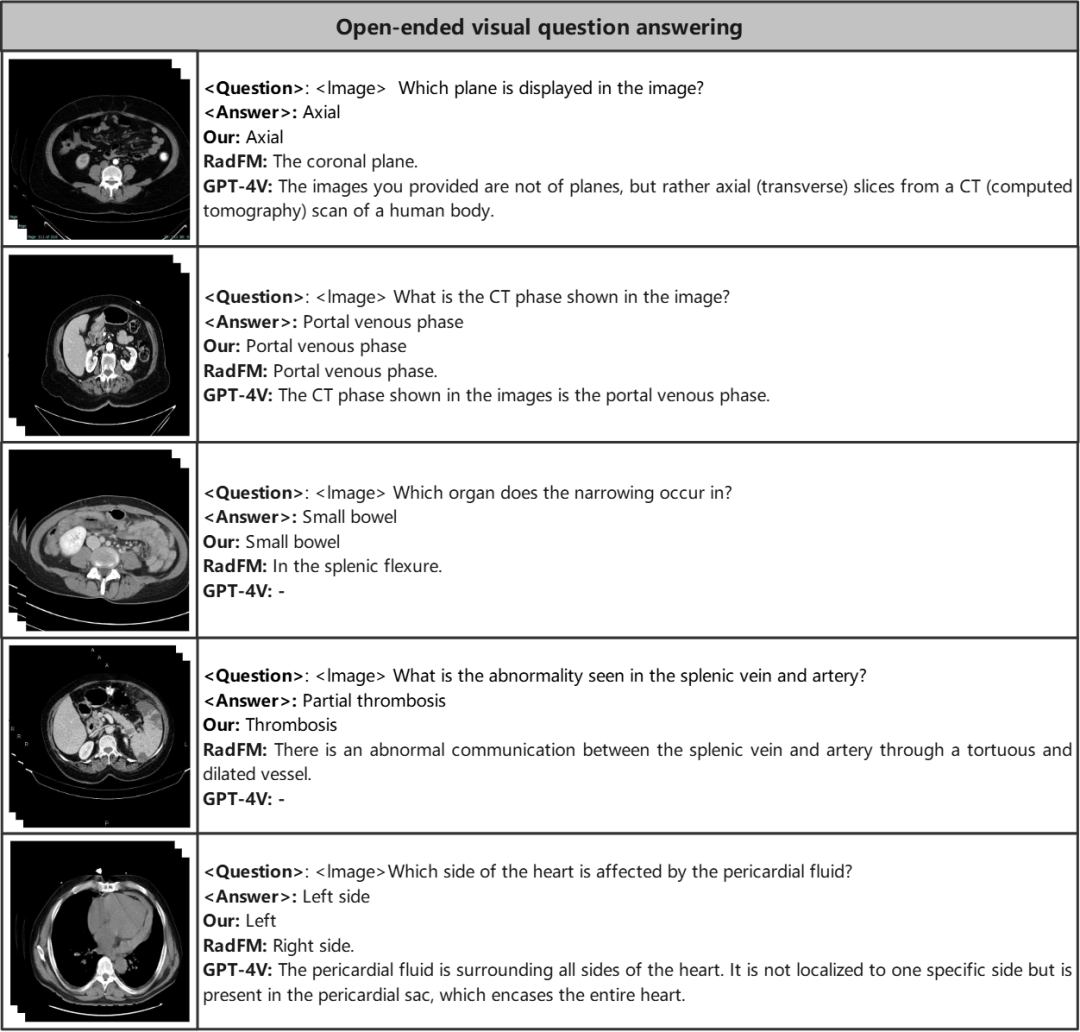
开放式视觉问答
在开放式视觉问答中,模型生成开放式的答案,不存在任何答案提示和候选。
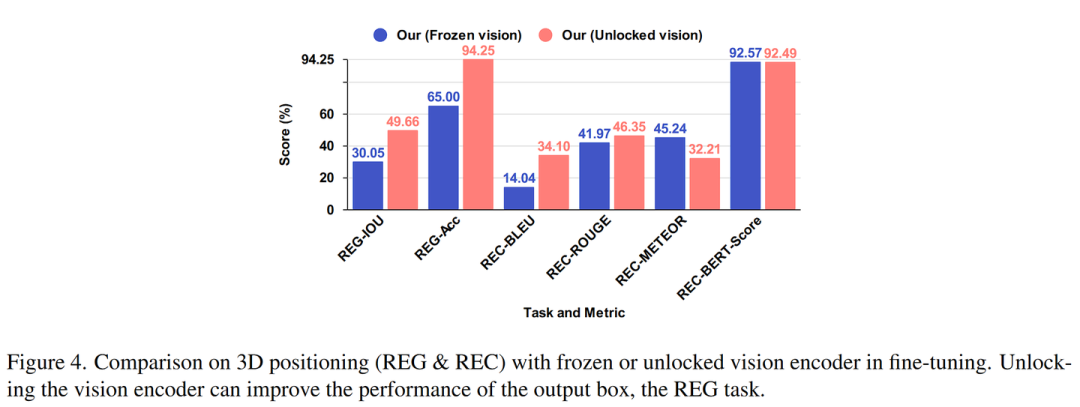
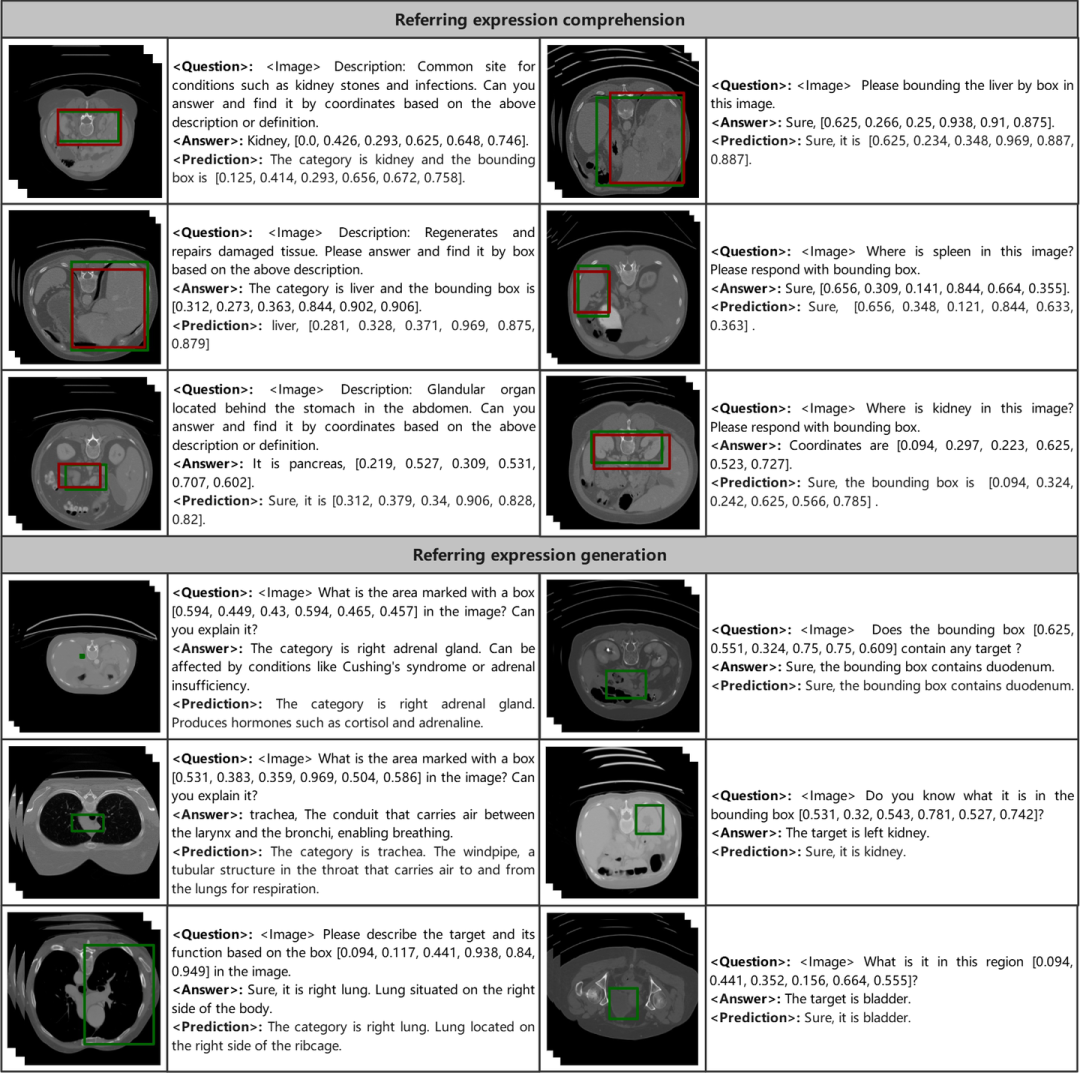
定位
定位在视觉语言任务中至关重要,尤其是涉及输入和输出框的任务。在输出框的任务,如指代表达理解 (REC) ,旨在根据指代表达在图像中定位目标对象。相比之下,在输入框的任务,如指代表达生成 (REG) ,要求模型根据图像和位置框生成特定区域的描述。
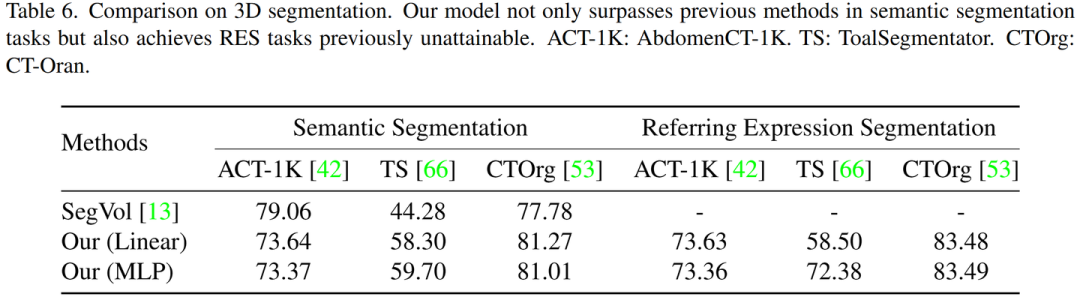
分割
分割任务在 3D 医学图像分析中至关重要,因为它具有识别和定位功能。为了解决各种文本提示,分割分为语义分割和指代表达分割。对于语义分割,该模型根据语义标签生成分割掩码。指代表达分割需要根据自然语言表达描述进行目标分割,需要模型具有一定的理解和推理的能力。
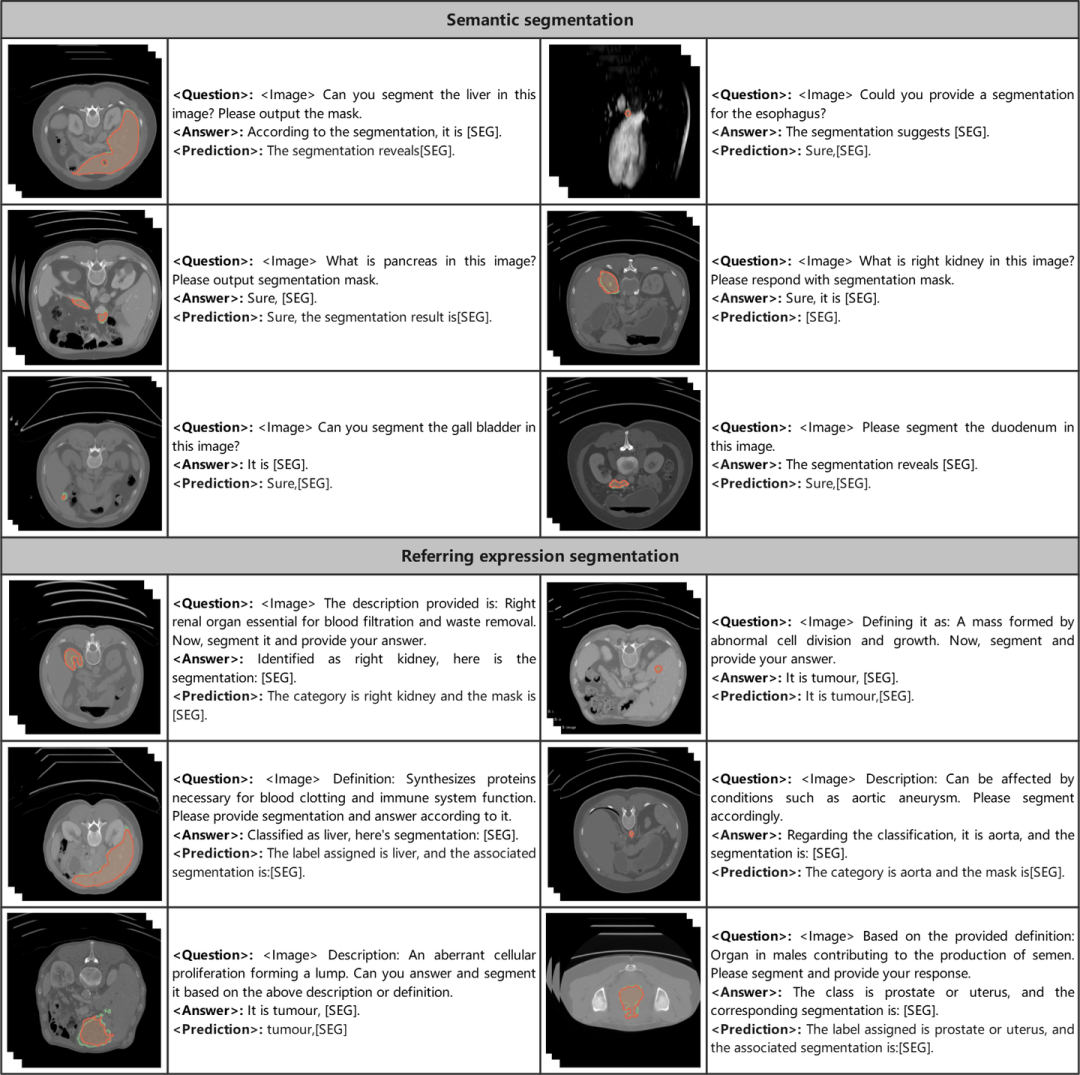
分布外 (OOD) 问题的案例研究
我们在 OOD 对话中测试了 M3D-LaMed 模型,这意味着所有问题都与我们的训练数据不相关。我们发现 M3D-LaMed 具有很强的泛化能力,可以对 OOD 问题产生合理的答案,而不是胡言乱语。在每组对话中,左侧的头像和问题来自用户,右侧的头像和答案来自 M3D-LaMed。

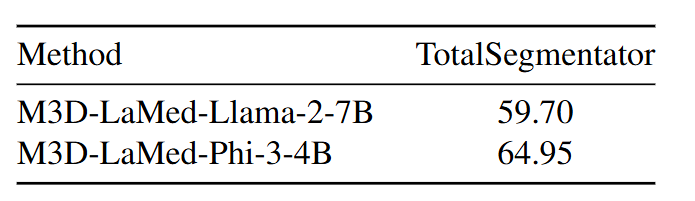
我们最新训练的更小的 M3D-LaMed-Phi-3-4B 模型具有更好的表现,欢迎大家使用!GoodBaiBai88/M3D-LaMed-Phi-3-4B · Hugging Face


总结
我们 M3D 系列研究促进了使用 MLLM 进行 3D 医学图像分析。具体来说,我们构建了一个大规模 3D 多模态医学数据集 M3D-Data,其中包含 120K 3D 图像文本对和 662K 指令响应对,专为 3D 医学任务量身定制。
此外,我们提出了 M3D-LaMed,这是一个通用模型,可处理图像文本检索、报告生成、视觉问答、定位和分割。此外,我们引入了一个综合基准 M3D-Bench,它是为八个任务精心设计的。我们的方法为 MLLM 理解 3D 医学场景的视觉和语言奠定了坚实的基础。
我们的数据、代码和模型将促进未来研究中对 3D 医学 MLLM 的进一步探索和应用。希望我们的工作能够为领域研究者带来帮助,欢迎大家使用和讨论。
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「医学影响」交流群👇备注:Med
















 2501
2501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









