






关注公众号,发现CV技术之美
在多模态大语言模型(MLLMs)的发展中,视觉-语言连接器作为将视觉特征映射到LLM语言空间的关键组件,起到了桥梁作用。
因此,它几乎成为了所有多模态大语言模型中不可或缺的结构之一。然而,如何高效地将视觉特征映射到LLM的探索还有很大提升空间。
字节团队与中大合作提出的 ParGo 模型,通过巧妙地融合全局视野和局部细节,不仅在多项权威基准测试(Benchmark)中表现出色,成功入选了 AAAI 2025。

论文标题:ParGo: Bridging Vision-Language with Partial and Global Views
论文地址:https://arxiv.org/abs/2408.12928
代码地址:https://github.com/bytedance/ParGo
过去,大多数研究主要依赖线性投影或多层感知机(MLP)将视觉特征直接映射,这种方法难以有效控制输入LLMs的视觉token数量,特别是在处理细粒度特征时,导致计算成本极高。
另一类基于注意力机制的方法(如Q-former)通过注意力操作将图像特征投射为固定数量的视觉token,虽然大幅减少了计算成本,但往往使得生成的token集中在图像的显著区域,忽略了细节部分。
为了解决这一问题,ParGo提出了一种创新的全局-局部投影器来连接视觉与文本,通过结合全局视野和局部细节的双重视角,克服了传统方法对显著区域的过度聚焦,使得视觉特征能够在更细腻的层面上得到全面展现,同时有能有效控制过长的token带来的计算成本的升高,进而实现了视觉特征和LLM的高效连接。

方法
ParGo (Partial-Global) 采用两种类型的可学习token, 利用attention机制,同时从局部和全局视角将视觉特征映射到大语言模型(LLM)中。该框架包含两个关键模块:Partial-Global Perception Block (PGP) 和 Cascaded Partial Perception Block (CPP)。这两个模块共同作用,实现了高效的视觉-语言连接,既捕捉了图像的全局信息,又能精细地提取局部特征,从而提升了多模态大语言模型的效果。
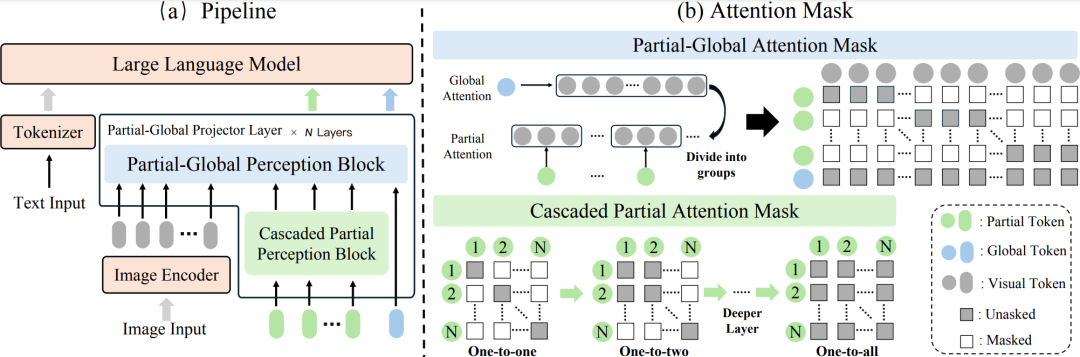
核心模块
Partial-Global Perception Block (PGP)
在 ParGo 中,视觉编码器的特征被映射为两种不同类型的token:Partial token 和 Global token,从而能够分别提取图像的局部和全局信息。具体来说:
Partial tokens:每个token仅与部分视觉特征进行交互,专注于图像的局部信息
Global tokens:全局token则与所有视觉特征进行交互,捕捉图像的全局信息
ParGo 采用了一种新的交叉注意力掩码设计(Partial-Global Attention Mask),如图1 (b) 所示,来处理输入的视觉特征。该设计能够同时输出包含图像局部和全局信息的特征,即 Partial tokens 和 Global tokens。具体的公式如下:
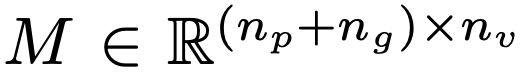
Cascaded Partial Perception Block (CPP)
此外,考虑到不同局部物体在图像中的占比不同,为了进一步增强对多种局部信息的完整捕获能力,ParGo 在 Partial-Global Perception 模块之前引入了 Cascaded Partial Perception (CPP) 模块。
CPP模块的核心是一个带有特殊设计掩码的自注意力机制 ,如图1 (b) 中的 Cascaded Partial Attention Mask。随着层数的增加,每个 Partial token 能够访问到更多的相邻 token,从而逐步扩展其感知范围。该过程可以通过以下公式表示:
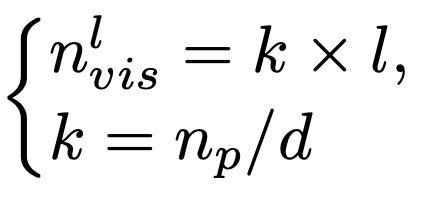
实验效果
论文重点对比了当前不同类型的Projector(投射器),在一些通用的MLLM的benchmark的效果,均取得了优异的效果。
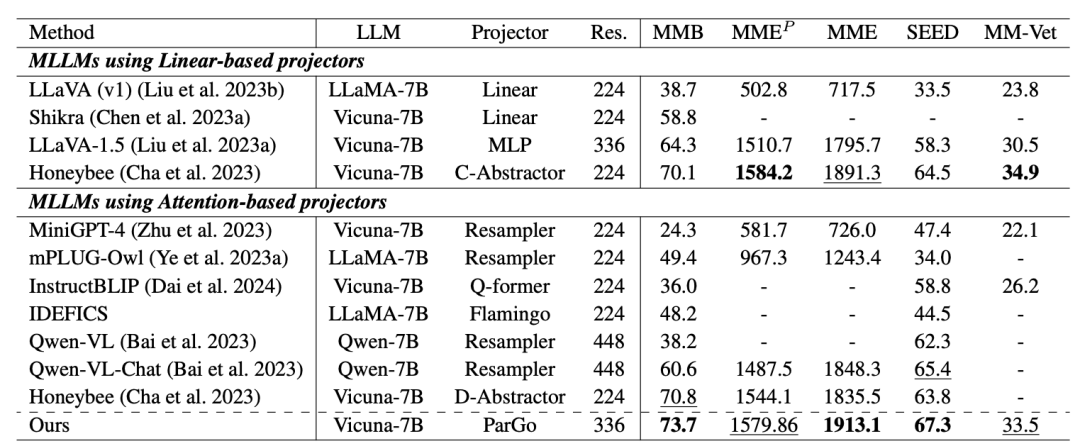
为了进一步进行公平对比,论文在相同数据集和实验参数下,比较了三种主流的投影器(Projector)。结果显示,ParGo 依然取得了最佳的性能表现。另外,在不同基座LLM下,ParGo均表现良好,体现出了更好的泛化性能。

案例分析
为了能进一步展现ParGo在控制token数量的情况下,依然能做到细粒度和空间关系的准确捕获,作者对比了ParGo和Q-former这两种均是基于注意力机制的Projector(投射器)在相同tokens下的效果,

结论
本研究提出了ParGo(局部-全局投影器),一种创新的视觉-语言投影方案,旨在提升多模态大语言模型(MLLMs)中视觉和语言模态的对齐效果。
ParGo通过结合局部token和全局token,并使用精心设计的注意力掩码分别提取局部和全局信息,在控制token数量的同时增强了局部区域之间的关系建模,充分考虑了图像的细节与全局视角,从而克服了传统方法中忽视细节的问题。
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「大模型」交流群👇备注:LLM



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









