






关注公众号,发现CV技术之美
本文分享论文卷积神经网络在图像超分辨上的应用,文章旨在通过分析基于插值和模块化的卷积神经网络图像超分辨方法的区别与联系、比较这些方法的性能,对潜在的研究点和挑战进行阐述并总结全文,以促进基于卷积神经网络的图像超分辨研究的发展。

作者:田春伟,宋明键,左旺孟,杜博,张艳宁,张师超
单位:哈尔滨工业大学,空天地海一体化大数据应用技术国家工程实验室,西北工业大学,武汉大学,广西师范大学
论文链接:https://kns.cnki.net/kcms2/article/abstract?v=Zb3wS6iuiaMEcb1BpoiR1sN1tLwlHd-ay6Bx2qisxCTT0IBjwAjDL1uH4ExxfP-x--mTZq6aEGBYkbSImmldUnvdRwAFCdb09AzSqxEOdboKckaAS-59dJtfk310WbWo7TNXEQwB6_0lBzBp_oIPSNGhS_wCPmf8glSxJioHAOuT2eW1Pp0QWMAfZt3W9_6A-45IjAFFQg8
1. 摘要
卷积神经网络因强大的学习能力,已成为解决图像超分辨问题的主流方法。然而,用于解决图像超分辨的不同类型深度学习方法存在巨大的差异。
目前,仅有少量文献能根据不同缩放方法来总结不同深度学习技术在图像超分辨上的区别和联系。因此,根据设备的负载能力和执行速度等介绍面向图像超分辨方法的卷积神经网络尤为重要。
本文首先介绍面向图像超分辨的卷积神经网络基础,随后通过介绍基于双三次插值、最近邻插值、双线性插值、转置卷积、亚像素层、元上采样的卷积神经网络的图像超分辨方法,分析基于插值和模块化的卷积神经网络图像超分辨方法的区别与联系,并通过实验比较这些方法的性能。
本文对潜在的研究点和挑战进行阐述并总结全文,旨在促进基于卷积神经网络的图像超分辨研究的发展。
2. 方法与贡献
本文首先回顾了图像超分辨从传统方法到深度学习方法的发展历史,搜集整理了多个超分辨技术框架,分析总结了近百种不同角度、不同思路的超分辨方法,并通过系统性的对比研究,展示了它们的性能、优缺点、复杂性、挑战和潜在的研究要点等。
具体为:
本文首先介绍了图像超分辨技术近年来的发展状况,概述了从传统的图像超分辨方法到基于卷积神经网络的图像超分辨方法的演进过程。
第二,本文从技术前身、基本原理与实际效果等角度,完整介绍了基于卷积神经网络图像超分辨率方法的经典网络框架。
第三,根据不同的技术原理,本文将面向图像超分辨的卷积神经网络划分为两类,包括基于插值和基于模块化的卷积神经网络图像超分辨方法,并分析了用于非盲图像超分辨与盲超分辨的卷积神经网络的动机、实现、性能与差异。
第四,本文定性和定量分析这些算法在图像超分辨公共数据集上的性能。
最后,本文指出了卷积神经网络在图像超分辨领域面临的挑战与未来发展方向。论文结构如下:
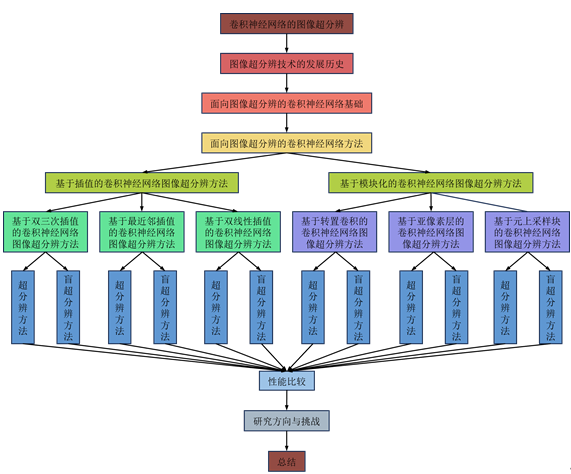
3.实验及结果
3.1数据集
数据集通常分为训练数据集和测试数据集,分别用于模型的训练与评估。此外,验证数据集通常包含在训练数据集中,用来训练过程中检测图像超分辨模型效果,它通常是与测试集具有相同分布的图像组成的数据集。不同模型的更多细节内容如下所示:
1. 单图像超分辨率卷积神经网络
训练数据集:ImageNet,91-images,BSD,DIV2K,Harvard,General-100,Flickr2K,MSCOCO,OST,DIV8K,SRResNet,WED,FFHQ,Nico-illust,NYUDepth,Make3D,T91,OASIS,BraTS,ACDC,COVID-CT,ILSVRC2012,UCID。
测试数据集:Set5,Set14,BSD,Urban100,Manga109,DIV2K,CAVE,Harvard,720p,PIRM,DIV8K,Nico-illust,SRResNet,DIV2K4D,Set12,UCID,SuperTexture,NYUDepth,Make3D,ImageNet400,OASIS,BraTS,ACDC,COVID-CT。
2. 单图像盲超分辨率卷积神经网络
训练数据集:DIV2K,Flickr2K,WED,FFHQ,OutdoorSceneTraining,DIV2KRK,CelebA,VOC2012。
测试数据集:NTIRE2018,Set5,Set14,BSD,DIV2K,Urban100,RealSRSet,OST,DPED,ADE20K,RealSR,DRealSR,CelebA,Manga109。
3.2评价指标
为定量描述不同方法的性能差异,本节将介绍常用于图像超分辨的评价指标,包括峰值信噪比(PeakSignal-to-NoiseRatio,PSNR)[171]、结构相似性(StructuralSimilarity,SSIM)[172]、模型参数量以及运行时间。
3.3实验设置
在图像超分辨领域,为了保持公平,测试时用Y通道测试[16,18]。由于不同方法实验设备、配置及实验设置不同,通常选择PSNR和SSIM及可视化图像比较细节来验证获得图像超分辨模型的性能。每种方法的实验设置可参考具体方法论文中参数设置。此外,待恢复倍数代表将低分辨率图像放大到几倍高清图像。
3.4定量比较
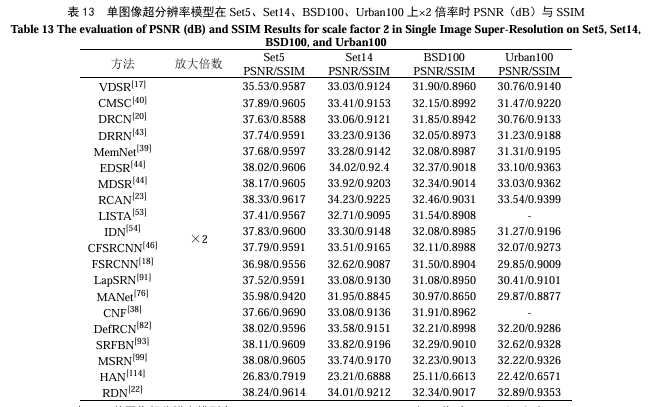
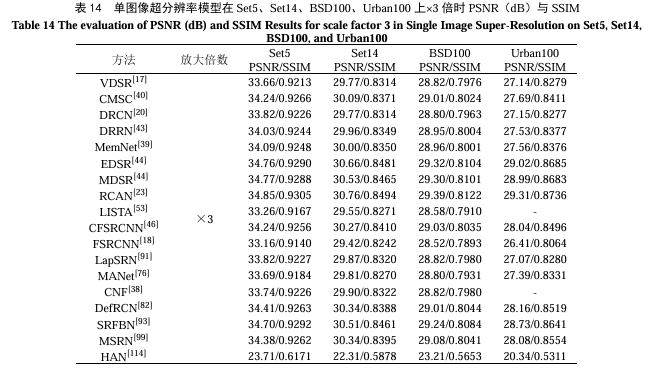
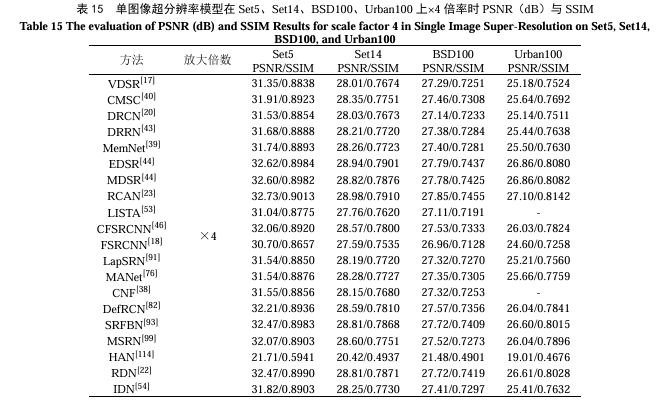
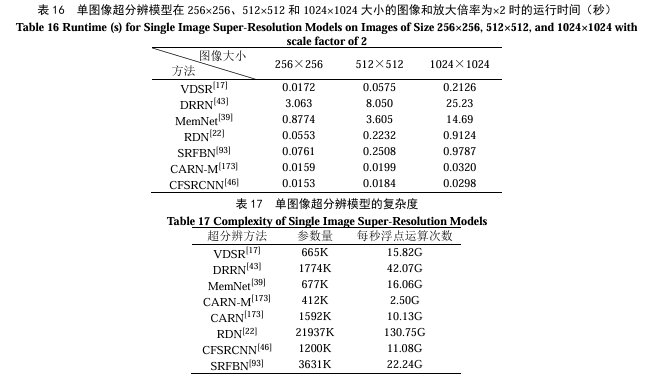
单图像超分辨模型的定量分析本次测试了VDSR、CMSC、DRCN、DRRN、MemNet、EDSR、MDSR、RCAN、LISTA、IDN、CFSRCNN、FSRCNN、LapSRN、MANet、CNF、DefRCN、SRFBN、MSRN、HAN、RDN等方法在Set5、Set14、BSD100、Urban100等公共数据集上不同倍数的图像超分辨性能。在表13中,在Set5数据集上倍数为2时,RDN的性能表现最好,在表14中倍数为3和表15中4时,RCAN的性能表现最好。此外,本实验选取部分超分辨模型在不同大小的图像上实际运行,比较不同模型在×2放大倍率时的处理时间。表16列举出的多种模型当中,CFSRCNN的模型处理速度最快。最后,本实验比较了几种经典单图像超分辨模型的参数大小与计算速度,如表17所示,CARN-M[173]的参数规模最小、运算速度最快、模型复杂度最小。
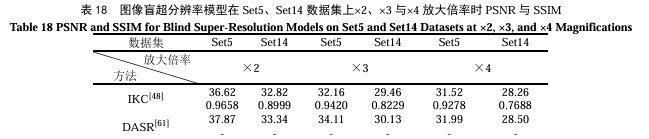
单图像盲超分辨率模型定量分析对于众多盲超分辨率模型,本实验同样选取了Set5和Set14公共数据集进行实验,表18列举了经典单图像盲超分辨模型在常见数据集、不同倍率时的性能表现,每种超分辨方法对应右侧第一行数值为PSNR,第二行数值为SSIM。如表18所示,在Set5数据集上且倍率为2和4时,DASR性能表现最好。


<<< 左右滑动见更多 >>>
3.5可视化图像
从图11中可以看到,在BSD100数据集上,放大倍数为3时,CFSRCNN方法效果最好。对比其他方法,CFSRCNN方法恢复图像的窗户框更平直,并且能恢复部分小窗户框。
图12中,在BSD100数据集上,放大倍数为4时,CFSRCNN方法表现最为优异,大多数方法无法恢复出游艇上最右侧的竖杆,CFSRCNN方法可以看清有竖杆。
图13中,在Urban100数据集上,放大倍数为3时,CFSRCNN方法再次展示出色的性能,在更高楼层仍然保持清晰横向玻璃框,而其他方法则会变得模糊或者错误地变成竖向玻璃框。
在图14中可以看出,在Urban100数据集上,放大倍数为4时,CFSRCNN方法同样表现突出,能够清晰地恢复出第三条柱子,而其他方法会模糊或者缺失第三根柱子。
综合来看,CFSRCNN方法在不同数据集和放大倍数下普遍表现优越,显示出其在多种场景中卓越的图像超分辨率能力。





<<< 左右滑动见更多 >>>
4.潜在研究点和挑战
4.1潜在研究点
超分辨质量的衡量尺度:现有的超分辨方法主要采取像素级误差度量,例如两像素间距离或者两者组合。然而这些方法只封装了局部像素级信息,因此评价结果并不一定是感知上的可靠结果。例如,高PSNR和SSIM值的图像往往过于平滑,直观上的超分辨效果并不一定好。没有一种通用的感知度量尺度,可以在所有条件下很好地度量图像超分辨效果,因此,新的衡量尺度是一个重要的潜在研究点。
统一架构的图像超分辨模型:在真实的世界中,两个及两个以上的图像退化因素通常会同时出现来降低图像的质量。因此,如何能获得一个鲁棒性模型以解决复杂场景下的图像超分辨问题是一个重要的研究方向。
自监督图像超分辨:真实场景下的参考高清图像难以获取,使得已有的图像超分辨方法在真实世界中实用性减弱,因此,根据图像的属性以自监督方式开发出适合真实场景的图像超分辨性能是非常必要的。
大模型图像超分辨率:利用像素之间关联能促进更多的互补信息,提升图像超分辨性能。因此,大模型技术引导深度网络,能结合结构信息和像素信息,提高图像超分辨性能。
多模态图像超分辨率结合:由于复杂的拍摄场景、运动的拍摄设备以及运动的目标,导致单源的图像引导深度网络获得图像超分辨模型在真实场景中的应用受限。因此,多模态的图像超分辨方法是非常有必要的和研究前景的。
轻量级网络:移动设备的普及和算力受限的情况,使得高效、低功耗的图像处理算法需求增加。轻量级网络通过减少参数和计算量,实现高效的图像超分辨率,同时保持较高的图像质量。其优势在于能在低功耗设备上实时运行,适用于智能手机、无人机和边缘计算等应用场景。因此,轻量级网络的图像超分辨研究非常有必要的。
4.2研究挑战
多种破坏因子的图像超分辨问题:在真实的世界中,由于相机抖动、运动的拍摄物体和相机以及复杂的拍摄背景等,会出现噪声、分辨率低等多种破坏因子,导致捕获的图像受损严重。因此,针对多种破坏因子的图像超分辨问题是有待解决的。
鲁棒的图像超分辨衡量指标:已有的图像超分辨方法通常采用PSNR和SSIM作为衡量指标,但获得可视化图像直观效果好,而对应方法的PSNR和SSIM结果低。因此,制定鲁棒的图像超分辨衡量指标是迫在眉睫。
更大的超分辨放大倍率:目前,已有的超分辨模型基本无法解决超大的图像超分辨率问题,这限制了图像超分辨算法在如人群场景中人脸超分辨场景下的使用。因此,研究更大倍数的图像超分辨方法是迫在眉睫。
真实图像超分辨任务:已有的大部分图像超分辨方法都通过有参考的干净图像等有监督的方式获得图像超分辨模型,而在真实世界中,由于抖动的相机、运动物体以及拍摄的背景等导致已有图像超分辨模型不使用于真实的图像超分辨任务。因此,研究解决真实场景下图像超分辨方法是必要的。
无监督的图像超分辨:已有的无监督图像超分辨方法过分依赖于无标签的数据,如何获得高质量、多样化的数据是一个关键问题。在真实世界中,低分辨率图像的退化过程往往复杂多变,如何在无监督学习框架下有效地建模和处理这些复杂的退化过程,也是一个亟待解决的难点。
大模型的图像超分辨:大模型通常需要大量的计算资源和存储空间。此外,训练大模型还需要高质量和多样性的海量数据,获取和处理这些数据既耗时又复杂。其次,大模型的推理速度和能效需要优化,以便在实际应用中能够高效运行。大模型在图像超分辨率的应用仍然具有很大的挑战性。
硬件资源受限平台的图像超分辨率:移动设备和嵌入式系统等资源受限平台通常无法提供足够的计算资源和内存,而图像超分辨率算法通常需要大量的计算能力以及功耗。同时,如何在硬件资源有限的情况下保证处理速度和图像质量也是一个难点。在硬件资源受限平台应用图像超分辨仍面临严峻挑战。
5.结论
本文比较和总结不同的卷积神经网络在图像超分辨上的应用,并给出了它们之间的联系与区别。
首先,本文介绍了图像超分辨方法的发展状况。其次,本文根据图像属性和设备的要求,介绍了主流的图像超分辨卷积神经网络框架。
随后,根据线性和非线性的缩放图像方式给出了基于插值的卷积神经网络图像超分辨方法(双三次插值算法、最近邻插值法、双线性插值算法)、基于模块化的卷积神经网络超分辨方法(转置卷积、亚像素层和元上采样模块),分析这些方法在非盲图像超分辨和盲图像超分辨问题上的动机、原理、区别和性能最后,本文给出卷积神经网络在图像超分辨的未来研究、挑战和总结全文。
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「超分辨率」交流群👇备注:SR



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









