







介绍
这篇博文会定期更新。它是关于在进行网络抓取时了解 CSS 选择器,以及哪些工具可能方便使用。
在 SerpApi,我们遇到了不同类型的选择器,其中一些非常复杂,包括复杂的逻辑,例如,逻辑可能包括选择器:has(),:not()如构建我们的 API 的旅程。
我们要指出的是,这篇博文并不是完整的 CSS 选择器参考,而是对常用和更高级类型的选择器以及如何在使用代码示例进行网络抓取时使用它们的迷你导览。
先决条件
基本熟悉bs4库,或者您正在使用的任何 HTML 解析器包/框架,因为不同语言、框架、包中 CSS 选择器的用法没有太大区别。
安装库:
pip install requests lxml beautifulsoup4
什么是 CSS 选择器
CSS 选择器是用于选择匹配你想要的元素风格从 HTML 页面中提取。
选择器小工具
让我们从简单的SelectorGadget Chrome 扩展程序开始。此扩展允许通过在浏览器中单击所需的元素来快速获取 CSS 选择器,并返回一个 CSS 选择器。
SelectorGadget 是一种开源工具,可让复杂站点上的 CSS 选择器生成和发现变得轻而易举。
用例:
Nokogiri用于使用和等工具进行网页抓取BeautifulSoup。jQuery为动态站点生成选择器。- 作为检查 JavaScript 生成的 DOM 结构的工具。
- 作为一种工具,可帮助您使用样式表仅对页面上的特定元素进行样式设置。
- 用于
selenium或phantomjs测试。
使用 SelectorGadget 时,它会突出显示以下元素:
-
黄色,这意味着它正在猜测用户正在寻找什么,并且需要可能的额外说明。
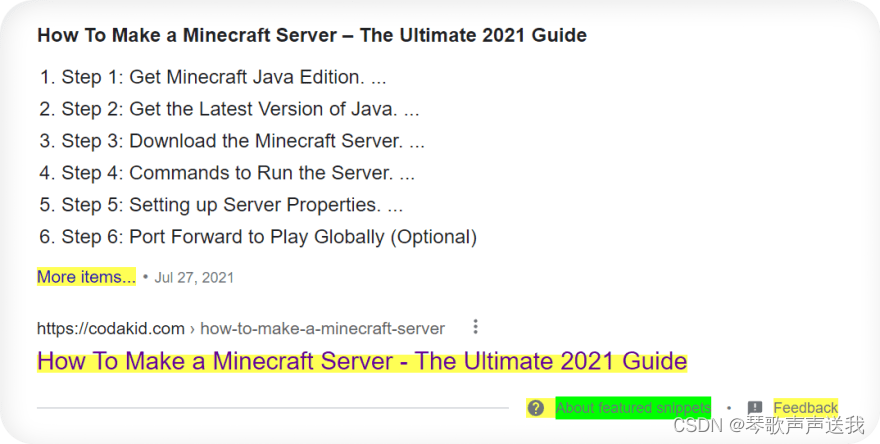
-
红色从匹配选择中排除。
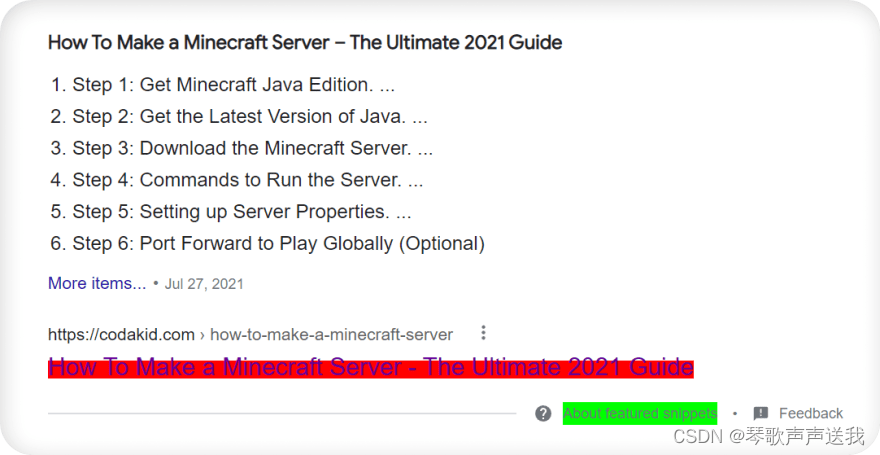
-
绿色包括匹配选择。
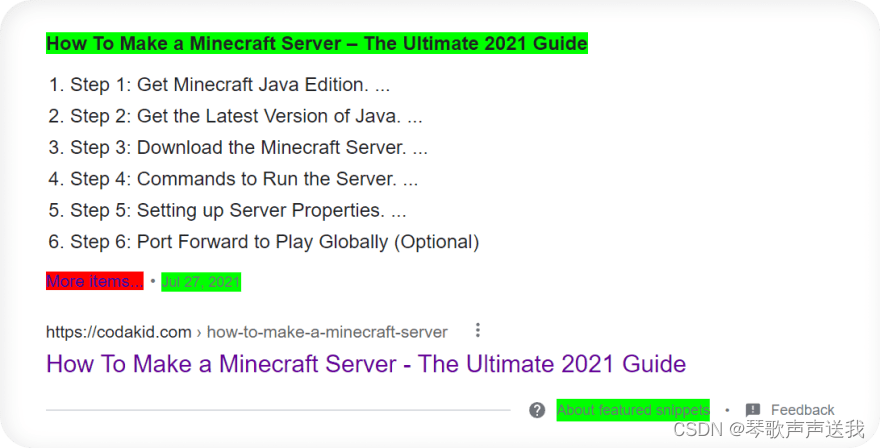
手动选择 CSS 选择器
由于 SelectorGadget 不是一个神奇的全能工具,有时它无法获取所需的元素。当网站 HTML 树结构不佳,或者网站是通过 JavaScript 呈现时,就会发生这种情况。
当它发生时,我们通过开发工具(F12在键盘上或CTRL+SHIFT+C)使用元素选项卡来定位和抓取 CSS 选择器或 HTML 元素:
- 类型选择器:
<input> - 类选择器:
.class - id 选择器:
#id - 属性选择器:
[attribute]
CSS 选择器的类型
类型选择器
✍语法:element_name
类型选择器按节点名称匹配元素。换句话说,它选择 HTML 文档中给定类型的所有元素。
soup.select('a') # returns all <a> elements
soup.select('span') # returns all <span> elements
soup.select('input') # returns all <input> elements
soup.select('script') # returns all <script> elements
类选择器
✍语法:.class_name
类选择器根据类属性的内容匹配元素。这就像调用一个类方法 PressF().when_playing_cod()。
soup.select('.mt-5') # returns all elements with current .selector
soup.select('.crayons-avatar__image') # returns all elements with current .selector
soup.select('.w3-btn') # returns all elements with current .selector
ID 选择器
✍语法:#id_value
ID 选择器根据 elementsid属性的值匹配元素。为了选择元素,其id属性必须与选择器中给定的值完全匹配。
soup.select('#eob_16') # returns all elements with current #selector
soup.select('#notifications-link') # returns all elements with current #selector
soup.select('#value_hover') # returns all elements with current #selector
属性选择器
✍语法:[attribute=attribute_value]或者[attribute],更多例子。
属性选择器根据给定属性的存在或值匹配元素。
唯一的区别是这个选择器使用花括号[]而不是点 ( .) 作为类,或者哈希(或八角形)符号 ( #) 作为 ID。
soup.select('[jscontroller="K6HGfd"]') # returns all elements with current [selector]
soup.select('[data-ved="2ascASqwfaspoi_SA8"]') # returns all elements with current [selector]
# elements with an attribute name of data-id
soup.select('[data-id]') # returns all elements with current [selector]
选择器列表
✍语法:element, element, element, ...
选择器列表选择所有匹配的节点(元素)。从网络抓取的角度来看,这个 CSS 选择器(在我看来)非常适合处理不同的 HTML 布局,因为如果存在其中一个选择器,它将从现有选择器中抓取所有元素。
以 Google 搜索(轮播结果)为例,HTML 布局将根据搜索来自的国家/地区而有所不同。
当搜索国家不是美国时:
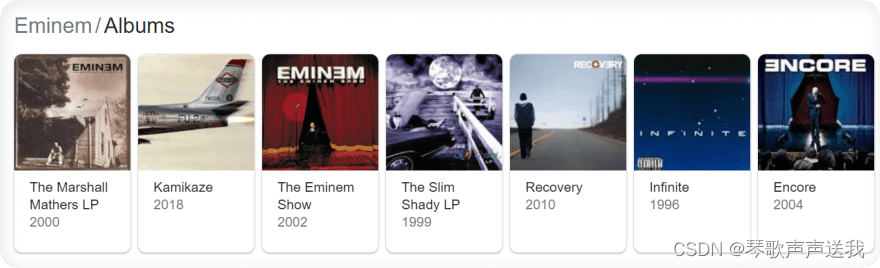
当搜索国家设置为美国时:
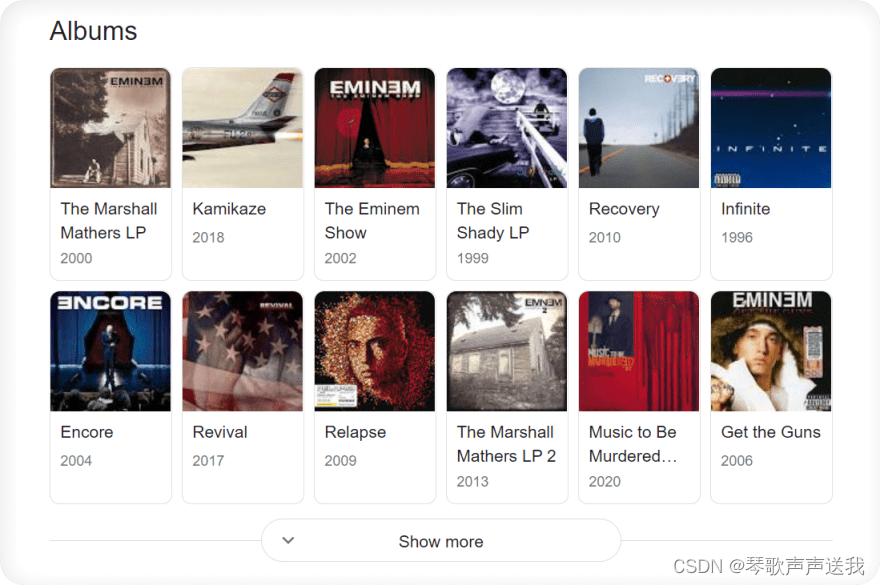
以下示例转换为此代码片段(处理两种 HTML 布局):
# will return all elements either by one of these selectors
soup.select('#kp-wp-tab-Albums .PZPZlf, .keP9hb')
后代组合子
✍语法:selector1 selector2
由单个空格 ( ) 字符表示的后代组合器,并选择两个选择器,以便选择与第二个选择器匹配的元素,如果它们具有与**第一个选择器匹配的祖先(父、父的父、父等)元素。
soup.select('.NQyKp .REySof') # dives inside .NQyKp -> dives again to .REySof and grabs data from it
soup.select('div cite.iUh30') # dives inside div -> dives inside cite.iUh30 and grabs data from it
soup.select('span#21Xy a.XZx2') # dives inside span#id -> dives inside a.XZx2 and grabs data from it
选择器 :nth-child()
✍语法:selector|element:nth-child()
:nth-child()伪类根据元素在一组兄弟中的位置来匹配元素。
soup.select('p.SacA1:nth-child(1)') # selects every second p.SacA1 element
选择器:有()
✍语法:selector|element:has(selector|element)
:has()是一个伪类,用于检查父元素是否包含某些子元素
soup.select('p:has(.sA1Sg)') # checks if p element that has .sA1Sg selector as a child
函数包含()
✍语法:selector|element:contains(selector|element|text)
contains()方法并不完全与 CSS 选择器相关,而是与 XPath 相关。如果搜索的(第一个)字符串的子字符串中有值,则返回 true 或 false。有点混乱,让我们举个例子。
from parsel import Selector
dummy_string_1 = 'I saw a cat that had $3000 in the pocket'
dummy_string_2 = 'I saw a cat that was dancing with pigeon'
selector_1 = Selector(text=dummy_string_1)
selector_2 = Selector(text=dummy_string_2)
# $ has to be espaced with \ symbol
# otherwise SelectorSyntaxError will be raised
text_1 = selector_1.css(':contains(\$)::text').get() 👈👈👈
text_2 = selector_2.css(':contains(\$)::text').get()
print(text_1)
print(text_2)
输出:
I saw a cat that had $3000 in the pocket 👈👈👈
None
选择器:不()
✍语法:selector|element:not(selector|element|text)
:not()伪类用于防止选择特定项目。
:not伪类可以使用(链接) with方法contains()来创建一个非常方便的布尔表达式。
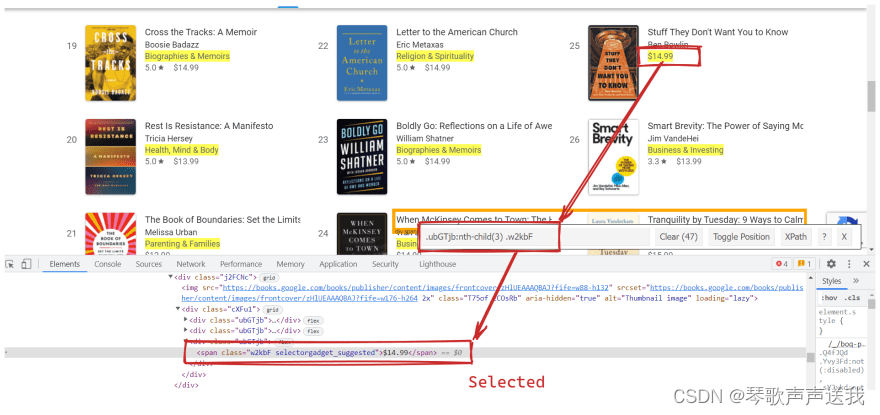
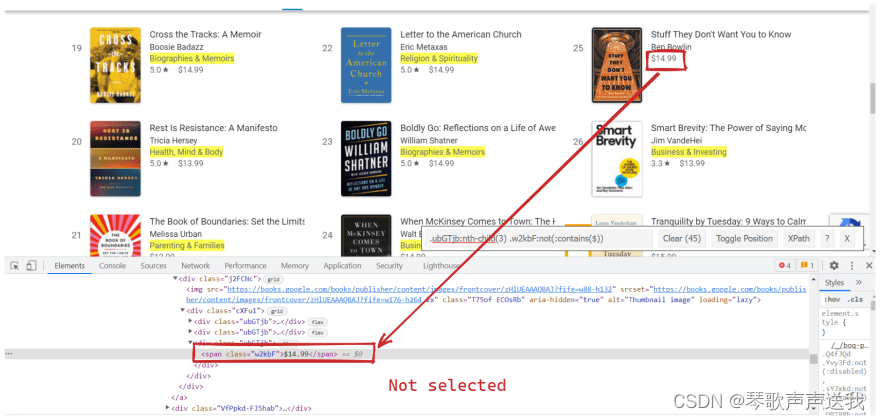
继续前面的例子,我们可以选择文本中不包含$符号的元素:not(:contains(\$))::text:
from parsel import Selector
dummy_string_1 = 'I saw a cat that had $3000 in the pocket'
dummy_string_2 = 'I saw a cat that was dancing with pigeon'
selector_1 = Selector(text=dummy_string_1)
selector_2 = Selector(text=dummy_string_2)
# $ has to be espaced with \ symbol
# otherwise SelectorSyntaxError will be raised
text_1 = selector_1.css(':contains(\$)::text').get()
text_2 = selector_2.css(':not(:contains(\$))::text').get() 👈👈👈
print(text_1)
print(text_2)
输出:
I saw a cat that had $3000 in the pocket
I saw a cat that was dancing with pigeon 👈👈👈
$这是一个更实际的用法,我们需要选择文本字符串中不包含的所有内容(仅类别) :
没有:not(:contains(\$)) | 和:not(:contains(\$)) |
|---|---|
 |  |
其他有用的 CSS 选择器:
| 选择器 | 解释 |
|---|---|
:nth-of-type() | 选择作为其父元素n的第二个元素的每个元素。n |
:is() | 伪类函数将选择器列表作为其参数,并选择可以由该列表中的一个选择器选择的任何元素。 |
您可以在W3C Level 4 选择器、 W3Schools CSS 选择器参考和MDN CSS 选择器文档中找到其他有用的 CSS 选择器。
测试 CSS 选择器
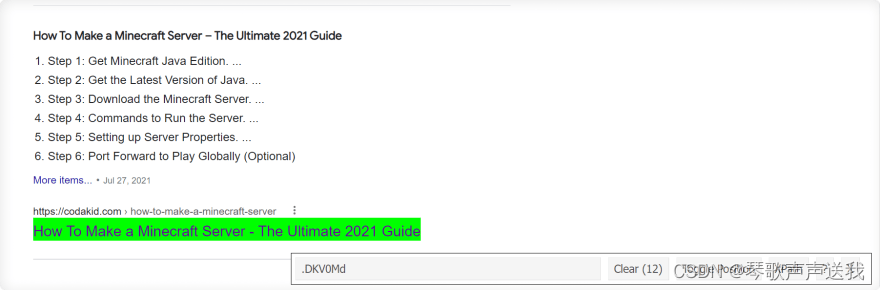
要测试选择器是否提取了正确的数据,您可以:
将这些 CSS 选择器放在 SelectorGadget 窗口中,然后查看哪些元素被选中:
$$(".selector")通过方法使用 Dev Tools Console 选项卡(创建元素的array(list() ) ):
$$(".DKV0Md")
这相当于document.querySelectorAll(".selector")方法(根据 Chrome 开发者网站:
document.querySelectorAll(".DKV0Md")
两种方法的 DevTools 控制台输出是相同的:

CSS 选择器的优点
- 容易挑选。
- 易于使用(特别是如果有 HTML 背景)。
- 有帮助挑选(选择)它们的工具。
- 如果选择器本身是可以理解的,而不是像
.wtf228YoLo.
CSS 选择器的缺点
只投注课程可能不是一个好主意,因为它们可能会改变。
一种更可行的方法是使用属性选择器选择器(上面提到的)它们可能不会经常更改。
属性选择器示例:(来自 Google 有机搜索结果的 HTML):

许多现代网站在对特定样式组件进行的每次更改时都使用自动生成的 CSS 选择器,这意味着完全依赖它们并不是一个好主意。但同样,这将取决于它们真正改变的频率。
可能出现的最大问题是当代码执行时会报错,代码的维护者应该手动更改 CSS 选择器以使代码正常运行。
看起来没什么大不了的,这是事实,但如果选择器频繁更改,可能会很烦人。
代码示例
本节将展示几个来自不同网站的实际示例,让您更加熟悉。
从 Google 搜索结果中提取标题、摘要、链接、显示的链接。
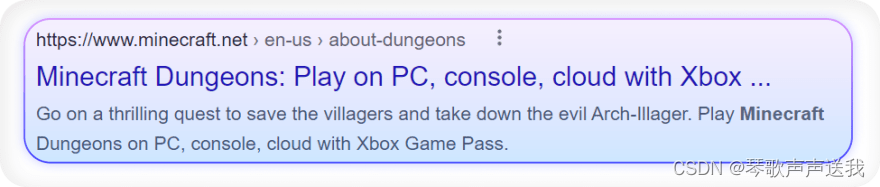
测试 CSS 容器选择器:
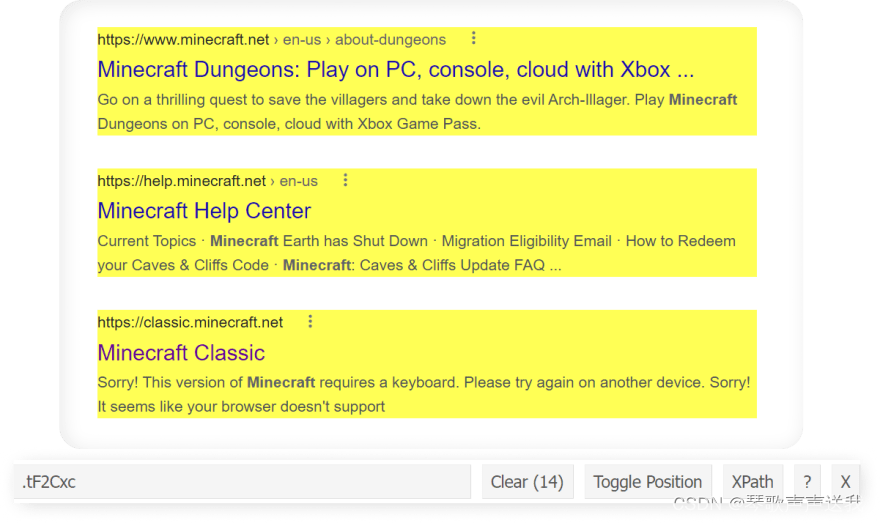
代码:
import requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
html = requests.get("https://www.google.com/search?q=minecraft", headers=headers)
soup = BeautifulSoup(html.text, "lxml")
for result in soup.select(".tF2Cxc"):
title = result.select_one(".DKV0Md").text
link = result.select_one(".yuRUbf a")["href"]
displayed_link = result.select_one(".lEBKkf span").text
snippet = result.select_one(".lEBKkf span").text
print(f"{title}\n{link}\n{displayed_link}\n{snippet}\n")
# part of the output
'''
Log in | Minecraft
https://minecraft.net/login
https://minecraft.net › login
Still have a Mojang account? Log in here: Email. Password. Forgot your password? Login. Mojang © 2009-2021. "Minecraft" is a trademark of Mojang AB.
What is Minecraft? | Minecraft
https://www.minecraft.net/en-us/about-minecraft
https://www.minecraft.net › en-us › about-minecraft
Prepare for an adventure of limitless possibilities as you build, mine, battle mobs, and explore the ever-changing Minecraft landscape.
'''
从 SerpApi 博客中提取标题
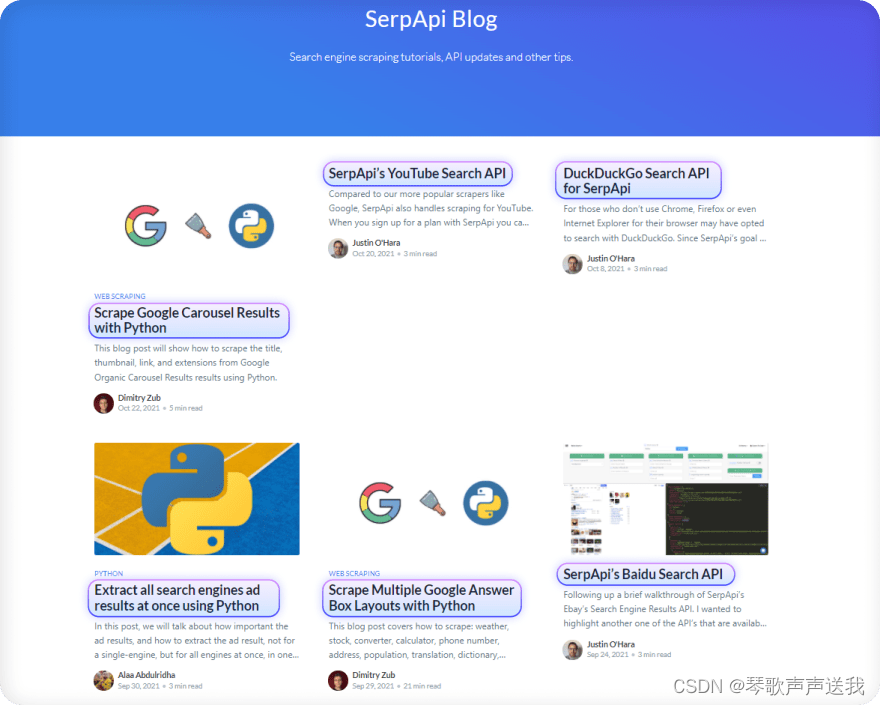
.post-card-title在 Devtools 控制台中测试CSS 选择器:
$$(".post-card-title")
(7) [h2.post-card-title, h2.post-card-title, h2.post-card-title, h2.post-card-title, h2.post-card-title, h2.post-card-title, h2.post-card-title]
0: h2.post-card-title
1: h2.post-card-title
2: h2.post-card-title
3: h2.post-card-title
4: h2.post-card-title
5: h2.post-card-title
6: h2.post-card-title
length: 7
[[Prototype]]: Array(0)
代码:
import requests, lxml
from bs4 import BeautifulSoup
html = requests.get("https://serpapi.com/blog/")
soup = BeautifulSoup(html.text, "lxml")
for title in soup.select(".post-card-title"):
print(title.text)
'''
Scrape Google Carousel Results with Python
SerpApi’s YouTube Search API
DuckDuckGo Search API for SerpApi
Extract all search engines ad results at once using Python
Scrape Multiple Google Answer Box Layouts with Python
SerpApi’s Baidu Search API
How to reduce the chance of being blocked while web scraping search engines
'''
提取标题
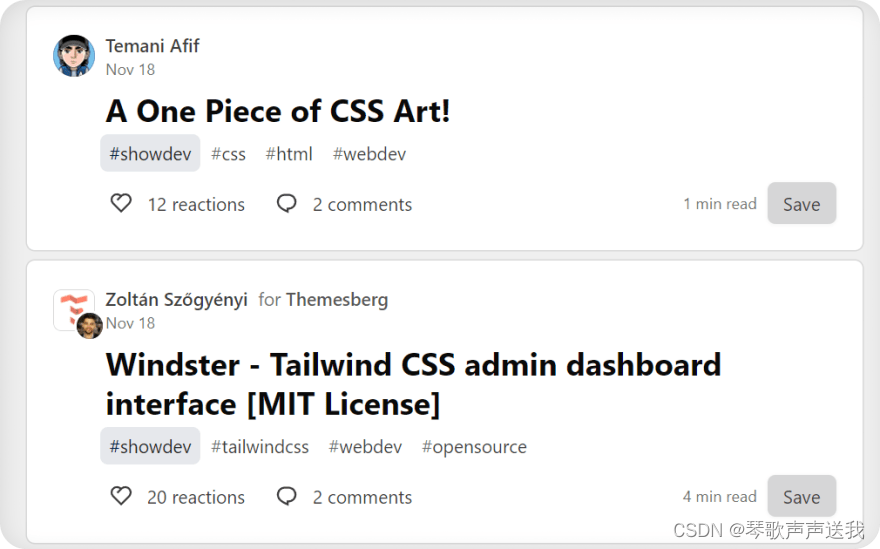
CSS使用 SelectorGadget 或 DevTools 控制台测试选择器:
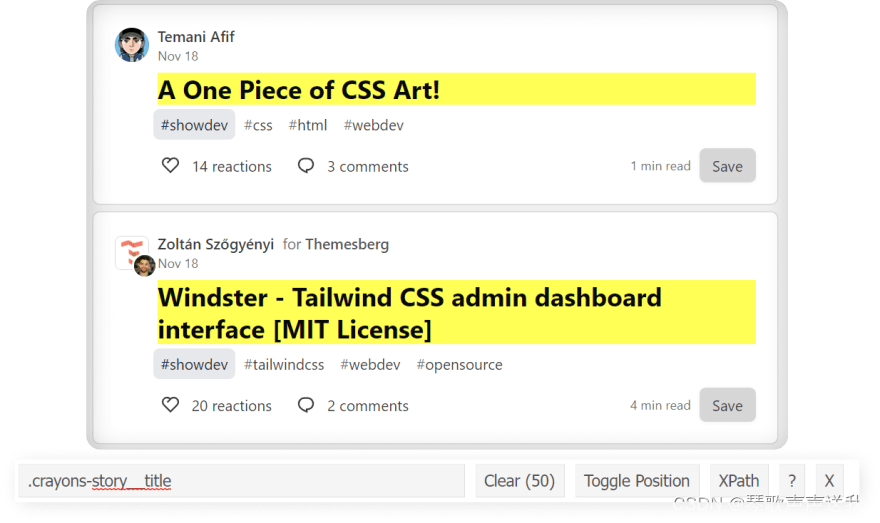
代码:
import requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
html = requests.get("https://dev.to/", headers=headers)
soup = BeautifulSoup(html.text, "lxml")
for result in soup.select(".crayons-story__title"):
title = result.text.strip()
link = f'https://dev.to{result.a["href"].strip()}'
print(title, link, sep="\n")
# part of the output:
'''
How to Create and Publish a React Component Library
https://dev.to/alexeagleson/how-to-create-and-publish-a-react-component-library-2oe
A One Piece of CSS Art!
https://dev.to/afif/a-one-piece-of-css-art-225l
Windster - Tailwind CSS admin dashboard interface [MIT License]
https://dev.to/themesberg/windster-tailwind-css-admin-dashboard-interface-mit-license-3lb6
'''
















 982
982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











