






概述
Apache Spark,全称伯克利数据分析栈,是一个开源的基于内存的通用分布式计算引擎,内部集成大量的通用算法,包括通用计算、机器学习、图计算等,用于处理大数据应用。
主要由下面几个核心构件组成,具体包括:
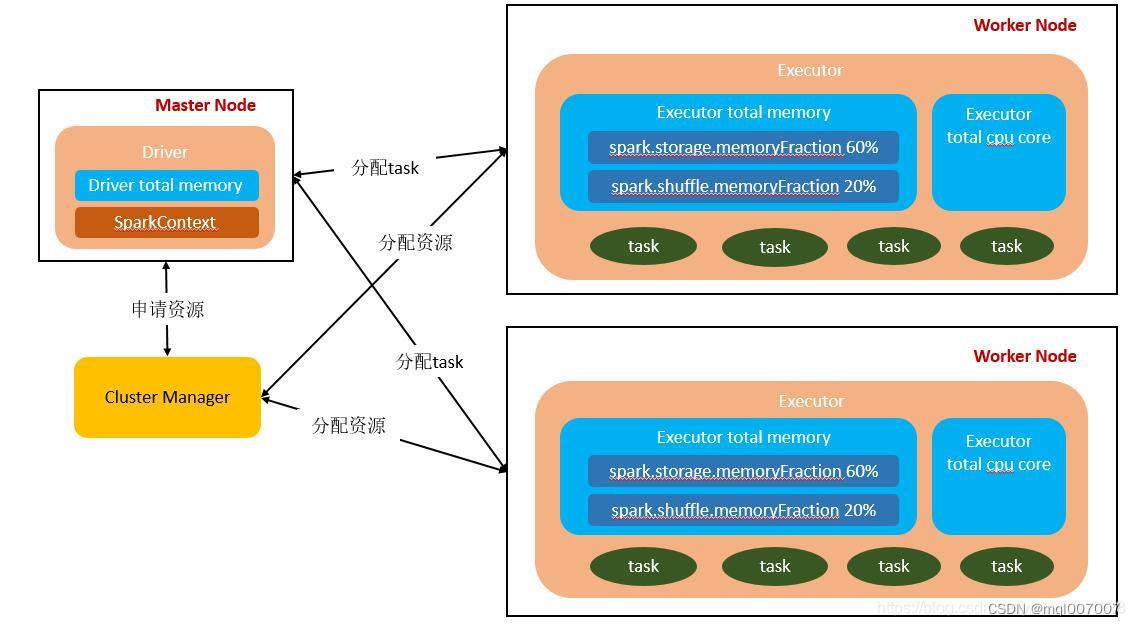
集群资源管理器(Muster Node)、任务控制节点(Driver)、任务执行节点(Worker Node)。
其中集群资源管理器可自由集成其他管理器(例如Yarn、Mesos、K8s等),目前一般主流生产环境都搭载在Yarn上运行。
Spark计算模型本质和MapReduce一样,也需要经过Map和Reduce两个过程,只是中间计算过程、计算依赖的编程模型、任务调度机制等,更加高效、快速、灵活。与Hadoop MapReduce计算框架相比,有下面几个优点:
1、采用多线程来执行具体的任务,MapReduce采用进程模型,减少进程切换的性能开销。
2、内部架构拥有一个BlackManager存储模块,会将内存和磁盘共同作为存储设备,中间计算结果可保存起来,MapReduce的中间计算结果都是落到HDFS文件里,减少IO开销。
3、内部计算都在内存里完成,MapReduce计算过程需要大量和磁盘进行交互,计算速度非常快。
4、任务调度机制采用有向无环图DAG,MapReduce采用迭代机制,可以共享中间计算结果
下面从如下几个方面介绍下其相关理论:
目录
一、架构
二、核心知识点
1、核心组件
SparkCore:将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。
SparkSQL:操作结构化数据的程序包,可以使用SQL语句的方式来查询数据,Spark支持多种数据源,包含Hive,Hbase、RMDBS、Kafka、JSON等数据源。开发人员无须编写 MapReduce程序,直接使用SQL命令就能完成更加复杂的数据查询操作。
SparkStreaming: 提供实时的流式计算组件,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用 Spark Core进行快速处理。
MLlib:提供常用机器学习算法的实现库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能,开发人员只需了解一定的机器学习算法知识就能进行机器学习方面的开发,降低了学习成本。
GraphX:提供一个分布式图计算框架,能高效进行图计算,拥有图计算和图挖掘算法的API接口以及丰富的功能和运算符,极大地方便了对分布式图的处理需求,能在海量数据上运行复杂的图算法。
BlinkDB:用于在海量数据上进行交互式SQL的近似查询引擎。
Tachyon:以内存为中心高容错的的分布式文件系统。
2、基本概念
Apache SparkContext
是Spark应用程序的核心,负责建立Spark的运行环境,通过提交Spark应用程序来驱动Spark配套服务完成作业计算任务。主要工作是:
获取Spark应用程序的当前状态
取消工作
取消Stage(一个阶段)
同步运行job
异步运行job
访问持久化的RDD
释放一个持久化的RDD
可编程动态资源分配
Apache Spark Shell
是用Scala编写的Spark应用程序,它提供Spark运行环境的命令行工具,便于管理Spark应用的执行
Spark Application
用户编写的Spark应用程序,包含了Driver Program以及在集群上运行的程序代码,物理机器上涉及了driver,master,worker三个节点。
Driver
Spark程序在Driver(进程)上执行,Driver进程所在的节点可以是Spark集群的某一个节点或者就是我们提交Spark程序的客户端节点,具体Driver进程在哪个节点上启动是由我们提交任务时指定的参数决定的。
Driver负责运行Application的main函数并创建SparkContext,由SparkContext负责与Cluster Manager通信,进行资源申请、任务的分配、监控等,当Executor部分运行完毕后Driver同时负责将SparkContext关闭。
Master
集群资源管理器中的主节点中启动的进程,主要负责集群资源的管理、分配、集群监控等,Master是一个物理节点。
Worker
集群资源管理器中的从节点中启动的进程,主要负责启动其它进程来执行具体数据的处理和计算任务,Worker是一个物理节点,在上面启动Executor进程执行Task。
Executor
Executor是一个执行Task的容器,由Worker负责启动,主要为了执行数据处理和计算,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个任务都有各自独立的Executor。
作业(Job)
Job是并行计算的工作单元,由多个任务组成,这些任务是响应Apache Spark中的Actoion而产生的。
一个Job包含多个RDD及作用于相应RDD上的各种操作,它包含很多task的并行计算,可以认为是SparkRDD里面的action,每个action的触发会生成一个job。用户提交的Job会提交给DAGScheduler,Job会被分解成Stage,Stage会被细化成Task,Task简单的说就是在一个数据partition上的单个数据处理流程。
任务(Task)
由Executor负责启动,它是真正干活的,完成具体的计算任务。每个阶段都有一个任务,每个分区分配一个任务,同一任务是在RDD的不同分区上完成的。
在Spark中有两类task:
shuffleMapTask,输出是shuffle所需数据,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。
resultTask,输出是计算结果,
比如:rdd.parallize(1 to 10).foreach(println)
这个操作没有shuffle,直接就输出了,那么只有它的task是resultTask,stage也只有一个。
比如:rdd.map(x=>(x,1)).reduceByKey(_+_).foreach(println)
这个操作有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。如果job中有多次shuffle,那么每个shuffle之前都是一个stage。
任务阶段(Stage)
是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为一个Stage就像MapStage,ReduceStage,或者也被称为TaskSet,代表一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集。
每个Job都分成一些较小的任务集,称为相互依赖的阶段(Stage)。Stage被分类为计算边界,不能在单个Stage中完成所有计算,Job通过许多个阶段(Stage)来完成具体作业目标。
RDD之间有一系列的依赖关系,又分为窄依赖和宽依赖。简单的区分可以看一下父RDD中的数据是否进入不同的子RDD,如果只进入到一个子RDD则是窄依赖,否则就是宽依赖。如下图
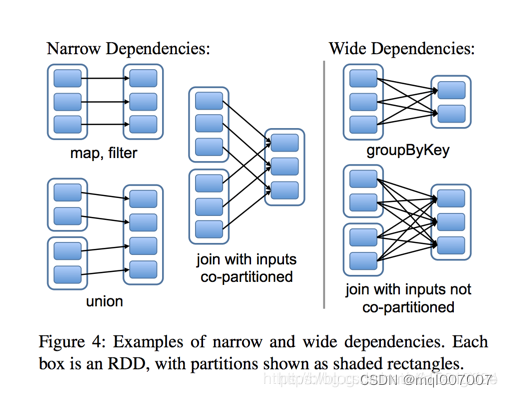
窄依赖( narrow dependencies ):
子RDD 的每个分区依赖于常数个父分区(即与数据规模无关)
输入输出一对一的算子,且结果RDD 的分区结构不变,主要是map 、flatMap
输入输出一对一,但结果RDD 的分区结构发生了变化,如union 、coalesce
从输入中选择部分元素的算子,如filter 、distinct 、subtract 、sample
宽依赖( wide dependencies ):
子RDD 的每个分区依赖于所有父RDD 分区
对单个RDD 基于key 进行重组和reduce ,如groupByKey 、reduceByKey ;
对两个RDD 基于key 进行join 和重组,如join
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。
Spark通过分析各个RDD的依赖关系生成了DAG,在通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage。具体划分方法如下:
在DAG中进行反向解析也就是从后往前,
遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行;
遇到窄依赖就把当前的RDD加入到Stage中;
将窄依赖尽量划分在同一个Stage中,可以实现流水线计算;
有向无环图(DAG)
反映RDD之间的依赖关系。Spark任务会根据RDD之间的依赖关系,形成一个DAG。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
DAGScheduler
根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),并提交Stage给TASkScheduler。 其划分Stage的依据是RDD之间的宽窄依赖关系找出开销最小的调度方法
TASKSedulter
将TaskSET提交给Worker运行,每个Executor运行什么Task就是在此处分配的。TaskScheduler维护所有TaskSet,当Executor向Driver发生心跳时,TaskScheduler会根据资源剩余情况分配相应的Task。另外TaskScheduler还维护着所有Task的运行标签,重试失败的Task。下图展示了TaskScheduler的作用:
存储模块(Block)
hdfs中的block是分布式存储的最小单元,类似于盛放文件的盒子,一个文件可能要占多个盒子,但一个盒子里的内容只可能来自同一份文件。假设block设置为128M,你的文件是250M,那么这份文件占3个block(128+128+2)。
这样的设计虽然会有一部分磁盘空间的浪费,但是整齐的block大小,便于快速找到、读取对应的内容。
block位于存储空间、大小是固定的、有冗余、不会轻易丢失。
分区(Partition)
是弹性分布式数据集RDD的最小单元,Spark计算是以partition为单位进行的,当然partition的划分依据可由具体作业控制,提供了一种划分数据的方式。
RDD是由分布在各个节点上的partition组成的,partition是指spark在计算过程中生成的数据,同一份数据(RDD)的partition大小不一,数量不定,是根据application里的算子和最初读入的数据分块数量决定的,所以叫“弹性分布式”数据集。
partition位于计算空间、大小是不固定的、没有冗余设计、丢失之后通过重新计算得到。
弹性分布式数据集(RDD)
是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合,Spark的编程模型是以RDD为基础的,各种处理和分析过程都是以RDD数据模型来开展。
RDD计算时是以分片(Partition)为基本单位进行的,Spark内部实现了两种分片策略,一种是基于哈希的HashPartitioner,一种是基于范围的RangePartitioner。
一个计算任务包括一系列RDD,在计算过程中会动态产生新的RDD,这些RDD之间具有一定的血缘关系,若发生数据丢失可基于这种关系直接重新计算丢失RDD即可,不需要整个任务重新计算。
RDD具有数据流模型的特点:自动容错、位置感知性调度、可伸缩性,可将中间计算过程产生的RDD缓存在内存或磁盘(容量大时)上,便于后续计算复用中间计算结果,减少了IO开销,提升查询速度。
注意:Spark应用程序代码中的RDD和Spark执行过程中生成的物理RDD不是一一对应的。
存储模块与RDD的生成:

输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为Block。
当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨越文件。
随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。
随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。
每个节点可以起一个或多个Executor。
每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
每个Task执行的结果就是生成了目标RDD的一个partiton。
注意: 这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。
而 Task被执行的并发度 = Executor数目 * 每个Executor核数。
至于partition的数目:
对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task。
在Map阶段partition数目保持不变。
在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
3、编程模型
Spark的编程模型是基于RDD开展的,编程过程就是对一系列RDD进行计算处理。
大数据计算就是在大规模的数据集上进行一系列的数据计算处理。
例如:MapReduce 针对输入数据,将计算过程分为两个阶段,一个 Map 阶段,一个 Reduce 阶段,然后计算过程就围绕着Map和Reduce开展,不停处理Map和Reduce,都是直接处理相应过程的直接结果,直到完成整个计算任务结果。
Spark计算思想本质也是基于两个阶段,只是中间计算过程由处理一系列RDD组成,直接基于数据计算,由于一系列RDD之间具有一定的血缘关系,所以可以复用和重新计算,加快计算速度。
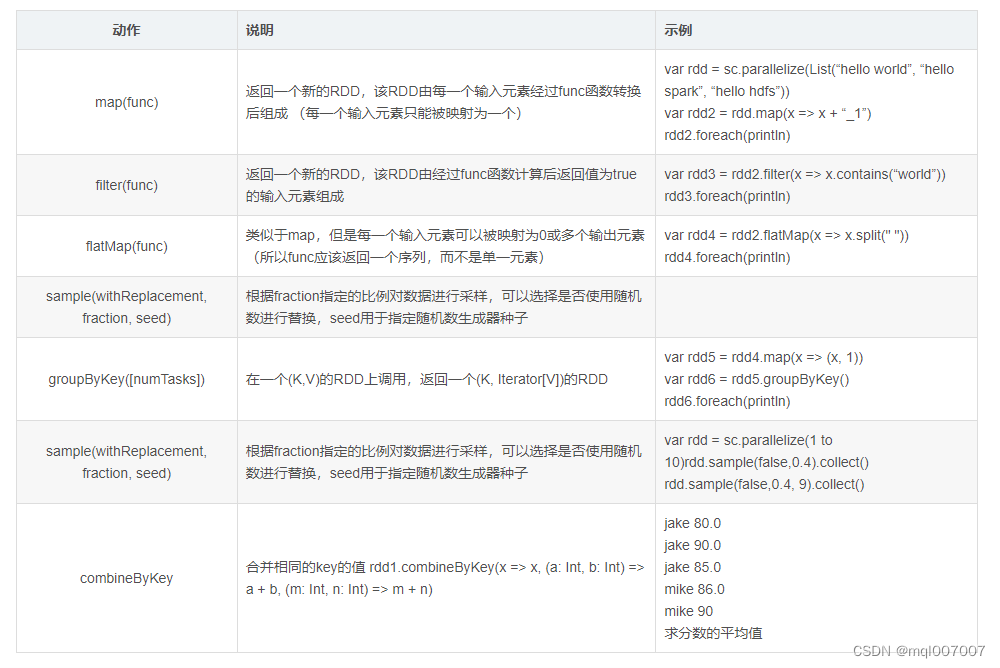
RDD上定义了很多操作函数,具体分为二大类,一类是转换函数(Transformation);一类是执行函数(Action)。
转换函数(Transformation):返回值是有的会产生新的RDD,有的不会产生新的RDD,只是改变当前RDD的数据内容。具有lazy特性(延迟加载),Transformation算子的代码不会真正被执行,只有当我们的程序里面遇到一个Action算子的时候,代码才会真正的被执行。
Spark内置了很多转换函数,详见下图:
执行函数(Action):触发代码的运行,所以Spark应用代码里至少需要有一个Action操作。
Spark内置了很多执行函数,详见下图:

持久化函数:可以对RDD、计算过程等计算任务进行持久化保存。RDD持久化级别
具体包括:cache()、persist()、checkpoint()
RDD持久化级别,详见下图:

cache和persist都是用于将一个RDD进行缓存,这样在之后使用的过程中就不需要重新计算,可以大大节省程序运行时间。
cache和persist的区别:cache只有一个默认的缓存级别MEMORY_ONLY,而persist可以根据情况设置其它的缓存级别。
checkpoint接口是将RDD持久化到HDFS中,与persist的区别是checkpoint会切断此RDD之前的依赖关系,而persist会保留依赖关系。
checkpoint的两大作用:
1)、spark程序长期驻留,过长的依赖会占用很多的系统资源,定期checkpoint可以有效的节省资源;
2)、是维护过长的依赖关系可能会出现问题,一旦spark程序运行失败,RDD的容错成本会很高。
注意:checkpoint执行前要先进行cache,避免两次计算。
4、计算过程
大数据计算基本原则:遵循”移动数据不如移动计算“理念,MapReduce和Spark都遵循这一基本原则,在中间计算过程中都需对数据进行“Shuffle”处理,然后才能得到最终的计算结果。
Shuffle过程:(无论是MapReduce还是Spark,都要实现Shuffle)
a、Shuffle就是处理数据从Map Tasks的输出到Reduce Tasks输入的这段过程。
b、Map Tasks的output向着Reduce Tasks的输入input映射的时候,并非节点一一对应的,在节点A上做map任务的输出结果,可能要分散跑到reduce节点A、B、C、D ,就好像shuffle的字面意思“洗牌”一样,
这些map的输出数据要打散然后根据新的路由算法(比如对key进行某种hash算法),发送到不同的reduce节点上去。
c、将最后阶段的reduce结果汇集在一起得到计算任务最终结果。
MapReduce计算过程:
根据MapReduce应用代码生成任务执行计划,然后持续迭代Map和Reduce两个过程的结果,直至全部任务计算完成,Shuffle过程需要多次IO磁盘,计算速度比较慢。下图描述了下MapReduce的Shuffle过程:
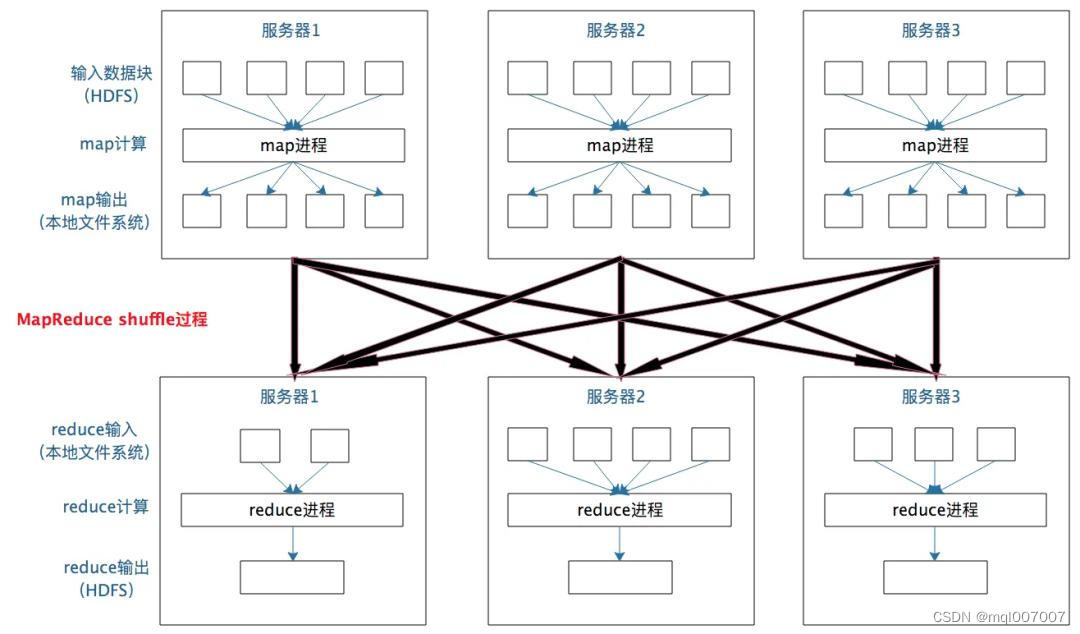
MapReduce 是 sort-based,进入 combine() 和 reduce() 的 records 必须先partition、key对中间结果进行排序合并,因为其输入数据可以通过外部得到(mapper 对每段数据先做排序,reducer 的 shuffle 对排好序的每段数据做归并)
Spark计算过程:
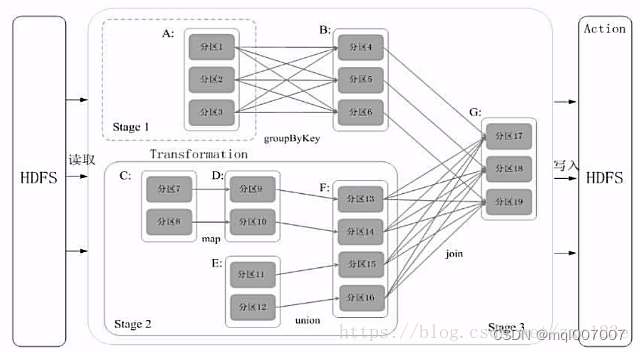
根据Spark应用代码生成任务执行计划,这个任务计划用有向无环图DAG表示,也就是说不同的计算阶段依赖关系是有向的,具体执行时序按依赖方向进行,有先后关系。见下图描述:
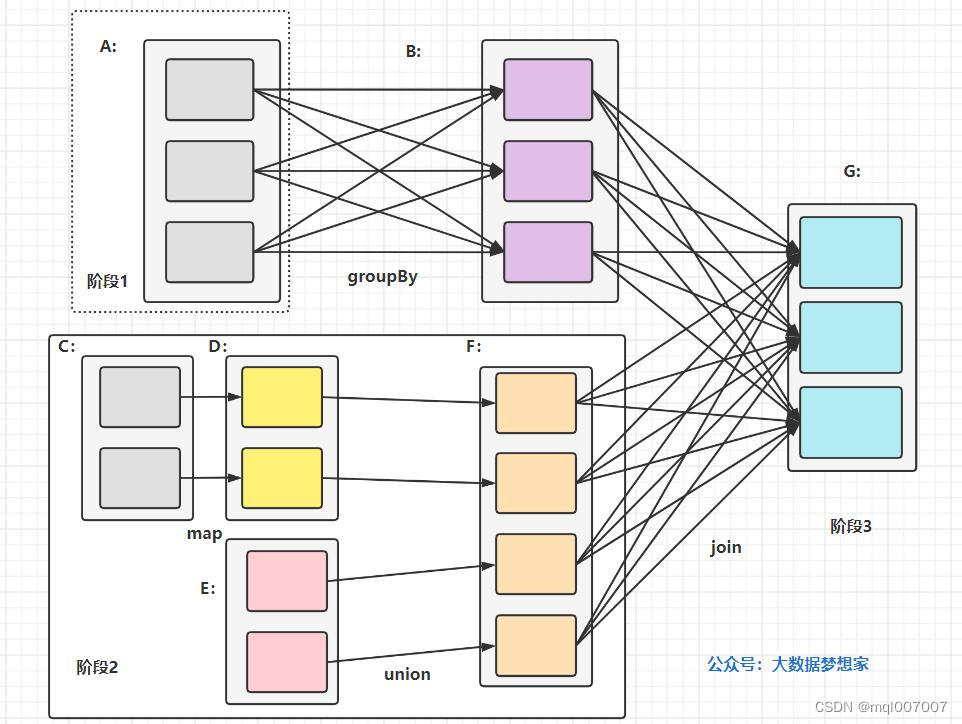
在上图中, A、C、E 是从 HDFS 上加载的 RDD,A 经过 groupBy 分组统计转换函数计算后得到的 RDD B,C 经过 map 转换函数计算后得到 RDD D,D 和 E 经过 union 合并转换函数计算后得到 RDD F ,B 和 F 经过 join 连接函数计算后得到最终的合并结果 RDD G 。
所以可以看到 Spark 作业调度执行的核心是 DAG,有了 DAG,整个应用就被切分成哪些阶段,每个阶段的依赖关系也就清楚了。之后再根据每个阶段要处理的数据量生成相应的任务集合(TaskSet),每个任务都分配一个任务进程去处理,Spark 就实现了大数据的分布式计算。
具体来看的话,负责 Spark 应用 DAG 生成和管理的组件是 DAGScheduler,DAGScheduler 根据程序代码生成 DAG,然后将程序分发到分布式计算集群,按计算阶段的先后关系调度执行。
Spark也需要通过 Shuffle 过程将数据进行重新组合,相同 Key 的数据放在一起,进行聚合、关联等操作,因而每次 Shuffle 都产生新的计算阶段。这也是为什么计算阶段会有依赖关系,它需要的数据来源于前面一个或多个计算阶段产生的数据,
必须等待前面的阶段执行完毕才能进行 Shuffle,并得到数据。
在DAG阶段以Shuffle为界,划分stage,上游stage做map task,每个map task将计算结果数据分成多份,每一份对应到下游stage的每个partition中,并将其临时写到磁盘,该过程叫做shuffle write;
下游stage做reduce task,每个reduce task通过网络拉取上游stage中所有map task的指定分区结果数据,该过程叫做shuffle read,最后完成reduce的业务逻辑。下图描述了Spark的Shuffle过程:
Spark有下面两种Sheffle过程,一种是Hash Shuffle(2.0开始已经删除),一种是Sort Shuffle
Hash Shuffle 过程

Sort Shuffle 过程
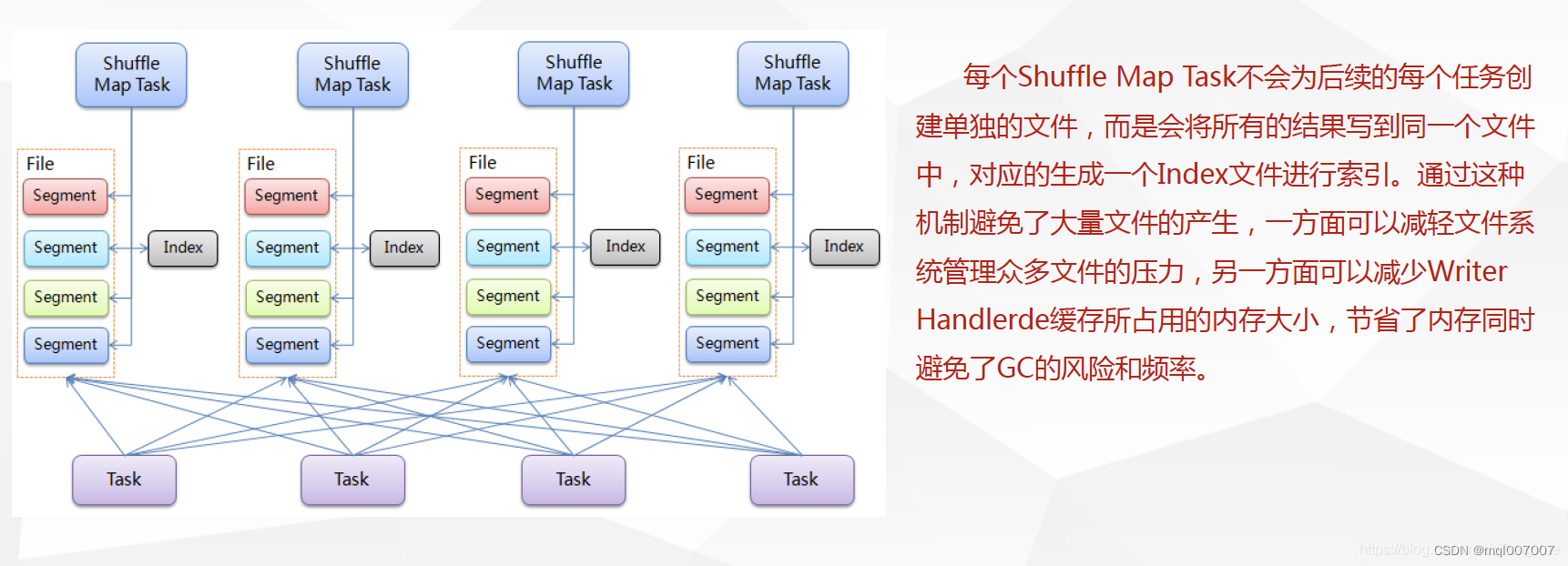
从本质上看,Spark 可以算作是一种 MapReduce 计算模型的不同实现。Hadoop MapReduce 简单粗暴地根据 shuffle 将大数据计算分成 Map 和 Reduce 两个阶段,然后不停的迭代,每次迭代都要经过IO磁盘,所以性能开销较大,计算速度较慢。
Spark 更细腻一点,将前一个的 Reduce 和后一个的 Map 连接起来,当作一个阶段持续计算,形成一个更加优雅、高效的计算模型,其本质依然是 Map 和 Reduce。
但是这种多个计算阶段依赖执行的方案可以有效减少对 HDFS 的访问,减少作业的调度执行次数,同时计算过程在内存中进行,还可以缓存局部RDD数据到内存(量大时可写入磁盘),因此执行速度更快。
5、整体运行过程
5.1、提交Spark应用作业后,在JVM内部启动一个Driver进程,该进程就是应用的main()函数并且构建SparkContext对象,根据使用的部署模式不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。
SparkContext 启动 DAGScheduler 构造执行的 DAG 图,切分成最小的执行单位也就是计算任务。
5.2、Driver进程首先会向集群管理器(standalone、yarn,mesos)申请spark应用所需的资源,这里的资源指的就是Executor进程。
然后集群管理器会根据spark应用所设置的参数在各个worker上分配一定数量的executor,每个executor都占用一定数量的cpu和memory。
将 Driver 的主机地址等信息通知给集群的所有计算节点 Worker。
5.3、在得到申请的应用所需资源以后,Driver就开始调度和执行我们编写的应用代码。Driver进程会将我们的应用代码拆分成多个stage(根据shuffle类算子为单位进行划分),每个stage都是任务的集合(taskset)并以taskset为单位提交给TaskScheduler。
一个stage执行完成后,同时会将计算结果写入内存或磁盘用于复用和容错。
5.4、TaskScheduler通过TaskSetManager管理任务(task)并通过集群中的资源管理器(Cluster Manager)<standalone模式下是Master,yarn模式下是ResourceManager>把任务(task)发给集群中的Worker的Executor, 期间如果某个任务(task)失败,
TaskScheduler会重试,TaskScheduler发现某个任务(task)一直未运行完成,有可能在不同机器启动一个推测执行任务(与原任务一样),哪个任务(task)先运行完就用哪个任务(task)的结果。
无论任务(task)运行成功或者失败,TaskScheduler都会向DAGScheduler汇报当前状态,如果某个stage运行失败,TaskScheduler会通知DAGScheduler可能会重新提交任务。
5.5、Driver 根据 DAG 图开始向注册的 Worker 分配任务, 根据 Driver 的主机地址跟 Driver 通信并注册Worker到Driver,然后将根据自己的空闲资源向 Driver 通报自己可以领用的任务数及当前任务执行状态。
Worker接收到的是任务(task), 启动 Executor 进程来执行任务(task),一个 Executor 进程中可以有多个线程工作进而可以处理多个数据分片,执行任务(task)、读取或存储数据。

三、部署方式
1、本地模式(local)
运行在本地,利用本地资源进行计算,所有进程都运行在一台物理机上,仅用于开发者搭建学习和试验环境。
2、独立集群模式(Standalone)
由一个Master和多个Worker构成,集群资源管理由Spark自己管理,可通过Zookeeper搭建Master高可用。具体又分为两种:一种是client模式;一种是cluster模式。
2.1、client模式:Driver是在SparkSubmit进程中运行
2.2、cluster模式:Driver运行在集群当中,需要将jar包上传到集群中。

3、集群模式(基于Yarn)【推荐生产使用】
基于Yarn的集群模式具体又分为两种:一种是YARN-Client模式;一种是YARN-Cluster模式。
3.1、YARN-Client模式:
1)、Spark Yarn Client向YARN的ResourceManager申请启动Application Master,同时在SparkContent初始化中将创建DAGScheduler、TASKScheduler、SparkEnv等运行环境,
由于选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
2)、ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,该ApplicationMaster不运行SparkContext,只与SparkContext联系进行资源的分派;
3)、Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
4)、一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,启动后会向Client中的SparkContext注册并申请Task;
5)、Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6)、应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己;
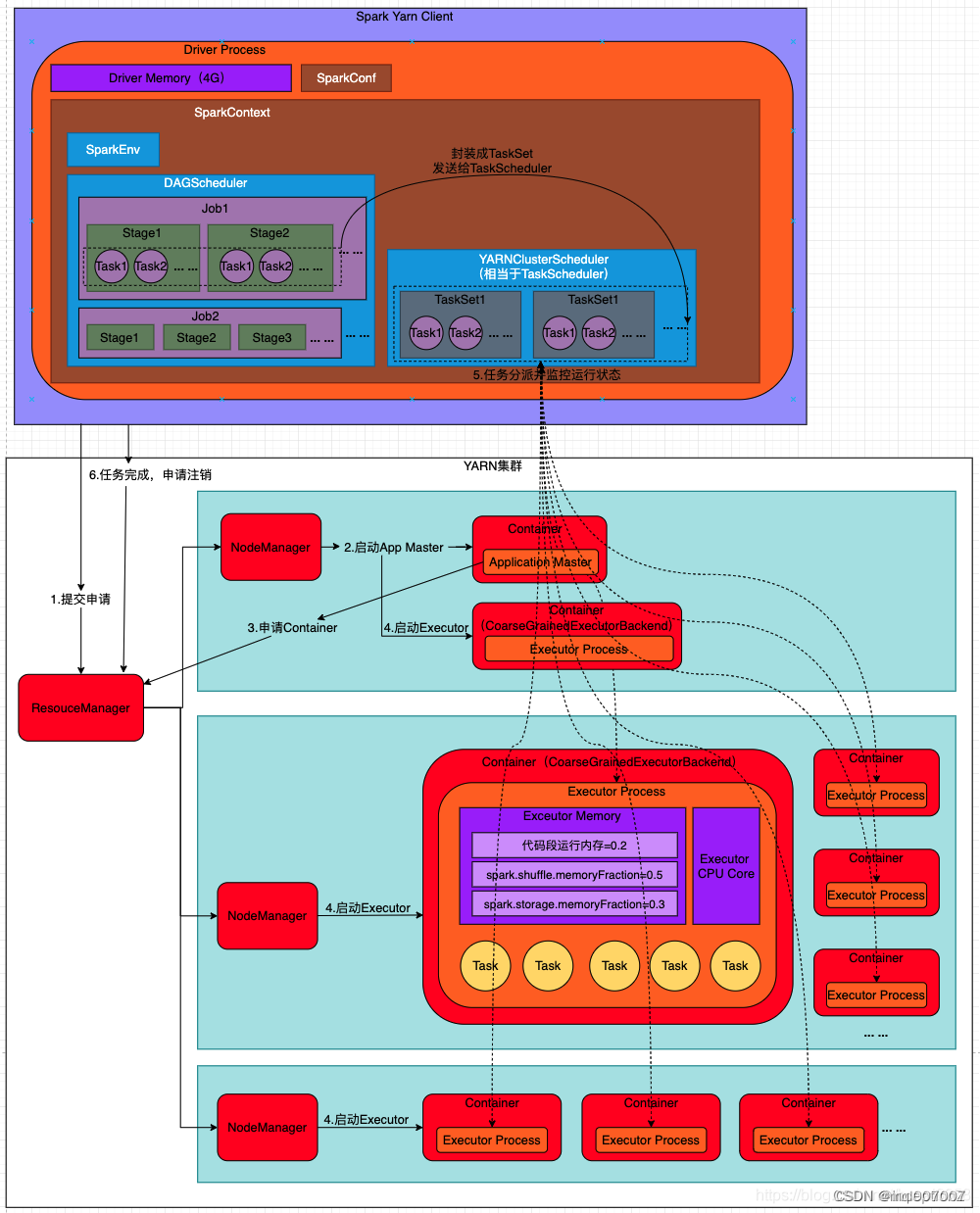
下面是一个client方式提交示例, 使用spark-submit提交一个任务到高可用的YARN集群,,使用client模式:
./bin/spark-submit
–class org.apache.spark.examples.mainTest
–master yarn
–deploy-mode client
–executor-memory 512m
–total-executor-cores 1
~/jars/spark-examples.jar
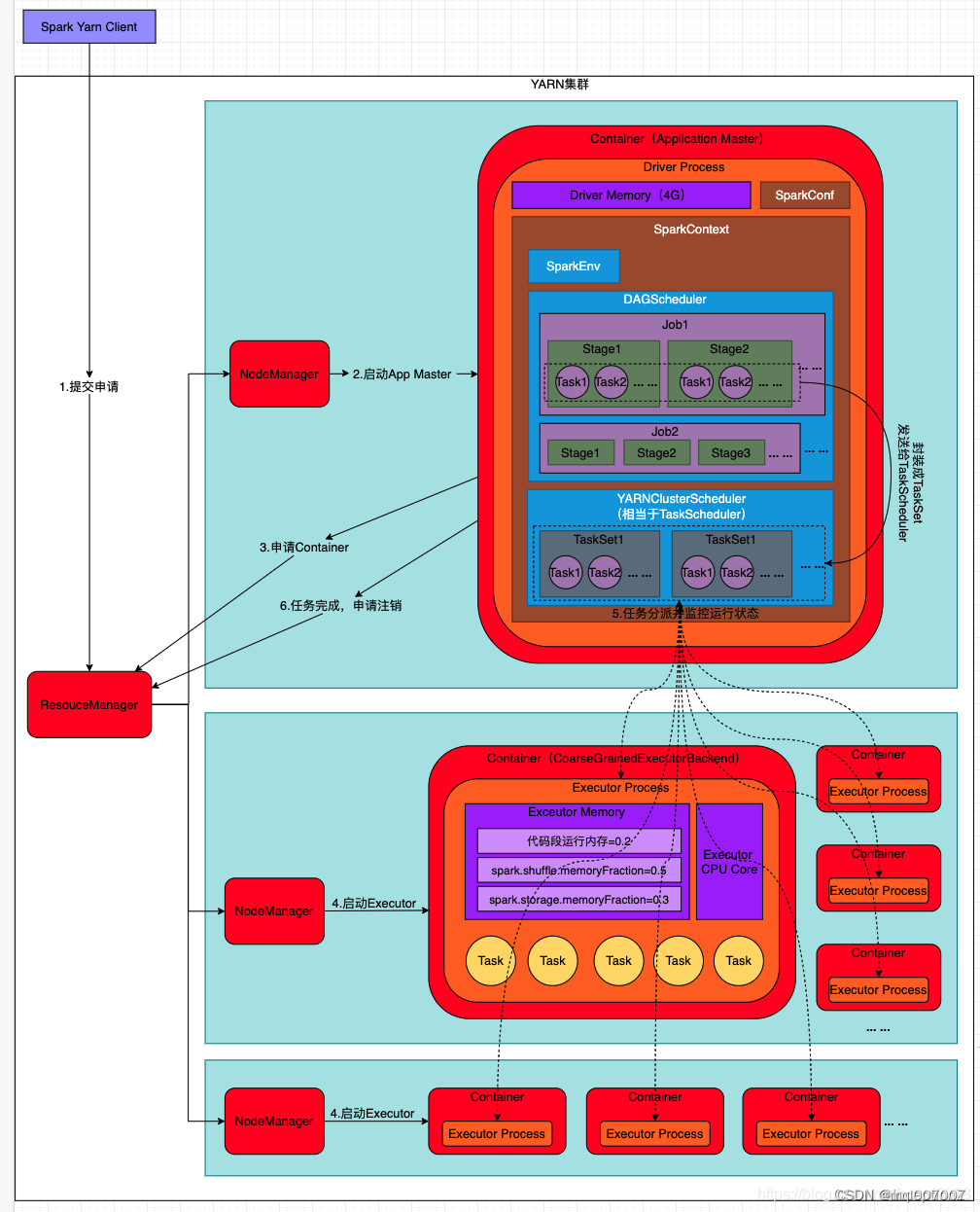
3.2、YARN-Cluster模式:
1)、Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
2)、ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
3)、ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
4)、一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,
CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。
5)、ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,
从而可以在任务失败时重新启动任务;
6)、应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
下面是一个client方式提交示例,使用spark-submit提交一个任务到高可用的YARN集群,使用cluster模式:
./bin/spark-submit
–class org.apache.spark.examples.mainTest
–master yarn
–deploy-mode cluster
–executor-memory 512m
–total-executor-cores 1
~/jars/spark-examples.jar
3.3、YARN-Client模式与YARN-Cluster模式的区别:
理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。
在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。
从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别。
YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业。
YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,必须依赖Client。
下图是几种模式下的比较:

四、优缺点分析
缺点
1、因为基于内存计算,所以对内存的容量及稳定性要求较高,同时应用要控制内存的应用情况,不然会发生OOM,导致应用崩溃
2、因为支持应用自定义分区规则,所以容易发生数据倾斜
3、自带集群资源管理器不太稳定,推荐生产环境应用Yarn来接管资源分配
4、受限于单机内存大小,所以不支持超大数据量的计算
5、由于作业进程常驻内存,数据都在内存里,由于内存垃圾回收延迟可能产生意想不到的结果,对代码质量要求较高
6、不支持复杂的SQL统计计算
7、不同Spark应用没有办法共享缓存的数据,除非引入外部缓存
优点:
1、支持大容量且批处理、流处理(本质是微批处理)计算
2、基于内存计算,计算速度快,对于大容量计算优化,可将中间计算结果写入内存或磁盘(数据量大时)
3、任务执行机制采用有向无环图DAG,能够关联数据血缘关系,可以共享中间计算结果,避免重新计算,耗费时间和资源
4、基于弹性分布式数据集RDD进行计算,集成大量的相关计算算法,支持多种数据集操作类型,具体包括两大类Transformations和Actions,便于开发具体应用
5、可以基于不同的数据源进行计算,支持Hive、Hbase、RMDBS、Kafka、JSON等数据源
6、高容错性
基于RDD数据模型,丢失的数据可容易的通过重新计算再次获得,重算过程在不同节点之间并行、只记录粗粒度的操作
7、高扩展性
计算能力理论可无限扩展, 支持scale-out和scale-up两个方向扩展
集群管理器可集成不同三方资源管理器(例如Yarn、Mesos、k8s等)
8、高性能
待计算数据实时读入内存,计算速度快,且可共享中间计算结果,存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化
9、高可靠性
自动感知节点状态
自带集群资源管理器,通过ZK可支持高可用
也可依赖其他资源管理器(支持高可用)
10、可以使用Spark Sql进行类SQL查询
11、支持Java、Python和Scala的API,可多种形式编写Spark应用
12、活跃度极高的社区和完善的生态圈的支持
五、常见应用场景
1、数据处理、ETL(ELT)、迭代计算
2、计算基础事实数据落入数据仓库,支持进行交互式查询
3、依据业务模型进行机器学习
4、一些流式应用场景,例如:
空气质量预测和评价
自动判断买家好/差评
客户流失预测
页面浏览/点击分析
推荐系统
舆情分析
点击预测
即席查询
内容精准推荐
社区发现
等等
六、调优经验
PS:后续逐渐把实践调优过程补充上来
七、API应用:
各个平台一般都有相应的操作组件,下面介绍下java和DoNet平台下的访问组件。
java平台:
1、纯原生java操作
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>版本</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>版本</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>版本</version>
</dependency>
若和其他应用集成还需要引入配套依赖,例如Hive、Kafka、Mysql、flume等需要引入下面配套依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>版本</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>版本</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>版本</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.11</artifactId>
<version>版本</version>
</dependency>
DoNet平台:(注意:Windows平台也可以搭建spark运行环境)
1、Microsoft.Spark.Worker,需要依赖WinUtils(仅限 Windows)
Microsoft.Spark
Nuget: 下载Microsoft.Spark、Microsoft.Spark.Worker














 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









