






视觉词袋
许多应用中需要快速的图像特征匹配,比如视觉SLAM中的回环检测环节,需要实时判断当前图像帧是否在之前的图像数据库中出现,为了满足实时场景,对时间要求非常敏感。
目前特征提取,包括SIFT、SURF等,在执行特征匹配时往往比较耗时,视觉词袋的设计则在一定程度解决了这一问题。
视觉词袋是一种利用视觉词汇表将图像转换为稀疏分层向量的技术手段,从而可以操作数量较大的图像集合。 本文中介绍的词袋模型主要参考《Bags of Binary Words for Fast Place Recognition in Image Sequences》文献,以FAST提取特征,BRIEF提取描述,为256 bit。
视觉词汇表通过离线的将2进制描述空间离散为
W
个词汇,在分层的词汇表中,将其表示为树结构。通过在图像数据集中提取大量的特征描述,并将其通过聚类方法将其离散为
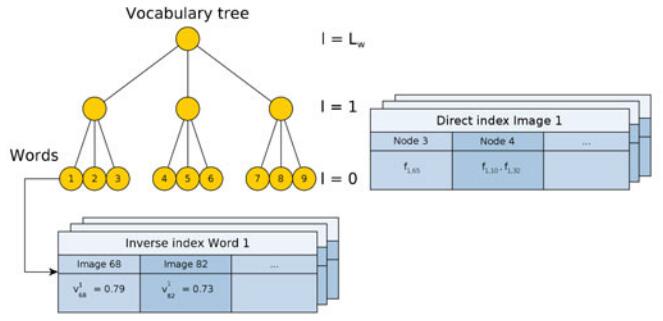
每个单词带有权重,该权重通过训练过程中的相关性进行确定,降低出现频率非常大但区别很小的词汇的权重,比如采用tf-idf算法。
每张图像(在线的)
反续表(Inverse index)
反续表为每个词汇 wi 存储一个图像列表,该列表中图像均含有该词汇,列表中每个元素表示为 <It,vit> <script type="math/tex" id="MathJax-Element-1017"> </script>。对于在数据库中快速检索含有相同词汇的场景非常有用。该反续表在图像加入时进行更新。
直接表(Direct index)
还有一种场景,需要在图像之间寻找最相似特征,直接表则可以派上用场。直接表可以有效的存储图像的特征,并提供比对。我们按照树结构在每一层
l
上分割节点,这些节点在出现的图像
词汇相似度
s(v1,v2)=1−12∣v1∣v1∣∣−v2∣v2∣∣















 4500
4500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









