






Implicit Neural Representations for Image Compression (arXiv 2021)
Paper: https://arxiv.org/abs/2112.04267
Abstract
近年来,内隐神经表示(INRs)作为一种新颖有效的数据类型表示方法受到了广泛关注。到目前为止,之前的工作主要集中在优化它们的重构性能。这项工作从一个新的角度研究INRs,即作为图像压缩的工具。为此,我们提出了第一个基于INRs的综合图像压缩管道,包括量化、量化感知再训练和熵编码。用INRs编码,即对数据样本的过拟合,通常慢一个数量级。为了拟合这个缺点,我们利用基于MAML的元学习初始化来在更少的梯度更新中达到编码,这也通常提高了INRs的率失真性能。我们发现,我们使用INRs进行源压缩的方法大大优于之前类似的工作,可以与专门为图像设计的常见压缩算法竞争,并缩小与基于率失真自动编解码器的先进学习方法的差距。另外,我们提供了一个全面的消融实验以验证每个部分的重要性,我们希望这有助于图像压缩的在这个新方法上的未来研究。
1. Introduction
在数字化无处不在、重要决策都基于大数据分析的当今世界,如何有效存储信息的问题比以往任何时候都更加重要。源压缩是一种通用术语,用于以一种紧凑的形式表示数据,这种形式要么保留所有信息(无损压缩),要么牺牲一些信息以实现更小的文件大小(有损压缩)。它是解决每天从互联网上上传、传输和下载大量图像和视频数据的关键组件。无损压缩可能更可取,它有一个基本的理论极限,即香农熵[44]。因此,有损压缩的目的是在文件质量和文件大小之间进行权衡,即所谓的速率失真权衡。
除了针对特定数据模式(如音频、图像或视频)调整的传统手工设计算法外,机器学习研究最近通过利用神经网络的力量开发了有前途的学习方法来进行源压缩。.这类方法通常构建在知名的自动编码器[25]上,通过实现它的限制版本。这些所谓的率失真自动编码器(RDAEs)[5,6,22,34]联合优化解码数据质量和其编码文件大小。这项工作避开了rdae的流行方法,并研究了一种新的源压缩范式——尤其是图像压缩。最近,隐式神经表示
3. Method
3.1 Background
INRs储存基于坐标的数据类似于图像、视频和3D形状,通过数据表示成一个连续函数,从坐标映射到值。例如,一个图像是由一个水平垂直的坐标映射到一个色彩空间中的色彩向量的函数:
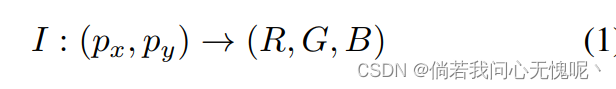
这种映射可以用神经网络fθ近似,典型的是带有参数
θ
\theta
θ的多层感知器(MLP)使
I
(
p
x
.
p
y
)
≈
f
θ
(
p
x
,
p
y
)
I(p_x.p_y) \approx f_{\theta}(p_x,p_y)
I(px.py)≈fθ(px,py)。由于这些函数是连续的,INRs是分辨率无关的,即它们可以在归一化范围[−1,1]内的任意坐标上计算。为了表示一个基于像素的图像张量
x
\bf{x}
x,我们在均匀间隔的坐标网格
p
\bf{p}
p上计算图像函数,使
x
=
I
(
P
)
∈
R
W
×
H
×
3
\bf{x} = I(P) \in \R^{W\times H\times 3}
x=I(P)∈RW×H×3
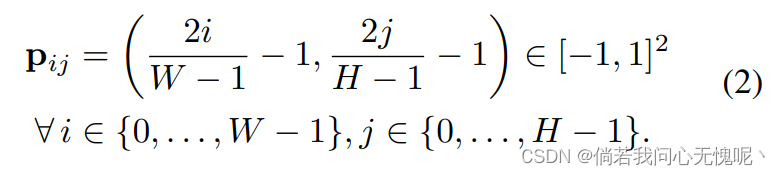
注意,每个坐标向量都是独立映射的:
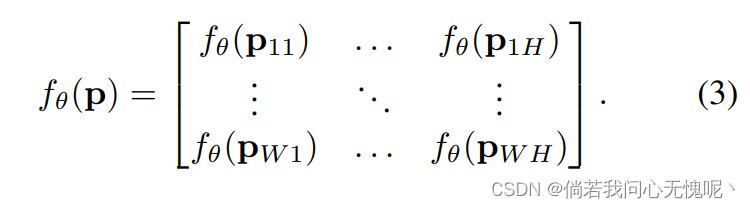
Rate-distortion Autoencoders. 主要的可学习源压缩方法是RDAEs:一个编码器网络产生一个压缩的表示,通常称作中间向量
z
∈
R
d
\bf{z} \in \R^{d}
z∈Rd,用于跟解码器网络联合训练并用于重建原始输入。早期的方法通过强制约束其维度来提高
z
\bf{z}
z的紧致性。较新的方法通过在损失中加入熵估计,即
z
\bf{z}
z的所谓的率损失,来约束这种表示。该码率项反映了z的存储要求,与量化压缩误差的失真项一起最小化。
3.2 Image Compression using INRs
不同于RDAEs,INRs在网络权重
θ
\theta
θ中隐式保存了全部信息。INR本身的输入,即坐标,不包含任何信息。编码过程相当于训练INR。解码过程相当于将一组权值加载到网络中,并在坐标网格上求值。我们可以将其总结为:
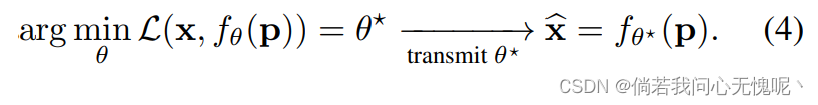
因此,我们只需要储存
θ
∗
\theta^*
θ∗重建原始图像
x
\bf{x}
x的失真版本。利用我们的方法,我们描述了一种寻找
θ
\theta
θ的方法,同时实现存储紧凑和良好重构。
架构: 我们使用SIREN,即使用频率ω = 30的正弦激活的MLP,最初在[46]中提出,其在图像数据上表现良好。我们根据作者的建议调整了初始策略。由于我们的目标是在多个比特率下评估我们的方法,我们改变模型的大小以获得一个率失真曲线。 我们还提供了关于如何改变模型尺寸以获得最佳的率失真性能(参见4.4节)和关于INR的架构(见4.5节)。
输入编码: 输入编码将输入坐标转换为更高的维度,这已被证明可以提高感知质量[37,49]。值得注意的是,据我们所知,我们是第一个将SIREN与输入编码相结合的人——以前的输入编码只用于基于修正线性单元(ReLU)激活函数的INRs。(我怎么记得不是啊,应该早就有人做了) 我们应用[37]中给出的位置编码的改编版本,其中我们引入尺度参数
σ
\sigma
σ来调整频率间距(类似于[49]),并将频率项与原始坐标
p
p
p连接(如在SIREN 1的代码中):
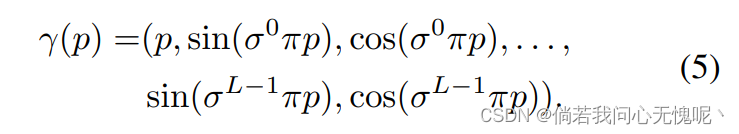
其中L是使用频率的数量。我们将在4.5节中研究输入编码的影响。
3.3 Compression Pipeline for INRs
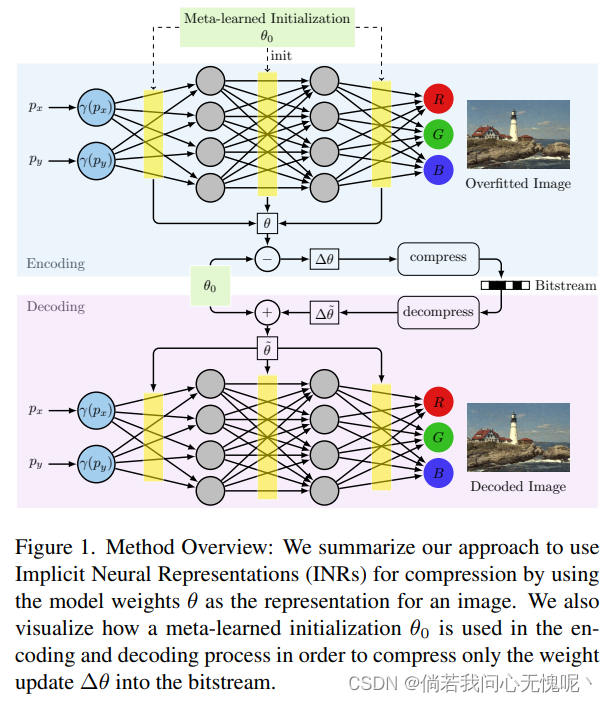
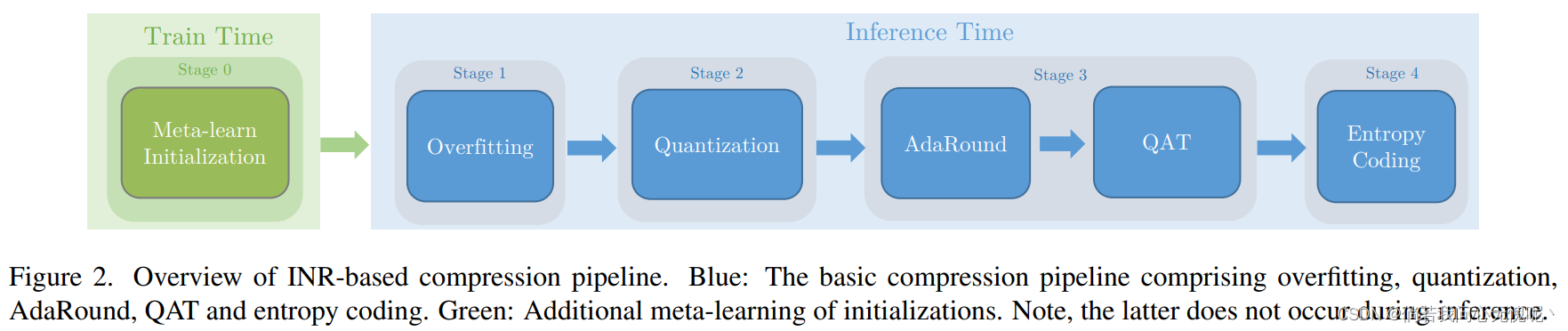
本节介绍我们基于INR的压缩管道。首先,我们描述了基于随机初始化INRs的核心/基本方法(章节3.3.1)。随后,我们提出元学习初始化来提高基于inr的压缩在率失真性能和编码时间方面的性能(章节3.3.2)。组合压缩管道如图2所示,更高层次的概述如图1所示。
3.3.1 Basic Approach using Random Initialization
Stage 1: 过拟合 首先,我们过拟合INR
f
θ
f_{\theta}
fθ到一个数据样本上。过拟合发生在测试时,相当于调用其他学习方法的编码器。(这里是不是说错了,应该是在训练时间才对啊) 我们称这一步为过拟合,以强调INR是被训练成只代表一个图像。.给定图像
x
\bf{x}
x和坐标网格
p
\bf{p}
p,最小化目标函数:
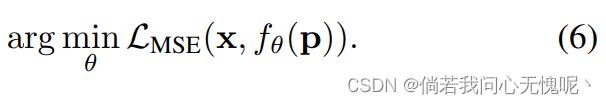
我们用均方误差(MSE)作为损失函数来衡量地面真实目标与INR输出的相似性:
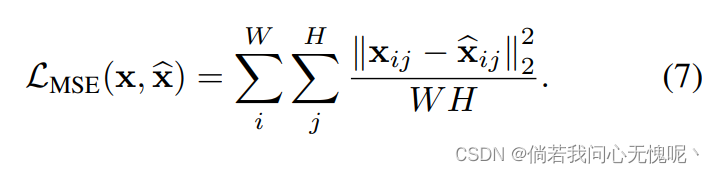
正则化: 在图像压缩中,我们的目标是同时最小化失真(如MSE)和比特率。由于模型熵不可微,我们不能直接将其用于基于梯度的优化。在文献中使用的一种选择是在训练[2]时使用可微熵估计器。然而,我们选择使用正则化项,它可以近似地诱导较低的熵值。特别地,我们将L1正则化应用于模型权重。总的来说,这产生了以下优化目标:
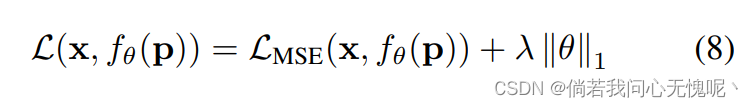 λ
\lambda
λ决定L1正则化的重要性。L1损耗具有诱导稀疏性的特性。因此,我们的正则化项与[53]的稀疏性损失有关: 我们有相同的目标,限制权重的熵,然而我们将此应用于INR,而他们将其应用于传统的显式解码器。
λ
\lambda
λ决定L1正则化的重要性。L1损耗具有诱导稀疏性的特性。因此,我们的正则化项与[53]的稀疏性损失有关: 我们有相同的目标,限制权重的熵,然而我们将此应用于INR,而他们将其应用于传统的显式解码器。 (可以看一些显式的图像压缩论文,有些技术应该是有可替换性的)
Stage 2: 量化 通常,由过拟合产生的模型权值是单精度浮点数,每个权值需要32位。为了减少内存需求,我们使用AI量化权重模型高效工具箱(AIMET)。我们对每个权重张量采用特定的量化,使等间距量化网格调整到张量的值范围内。位宽决定了离散级别的数量,即量化步长。我们经验地发现,位宽在7-8的范围内导致我们的模型的最佳率失真性能,如补充说明所示。
Stage 3: 后量化优化 量化通过将权重四舍五入到最接近的量化位会降低模型的性能。我们利用两种方法来减轻这种影响。首先,我们使用AdaRound[39],这是一种二阶优化方法来决定是否向上调整权重还是向下调整权重。其核心思想是,传统的最近邻舍入并不总是最佳选择,如[39]所示。随后,我们使用量化感知训练(QAT)微调量化的权重。这一步的目的是扭转部分量化误差。量化是不可微的,因此我们依靠于用于梯度计算的直通估计器(STE)[8],其本质上绕过了反向传播期间的量化操作。 (这一段没有看懂,什么叫绕过了反向传播期间的量化操作)
Stage 4: 熵编码 最后,我们采用熵编码进一步无损压缩权值。特别地,我们使用一种二值化算术编码算法对量化的权值进行无损压缩。
3.3.2 Meta-learned Initialization for Compressing INRs
直接将INRs应用于压缩有两个严重的限制:首先,在编码过程中需要将模型从无到有过拟合到数据样本。其次,它不允许在压缩算法中嵌入归纳偏差(例如,特定图像分布的知识)。为此,我们采用了元学习,即模型无关元学习(MAML) [20],为了学习一个接近权值的权值初始化,并包含图像分布的信息。以前关于INRs元学习的工作主要是为了提高收敛速度[48]。认为所学的初始化
θ
0
\theta_0
θ0在权重空间上更接近最终INR。我们希望在更新
Δ
θ
=
θ
−
θ
0
\Delta \theta = \theta -\theta_0
Δθ=θ−θ0比全部权重张量
θ
\theta
θ需要更少的存储的假设下利用这一事实进行压缩。因此,我们固定
θ
0
\theta_0
θ0,并在解码器中包含它,以便它足以传输
Δ
θ
\Delta \theta
Δθ,或者,准确地说是量化的更新
Δ
θ
~
\Delta \tilde{\theta}
Δθ~。然后解码器可以通过计算来重建图像:
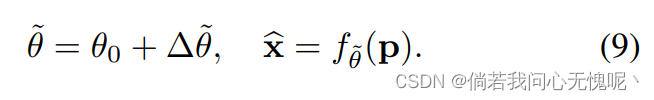
我们期望权值更新
Δ
θ
\Delta \theta
Δθ所占的值区间显著小于全部权重
θ
\theta
θ。因此,在量化权重更新时,最低量化位和最高量化位之间的范围可以更小。 如果我们在固定的位宽下进行比较,在量化权值更新时,量化位之间的步长会更低,因此,平均舍入误差也会更小。注意,在对单个图像过拟合之前,初始化的学习只在每个分布
D
D
D中执行一次。因此,我们将其引入阶段0。阶段0发生在训练时,在许多图像上执行,不是推理的一部分。 阶段1-4发生在推断时间,目的是压缩单个图像。因此,使用元学习获得的初始化不会增加推断时间。 (这一部分其实还挺好的,跟我之前的一个想法是类似的,不过我代码写不出来TAT)
集成到压缩流程中: 当我们只对更新
θ
\theta
θ进行编码时,我们需要相应地调整压缩管道。在过拟合过程中,我们将目标改为:
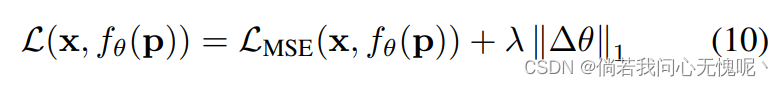
然而,现在正则化项诱导模型权重保持接近初始化。同时,我们直接对更新∆θ进行量化。为了执行
AdaRound和QAT,我们对MLP中的所有线性层进行分解,从更新中分离初始值:
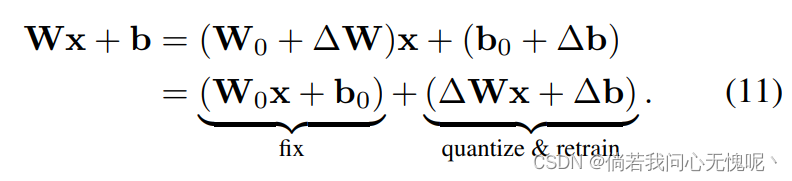
这是必要的,因为优化四舍五入和QAT需要每个线性层的原始输入输出函数。将其分为两个平行的线性层,我们可以固定包含
W
0
\bf{W}_0
W0和
b
0
\bf{b}_0
b0的线性层,并进行量化、AdaRound和QAT用于更新参数
Δ
W
\Delta \bf{W}
ΔW和
Δ
b
\Delta \bf{b}
Δb。
4. Experiments
数据集: Kodak数据集包含24张图片,其中有不同的人物、目标和风景。图像的分辨率为 768 × 512 768 \times 512 768×512(垂直和水平)。DIV2K数据集包含1000幅宽度≈2000像素的高分辨率图像。数据集分为800张训练图像、100张验证图像和100张测试图像。为了元学习初始化的目的,我们将DIV2K图像的大小调整为与Kodak ( 768 × 512 768 × 512 768×512)相同的分辨率。CelebA[31]是一个包含的数据集20万张名人照片,分辨率为 178 × 218 178×218 178×218。我们在测试集中随机抽取的100幅图像上评估我们的方法。
指标: 我们评估了两个指标来从速率和失真的角度分析性能。我们用存储表示所需的总比特数除以图像像素数W·H来衡量速率:
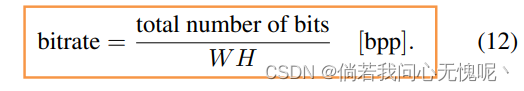
我们用MSE测量失真,并将其转换为峰值信噪比(PSNR),公式为:
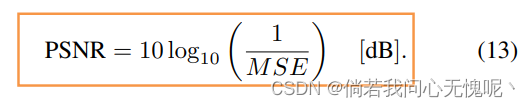
基线: 我们将我们的方法与传统的编解码器、基于INR的压缩和基于RDAE的学习方法进行了比较。
- 传统编解码: JPEG、JPEG2000、BPG
- 基于INR的方法:Dupont et al. (COIN)
- 记忆RDAE的方法:Balle et al.,Xie et al.
优化和超参数: 除非另有说明,我们在整个实验部分都使用默认的超参数集。特别地,我们使用具有3个隐藏层和正弦激活的INRs,并结合使用σ = 1.4的位置编码。在高分辨率的Kodak数据集上,我们将频率数设置为L = 16,而在CelebA上,我们将L = 12。我们改变每层M的隐藏单元的数量,即MLP的宽度,以评估在不同的率失真工作点的性能。对于CelebA图像,我们选择
M
∈
{
24
,
32
,
48
,
64
}
M∈\{24,32,48,64\}
M∈{24,32,48,64},对于Kodak图像,我们选择
M
∈
{
32
,
48
,
64
,
128
}
M∈\{32,48,64,128\}
M∈{32,48,64,128}。正则化参数默认为
λ
=
1
0
−
5
\lambda = 10^{-5}
λ=10−5。我们将随机初始化的方法称为基本(basic)方法,而包含元学习初始化的方法称为元学习初始化(meta-learned)方法。我们发现元学习方法的最佳位宽为b = 7,基本方法的最佳位宽为b = 8。我们通过执行网格搜索并选择一个在不同比特率下工作得最好的值来确定超参数。我们在PyTorch[43]中实现了我们的方法,并在过拟合和QAT期间使用Adam[29]对INRs进行训练。我们采用混合精确训练来降低记忆要求,提高训练速度。一般来说,所示结果是使用AdaRound和QAT组合得到的。我们参考补充资料了解更多的培训细节。由于我们改变了实验之间的轴缩放,我们在所有绘图中包括JPEG和JPEG2000基线以提供参考。
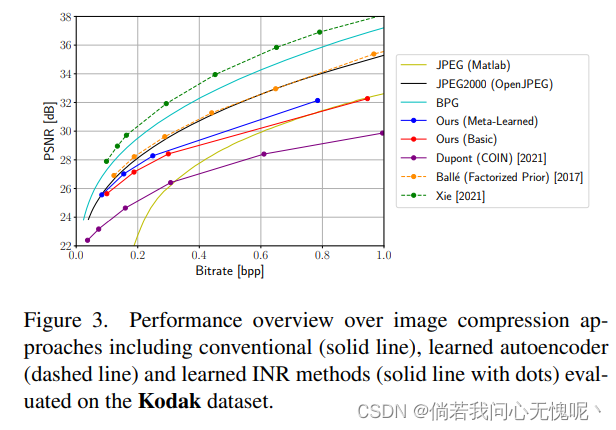
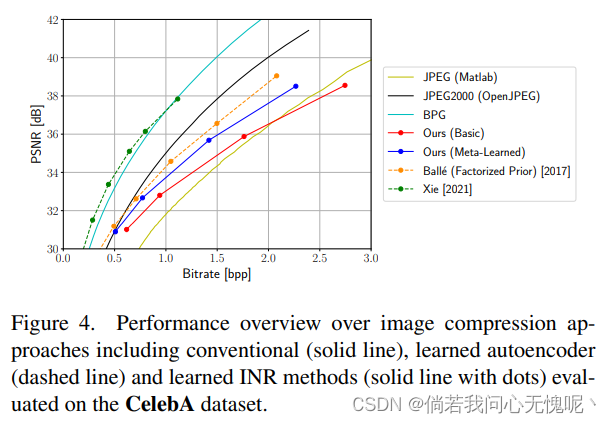
4.1 Comparison with State-of-the-Art
在本节中,我们使用默认超参数进行训练,从而获得基本方法和元学习方法的最佳性能模型。图3和图4分别描绘了我们在Kodak/CelebA上的结果。提出的基本方法已经可以在整个比特率范围内明显优于COIN。在大多数比特率方面,它也比JPEG更好,除了CelebA上的最高设置。 通过我们提出的元学习方法,我们在所有比特率下都优于基本方法。在两个数据集之间,CelebA数据集上的差异明显更大。在最低比特率的情况下,元学习方法达到了JPEG2000的性能,然而我们的方法不能跟上更高比特率的JPEG2000。在CelebA数据集上,元学习方法在较低的比特率下也几乎达到了具有分解先验[6]的自动编码器的性能。对于更高的比特率,自动编码器的优势越来越明显。BPG以及最先进的RDAE[55]在两个数据集上都明显优于我们的方法。
4.2 Visual Comparison to JPEG and JPEG2000
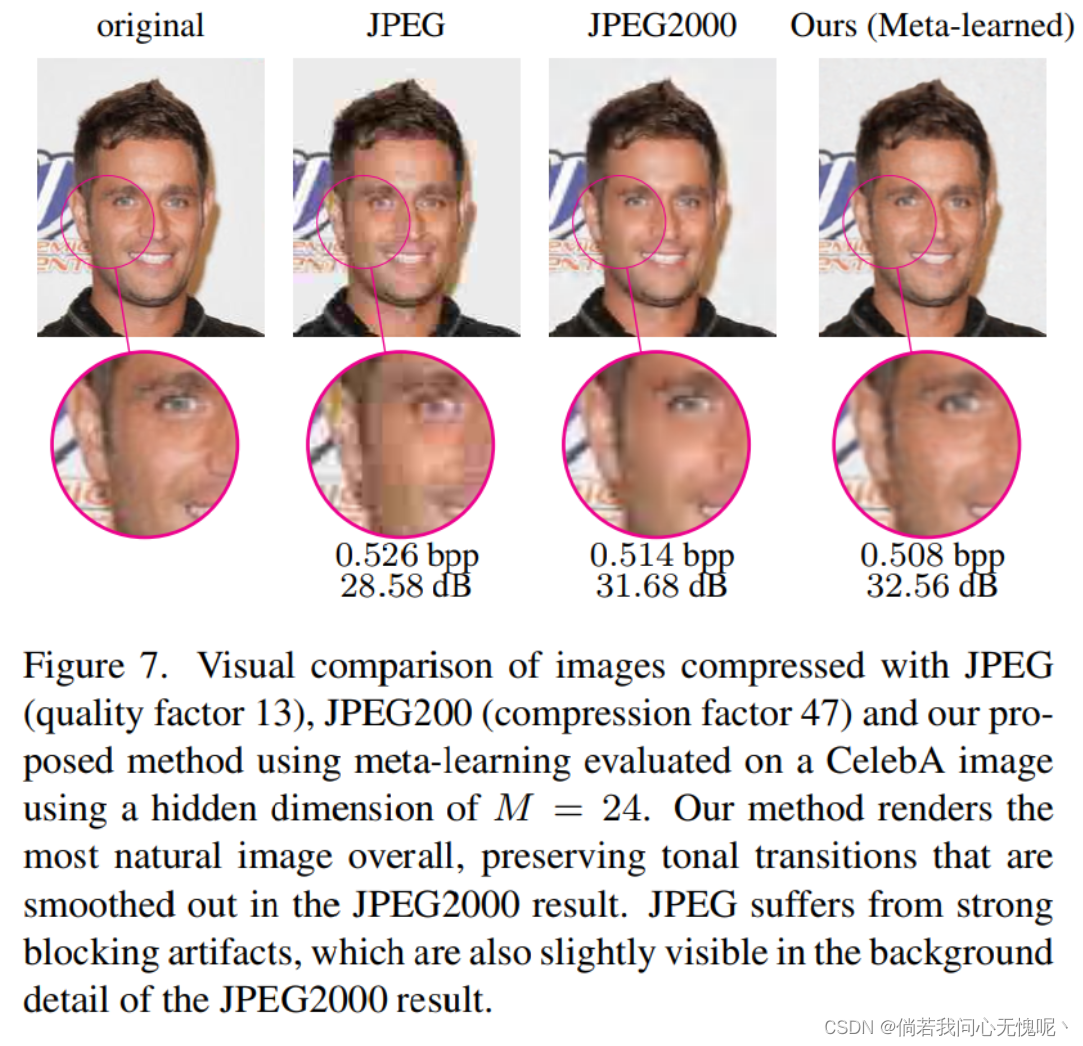
我们将元学习方法的压缩图像与图6(柯达)和图7 (CelebA)中的解码器JPEG和JPEG2000进行比较。我们在视觉上确认了我们的模型比JPEG有了显著的改进:我们的模型产生了一个整体上更令人满意的图像,具有更好的细节和更少的伪影,尽管我们在两个图像上都以较低的比特率操作。对于图6中的柯达图像,与JPEG2000相比,在相同失真的情况下,我们实现了略低的比特率。从视觉上看,JPEG2000图像在边缘和高频细节区域显示了更多的伪影。然而,天空在JPEG2000图像上呈现得更好,因为我们的模型引入了周期性伪影。对于图7中的CelebA图像,我们的方法实现了较低的比特率和较高的PSNR,相比JPEG2000图像。如JPEG2000再次显示边缘周围的伪影(例如背景中的字母周围),并平滑脸部从浅色到深色区域的过渡。我们的方法产生了一个更自然的色调过渡。

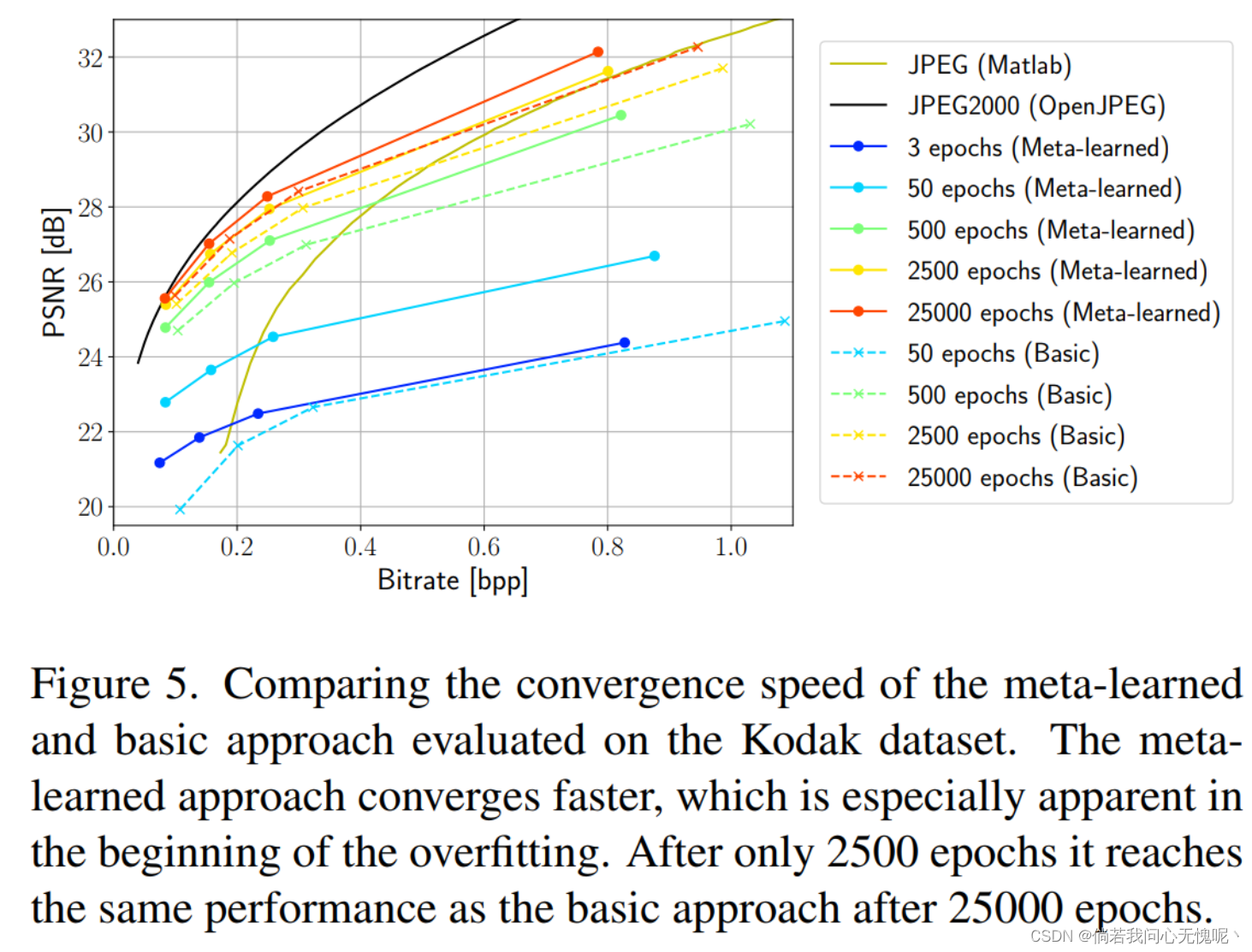
4.3 Convergence Speed
在图5中,我们展示了基本学习方法和元学习方法在不同时期的比较。特别是在过拟合的开始阶段,元学习方法的收敛速度明显加快。在前3个阶段之后,我们获得了比基本方法在50个阶段之后获得的更好的性能。当我们接近各自模型的最终性能时,收敛速度会减慢,而元学习方法仍然保持优势:它在2500个epoch后的性能与25000个epoch后的基本方法相同,这相当于减少了90%的训练时间。
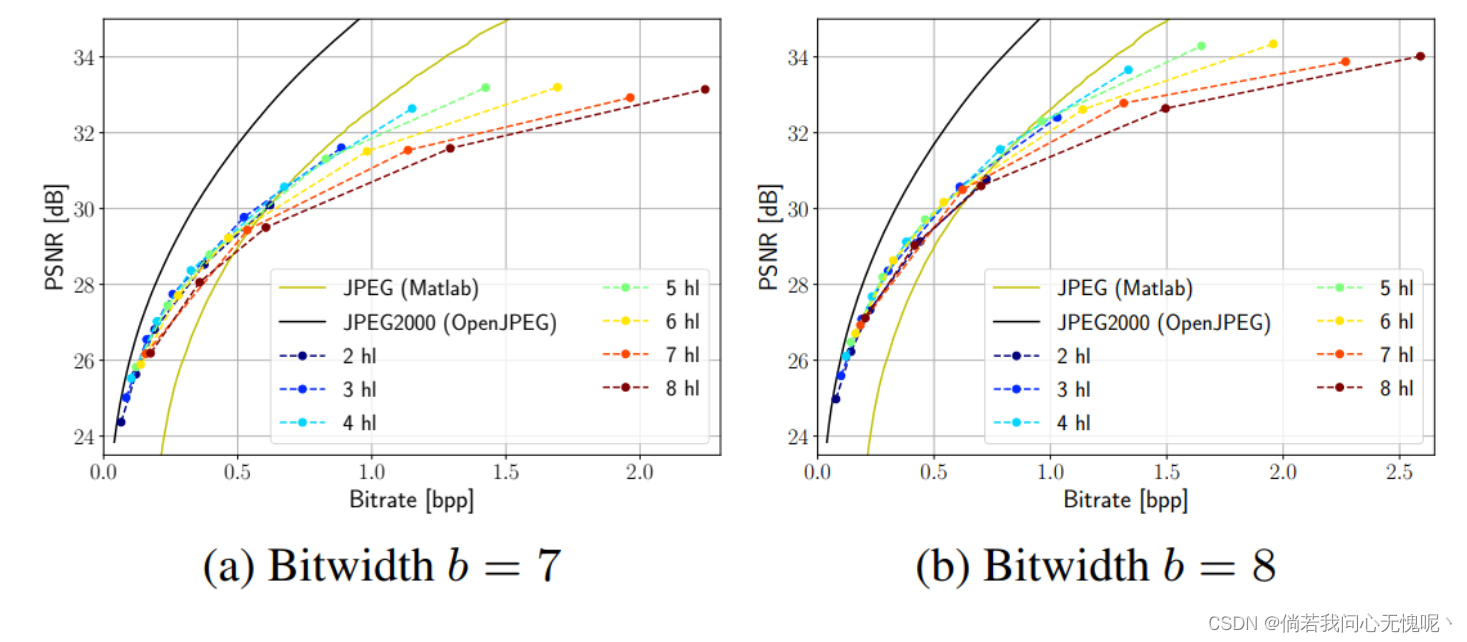
4.4 Number of Layers and Hidden Dimension
当使用基于MLP的网络时,架构选择是很重要的,特别是隐藏层的数量和隐藏单元的数量。对于给定的MLP,深度或宽度会直接影响参数的数量,并间接影响比特率。换句话说,有两种扩大网络的方法。我们研究了各种隐藏单元
(
M
∈
{
32
,
48
,
64
,
96
,
128
}
)
(M \in \{32,48,64,96,128\})
(M∈{32,48,64,96,128})和隐藏层
(
{
2
,
⋯
,
8
}
)
(\{2,\cdots,8\})
({2,⋯,8})组合的率失真性能,使用基础方法和
λ
=
1
0
−
6
\lambda= 10 ^{-6}
λ=10−6,结果展示在8中。我们可以从两个图中看到,增加层数最终会导致收益递减:在PSNR增益很小的情况下,比特率不断增加。在较低的位宽b = 7处,隐藏层数量越多,平坦就越明显。这里的量化噪声更强,随着深度的增加,噪声可能被放大并限制性能。我们得出结论,对于模型的宽度,速率失真性能的伸缩更加优雅。
4.5 Choosing Input Encoding and Activation
一个重要的体系结构选择是输入编码和使用的激活函数的组合。我们与[49]中提出的高斯编码进行了比较。对于这种编码,我们使用与[49]中相同的频率数作为隐藏维度(L = M)和标准差σ = 4。我们训练不同隐藏维度的模型
(
M
∈
{
32
,
48
,
64
,
96
,
128
}
)
(M \in \{32, 48, 64, 96, 128\})
(M∈{32,48,64,96,128})和不同的输入编码在柯达数据集上使用正则化参数
λ
=
1
0
−
6
\lambda = 10^{-6}
λ=10−6从随机初始化开始。
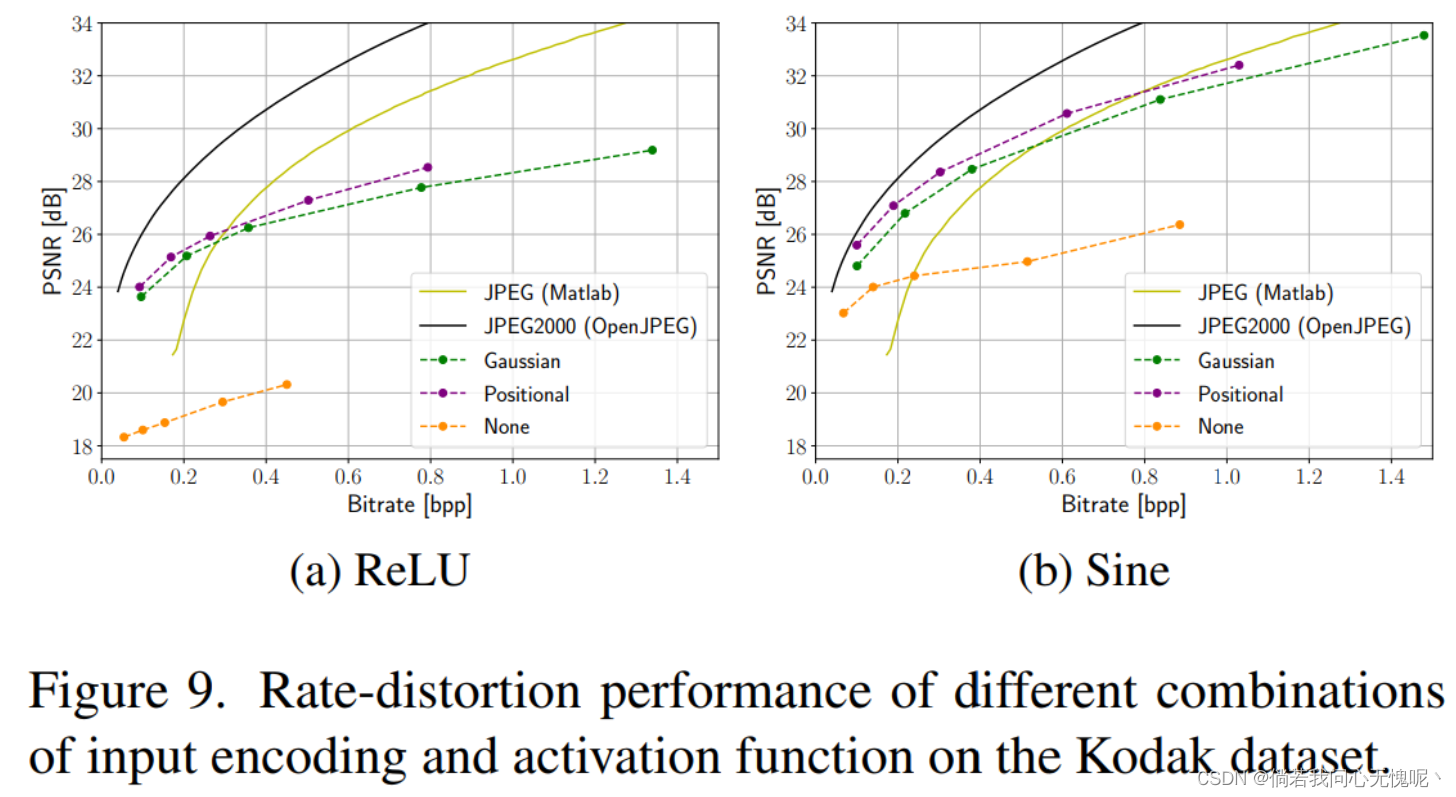
对比图9a和图9b,我们可以看到正弦激活在每个配置中都优于ReLU激活,特别是在更高的比特率下。对于两个激活,最佳的整体输入编码是位置编码,而不是高斯编码。没有输入编码和正弦激活的MLP, SIREN架构,性能明显优于其对应的ReLU,但仍然不能达到有输入编码的模型的性能。
4.6 Impact of L 1 L_1 L1 Regularization
在这个实验中,我们试图验证 L − 1 L-1 L−1正则化是否对性能有有益的影响。我们从其他默认参数和随机初始化开始训练,将 λ \lambda λ在 [ 0 , 1 0 − 4 ] [0, 10^{-4}] [0,10−4]内。
我们观察到,对于这两个数据集, λ = 1 0 − 5 \lambda = 10 ^{-5} λ=10−5的值在较高的比特率下比 λ \lambda λ的较低选择有更好的性能。性能的改善表现为比特率的降低,这支持L1正则化可以导致熵的降低的主张。随着正则化强度的增加, λ = 1 0 − 4 λ = 10^{−4} λ=10−4对权重的限制过大,导致其性能不如 λ = 1 0 − 5 λ = 10^{−5} λ=10−5。因此,L1正则化可以帮助降低熵,但需要结合修改架构大小,以实现良好的率失真折衷。
4.7 Post-Quantization Optimization
我们将我们的元学习方法用于不同的量化后优化设置。图11显示了在柯达上评估的性能差异。我们可以看到,AdaRound和应用于自身的再培训得到了持续的提升。然而,在比特率范围内的最佳选择是将这些方法结合使用。(这几个方法都有用,结合起来效果更好,虽然我觉得提升也不大)

5. Conclusion
总的来说,INRs显示了被用作图像压缩表示的潜力。我们在速率失真性能方面取得了很大的改善,比以前INR的方法[17]进行图像压缩。性能的提高可以特别归因于对INR架构的仔细去除和元学习初始化的引入。此外,我们的方法是第一个允许INRs在很大一部分比特率上与传统编解码器竞争的方法。
我们强调,我们提出的元学习方法比随机初始化的基本方法有显著优势。具体来说,我们观察到在相同的重构质量下比特率的降低。因此,我们可以使用较低的量化位宽,同时保持相似的PSNR。这支持了权值更新比完整模型权值更可压缩的假设。特别是,在CelebA数据集上性能提高更为显著,其中初始化是在更类似于测试集的图像分布上训练的。此外,名人面孔的分布比自然场景的分布变化更少,这可能会简化单一强初始化的学习。因此,我们可以通过在初始化中加入先验知识,使我们的压缩算法适应于特定的分布。
此外,在基于INR的压缩中引入元学习初始化是长时间编码的一个潜在解决方案:我们展示了我们的元学习方法可以减少高达90%的训练时间,同时达到与基本方法相同的性能。我们还强调了基于inr的压缩的架构和输入编码的重要性(见图9)。这表明了选择正确的归纳偏差进行压缩的重要性,是另一个有前途的未来研究途径。
未来工作需要解决的一个明确的限制是将INRs扩展到更高的比特率。虽然我们观察到对隐藏维进行缩放可以改善比例失真性能的缩放特性(见图8),相比于现有的方法,基于inr的方法(我们的和COIN[17])在较高的比特率下表现出较低的竞争力。因此,在MLP之外为INRs开发新的架构是至关重要的,以减轻当前高比特率的缺陷。
而现在基于INR的压缩——例如我们的和COIN用于图像压缩,NeRV用于视频压缩——并不优于基于RDAE的方法,可以说它仍处于起步阶段。然而,我们已经表明,一个精心构造的压缩管道将基于INR的方法提升到一些传统算法范围的性能和元学习消除长编码时间的潜力。
6. Supplementary Material
补充材料有空再写,该回去休息了















 194
194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









