







环境:
fedora37,kernel:6.0.7-301.fc37.x86_64,cilium 版本 v1.13.0
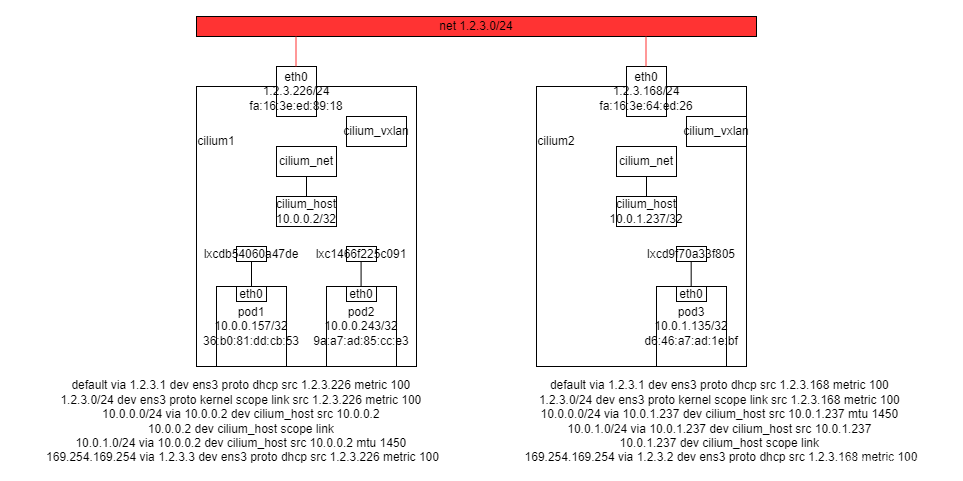
传统的基于二层转发或三层路由的方式,数据包转发的路径是比较清晰,可以利用一些抓包工具直观的分析报文的走向,但在基于 ebpf 的 cilium 场景下,用传统的分析工具就没那么清晰了。
下面通过 ebpf 代码和对应接口的挂载点就行数据包的分析。
先进到 pod1 里查看 netns 网络环境
# ip r
default via 10.0.0.2 dev eth0 mtu 1450
10.0.0.2 dev eth0 scope link
# ip neighbor
10.0.0.2 dev eth0 lladdr 5a:e7:3b:d0:b8:c5 STALE
10.0.0.2 是本节点 cidr 的网关地址,配置在 cilium_host 上,看到下一跳地址的 mac 是 66:52:92:66:66:01,但在主机上看 mac 是 3a:65:ff:db:e0:28,而 66:52:92:66:66:01 是 veth host 端的 mac 地址,这是因为开启了 arp_proxy,像 calico 也是这样做的。
4: cilium_host@cilium_net: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 3a:65:ff:db:e0:28 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.2/32 scope global cilium_host
Pod 间
同节点 pod
pod1 <–> pod2 10.0.0.157 ping 10.0.0.243
原始报文:
36:b0:81:dd:cb:53 > 5a:e7:3b:d0:b8:c5
10.0.0.157 > 10.0.0.243
查看网卡情况
# tc filter show dev lxcdb54060a47de ingress
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 cilium-lxcdb54060a47de direct-action not_in_hw id 1703 name cil_from_contai tag 7bd3467ce6274e22 jited
# tc filter show dev lxc1466f225c091 ingress
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 cilium-lxc1466f225c091 direct-action not_in_hw id 1717 name cil_from_contai tag a6c2cf4a8cf17a1c jited
在 veth 的 host 端 tc ingress 挂载 ebpf 程序,section(from_contianer),当 veth 收到 ns 端发来的包会由该 section 处理。
函数流程
|-cil_from_container
|-tail_handle_ipv4
|-__tail_handle_ipv4
|-->invoke_tailcall_if
...// svc 的查询等。
|-tail_handle_ipv4_cont // 根据 TAIL_CT_LOOKUP4,上一章节有介绍
|-handle_ipv4_from_lxc
|--> lookup_ip4_remote_endpoint // 根据目的 IP 从 IPCACHE map 找 endpoint
|--> lookup_ip4_endpoint // 根据目的 IP 从 ENDPOINTS_MAP 找 endpoint
|- ipv4_local_delivery
|- redirect_ep
|- ctx_redirect_peer
|- redirect_peer
bpf/bpf_lxc.c L1261
__section("from-container")
int cil_from_container(struct __ctx_buff *ctx)
{
// 判断二层协议号,不能小于 ETH_P_802_3_MIN(0x0600)
if (!validate_ethertype(ctx, &proto)) {
ret = DROP_UNSUPPORTED_L2;
goto out;
}
switch (proto) {
#ifdef ENABLE_IPV4
case bpf_htons(ETH_P_IP):
edt_set_aggregate(ctx, LXC_ID);
// 尾调到 tail_handle_ipv4 函数
ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_LXC);
ret = DROP_MISSED_TAIL_CALL;
break;
}
static __always_inline int handle_ipv4_from_lxc(struct __ctx_buff *ctx, __u32 *dst_id,
__s8 *ext_err)
{
......
info = lookup_ip4_remote_endpoint(ip4->daddr, 0);
// 10.0.0.243/32 identity=14753 encryptkey=0 tunnelendpoint=0.0.0.0 nodeid=0
......
// 10.0.0.243:0 id=505 flags=0x0000 ifindex=21 mac=9A:A7:AD:85:CC:E3 nodemac=E6:5B:CE:77:AA:3D
ep = lookup_ip4_endpoint(ip4);
if (ep) {
#ifdef ENABLE_ROUTING
if (ep->flags & ENDPOINT_F_HOST) {
#ifdef HOST_IFINDEX
goto to_host;
#else
return DROP_HOST_UNREACHABLE;
#endif
}
#endif /* ENABLE_ROUTING */
policy_clear_mark(ctx);
/* If the packet is from L7 LB it is coming from the host */
return ipv4_local_delivery(ctx, ETH_HLEN, SECLABEL, ip4,
ep, METRIC_EGRESS, from_l7lb, hairpin_flow);
}
}
static __always_inline int redirect_ep(struct __ctx_buff *ctx __maybe_unused,
int ifindex __maybe_unused,
bool needs_backlog __maybe_unused)
{
......
// ifindex 为 21
return ctx_redirect_peer(ctx, ifindex, 0);
}
}
redirect_peer(ifindex, flags);
跨节点 pod in vxlan
由于节点重启过,环境内容更新
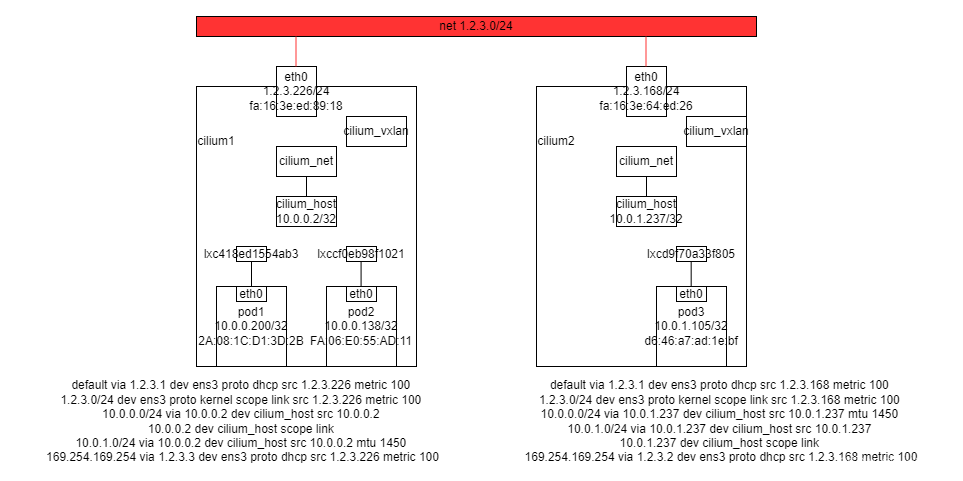
pod1 <–> pod3 10.0.0.200 ping 10.0.1.105
原始报文:
2A:08:1C:D1:3D:2B <–> A2:50:5E:72:41:26
10.0.0.218 > 10.0.1.105
和上面的流程相似,到 endpoint 获取时
Ipcache map
10.0.1.105/32 identity=14753 encryptkey=0 tunnelendpoint=1.2.3.168 nodeid=32012
函数流程
函数流程
|-cil_from_container
|-tail_handle_ipv4
|-__tail_handle_ipv4
|-->invoke_tailcall_if
...// svc 的查询等。
|-tail_handle_ipv4_cont // 根据 TAIL_CT_LOOKUP4,上一章节有介绍
|-handle_ipv4_from_lxc
|--> lookup_ip4_remote_endpoint // 根据目的 IP 从 IPCACHE map 找 endpoint
|--> lookup_ip4_endpoint // 根据目的 IP 从 ENDPOINTS_MAP 找 endpoint,其他 node 的ip,找不到
|-__encap_and_redirect_lxc
|-__encap_and_redirect_with_nodeid
|-__encap_with_nodeid // nodeid 为 ipcache 中查到的对端 endpoint ip
|-ctx_set_encap_info
|-ctx_set_tunnel_key
|- bpf_skb_set_tunnel_key // linux 内核函数 // net/core/filter.c
|--> ctx_redirect
代码流程
重新回到 handle_ipv4_from_lxc 的 lookup_ip4_remote_endpoint
static __always_inline int handle_ipv4_from_lxc(struct __ctx_buff *ctx, __u32 *dst_id,
__s8 *ext_err)
......
if (1) {
struct remote_endpoint_info *info;
info = lookup_ip4_remote_endpoint(ip4->daddr, 0);
// identity=14753 encryptkey=0 tunnelendpoint=1.2.3.168 nodeid=32012
if (info && info->sec_label) {
*dst_id = info->sec_label;
// tunnel_endpoint 1.2.3.168
tunnel_endpoint = info->tunnel_endpoint;
encrypt_key = get_min_encrypt_key(info->key);
} else {
*dst_id = WORLD_ID;
}
......
#ifdef TUNNEL_MODE
{
struct tunnel_key key = {};
key.ip4 = ip4->daddr & IPV4_MASK;
key.family = ENDPOINT_KEY_IPV4;
// 封包转发
ret = encap_and_redirect_lxc(ctx, tunnel_endpoint, encrypt_key,
&key, SECLABEL, *dst_id, &trace);
......
}
转到本节点 vxlan 处理
static __always_inline __maybe_unused int
ctx_set_encap_info(struct __sk_buff *ctx, __u32 node_id, __u32 seclabel,
__u32 dstid __maybe_unused, __u32 vni __maybe_unused,
__u32 *ifindex)
{
struct bpf_tunnel_key key = {};
int ret;
......
key.remote_ipv4 = node_id;
key.tunnel_ttl = IPDEFTTL;
ret = ctx_set_tunnel_key(ctx, &key, sizeof(key), BPF_F_ZERO_CSUM_TX);
// 转到本节点 vxlan 的 iface
*ifindex = ENCAP_IFINDEX;
return CTX_ACT_REDIRECT;
}
查看 cilium_vxlan
# tc filter show dev cilium_vxlan egress
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 bpf_overlay.o:[from-overlay] direct-action not_in_hw id 1509 name cil_from_overla tag 10c7559775622132 jited
# ip -d link show cilium_vxlan
5: cilium_vxlan: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 82:89:58:47:c7:bd brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 68 maxmtu 65535
vxlan external id 0 srcport 0 0 dstport 8472 nolearning ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 gro_max_size 65536
回顾一下 from-container ctx_set_encap_info 发到 cilium_vxlan 之前
ctx_set_encap_info(struct __sk_buff *ctx, __u32 node_id, __u32 seclabel,
__u32 dstid __maybe_unused, __u32 vni __maybe_unused,
__u32 *ifindex)
{
struct bpf_tunnel_key key = {};
int ret;
#ifdef ENABLE_VTEP
if (vni != NOT_VTEP_DST)
key.tunnel_id = vni;
else
#endif /* ENABLE_VTEP */
// tunnel_id 根据 ep_config.h 为 47204,即 vni
key.tunnel_id = seclabel;
// remote_ipv4 是通过查 remote_endpoint 中的 tunnel_ip
key.remote_ipv4 = node_id;
key.tunnel_ttl = IPDEFTTL;
ret = ctx_set_tunnel_key(ctx, &key, sizeof(key), BPF_F_ZERO_CSUM_TX);
if (unlikely(ret < 0))
return DROP_WRITE_ERROR;
*ifindex = ENCAP_IFINDEX;
return CTX_ACT_REDIRECT;
}
根据路由选择外层源 IP,然后利用 linux 内核封包并发出。linux 封包流程有时间再进一步单独学习分享。
Node 网卡未做多余的处理,将封装好的包发送到目标节点
Target 节点上的 cilium_vxlan 的 ingress 是 from-overlay
主要处理函数:
static __always_inline int handle_ipv4(struct __ctx_buff *ctx, __u32 *identity)
...
/* Lookup IPv4 address in list of local endpoints */
ep = lookup_ip4_endpoint(ip4); // 通过目的 ip 获取 endpoint 10.0.1.105:0 id=2910 flags=0x0000 ifindex=39 mac=5E:74:7D:93:A7:92 nodemac=66:A3:FB:74:62:08
if (ep) {
/* Let through packets to the node-ip so they are processed by
* the local ip stack.
*/
if (ep->flags & ENDPOINT_F_HOST)
goto to_host;
return ipv4_local_delivery(ctx, ETH_HLEN, *identity, ip4, ep,
METRIC_INGRESS, false, false);
}
ipv4_local_delivery
|-redirect_ep
|-ctx_redirect_peer
|-redirect_peer // 直接redirect 到 查到的 ifindex 的 peer口
static __always_inline int ipv4_local_delivery(struct __ctx_buff *ctx, int l3_off,
.....
return redirect_ep(ctx, ep->ifindex, from_host);
static __always_inline int redirect_ep(struct __ctx_buff *ctx __maybe_unused,
return ctx_redirect_peer(ctx, ifindex, 0);
static __always_inline __maybe_unused int
ctx_redirect_peer(const struct __sk_buff *ctx __maybe_unused, int ifindex, __u32 flags)
{
return redirect_peer(ifindex, flags);
}
小结
可以看到 报文直接从 cilium_vxlan 上直接redirect 到 ns 内的网卡上;
两端 vni 不同,vni 是 identity 的 ID,所以 vxlan 的 vni 为源 pod ipcache 中 ID,为了安全规则使用。















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









