







字符集
ASCII编码
图片来源:百度百科

问题集
Java自动生成bat的换行和乱码问题
想用java自动创建Windows中的bat批处理文件,但是遇到了换行和中文乱码问题,记录如下
换行问题
不同系统的换行符:
- windows下的文本文件换行符:\r\n (一定是\r在前,\n在后)
- linux/unix下的文本文件换行符:\r
- Mac下的文本文件换行符:\n
各软件识别换行符:
- Java在处理String或者在console输出的时候,无论是\r或是\n都能换行。
- 但是偏偏在txt中,哪个都不是标准的换行,只有合起来的\r\n才是换行(对于整个windows默认的换行来说,都是这样)。
- 意思是\r敲个回车,表明这行结束了,光标回到本行的最前面去,然后再\n下移一行来个新行。
参考自:关于换行符 - tonygao
乱码问题
手动创建编写Bat文件时,将该bat文件以 ANSI 1 编码进行保存,则能正常地在所有文本编辑软件中正常查看,运行时也不会出现中文乱码。但java中无法设置ANSI编码,于是尝试了utf-8和GBK编码,效果如下:
java以不同编码的输出流将中文写入到bat文件中的效果:
| 编码 | Windows记事本打开是否乱码 | notepad++打开是否乱码 | EditPlus打开是否乱码 | 运行该Bat文件是否显示乱码 |
|---|---|---|---|---|
| utf-8 | 否 | 否 | 否 | 乱码 |
| GBK | 否 | 乱码 | 乱码 | 否 |
- 因为最终要运行bat文件,CMD中需要有中文查看运行日志,所以不能使用uft-8。
- 而GBK编码下,记事本软件不乱码,能正常查看中文,notepad++软件更改为以gb2312编码读取文本后,也能正常查看中文。所以决定使用GBK编码。
- notepad++软件更改为以gb2312编码读取文本(仅以gb2312编码读取,不以gb2312编码保存):菜单栏 ⇨ 编码 ⇨ 编码字符集 ⇨ 中文 ⇨ GB2312(simplified)
测试代码如下:
public static void main(String[] args) throws IOException {
File file = new File("D:/test.bat");
//创建输出流
OutputStreamWriter ows = null;
try {
ows = new OutputStreamWriter(new FileOutputStream(file),"utf-8");//此处更换不同编码进行测试
} catch (UnsupportedEncodingException e) {
System.err.println("编码设置错误,请检查编码名称的拼写及大小写。");
e.printStackTrace();
return ;
} catch (FileNotFoundException e) {
e.printStackTrace();
return ;
}
//写入到文件
try {
ows.write("@echo 测试CMD中能否正常显示中文。");//cmd中“@echo”用于回显打印字符
ows.write("\r\n");//windows下的文本软件使用“\r\n”来表示换行
ows.write("@echo This is the second line.");
} catch (IOException e) {
e.printStackTrace();
return false;
}
//清空输出流缓存 及 关闭输出流
try {
ows.flush();
ows.close();
} catch (IOException e) {
return;
}
}
Java读取及处理注册表文件的异常问题
最近用Java读取Windows注册表的导出备份文件出现了问题,最终发现了原因。
问题原因
- 首先介绍下0号字符:0号字符是ASCII编码中的第一个字符,而ASCII编码的前32个字符都是不可见字符。ASCII编码一共只有128个字符,UTF-8编码兼容ASCII编码,也就是说UTF-8编码的前128个字符就是ASCII编码,并且顺序也一致。
另外“不可见字符”的含义是:在诸如记事本、Editplus软件中是不显示的,并且也不会有一个空位来表示这里有个不可见字符,用这些软件打开导出文件时看起来是很正常的! - 然后Java中使用 FileReader 对象按行读取数据时的行结束标识符有三个:
组合在一起的“\r\n”、单独存在的“\r”、单独存在的“\n”。并且FileReader字符流对象的底层仍是读字节,再将字节转为字符,所以Java是能读到0号字符的,再用输出流输出时会以某种符号表示0号字符; - 其次发现注册表的导出文件是UTF-8格式,并且每个内容字节的后面都有一个0号字符,包括原本的换行符也有0号字符。而0号字符是不可见字符,这里以符号
♦表示:原本的\r\n变成了\r♦\n♦。而这也就导致了后续的字符串处理问题。 - 最后,上述原因共同导致了一个问题。用记事本打开文件看到的内容是这样的:
此时以为这个文件的编码是ABC DEFABC\r\nDEF,而实际上文件的编码是A♦B♦C♦\r♦\n♦D♦E♦F♦,可以看到\r\n被分开了,于是FileReader对象读取并输出的结果如下:A♦B♦C♦ ♦ ♦ D♦E♦F♦
截图举例
实际输出的部分截图,如下:
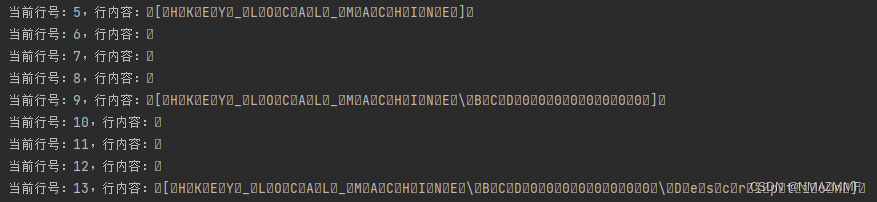
而在记事本中看到是是这样的:
[HKEY_LOCAL_MACHINE]
[HKEY_LOCAL_MACHINE\BCD00000000]
[HKEY_LOCAL_MACHINE\BCD00000000\Description]














 2226
2226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









