







Master源码分析之主备切换机制
1.当选为leader之后的操作
//ElectedLeader 当选leader
case ElectedLeader => {
//从持久化引擎中获取数据,driver,worker,app 的信息
val (storedApps, storedDrivers, storedWorkers) = persistenceEngine.readPersistedData(rpcEnv)
state = if (storedApps.isEmpty && storedDrivers.isEmpty && storedWorkers.isEmpty) {
//如果APP、driver、worker是空的,recoverystate设置为alive
RecoveryState.ALIVE
} else {
//有一个不为空则设置为recovering
RecoveryState.RECOVERING
}
logInfo("I have been elected leader! New state: " + state)
if (state == RecoveryState.RECOVERING) {
//判断状态如果为recovering 恢复中,将storedApps,storedDrier,storeWorkers重新注册到master内部缓存结构中
beginRecovery(storedApps, storedDrivers, storedWorkers)
recoveryCompletionTask = forwardMessageThread.schedule(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
//调用自己的CompleteRecovery()方法
self.send(CompleteRecovery)
}
}, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS)
}
}2.调用beginRecovery()方法
//开始恢复
private def beginRecovery(storedApps: Seq[ApplicationInfo], storedDrivers: Seq[DriverInfo],
storedWorkers: Seq[WorkerInfo]) {
for (app <- storedApps) {
logInfo("Trying to recover app: " + app.id)
try {
//重新注册application
registerApplication(app)
//将application状态设置为unknown
app.state = ApplicationState.UNKNOWN
//向work中的driver发送masterChanged消息
app.driver.send(MasterChanged(self, masterWebUiUrl))
} catch {
case e: Exception => logInfo("App " + app.id + " had exception on reconnect")
}
}
//将storedDrivers重新加入内存缓存中
for (driver <- storedDrivers) {
// Here we just read in the list of drivers. Any drivers associated with now-lost workers
// will be re-launched when we detect that the worker is missing.
drivers += driver
}
//将storedWorkers重新加入内存缓存中
for (worker <- storedWorkers) {
logInfo("Trying to recover worker: " + worker.id)
try {
//重新注册worker
registerWorker(worker)
//将worker状态修改为unknown
worker.state = WorkerState.UNKNOWN
//向work发用masterChanged
worker.endpoint.send(MasterChanged(self, masterWebUiUrl))
} catch {
case e: Exception => logInfo("Worker " + worker.id + " had exception on reconnect")
}
}
}3.调用registerApplication()方法,重新注册APP
/**
* 注册application
* @param app
*/
private def registerApplication(app: ApplicationInfo): Unit = {
val appAddress = app.driver.address
if (addressToApp.contains(appAddress)) {
logInfo("Attempted to re-register application at same address: " + appAddress)
return
}
//spark测量系统通注册appsource
applicationMetricsSystem.registerSource(app.appSource)
//将APP加入内存缓存中
apps += app
idToApp(app.id) = app
endpointToApp(app.driver) = app
addressToApp(appAddress) = app
//等待调度的队列,FIFO的算法
waitingApps += app
}4.重新注册worker
private def registerWorker(worker: WorkerInfo): Boolean = {
// There may be one or more refs to dead workers on this same node (w/ different ID's),
// remove them.
//在同一个节点上可能有一个或多个死掉的worker(不同ID),删除它们。
workers.filter { w =>
(w.host == worker.host && w.port == worker.port) && (w.state == WorkerState.DEAD)
}.foreach { w =>
workers -= w
}
val workerAddress = worker.endpoint.address
if (addressToWorker.contains(workerAddress)) {
val oldWorker = addressToWorker(workerAddress)
if (oldWorker.state == WorkerState.UNKNOWN) {
// A worker registering from UNKNOWN implies that the worker was restarted during recovery.
// The old worker must thus be dead, so we will remove it and accept the new worker.
//从UNKNOWN注册的worker意味着worker在恢复期间重新启动。
//因此,老worker必须死亡,所以我们会把它删除并接受新的worker。
removeWorker(oldWorker)
} else {
logInfo("Attempted to re-register worker at same address: " + workerAddress)
return false
}
}
//保存workerInfo到wokers(hashmap)中
workers += worker
//保存worker的id到idToWorker(hashmap)中
idToWorker(worker.id) = worker
//将work端点的地址保存起来
addressToWorker(workerAddress) = worker
true
}5.删除旧的worker 调用removeworker()方法
private def removeWorker(worker: WorkerInfo) {
logInfo("Removing worker " + worker.id + " on " + worker.host + ":" + worker.port)
//将work状态修改为dead
worker.setState(WorkerState.DEAD)
//从idToWorker(hashmap)中去掉workid,
idToWorker -= worker.id
//从addressToWorker(hashmap)中去掉worker.endpoint.address
addressToWorker -= worker.endpoint.address
for (exec <- worker.executors.values) {
logInfo("Telling app of lost executor: " + exec.id)
//向driver中发送executor状态改变
exec.application.driver.send(ExecutorUpdated(
exec.id, ExecutorState.LOST, Some("worker lost"), None))
//从application中删除掉这些executor
exec.application.removeExecutor(exec)
}
for (driver <- worker.drivers.values) {
if (driver.desc.supervise) {
logInfo(s"Re-launching ${driver.id}")
//重新启动
relaunchDriver(driver)
} else {
logInfo(s"Not re-launching ${driver.id} because it was not supervised")
//删除driver
removeDriver(driver.id, DriverState.ERROR, None)
}
}
//持久化引擎删除worker
persistenceEngine.removeWorker(worker)
}6.调用completeRecovery()方法
recoveryCompletionTask = forwardMessageThread.schedule(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
//调用自己的CompleteRecovery()方法
self.send(CompleteRecovery)
}
}, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS)7.以下是completeRecovery()的具体实现
/**
*completeRecovery 完成恢复 主备恢复机制
*/
private def completeRecovery() {
// Ensure "only-once" recovery semantics using a short synchronization period.
//使用短的同步时间确保“只有一次”恢复语义。
//清理机制:1.从内存缓存结构中移除。2.从相关的组件的内存中移除。3.从持久化存储中移除
if (state != RecoveryState.RECOVERING) { return }
//将状态修改为正在恢复
state = RecoveryState.COMPLETING_RECOVERY
// Kill off any workers and apps that didn't respond to us.
// 过滤出来任何对我们没有回应的worker和Apps,根据workstate和applicationstate判断是否为unknown
//然后分别执行removerWorker和finishApplication,来删除worker和application
//删除worker
workers.filter(_.state == WorkerState.UNKNOWN).foreach(removeWorker)
//删除application
apps.filter(_.state == ApplicationState.UNKNOWN).foreach(finishApplication)
// Reschedule drivers which were not claimed by any workers
//重新调度 那些没有回应worker的 drivers
drivers.filter(_.worker.isEmpty).foreach { d =>
logWarning(s"Driver ${d.id} was not found after master recovery")
if (d.desc.supervise) {
logWarning(s"Re-launching ${d.id}")
//重新启动driver
relaunchDriver(d)
} else {
//删除driver
removeDriver(d.id, DriverState.ERROR, None)
logWarning(s"Did not re-launch ${d.id} because it was not supervised")
}
}
//将state转为alive,代表恢复完成
state = RecoveryState.ALIVE
//重新调用schedule()恢复完成
schedule()
logInfo("Recovery complete - resuming operations!")
}
8.调用removWorker()方法,具体实现看第5条
9.master的finishApplication()方法调用了自己的removeApplication(app, ApplicationState.FINISHED)方法
//删除application
def removeApplication(app: ApplicationInfo, state: ApplicationState.Value) {
if (apps.contains(app)) {
logInfo("Removing app " + app.id)
//从application队列(hashset)中删除当前application
apps -= app
idToApp -= app.id
endpointToApp -= app.driver
addressToApp -= app.driver.address
if (completedApps.size >= RETAINED_APPLICATIONS) {
val toRemove = math.max(RETAINED_APPLICATIONS / 10, 1)
completedApps.take(toRemove).foreach( a => {
Option(appIdToUI.remove(a.id)).foreach { ui => webUi.detachSparkUI(ui) }
applicationMetricsSystem.removeSource(a.appSource)
})
completedApps.trimStart(toRemove)
}
//加入已完成的application队列
completedApps += app // Remember it in our history
//从当前等待运行的application队列中删除当前APP
waitingApps -= app
// If application events are logged, use them to rebuild the UI
asyncRebuildSparkUI(app)
for (exec <- app.executors.values) {
//停止executor
killExecutor(exec)
}
app.markFinished(state)
if (state != ApplicationState.FINISHED) {
//从driver中删除application
app.driver.send(ApplicationRemoved(state.toString))
}
//从持久化引擎中删除application
persistenceEngine.removeApplication(app)
//从新调度任务
schedule()
// Tell all workers that the application has finished, so they can clean up any app state.
//告诉说有的worker,APP已经启动完成了,所以他们可以清空APP state
workers.foreach { w =>
w.endpoint.send(ApplicationFinished(app.id))
}
}
}10。removeApplication()中调用了relaunchDriver()方法
/**
* 重新启动driver
* @param driver
*/
private def relaunchDriver(driver: DriverInfo) {
//将driver的worker设置为None
driver.worker = None
//将driver的状态设置为relaunching(重新调度)
driver.state = DriverState.RELAUNCHING
//将当前的driver重新加入waitingDrivers队列
waitingDrivers += driver
//重新开始任务调度
schedule()
}11.removeDriver()方法
//删除driver
private def removeDriver(
driverId: String,
finalState: DriverState,
exception: Option[Exception]) {
//用Scala高阶函数find()根据driverId,查找到driver
drivers.find(d => d.id == driverId) match {
case Some(driver) =>
logInfo(s"Removing driver: $driverId")
//将driver将内存缓存中删除
drivers -= driver
if (completedDrivers.size >= RETAINED_DRIVERS) {
val toRemove = math.max(RETAINED_DRIVERS / 10, 1)
completedDrivers.trimStart(toRemove)
}
//将driver加入到已经完成的completeDrivers
completedDrivers += driver
//从持久化引擎中删除driver
persistenceEngine.removeDriver(driver)
//设置drier状态设置为完成
driver.state = finalState
driver.exception = exception
//从worker中遍历删除传入的driver
driver.worker.foreach(w => w.removeDriver(driver))
//重新调用schedule
schedule()
case None =>
logWarning(s"Asked to remove unknown driver: $driverId")
}
}
}12.到处处master的主备切换基本上已经完成。
大体流程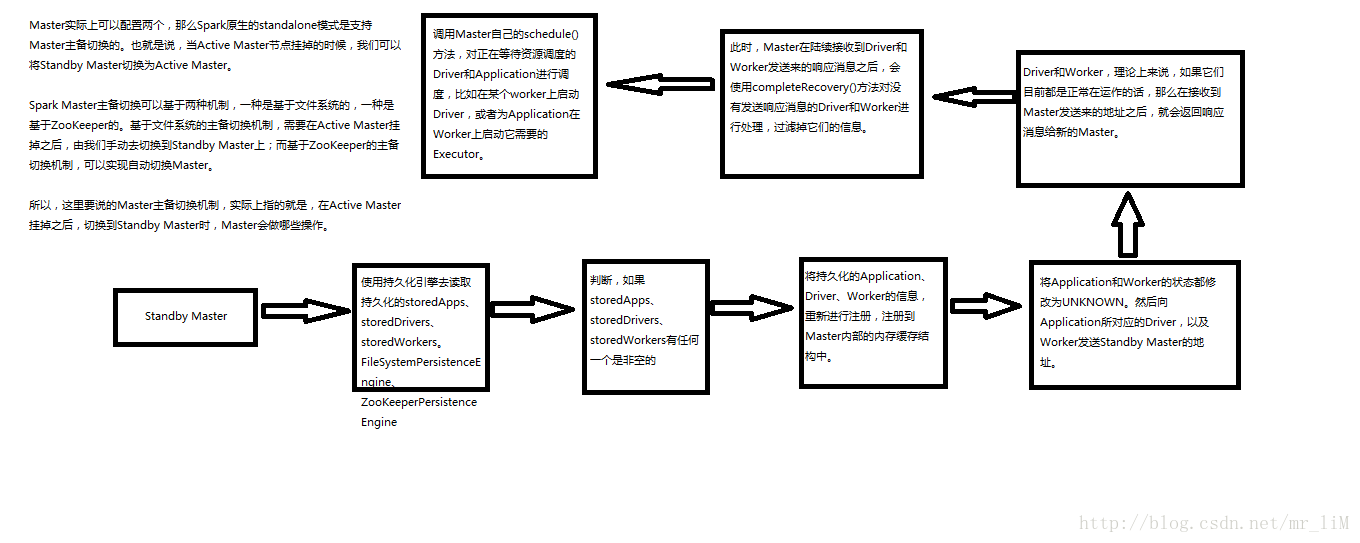
13.如有错误之处还请及时指正,共同学习!!!















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









