







—-
分布式锁:(一般3种实现方式)
1.数据库乐观锁; 2.基于redis的分布式锁。 3.基于zookeeper的分布式锁。
分布式锁 区分于 进程锁, 线程锁。。
进程锁(系统中多个进程之间对资源使用到的管理)
线程锁(进程中多个线程对资源共享)
分布式锁:分布式系统中多个进程之间互相干扰。用分布式协调技术管理进程调度。(这个技术就是分布式锁)
—-
mysql的并发控制(用到了很多策略)
1.锁
锁的粒度: 表级锁, 行级锁, 页级锁 (越来越细) 不同级别锁 保证冲突。
2.多版本控制(MVCC)
保证只读事务 不用等待锁,提高事务并发性。
每行记录后面保存两个列(行创建时间,行过期时间) 事务也有版本号。
共享锁(又叫读锁):读操作可以并发;
排他锁(又叫写锁):写操作互斥。
—-
bin log同步,实现主从复制,
缓存和数据库读写一致性的问题
比较好的方案:缓存双删(写之前删缓存, 写之后删缓存(延时1秒),(保证写的过程中 1秒内的脏数据也被清理掉)
nginx:
nginx原理:
会有一个master进程和多个worker进程,master进程主要用来管理worker进程;
当一个连接过来的时候,每一个worker都能接收到通知,但是只有一个worker能和这个连接建立关系,其他的worker都会连接失败,nginx提供一个共享锁accept_mutex,有了这个共享锁后,就会只有一个worker去接收这个连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接。
事件驱动机制:几个worker进程(每一个worker进程里面其实只有一个主线程)能同时接收上万的请求呢?这是因为nginx事件处理机制是异步非阻塞的。(用了epoll,将过程分为多个阶段。)
nginx的作用:
- 反向代理,将多台服务器代理成一台服务器,
- 负载均衡,将多个请求均匀的分配到多台服务器上,减轻每台服务器的压力,提高服务的吞吐量;
- 动静分离,nginx可以用作静态文件的缓存服务器,提高访问速度
—-
数据处理, 大数据相关
1.离线数据流:日常周期性的(每周执行一次、每日、或者每小时),将某些数据源的数据(全量或增量)迁移到存储引擎上(hbase mysql tendis等)。
2.实时数据流(在线):该数据流一直保持运行状态,实时抽取(pull/push)数据源的数据,毫秒级写入存储引擎。
大数据处理 计算框架。(建立一个流程,数据源、处理、分析和计算,还可以训练模型 等等,输出最终结果。 上面可以跑很多任务)
flink: 支持批处理和流处理。
1.高吞吐、低延迟、高性能。(同时支持,spark那边都不行)
2.支持事件时间概念(event time),基于时间事件时间(event time)语义进行窗口计算,时间产生的时间。即使乱序到达,事件乱序到达,流系统也能计算出精确结果。保证时序性。
3.有状态的计算, 中间结果保存,下一时间段进入算子后可以直接用这个结果。
4.灵活的窗口统计功能(多少次内的统计、多少秒内。)
5.分布式快照(checkpoint)
可以分布式运行在上千节点上,大型计算任务分解成一个个小任务,在所有节点上并行处理。(其中节点小任务出现问题,快照保存。自动恢复)
6.独立内存管理。flink自己管理自己的内存,序列化为二进制内存存储。(不会让gc带来性能下降等等)
数据库三大范式:
为了建立冗余较小、结构合理的数据库,建立一些规范标准,常用于关系数据库。
1.第一范式:最基本的范式,确保每列保持原子性,数据库表中所有字段值都是不可分解的原子值,
2.第二范式:确保表中每列都和主键相关,一个表中只存一种数据,保证减少冗余。
3.第三范式:确保表中每列都和主键直接相关,而不是间接相关。(进一步的解耦、独立。)
缓存命中率:
缓存查询次数中,得到正确结果的次数,叫做命中率。缓存命中率=缓存命中次数/缓存查询请求次数。(命中率越高,缓存的使用率越高)。
缓存:一次写入,多次读出。(适合高频读 低频写的应用场景)
影响缓存命中率的三个因素:1.缓存键集合大小,2.内存空间大小,3.缓存寿命。
Redis:
开源的k-v数据库,存储系统。
优势:
1.支持数据持久化,写入磁盘,重启时重新加载再次使用;
2.支持的数据类型丰富,key-value,value可以是list,set,hash,zset(sorted set)等数据结构等等;(项目里一般用字符串)
3.支持数据备份,master-slave 主从模式的备份。
redis的String数据类型:
String底层采用SDS(简单的动态字符串)数据结构来存储。 长度小于39时,用embstr存储形式,其它用raw存储形式(普通的原生字符串)。
embstr: RedisObject对象头和SDS结构放在内存中连续的空间位置,使用malloc分配一次就行,空间释放也就一次。
**raw:分配和释放都要两次,**RedisObject一次,SDS一次。
redis的zset:叫做有序集合(sorted set),每个元素都带一个分数,底层实现用的跳跃表。。
set是无序的,
zset底层用了跳跃表和哈希,插入更新时同时在跳跃表和哈希中都更新。跳跃表保证范围查询的高效,哈希保证单点查询的高效(哈希还保证元素不重复)。
zset底层: 元素个数小于128,长度小于64字节,使用ziplist(双向链表)。
zset的实现,不用平衡树的原因: 为啥非用跳跃表。
(1)内存占用:树结构每个节点都要包含2个指针,跳跃表包含的指针数非常少,跳跃表节省内存。
(2)范围查找:跳跃表范围查找很简单。 平衡树范围查找时,找到小值之后还要继续中序遍历查找其它值;
(3)实现难以程序,是否简单:跳跃表简单,平衡树复杂(维护平衡树)
zset实现延时队列: 进入该队列的消息,会被延迟消费的队列。(一般队列,消息一旦入队,就会被立马消费) zset实现延时队列:score为时间戳,有序队列,轮询时 达到执行时间就执行。
1.读写查询的性能特别高,
2.原子性,单个操作都是原子性的,多个操作也支持事务,multi和exec包起来。
3.丰富的特性,支持消息队列 分布和订阅,通知机制 和 过期机制。
应用场景
1.高频次、热门访问的数据,降低数据库IO。
2.分布式系统中,session共享。
redis架构图:
1.事件处理模块,
采用的是作者自己开发的 ae 事件驱动模型,可以进行高效的网络 IO 读写、命令执行,以及时间事件处理。(网络 IO 读写处理采用的是 IO 多路复用技术,通过对 evport、epoll、kqueue、select 等进行封装,同时监听多个 socket,并根据 socket 目前执行的任务,来为 socket 关联不同的事件处理器。)
2.数据管理
redis的内存数据都存在redisDB中。
redis是纯内存,需要的话,可以自己选择持久化到磁盘中。
Redis 进行数据读写的核心处理线程是单线程模型, 为了保持整个系统的高性能,必须避免任何线程导致阻塞的操作。为此,Redis fock子线程,来处理容易导致阻塞的文件 close、fsync 等操作,确保系统处理的性能和稳定性。
利用队列技术把并发访问变为串行访问,没有进程线程的切换,不需要考虑锁的问题
redis持久化:内存数据库,内存数据变化快,容易丢失,需要持久化。
两种持久化方案:
1.RDB(Redis DataBase)默认的持久化方案;指定时间间隔内,执行指定次数的写操作,将内存数据写入到磁盘。dump.rdb文件。 redis重启时会加载dump.rdb文件来恢复数据。
是一种数据集快照的方式,半持久化记录redis的所有键值对,某个时间点的数据写入临时文件,持久化结束,把临时文件替换上次持久化的文件。
rdb优点:只有一个rdb文件,方便持久化;安全的保存在磁盘中。容灾性好;性能好,fork子进程来执行写操作,主进程只处理IO;重启加载效率高。
缺点:持久化过程中 redis故障,会发生数据丢失。适合对数据要求不高的场景。
2.AOF(Append Only File)(为了弥补rdb的不足,弥补数据不一致性)
所有命令行记录以redis命令请求协议的格式来完成持久化存储, 用日志形式来记录每个写操作,并追加到文件中,redis重启时根据日志文件的内容将写指令从头到尾执行一遍,来恢复数据。
优点:数据安全,append形式,记录都能保留。(记录可以合并重写并删除)
缺点:aof文件比rdb文件大,恢复速度慢。启动效率低。
Redis的集群模式有3种:
(1)主从模式: redis提供了复制功能,分为主数据库(master),从数据库(slave);主数据库可以进行读写操作,数据变化都会同步给从数据库。从数据库只负责读。
缺点:主节点宕机后,从节点无法自动拉起,需要手动拉起。
(2)哨兵模式(sentinel):为了解决主从模式的问题。(2.1)监控功能;(2.2)故障自动恢复;(2.3)选举一个master。
redis哨兵(sentinel), 自动分区。
哨兵模式(sentinel):哨兵系统可以监控一个或多个redis master服务,以及从服务,某个master下线后,自动将该master从服务升级为master来代替。
缺点:只有一个master,写操作会成为性能瓶颈。
(3)cluster集群模式: 为了解决写操作的性能瓶颈。
配置三主三从。 16384个哈希槽,每一个key-value写入映射,每个哈希槽都是一个分区表。
redis发布(publish)-订阅(subscribe), 一种消息通信模式,发送者(pub)发布消息,订阅者(sub)接收消息.
新消息通过PUBLISH命令发送到频道channel中时,这个消息就会被发送给订阅它的所有客户端。
redis stream: 用于消息队列(MQ, Message Queue), 提供消息持久化,主备复制功能,
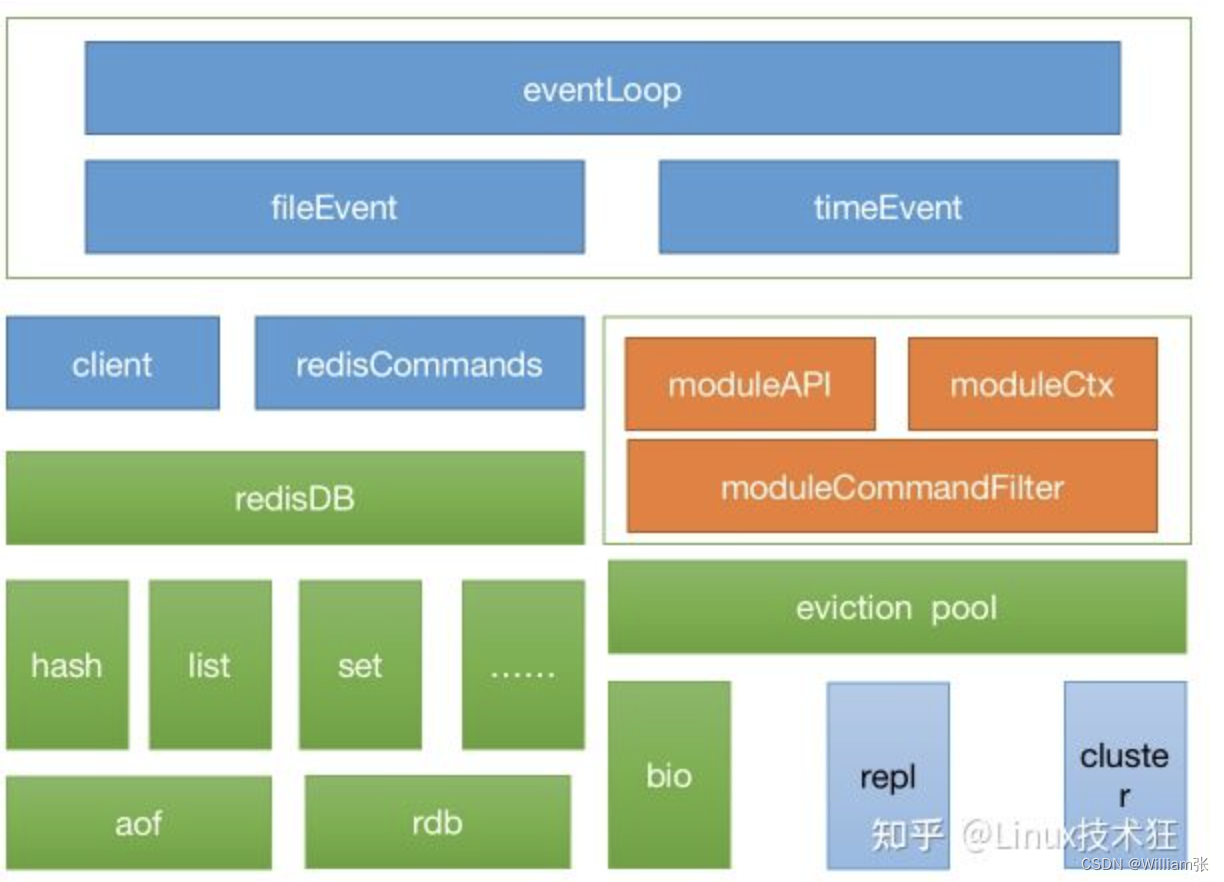
Redis的哈希 (ReHash),键值查找
Redis用哈希表,保存所有键值对。
哈希计算映射到桶, + 拉链法(每个桶上用链表来保存)
数据越来越多,链表越来越长,效率变低。
Redis的ReHash方法:
增加现有hash桶数量,让逐渐增多的键值对数据分散到更多的桶去保存,减少单个桶中的元素数量,提高效率。
ReHash具体方法:
(1)Redis默认2个哈希表,哈希表1和哈希表2. 默认先使用哈希表1,哈希表2是空的,没有分配空间。
(2)执行rehash时,为哈希表2分配更大的空间(比如原来的2倍);把哈希表1的数据重新映射并拷贝到哈希表2. 释放哈希表1的空间。
(3)拷贝过程,使用渐进式拷贝。 客户端来一次请求时,顺便执行该键值对的拷贝。 巧妙地把全量的大量拷贝分散到多次的请求中处理。 rehash过程,(3.1)新增键值对都写到哈希表2,哈希表1只减不增;(3.2)查找操作,先查表1再查表2. (3.3)没有键值对操作请求时,定时任务执行拷贝。
map和redis的区别:
map等编程语言的数据结构 也叫做缓存,本地缓存。
redis:可以分布式缓存,多实例时,各个实例共用一份缓存数据,缓存一致性。(前提要保证服务高可用)
redis做缓存的缺点,可能会存在的问题:
常见的那些问题都算是缺点
1.缓存和数据库不一致;
2.缓存雪崩、击穿、
3.物理内存受限(海量数据受限)
4.在线扩充不灵活,一般都尽量保证单台内存够用。
5.主从机数据不一致,宕机时 主机同步从机时。
6.没有自动容错和恢复功能,主从宕机时 就无法完成请求。
依次解决以上这些问题。
redis缓存和数据库一致性的问题:
1.缓存设置过期时间,数据以数据库为准,
主要是数据更新操作,(主要不一致是 缓存里的旧数据,mysql主从机制不一致)
方案1:延时双删(数据库写操作之前删,写操作完成也删)
方案2:主动加载。
缓存雪崩: 缓存中数据大量都到了过期时间,查询量大 都查询不到。(很多数据都查不到)
解决方法:热点数据永不过期,过期时间设置随机。
缓存击穿: 缓存没有命中,但是数据库中有数据(一般指缓存到期)
解决方法:热点数据永不过期(搜索频率很高的设置为不会过期)(并发查一条数据)
缓存穿透: 缓存和数据库中都没有的数据,用户不断的发起请求(我们搜索服务应该不存在这种情况)
解决方法:对请求接口做校验,不合法的直接拦截。
缓存更新策略。保证缓存内容和db数据内容一致。(低峰时期,对缓存内容批量更新)另外,db数据更新,也有一致性策略、保证缓存和db的一致性。(缓存索引非耦合策略,缓存逐步过期,减少不一致的项)
缓存管理策略:
缓存淘汰策略:过期的,最少使用的删除掉。(LRU)
LRU驱动事件,事务,不同级别的磁盘持久化。
常见的缓存算法。
(1)(LRU,Least Recently Used,最近最少使用,看的!!时间戳!!)算法。缓存中也常使用。。(!!!应用最广的缓存淘汰策略,实现简单,很实用,运行性能高,命中率高!!!)
最近经常被访问的数据,在以后也会经常被访问,经常被访问的数据,需要快速被命中,不常访问的数据,超出容量时要将其淘汰。
实现细节:(1)最近访问的数据插入或置换到缓存队列靠前的位置,(2)优先淘汰队列最末尾的字段。
实现数据结构和算法:链表 + map,map的key,value来保存数据内容;链表用来维护缓存队列。
(2) LFU,Least Frequently Used,最不经常使用,看的是频率),最近一段时间内的访问次数,
(3) FIFO(先进先出),最先进入缓存中,最先被淘汰。
Redis中热点key问题:
热点key:就是访问频率较高的key。 大量请求集中在热点key上时,key所在的redis节点的cpu、内存、网络带宽资源会被大量消耗,影响集群稳定性和整体性能。
热点key会出现的问题:
(1)热点key的节点负载过高;(2)负载不均匀,(3)甚至宕机;(4)访问频率过快,可能会出现在数据不一致问题,缓存和数据库不一致,不同节点之间不一致。(5)会出现缓存击穿问题。
热点key解决方法:
(1)提前发现, 预估发现(自身对业务的理解), redis监控工具:提前发现热点key; redis monitor发现key访问情况; redis-stat发现redis节点内存相关情况。
(2)慢查询日志,redis的慢查询日志,可能存在热点key。
(3)解决热点key:
(3.1)数据分片,集群模式下,数据分布在多个节点上,避免单个节点负载过高;非集群模式的话,用一致性哈希实现分片算法,数据分布在多个redis实例上;
(3.2)读写分离: 主从复制下,从节点用来读,主节点用来写。redis sentinel实现故障转移(master节点挂了,从节点变为主节点),以及读写分离。
(3.3)缓存预热: 定时服务或者程序启动加载热点key到缓冲中去。避免对后端服务造成压力。
(3.4)限流: 控制请求速率,来防止系统过载。应用层实现限流。常见的限流算法:有漏桶算法(强制一个常量的输出速率而不管输入数据流的突发性。当输入空闲时,该算法不执行任何动作)和令牌桶算法(限制数据的平均传输速率的同时还允许某种程度的突发传输)
(3.5)熔断降级: 在系统出现问题时,自动降低系统功能
Redis‘过期键的删除策略:
Redis中使用的是惰性删除策略 + 定期删除策略。
Redis的定期删除过程:(1)从一定数量数据库中取一定数量随机键进行检查,删除其中过期键;(2)有一个全局变量current_db,记录键检查的进度,下一次会在上一次进度上继续处理;(3)最终所有数据库的键都被检查一遍,current_db重置为0,这一轮检查结束。
(1)定时删除:设置键的过期时间的同时,创建一个定时器,定时器在键的过期时间来临时,执行键的操作;
缺点: 过期键过多时,删除操作会占用大量CPU。 对CPU不友好。
定时器的实现: redis中间件-事件,用无序列表,查找一个时间事件O(N)。
(2)惰性删除:对键的过期时间不管,每次从空间中获取键时,查看下键是否过期,过期的话就删除。
缺点:对内存不友好,会有大量过期键还在内存中占用着空间。
优点:对CPU友好,只有当前获取的键才删除,CPU上不会花费太多时间。
(3)定期删除:每隔一段时间对数据库进行检查,删除里面的过期键。 (前两种策略的折中)
每隔一段时间执行删除操作,限制删除操作执行的时长和频率, 来减少对CPU的影响; (频率不太好控制)
定期删除,也减少了内存的空间占用。
Redis是单线程的吗?
网络IO和键值对读写部分,是单线程,由一个线程完成。
其它部分,持久化存储模块、集群支撑是多线程。
redis不需要多线程: 读写主要是IO操作涉及网络IO和磁盘IO。Redis的操作都是基于内存的,不需要提高CPU利用率,多线程不起作用。
提高IO利用率,使用IO多路复用。
多线程的缺点:各种锁,以及多线程切换,反而降低查询性能。
Redis的ACID性质:
事务是一个数据库必备的元素,
Redis只满足一致性 和 隔离性, 其它特性不支持。
A(Atomic,原子性),Redis的单个命令执行是原子性的,但是Redis没有在事务上增加任何维持原子性的机制,所以,Redis的事务执行不是原子性;
C(一致性):Redis是内存模式,重启后数据库是空的,满足一致性;RDB模式; AOF模式。
I(隔离性):Redis是单线程,并且执行事务时不会中断,Redis事务具有隔离性、
D(持久性):内存模式,事务肯定不持久。RDB模式,AOF模式。
—————-
MQ(Message Queue),常叫做消息中间件、分布式消息队列
存放消息的容器,需要使用消息的时候取出来供自己使用。
分布式项目中,MQ基本都是必备消息中间件。 常用的消息中间件有:Kafka、
目的:(1)异步处理,高峰时刻提高系统性能和削峰,(2)降低系统耦合(异步处理:减小高并发的压力。
1.解耦:消息发送端和消息接收端是模块独立的。互不影响。消息队列某个机器宕机,也可以继续用集群中的其它机器做消息队列服务。
2.异步处理:业务逻辑以同步方式运行,很耗费时间;MQ中,用户请求发送到消息队列中就立刻返回;消息接收端拿到数据也是异步消费执行。消息队列的处理速度也很快。
3.削峰:主要是通过异步处理达到削峰目的。短时间高并发产生的事务消息放到消息队列中,削平高峰期的并发事务。
MQ消息队列的缺点:
1.系统可用性降低:引入了一个新模块,消息丢失 mq挂掉,
2.系统复杂性提高:重复消费、消息丢失、消息顺序。。
3.一致性问题:是异步的。。生产的消息没有被正确消费。。
kafka架构:
底层基于zookeeper,部署2N+1个节点,形成zookeeper集群,保证高可用。
kafka prodcuer: 从zookeeper拉取topic的leader分区,写入消息。
kafka broker: 每个topic的partition,会有副本,保证消息存储的可靠性。副本选择leader的partition(给producer和consumer使用),只读写leader分区。
kafka consumer:从topic的leader分区读取消息。
所有MQ中间件,都会有消息重复消费的问题存在。
如何解决重复消费的问题:
(1) kafka层面的解决:offset的概念,写入的每一个消息都有一个offset,消费时,提交offset,证明该消息已经被消费。下次继续从当前位置开始继续消费。。
(2)业务层面的解决:自己做是否重复的校验,比如写入数据,判断是否已经在数据库里了。。等等, 唯一的id。。消息id加锁。。
数据丢失问题:(常用的解决方案 以kafka为例)
- 生产者和broker弄丢数据。
(1) ack机制(确认机制),生产者发送消息,broker中leader分区和所有follower都要进行确认没问题,才回复ok;否则,生产者会一直重试发送。
(或者,其它MQ中间件用的方法:保存到本地磁盘。。。)
2.broker挂了。
保证leader的follower多于2个,都数据同步成功。写入失败,就一直重试。
3.消费端丢失数据。
原因是:消费了提交了offset,机器挂了。。
解决方案:关闭offset提交(就会认为数据还没消费),等自己处理完手动提交offset即可。。(会有重复消费情况,自己业务上保证数据一致,幂等性)
消息中的顺序性保证:
原因:多个消费端在消费,执行速度可能不太一样。。
内存中N个队列queue,指定key,相关的数据都是相同的key,写到同一个队列中,消费的时候同一个队列用单线程消费。(内部有序)
kafka如何保证高效检索查询:
1.offset
2.时间戳
查询时,根据offset即可。二分查找的方式。即可快速定位到消息内容。
kafka写操作:
顺序追加写日志的方式,自然很快,一条条记录。
常用Kafka优点
核心功能强大,吞吐量高,ms级延迟,高可用可靠性,分布式任意拓展, 存在消息重复消费。。
位移主题(consumer_offset): 消费者消费提交的offset。
生产者也有个自己的offset。
一般,消费者个数一般要等于分区数。
消费者个数大于分区数,消费者就浪费了。
消费者个数小于分区数,均衡失效,某些消费者会消费更多的分区任务。 (可以充分发挥机器性能)
B树和B+树
B树(Balanced Tree,平衡树),多路平衡查找树。
B树性质:
(1)节点中关键字,自左到右递增,关键字两侧均有指向子树的指针,左边的小于该关键字,右边的大于该关键字。
(2)B树的操作,所需磁盘的存取次数与B树的高度成正比。
B树查找:第一步确定节点,第二步在节点内确定关键字。
B+树,为了满足数据库出现的一种变形树。
B+树和B树的差异:
1.B+树中节点关键字数目和节点子树1:1; B树中n个关键字的节点可以有n+1个子树;
2.非根节点的关键字数目不同。
3.B+树中,叶子节点包含信息,非叶子节点起到索引作用;非叶节点包含子树的最大关键字和子树指针,
4.B+树的叶子节点,包含了全部关键字,非叶节点的关键字会在叶子结点中重复出现;B树中不会重复。
———————-
mysql:
mysql的架构图:
(1)连接器:负责客户端的通信,连接处理、身份验证等功能。
(2)核心服务层:通常叫SQL Layer。主要工作:权限判断、sql解析、行计划优化、query cache(缓存)的处理和所有内置函数(日期、时间、数学运算、加密等等);存储过程、触发器、视图等功能。
(3)存储引擎层: 底层数据的保存和查询操作的实现部分,由多种存储引擎共同组成。存储引擎对外提供一组API, 这些API包含了很多底层的操作。
(4)数据存储层: 将数据存储在运行于裸设备的文件系统之上,存储引擎将数据的读写功能提交到数据存储层,跟文件系统交互完成数据读写。
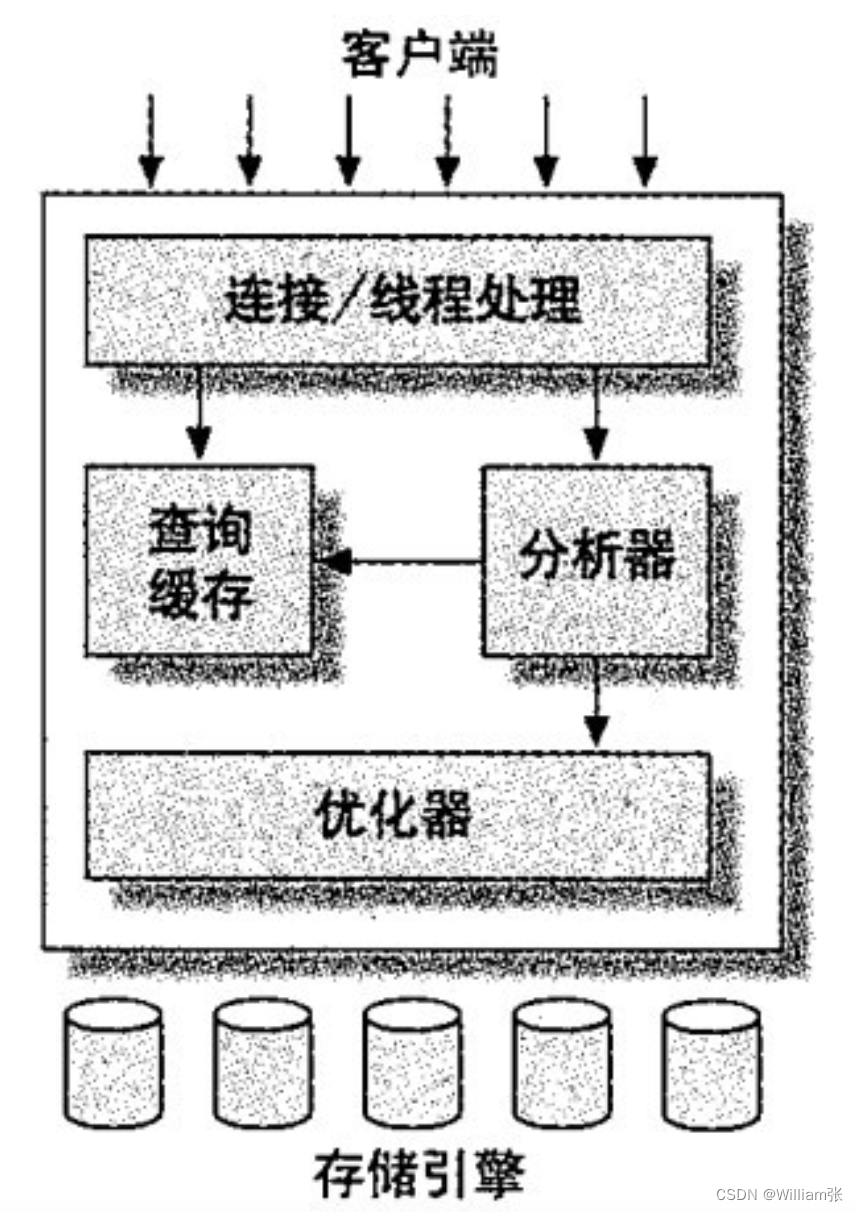
mysql执行一条查询语句的流程:
(1) 先通过连接器连接到mysql服务器;连接器权限验证通过后,查询是否有查询缓存(之前执行过该语句),有缓存则直接返回缓存数据;如果没有缓存,则进入分析器;
(2) 分析器: 对查询语句进行词法分析、语法分析,判断SQL语法是否正确;错误则返回给客户端;正确则进入优化器;
(3)优化器: 对查询语句进行优化处理,(比如一个表有多个索引,判断哪个索引性能好)
(4)执行器: 优化器执行完,则进入执行器,执行语句进行查询比对,查询到所有满足条件的所有数据,进行返回。
mysql查询缓存(query cache):
优点:效率高,在连接器之后立刻返回结果;
缺点:失效太频繁,导致命中率极低,任何更新表的操作都会清空查询缓存。
mysql存储引擎:
InnoDB是mysql默认存储引擎。
InnoDB支持事务,MyISAM不支持事务。
InnoDB提供了事务、行锁、日志等功能特性。
InnoDB架构分为2部分:
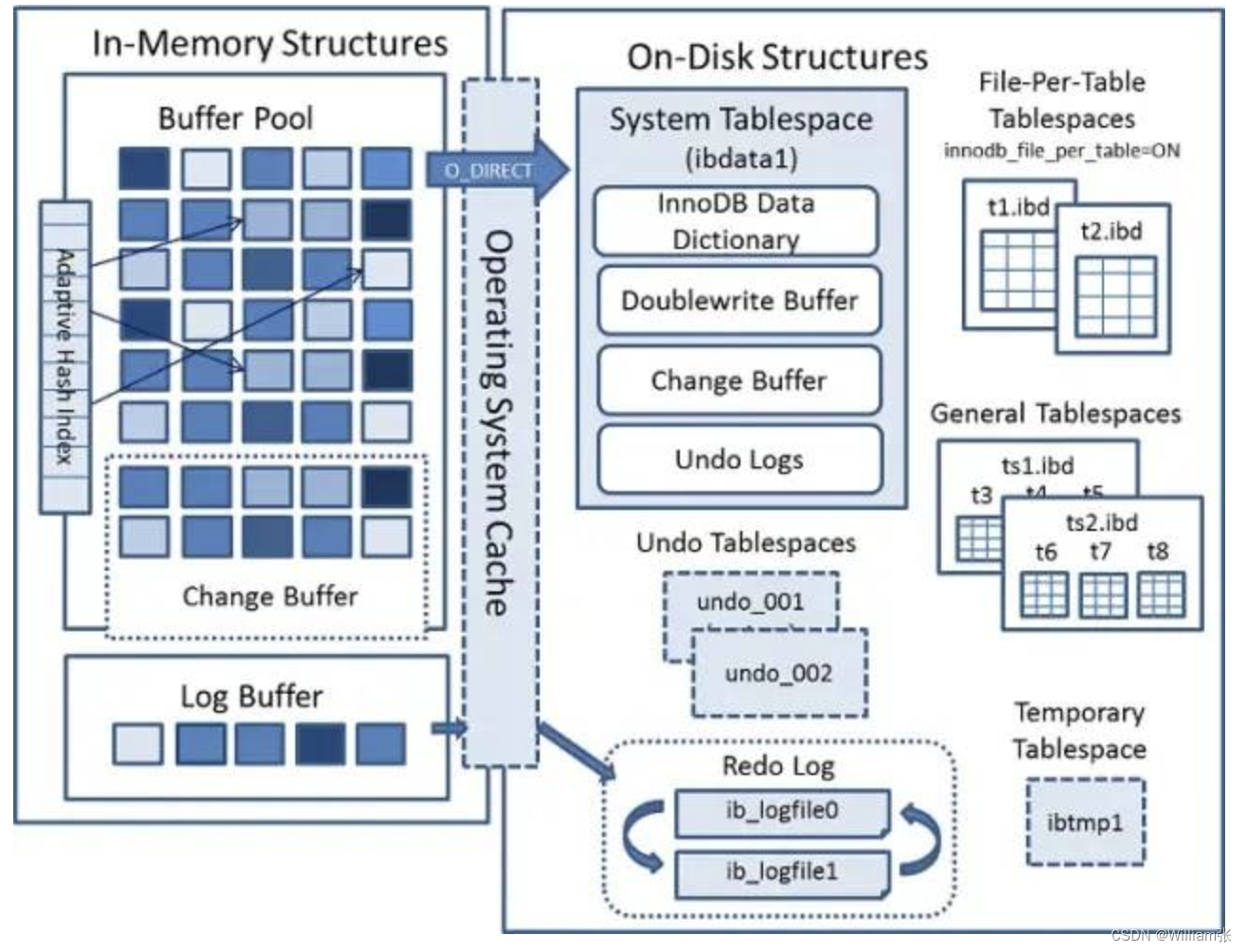
(1)内存部分: 包括缓冲池(Buffer Pool)(包含Page cache、Change Buffer、Adaptive Hash Index)、Log buffer。
缓冲池用页链表来管理,LRU算法来淘汰很少访问的页。
(2)磁盘部分 包括: (2.1)表空间、(2.2)Redo日志,
表空间: 包括系统表空间、临时表空间、常规表空间,Undo表空间和file-per-table表空间。还包括数据字典、双写缓冲区、Change Buffer、Undo日志
Mysql InnoDB是支持事务的
事务相关:一件事情有n个组成单元,一起成功 或者一起失败,n个组成单元放在一起,就是一个事务。。
mysql:一条sql语句就是一个事务。。 默认开启事务并提交事务。。
开启事务,事务提交, 事务回滚。。
mysql InnoDB支持事务的四种隔离级别:
1.read uncommited,读取尚未提交的数据(哪个问题都解决不了)
2.read commited,读取已经提交的数据(可以解决脏读)
3.重复读取,Repeatable Read(解决脏读和不可重复读)mysql默认。(这个隔离级别可以解决了幻读问题)读的都是快照读。
(不可重复读,指一个事务中多次读同一数据 结果出现不一致)
4.串行化,可以解决脏读,不可重复读,虚读,相当于锁表。
(幻读,一个事务中使用相同的sql,两次读取,第二次读取到了其他事务新插入的行)
事务特性:ACID,
(1)原子性(事务是一个不可分割的单位,全部发生、全部不发生)
InnoDB实现原子性:auto_commit设置,commit和roll_back(通过undo log实现)。
(2)一致性,(事务前后 数据完整性必须保持一致)
InnoDB实现一致性:双写缓冲区、故障恢复机制。
(3)隔离性,多个用户并发访问,一个用户的事务不能被其他用户的事务干扰,互相隔离)
InnoDB实现隔离性:锁机制,auto_commit.
(4)持久性,(事务被提交,对数据的改变是永久性的,即使故障也不能有影响)
InnoDB实现持久性的措施:太多了。。
MvCC(多版本 并发控制)。Multi Version
https://cnblogs.com/chinesern/p/7592537.html
为啥用b+树:
1.肯定是为了提高查询效率。
b+树磁盘读写代价更低:数据都在叶子节点,其它节点存储更多的键,树的高度很小。(1-3次)
b+树查询效率更稳定:任何查询都必须从根节点走到叶子节点,路径长度相同。
叶子节点数据之间用指针链表 连起来,可以查到所有数据,可以进行范围查询range
innodb:
是mysql的数据库内部引擎,用了这个才能支持事务。 内存存储引擎, 页是管理数据的最小磁盘单位,b-tree节点就是实际存放表数据的节点,
1.支持ACID,支持事务完整性和一致性。
2.支持行锁,一致性读,多用户并发。
3.聚集索引 主键设计方式, 大幅提升并发读写性能。
mysql数据都在磁盘中,为了提高速度,用了缓冲池
undo页:实现事务原子性,用来实现多版本并发控制(MVCC),任何操作之前数据备份的地方,方便回滚
InnoDB体系架构:
1.后台线程(主要负责刷新内存池中的数据,将已修改的数据刷新到磁盘)
(1.master thread,主线程,将缓冲池数据异步刷新到磁盘,保证数据一致性,脏页刷新、合并插入缓冲、UnDo页回收;2.IO thread:大量属于异步IO来处理写IO请求;3.purge thread(清理线程):回收已经使用并分配的undo页。
2.内存池(多个内存块,组成一个很大的内存池)
一个innodb页有7个部分组成:
fil header/fil trailer
page header/page dictionary:页的状态信息
dictionary:存储稀疏索引,
user records:页面里 真正存放行记录的部分,
free space:空余空间。 链表结构(从左到右寻找空白节点插入)
b+树查找, 内存中进行。
慢查询:日志记录运行比较慢的sql语句,(记录下来之后可以方便定位优化查询效率)非常有用的日志。
sql优化: 1.修改sql写法, 2.新增索引。
将字段分解成多个表;增加中间表;分解关联查询。 覆盖索引。。。
各种索引:
全文索引:参考es里的term倒排索引
主键索引:主键是一种约束,主键创建后相当于一种唯一索引,(不允许为空,可以被其它表引用为外键;适合 自动递增列,身份证号,
唯一索引:不一定是主键索引。(允许为空)
索引:mysql索引大大提高检索速度
索引优化,是提高查询性能最重要的手段。(查询时每次只能用1个索引)
索引的作用:大大减小服务需要扫描的数据量,大大加快数据检索速度,随机IO变成顺序IO。
——-
mysql日志有哪些:
1.redo log(重做日志), 2.undo log(回滚日志), 3.bin log(二进制日志), 4.slow query log(慢查询日志), 5.relay log(中继日志)
redo log:记录事务执行后的状态,
https://cnblogs.com/myseries/p/10728533.html
(mysql日志)
mysql锁的级别: 表级锁, 页级锁, 行级锁。
https://blog.csdn.net/zcl_love_wx/article/details/81983267
mysql的老版本, myISAM是默认引擎(但是不支持事务及行级锁,
innodb存储引擎:使用b+树建立索引,关系数据库中最常用的
(b+树并不能找到给定键对应的具体值,只能找到数据行对应的页,整个页读入内存,在内存找到具体数据行)
b+树是平衡树,查找任意节点耗费时间都是完全相同的,比较次数就是b+树的高度。
数据库中b+树索引分为聚集索引(clustered index)和辅助索引(secondary index),
聚集索引 存放一条行记录的全部信息。(物理地址连续存放的索引,取区间时,查找速度非常快,使用链表)
辅助索引:只包含索引列和一个用于查找对应行记录的书签。(存的是主键索引,提高某个字段值查询的效率,辅助索引通过牺牲空间来提高查询效率,会浪费空间,合理创建辅助索引)
主键 看作是 聚集索引,如果没有创建,系统自动创建一个隐含列为表的聚集索引。
———
主从同步:
减轻服务器处理海量并发访问,产生的性能问题。
1.master主机器,将对数据的操作记录写到二进制日志中(binary log),mysql将事务串行的写入;
2.slave(备份机器)将二进制日志(binary log) 拷贝到中继日志(relay log)。 slave机器开启一个工作线程 io线程。
然后slave和 master保持一致。
需要中继:bin log不能一口气存到io线程,relay log缓存bin log事件。
———-
读写分离:
master 主机器 只用来进行写操作(主机器创建一个用户,只进行写,给予对应权限)
slave 备份机器 只用来进行读操作。
(通过路由,进行读写分离,
———
分布式事务:
mysql本身支持分布式事务,有限支持。
主要解决:分布式数据库场景下 所有节点间数据一致性问题。(通常采用2PC协议),分布式中会存在部分节点提交失败的情况。(所有节点都能提交时,整个分布式事务才允许被提交)
分布式事务通过2PC协议 将提交分为2个阶段:
1.prepare
2.commit/rollback
mysql 并发控制:
乐观并发控制(默认不出问题。遇到了问题了就重试,写的时候看是否被其他修改了, 整个过程中就没有枷锁。)乐观锁不会死锁, 但是冲突和重试过多时,增加负担,最好用悲观锁。
响应速度要求很高,并发量很大时,推荐乐观锁。(这时悲观锁会有性能问题。)
悲观并发控制(最常见的方法,就是锁)
共享锁,排他锁,两种实现方式。实现了标准的行级锁。
多版本并发控制
并发控制要考虑:冲突频率、重试成本、响应速度和并发量。
——————
——
zab(zookeeper内部的分布式协调功能)
https://blog.csdn.net/a724888/article/details/80757503
zab协议, zookeeper根据zab协议实现分布式系统数据一致性。
写入一条数据,到遵循zab一致性,的整个流程:
1.客户端发起写操作请求,
2.
Flink:
火热的大数据处理框架,天然的流式计算,强大的处理性能。
优势:数据分布、容错处理、资源管理。。
工作流程: 创建job, -> 工作环境(environment) -> 数据源(source) ->数据处理transform -> 保存数据。
1.Flink统一批数据(有边界的数据)和流数据(无边界的数据)(流数据应用更广泛)
Flink是标准的实时处理引擎,基于事件驱动。
Spark:是微-批处理引擎。
Flink 和 Spark的区别:
1.架构层面: (1)Flink: job管理, task管理,slot ; (2)Spark: master, worker, driver, executer.
容错机制:(1)spark设置checkpoint,故障重启从checkpoint恢复,保证数据不丢失,danshi可能会重复处理。(2)Flink使用两个阶段提交来保证容错。
https://zhuanlan.zhihu.com/p/142439942














 1041
1041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









