






 本文汇总了Java开发中常用的框架注解,包括Spring、JPA、SpringMVC、SpringBoot等,详细解释了各注解的功能与使用场景,是Java程序员必备的注解指南。
本文汇总了Java开发中常用的框架注解,包括Spring、JPA、SpringMVC、SpringBoot等,详细解释了各注解的功能与使用场景,是Java程序员必备的注解指南。
新人小白,刚接触注解几天,每天都在搜索各种注解的意思,这里根据网上其他的人资料,自己整理了一下各个框架的常用注解,只是最基本的一个概念,没有代码演示例子啥的,有些归类可能不太对,如果有错误还请大家指出来。
文章目录
一、Spring常用注解
- 注解就相当于XML文件中的<bean id=””class=”/>使用注解就不用去写配置文件,spring这些框架帮我们去写XML配置文件。
1.1组件注解
@Service:注解在类上,表示这是一个业务逻辑层bean,表示创建这这个类的对象。
@Controller:注解在类上,表示这是一个控制层bean,用来创建处理http请求的对象
@Repository:注解在类上,表示这是一个数据访问层bean,表示创建这这个类的对象。
这几个注解就是标记作用,表示这些类是哪个层而已:service层action层dao层。也是创建这几个类的对象。
@Component: 注解在类上,表示一个普通的bean ,表示创建这这个类的对象。value不写默认就是类名的首字母小写。
这个注解就是标记其他类,比如工具类,表示除了这三层之外的类。
@Component可以代替@Repository、@Service、@Controller,因为这三个注解是被@Component标注的。
1.2组件扫描注解
@ComponentScan:注解在类上,组件扫描。告诉spring 哪个packages 的用注解标识的类会被spring自动扫描并且装入bean容器。让spring扫描到Configuration类并把它加入到程序上下文。它会自动扫描指定包下的全部标有 @Component注解的类,并注册成bean,当然包括 @Component下的子注解@Service、@Repository、@Controller。
@ComponentScan 如果不设置basePackage的话 默认会扫描包的所有类,所以最好还是写上basePackage ,减少加载时间。默认扫描**/*.class路径 比如这个注解在com.wuhulala 下面 ,那么会扫描这个包下的所有类还有子包的所有类,比如com.wuhulala.service包的应用。
@WishlyConfiguration 为@Configuration与@ComponentScan的组合注解,可以替代这两个注解。
1.3 bean相关注解
@Scope:注解在类上,描述spring容器如何创建Bean实例。
(1)singleton: 表示在spring容器中的单例,通过spring容器获得该bean时总是返回唯一的实例
(2)prototype:表示每次获得bean都会生成一个新的对象
(3)request:表示在一次http请求内有效(只适用于web应用)
(4)session:表示在一个用户会话内有效(只适用于web应用)
(5)globalSession:表示在全局会话内有效(只适用于web应用)
在多数情况,我们只会使用singleton和prototype两种scope,如果未指定scope属性,默认为singleton。
该注解和@Component这一类注解联合使用,用于标记该类的作用域,默认singleton。也可以和@Bean一起使用,此时@Scope修饰一个方法。
@DependsOn:该注解也是配合@Component这类注解使用,用于强制初始化其他bean。
@Lazy:指定bean是否延时初始化,相当于<bean id=“xx” lazy-init=“”> ,默认false。@Lazy可以和@Component这一类注解联合使用修饰类,也可以和@Bean一起使用修饰方法。
1.4 bean(singleton作用域)的生命周期的行为注解
@PostConstruct:修饰方法。用于在依赖关系注入完成之后需要执行的方法上,以执行任何初始化。 被@PostConstruct修饰的方法会在服务器加载Servlet的时候运行,并且只会被服务器调用一次,类似于Servlet的inti()方法。被@PostConstruct修饰的方法会在构造函数之后,init()方法之前运行。
@PreDestroy: 修饰方法。被@PreConstruct修饰的方法会在服务器卸载Servlet的时候运行,并且只会被服务器调用一次,类似于Servlet的destroy()方法。被@PreConstruct修饰的方法会在destroy()方法之后运行,在Servlet被彻底卸载之前。
spring用这两个注解管理容器中spring生命周期行为。这两个注解被用来修饰一个非静态的void()方法.而且这个方法不能有抛出异常声明。
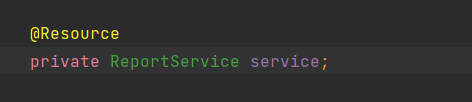
@Resource:可以修饰成员变量也可以修饰set方法。
@Autowired:自动导入对象到类中,被注入进的类同样要被 Spring 容器管理比如:Service 类注入到 Controller 类中
@Autowired可以修饰构造器,成员变量,set方法,普通方法。@Autowired默认使用byType方式自动装配。required标记该类型的bean是否时必须的,默认为必须存在(true)。
可以配合@Qualifier(value=“xx”),实现按beanName注入。
required=true(默认),为true时,从spring容器查找和指定类型匹配的bean,匹配不到或匹配多个则抛出异常。当不能确定 Spring 容器中一定拥有某个类的Bean 时,可以在需要自动注入该类 Bean 的地方可以使用 @Autowired(required = false), 这等于告诉Spring:在找不到匹配Bean时也不抛出BeanCreationException 异常。
使用@Qualifier(“xx”),则会从spring容器匹配类型和 id 一致的bean,匹配不到则抛出异常
@Autowired会根据修饰的成员选取不同的类型
修饰成员变量。该类型为成员变量类型
修饰方法,构造器。注入类型为参数的数据类型,当然可以有多个参数
@Autowired可以对成员变量、方法以及构造函数进行注释,而 @Qualifier 的标注对象是成员变量、方法入参、构造函数入参。正是由于注释对象的不同,所以 Spring 不将 @Autowired 和 @Qualifier 统一成一个注释类。
理解:在一个类里面注入其他类(注入属性),就可以调用注入的那个类的属性和方法了。
xml方式:定义属性
set方法
配置文件对象类型注入
注解方式:定义属性
@AutoWired
使用注解方式就省略了配置文件和set方法,就跟其他基本数据类型的属性一样定义即可。
@Resource和@Autowired的区别:
@Resource是Java自己的注解,@Resource有两个属性是比较重要的,分是name和type;Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不指定name也不指定type属性,按type进行注入的自动注入策略。
下面看一下这样的一个变量注入方式:
按type进行注入的自动注入策略。这个type指的就是类的类型,可以这样理解,比如Apple.class,类型就是Apple,Person.class,类型就是Person。
@AutoWired是spring的注解,Autowired只根据type进行注入,不会去匹配name。如果涉及到type无法辨别注入对象时,那需要依赖@Qualifier或@Primary注解一起来修饰。@Resource默认按名称方式进行bean匹配,@Autowired默认按类型方式进行bean匹配。
详情看我的另外一篇文章@Resource和@Autowired的区别
@Bean 和 @Autowired 的区别:
@Bean 告诉 Spring:“这是这个类的一个实例,请保留它,并在我请求时将它还给我”。
@Autowired 说:“请给我一个这个类的实例,例如,一个我之前用@Bean注释创建的实例”。
@SpringBootApplication
public class Application {
@Autowired
BookingService bookingService;
@Bean
BookingService bookingService() {
return new BookingService();
}
public static void main(String[] args) {
bookingService.book("Alice", "Bob", "Carol");
}
}
在本例中,@Bean 注释为 Spring 提供了一个BookingService类型的对象bookingSercive, @Autowired 使用了它。这可能是一个稍微没有意义的示例,因为你在同一个类中使用这些,但是如果您在一个类中定义了@Bean,而在另一个类中定义了@Autowired,那么它就非常有用。
理解:
@Bean就是创建了对象,spring在管理,然后@Autowired去使用,@Autowired只是使用,比如我在controller层使用注入service对象,就是容器里有service对象了,使用而已,@Service、@Repository、@Component等等都可以产生bean,那么@Autowired就可以去注入了。一个是自己产生,一个是别人产生,自己来用。
1.5 AOP 相关注解
该注解是AspectJ中的注解,并不是spring提供的,所以还需要导入aspectjweaver.jar,aspectjrt.jar,除此之外还需要依赖aopalliance.jar
@Aspect:修饰Java类,指定该类为切面类。当spring容器检测到某个bean被@Aspect修饰时,spring容器不会对该bean做增强处理(bean后处理器增强,代理增强)
@Before:修饰方法,before增强处理。有一个value属性用于指定切入点表达式。用于对目标方法(切入点表达式指定方法)执行前做增强处理。可以用于权限检查,登陆检查。该注解标注的方法在业务模块代码执行之前执行,其不能阻止业务模块的执行,除非抛出异常。
@Before是业务逻辑执行前执行,与其对应的是@AfterReturning,而不是@After,@After是所有的切面逻辑执行完之后才会执行,无论是否抛出异常。
@AfterReturning:修饰方法,afterreturning增强处理。目标方法正常结束后做增强处理
@AfterThrowing:修饰方法,afterthrowing增强处理。当目标程序方法抛出异常或者异常无法捕获时,做增强处理。
@After:修饰方法 ,after增强处理。无论方法是否正常结束,都会调用该增强处理(@After= @AfterReturning+@AfterThrowing)。一般用于释放资源。
@Around:修饰方法, around增强处理。该处理可以在目标方法执行之前和执行之后织入增强处理,可以看作是@Before和@AfterReturning的总和。其所标注的方法用于编写包裹业务模块执行的代码,其可以传入一个ProceedingJoinPoint用于调用业务模块的代码,无论是调用前逻辑还是调用后逻辑,都可以在该方法中编写,甚至其可以根据一定的条件而阻断业务模块的调用。注意:环绕通知内部一定要确保执行proceed()该方法,如果不执行该方法,业务bean中被拦截的方法就不会被执行。当执行该方法,如果后面还有切面的话,它的执行顺序应该是这样的:先执行后面的切面,如果后面没有切面了,再执行最终的目标对象的业务方法。若不执行该方法,则后面的切面,业务bean的方法都不会被执行。
其实仅使用环绕通知就可以实现前置通知、后置通知、异常通知、最终通知等效果。
虽然Around功能强大,但通常需要在线程安全的环境下使用。因此,如果使用普通的Before、AfterReturing增强方法就可以解决的事情,就没有必要使用Around增强处理了。
@Pointcut:修饰方法,定义一个切入点,用于被其他增强调用。@Order:当不同的切面中的两个增强处理需要在同一个连接点被织入时,spring aop可以指定不同切面类的增强处理优先级。
1.6 Java配置类相关注解
@Configuration: 注解在类上,表示这是一个IOC容器,被修饰的类相当于一个spring的配置xml文件,相当于<beans> </beans>。IOC容器的配置类一般与 @Bean 注解配合使用,用 @Configuration 注解类等价与 xml配置文件中的<beans>,用@Bean 注解方法等价于xml配置文件中的<bean>。
@Import:修饰Java类,用于向当前配置类导入其他java配置类
@ImportResource:修饰Java类,用于向当前注解类导入xml配置文件
上面两个都是用于配置的导入相当于<import resource=“”>元素
@Bean:注解在方法上,声明当前方法返回一个Bean。该注解相当于<bean />元素
常用的属性:
name:bean id 。name可以省略,省略时name值为方法名。
autowire: 是否自动注入,默认Autowire.NO
initMethod:bean的初始化方法。在依赖注入之后执行\<bean id="" init-method="">
destroyMethod: spring容器关闭时bean调用的方法 \<bean id="" destroty-method="">
当然@Bean还可以配合@Scope指定bean的作用域。
spring启动过程中会自动扫描注解,当遇到能产生Bean的注解后,会将注解的类自动实例化(自动扫描及实例化只进行一次),之后将这个类的实例放到springIOC容器中,当需要使用时(自动装配)会从容器中调用这个实例。
带有 @Configuration 的注解类表示这个类可以使用 Spring IoC 容器作为 bean 定义的来源。@Bean 注解告诉 Spring,一个带有 @Bean 的注解方法将返回一个对象,该对象应该被注册为Spring 应用程序上下文中的 bean。
能产生Bean的注解有:
@Component
@Repository
@Controller
@Service
@Configration
@Bean
自动装配:
类A中有对象属性类B,在实例化A时,也需要为A的属性B进行实例化,即装配。
在A类中声明属性B时加上注解@Autowired,A实例化时spring会自动从容器中调动B的实例。为了让spring能从容器中调用B的实例,需在B的类声明上能产生Bean的注解。
@Value:注解在变量上,为属性注入值。@Value的作用是通过注解将常量、配置文件中的值、其他bean的属性值注入到变量中,作为变量的初始值。@Value(“${expression}”),表示只公开getter,对所有属性的setter都封闭,即private修饰,所以它不能和@Builder一起用。
支持如下方式的注入:
注入普通字符:@Value("Michael Jackson")String name;
注入操作系统属性:@Value("#{systemProperties['os.name']}")String osName;
注入表达式: @Value("#{ T(java.lang.Math).random() * 100 }") String randomNumber;
注入其它bean属性:@Value("#{domeClass.name}")String name;
注入文件资源:@Value("classpath:com/hgs/hello/test.txt")String Resource file;
注入网站资源:@Value("http://www.cznovel.com")Resource url;
注入配置文件:@Value("${book.name}")String bookName;
注入配置文件属性使用方法:
① 编写配置文件(test.properties)
book.name=《三体》
② @PropertySource 加载配置文类上,表示读取哪个配置文件
@PropertySource(“classpath:com/hgs/hello/test/test.propertie”)
注意: @Value不能对 static 属性注入。
在application.properties中的文件,直接使用@Value读取即可,applicarion的读取优先级最高,如果是其他文件,就要像上面的德尔方式去设置。
@Value的值有两类:
① ${ property : default_value }
② #{ obj.property? : default_value }
就是说,第一个注入的是外部参数对应的property,第二个则是SpEL表达式对应的内容。那个 default_value,就是前面的值为空时的默认值。注意二者的不同。
@ConfigurationProperties:读取配置文件信息,读取并自动封装成实体类,在bean上添加上这个注解,指定好配置文件的前缀,那么对应的配置文件数据就会自动填充到bean中。
1.7 环境切换
@Profile:注解在方法或类上,通过设定Environment的ActiveProfiles来设定当前context需要使用的配置环境。
@Conditional:根据满足某个特定的条件创建一个特定的Bean。比如,当某一个jar包在一个类路径下时,自动配置一个或者多个Bean。或者只有一个Bean创建时,才会创建另一个Bean。总的来说,就是根据特定条件来控制Bean的创建行为,这样我们可以利用这个特性进行一些自动配置。通过实现Condition接口,并重写matches方法,从而决定该bean是否被实例化。(方法上)
1.8 异步相关
@EnableAsync:注解在类上,配置类中,通过此注解开启对异步任务的支持。
@Async:注解在类或方法上,在实际执行的bean方法使用该注解来申明其是一个异步任务(方法上或类上所有的方法都将异步,需要@EnableAsync开启异步任务)。
1.9 定时任务相关
@EnableScheduling:注解在类上,开启计划任务的支持。
@Scheduled:注解在方法上,申明这是一个任务,包括cron,fixDelay,fixRate等类型(需先开启计划任务的支持)。
1.10 Enable注解说明*
这些注解主要用来开启对xxx的支持。
@EnableAspectJAutoProxy:开启对AspectJ自动代理的支持。
@EnableAsync:开启异步方法的支持。
@EnableScheduling:开启计划任务的支持。
@EnableWebMvc:开启Web MVC的配置支持。
@EnableConfigurationProperties:开启对@ConfigurationProperties注解配置Bean的支持。
@EnableJpaRepositories:开启对SpringData JPA Repository的支持。
@EnableTransactionManagement: 开启注解式事务的支持。
@EnableCaching:开启注解式的缓存支持。
@EnableFeignClients:前service服务要调用到其他service服务的api接口时,可通过EnableFeignClients调用其他服务的api。
@EnableAutoConfiguration:启用 Spring 应用程序上下文的自动配置,试图猜测和配置您可能需要的bean。自动配置类通常采用基于你的classpath 和已经定义的 beans 对象进行应用。被 @EnableAutoConfiguration 注解的类所在的包有特定的意义,并且作为默认配置使用。通常推荐将 @EnableAutoConfiguration 配置在 root 包下,这样所有的子包、类都可以被查找到。
1.11 测试相关注解
@RunWith:运行器,Spring中通常用于对JUnit的支持。
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration:加载配置ApplicationContext,其中classes属性用来加载配置类。
@ContextConfiguration(classes={TestConfig.class})
1.12其他注解
@EnableCaching:@ResponseStatus:改变服务器响应的状态码 ,比如一个本是200的请求可以通过@ResponseStatus 改成404/500等,一种是加载自定义异常类上,一种是加在目标方法中。
1、value:设置异常的状态码
对应枚举HttpStatus的值,此值对应404,403,500等
2、reason:异常的描述
界面提示文字
@ResponseStatus注解配合@ExceptionHandler注解使用会更好。
加在自定义异常类上
例:
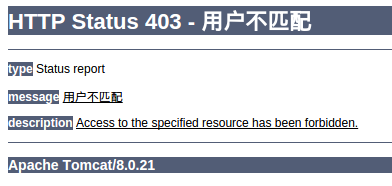
@ResponseStatus(value=HttpStatus.FORBIDDEN,reason="用户不匹配")
public class UserNotMatchException extends RuntimeException{
private static final long serialVersionUID = 1L;
}
写一个目标方法抛出该异常
@RequestMapping("/testResponseStatus")
public String testResponseStatus(@RequestParam(value = "id") final int i){
if(i==0){
throw new UserNotMatchException();
}
return "hello";
}
传入参数i==0的时候将抛异常。下图是效果图:
加在方法上
例:
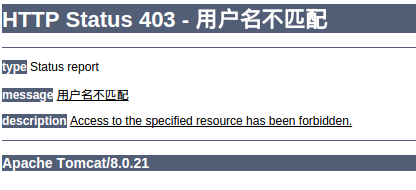
@ResponseStatus(value=HttpStatus.FORBIDDEN,reason="用户名不匹配")
@RequestMapping("/testResponseStatus")
public String testResponseStatus(@RequestParam(value = "id") final int i){
if(i==0){
throw new UserNotMatchException();
}
return "hello";
}
传入参数i==0的时候也会抛异常,效果图:
注意:重点注意的是不管该方法是不是发生了异常,将@ResponseStatus注解加在目标方法上,一定会抛出异常(错误的说法,看下面的解释)。但是如果没有发生异常的话方法会正常执行完毕。
实际上并不是抛异常,而是因为修改了响应状态码为403,并加上了错误提示(reason),所有页面回显的数据按照403错误显示页面。
@ResponseStatus(code=A,reason=B)标注在@RequestMapping方法上,作用效果与 response.sendError(A,B)是一样的,所以标注到方法上面后总会返回错误页面。如果去掉reason属性,spring就只会设置状态码,就能正常返回;所以配置在方法上面的ResponseStatus注解建议不要携带属性reason。
@AliasFor:
1.用于为注解属性声明别名
2.把多个元注解的属性组合在一起形成新的注解
如:
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD})
@Documented
public @interface AliasFor {
@AliasFor("attribute")
String value() default "";
@AliasFor("value")
String attribute() default "";
Class<? extends Annotation> annotation() default Annotation.class;
}
它有两个属性value和attribute @AliasFor注解注释了自身,并且value和attribute互为别名。
1.13 spring 5 core
@NonNullFields:包级规则,表示Field不为null。
@NonNullApi:包级规则,表示方法参数和返回值不为null。
@Nullable:对于部分可为空的Field、方法参数和返回值需要使用@Nullable进行标示。
二、JPA常用注解
@Entity:表明这个class是实体类,并且使用默认的orm规则,class名即数据库表中表名,class字段名即表中的字段名。如果想改变这种默认的orm规则,就要使用@Table来改变class名与数据库中表名的映射规则,@Column来改变class中字段名与db中表的字段名的映射规则。
@Table:注解在类上表明这是一个实体类。当实体类与其映射的数据库表名不同时,需要使用@Table注解说明,但是如果表名和实体类名相同的话,@Table可以省略,@Table标注还有catalog和schema用于设置表所属的数据库目录或模式,通常为数据库名。
@Column:标注在属性前或getter方法前,通过这个注解设置,包含的设置如下 :
name:数据库表字段名
unique:是否唯一
nullable:是否可以为空
Length:长度
inserttable:是否可以插入
updateable:是否可以更新
columnDefinition: 定义建表时创建此列的DDL
secondaryTable: 从表名。如果此列不建在主表上(默认建在主表),该属性定义该列所在从表的名字。
precision和scale:表示精度,当字段类型为double时,precision表示数值的总长度,scale表示小数点所占的位数。
//设置属性userCode对应的字段为user_code,长度为32,非空
@Column(name = "user_code", nullable = false, length=32)
private String userCode;
//设置属性wages对应的字段为user_wages,12位数字可保留两位小数,可以为空
@Column(name = "user_wages", nullable = true, precision=12,scale=2)
private double wages;
@Id:表示该属性为主键。
//设置为时间类型
@Temporal(TemporalType.DATE)
private Date joinDate;
@Transient:表示该属性并非一个到数据库表的字段的映射,ORM框架将忽略该属性。如果一个属性并非数据库表的字段映射,就务必将其标示为@Transient,否则,ORM框架默认其注解为@Basic。@Basic(fetch=FetchType.LAZY):标记可以指定实体属性的加载方式
@JsonIgnore:作用是json序列化时将Java bean中的一些属性忽略掉,序列化和反序列化都受影响。
@JoinColumn(name=”loginId”):一对一:本表中指向另一个表的外键。一对多:另一个表指向本表的外键。
@OneToOne:对应hibernate配置文件中的一对一。
@OneToMany:对应hibernate配置文件中的一对多。
会产生中间表,此时可以用@onetoMany @Joincolumn(name=" ")避免产生中间表,并且指定了外键的名字(@joincolumn在一中写着,但它存在在多的那个表中)。
如果不在@OneToMany中加mappedy属性就会产生中间表。
@ManyToOne:对应hibernate配置文件中的多对一,注解的这端,是多端。
属性:
optional:外键为空时是否仍可以向表中添加数据。
cascade:级联操作。
fetch: 加载类型,默认情况一的方为立即加载,多的一方为延迟加载。@ManyToOne默认是立即加载,@OneToMany默认是懒加载。lazy模式用到了那个属性才会加载,eager是总会加载。
mappedBy: 关系维护,mappBy表示关系被维护端,只有关系端有权去更新外键。
不产生中间表,但可以用@Joincolumn(name=" ")来指定生成外键的名字,外键在多的一方表中产生。
@Basic:表示一个简单的属性到数据库表的字段的映射,对没有任何标注的getXxx()方法,默认即为@Basic。
fetch:表示该属性的读取策略,有 EAGER 和 LAZY 两种。
optional:表示该属性是否允许为null,默认为true。
@Temporal:用于调整Date类型的精度,用三种精度:DATE,TIME或TIMESTAMP
@Temporal(TemporalType.TIMESTAMP)
@GeneratedValue:用于标注主键的生成策略,通过 strategy 属性指定。默认情况下,JPA 自动选择一个最适合底层数据库的主键生成策略:SqlServer 对应 identity,MySQL 对应 auto increment。 在 javax.persistence.GenerationType 中定义了以下几种可供选择的策略:
IDENTITY:采用数据库 ID自增长的方式来自增主键字段,Oracle 不支持这种方式;
AUTO: JPA自动选择合适的策略,是默认选项;
SEQUENCE:通过序列产生主键,通过 @SequenceGenerator 注解指定序列名,MySql 不支持这种方式
TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。
三、SpringMVC常用注解
@RequestMapping:注解在类或方法上,和请求报文做对应的,配置url映射。@RequestMapping(“/path”)表示该控制器处理所有“/path”的UR L请求。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
a:value:指定请求的实际地址,指定的地址可以是URI Template 模式。
b:method:指定请求方法类型,这个不写的话,自适应:get或者post。
c: consumes:指定请求的提交内容类型,如application/json,text/html。仅处理request Content-Type为“application/json”类型的请求。
d:produces:指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回。(对象接受的时候要加上这个属性,
如produces = MediaType.APPLICATION_JSON_UTF8_VALUE)
e: params:指定request中必须包含某些参数值,才让该方法处理请求。
f:headers:指定request中必须包含指定的header值,才能让该方法处理请求。
g: name 指定映射的名称
当然也可以使用@GetMapping/@PostMapping/@PutMapping/@DeleteMapping
@GetMapping:是一个组合注解,是@RequestMapping(method = RequestMethod.GET)缩写。该注解将HTTP Get 映射到 特定的处理方法上。
@PostMapping:是一个组合注解,是@RequestMapping(method = RequestMethod.POST)的缩写。该注解将HTTP Post映射到 特定的处理方法上。
其他几个注解依此类推。
PUT请求:如果两个请求相同,后一个请求会把第一个请求覆盖掉。(所以PUT用来改资源)
POST请求:后一个请求不会把第一个请求覆盖掉。(所以Post用来增资源)
@RequestParam:注解在方法的参数前面,获取参数,用键值对的方式取值。
@RequestParam == @QueryParam
@PathParam == @PathVariable
在前端:
get请求,参数是拼接在url地址后面的,方法名后面加 “?” 开始,多个参数用 “&” 拼接,
格式为:/getInfos?pageNum=1&pageSize=10
post 请求,放在请求头中,url格式也一样(前端代码用的时候不一样),
格式为:/getInfos?pageNum=1&pageSize=10
后端使用,如:
@RequestParam(value = "pageNum")Integer pageNum,
@RequestParam(value = "pageSize")Integer pageSize
@PathVariable:路径变量,注解在方法的参数前面,获取参数,通过路径映射取值。
在前端:
参数都用 “/” 按照约定的顺序拼接在方法后面,格式为:/getInfos/1/10
后端使用,如:
@GetMapping("/employee/{id}")
public Result<EmployeeBO> getEmployeeById(
@PathVariable("id") final Integer id,
HttpServletRequest request,
HttpServletResponse response) {}
@GetMapping("/getInfos/{page}/{limit}")
public R page(@ApiParam(name = "page", value = "页码", required = true)
@PathVariable Integer page,
@ApiParam(name = "limit", value = "记录条数", required = true)
@PathVariable Integer limit) {}
两者的作用都是从request中接收请求的,将request里的参数的值绑定到control里的方法参数里的,都可以用于在Controller层接收前端传递的数据,区别在于,@RequestParam 是从request里面拿取值,而 @PathVariable 是从一个URI模板里面来填充。
当请求参数username不存在时会有异常发生,可以通过设置属性required=false解决。例如:
@RequestParam(value="userId",required=false) Integer userId
使用@RequestParam时,URL是这样的:http://host:port/path?参数名=参数值
http://www.test.com/user/getUserById?userId=1
使用@PathVariable时,URL是这样的:http://host:port/path/参数值
http://www.test.com/user/getUserById/2
不写的时候也可以获取到参数值,但是必须名称对应,参数可以省略不写。
http://localhost:8080/springmvc/hello/101?param1=10¶m2=20
@RequestMapping("/hello/{id}")
public String getDetails(@PathVariable(value="id") String id,
@RequestParam(value="param1", required=true) String param1,
@RequestParam(value="param2", required=false) String param2){
.......
}
public String getDetails(
@RequestParam(value="param1", required=true) String param1,
@RequestParam(value="param2", required=false) String param2){
...
}
@RestController :该注解为一个组合注解,结合了 @ResponseBody 和 @Controller,注解在类上,意味着该Controller的所有方法都默认加上了@ResponseBody。原来在@Controller中返回json需要@ResponseBody来配合,如果直接用@RestController替代@Controller就不需要再配置@ResponseBody,默认返回json格式。@RestController相当于它能实现将后端得到的数据在前端页面(网页)中以json串的形式传递,即将函数的返回值直接填入 HTTP 响应体中,是 REST 风格的控制器。
@Responsebody:支持将返回值放在response内,而不是一个页面,通常用户返回json数据,通常是在使用 @RequestMapping 后,返回值通常解析为跳转路径,加上@Responsebody 后返回结果不会被解析为跳转路径,而是直接写入HTTP 响应正文中。即将返回结果转换为JSON字符串。
@ResponseBody注解在转换日期类型时会默认把日期转换为时间戳(例如: date:2017-10-25 转换为 时间戳:15003323990)
@RequestBody:注解在参数前,表示接收JSON格式字符串参数。允许request的参数在request体中,而不是在直接连接在地址后面。
读取 Request 请求(可能是 POST,PUT,DELETE,GET 请求)的 body 部分并且Content-Type 为 application/json 格式的数据,接收到数据之后会自动将数据绑定到 Java 对象上去。系统会使用HttpMessageConverter或者自定义的HttpMessageConverter将请求的 body 中的 json 字符串转换为 java 对象。
注意:一个请求方法只可以有一个@RequestBody,但是可以有多个@RequestParam和@PathVariable。
post 请求,对象类型的参数
前端:放在请求体中的 payload / 负载
后端使用,如:
@PostMapping()
public R page(@ApiParam(name = "query", value = "查询对象", required = false)
@RequestBody Employee employee) {}
@RequestAttribute:获取HTTP的请求(request)对象属性值,可以被用于访问由过滤器或拦截器创建的、预先存在的请求属性。
@RequestHeader:请求的参数在header 信息中。
@RequestPart:支持对multipart/form-data 类型的参数进行参数绑定,支持的参数类型有 :MultipartFile,MulitpartResolver , Part 等参数,对于其他任意的参数类型,类似于 requestBody对参数的解析,属于Spring的MultipartResolver类。这个请求是通过http协议传输的。
注意:
@RequestParam 对于 multipart/form-data 也支持参数解析,区别在于处理字符串时不同。@RequestParam适用于name-valueString类型的请求域,@RequestPart适用于复杂的请求域(像JSON,XML)。
如果@RequestPart 注解的参数类型是MultipartFile 就必须配置 multipartResolver 解析器, 如果@RequestPart 注解的参数类型是Servlet 3.0 规范的 Part 参数,就不必配置multipartResolver 解析器。
@EnableWebMvc:在配置类中开启Web MVC的配置支持,如一些ViewResolver或者MessageConverter等,若无此句,重写WebMvcConfigurerAdapter方法(用于对SpringMVC的配置)。
@Controller:声明该类为SpringMVC中的Controller。
@ControllerAdvice:包含@Component,可以被扫描到,统一处理异常。通过该注解,我们可以将对于控制器的全局配置放置在同一个位置,注解了@Controller的类的方法可使用@ExceptionHandler、@InitBinder、@ModelAttribute注解到方法上,这对所有注解了 @RequestMapping的控制器内的方法有效。该注解可以把异常处理器应用到所有控制器,而不是单个控制器。借助该注解,我们可以实现:在独立的某个地方,比如单独一个类,定义一套对各种异常的处理机制,然后在类的签名加上注解@ControllerAdvice,统一对 不同阶段的、不同异常 进行处理。这就是统一异常处理的原理。
@ExceptionHandler:注解在方法上,表示遇到这个异常就执行以下方法。
@InitBinder:用来设置WebDataBinder,WebDataBinder用来自动绑定前台请求参数到Model中。
@ModelAttribute:本来的作用是绑定键值对到Model里,在@ControllerAdvice中是让全局的@RequestMapping都能获得在此处设置的键值对。
@Valid:用于校验
① 首先需要在实体类的相应字段上添加用于充当校验条件的注解,如:@Min,如下代码(age属于User类中的属性):
@Min(value = 18,message = "年龄不合法")
private Integer age;
② 其次在controller层的方法要校验的参数上添加@Valid注解,并且需要传入BindingResult对象,用于获取校验失败情况下的反馈信息,如下代码:
@PostMapping("/users")
public User addUser(@RequestBody @Valid User user, @ApiIgnore BindingResult bindingResult) {
//所有字段是否验证通过,true:是,false:否
if(bindingResult.hasErrors()){
//验证有误,返回结果到前端
return bindingResult.getFieldError().getDefaultMessage();
}
return userResposity.save(user);
}
bindingResult.getFieldError.getDefaultMessage()用于获取相应字段上添加的message中的内容,如:@Min注解中message属性的内容。
@NotNull和@NotEmpty和@NotBlank区别:
1.@NotNull:不能为null,但可以为empty
(“”," “,” “)
2.@NotEmpty:不能为null,而且长度必须大于0
(” “,” ")
3.@NotBlank:只能作用在String上,不能为null,而且调用trim()后,长度必须大于0
(“test”) 即:必须有实际字符
Objects.isNull() :判断对象是否为空
StringUtils.isEmpty() :判断字符串是否为空
CollectionUtils.isEmpty() :判断集合是否为空
isNUll()这种只能判断对象是否为空,即有或者没有,比如一个超市,有或者没有。
isEmpty()这种既判断对象是否为空,也判断内容是否为空,比如一个超市,有或者没有,且超市里的商品,有或者没有。
@Validated 和 @Valid的区别:
@Validated:提供了一个分组功能,可以在入参验证时,根据不同的分组采用不同的验证机制。@Valid:还没有吸收分组的功能。
@Validated:可以用在类、方法和方法参数上。但是不能用在成员属性(字段)上
@Valid:可以用在方法、构造函数、方法参数和成员属性(字段)上
两者是否能用于成员属性(字段)上直接影响能否提供嵌套验证的功能。
@Validated不能嵌套验证,@Valid能嵌套验证(需要在嵌套的实体上加上这个注解)。
四、SpringBoot常用注解
@SpringBootApplication:申明让spring boot自动给程序进行必要的配置。是springboot启动类,包括三个注解。@SpringBootApplication=@ComponentScan+@Configuration+@EnableAutoConfiguration:约定优于配置
@ComponentScan:表示程序启动时,自动扫描当前包及子包下所有类。
@Configuration:表示将该类作用springboot配置文件类。
@EnableAutoConfiguration:表示会在你开启某些功能的时候自动配置,告诉Spring Boot根据添加的jar依赖猜测你想如何配置Spring。
@JsonBackReference:解决嵌套外链问题。
@RepositoryRestResourcepublic:配合spring-boot-starter-data-rest使用。
@suppresswarnings:抑制警告
@Modifying:如果是增,改,删加上此注解
1:方法的返回值应该是int,表示更新语句所影响的行数。
2:在调用的地方必须加事务,没有事务不能正常执行。
@Transactional:是声明式事务管理编程中使用的注解。如果类加了这个注解,那么这个类里面的方法抛出异常,就会回滚,数据库里面的数据也会回滚。
@Transactional注解中如果不配置rollbackFor属性,那么事物只会在遇到RuntimeException的时候才会回滚,加上rollbackFor=Exception.class,可以让事物在遇到非运行时异常时也回滚。
当作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。
注意事项:
1.使用必须是java5或者以上;
2.@Transactional应该只被应用在public修饰的可见类或者方法上面,如果在private,protected上使用的话,不会报错但是事务会不能生效;
3.建议将该注解使用在具体的类或者方法上,不要注解在接口上面,因为注解是不能被继承,这样造成编程上会相当麻烦。
@Query: 自定义查询语句 JPQL
@Mapper:Mapper类上面添加注解@Mapper,这种方式要求每一个mapper类都需要添加此注解。
@MapperScan(“com.xxx.user.mapper”):扫描mapper类的注解,就不用在每个mapper类上加@MapperScan了。
@MapperScan和@ComponentScan都是扫描包,区别:
@ComponentScan是组件扫描注解,用来扫描@Controller @Service @Repository这类,主要就是定义扫描的路径从中找出标志了需要装配的类到Spring容器中。这两个注解是可以同时使用的。
@Cacheable(value = “key” ):针对方法配置,能够根据方法的请求参数对其结果进行缓存。
@CachePut :针对方法配置,能够根据方法的请求参数对其结果进行缓存,和 @Cacheable 不同的是,它每次都会触发真实方法的调用。
@CachEvict :针对方法配置,能够根据一定的条件对缓存进行清空。
@CacheEvict 作用和配置方法:
参数 解释 example
value:缓存的名称,在 spring 配置文件中定义,必须指定至少一个 ,如:@Cacheable(value=”mycache”)
@Cacheable(value={”cache1”,”cache2”}
key:缓存的 key,可以为空,如果指定要按照 SpEL 表达式编写,如果不指定,则缺省按照方法的所有参数进行组合,如@Cacheable(value=”testcache”,key=”#userName”)
condition:缓存的条件,可以为空,使用 SpEL 编写,返回 true 或者 false,只有为 true 才进行缓存,如@Cacheable(value=”testcache”,condition=”#userName.length()>2”)
@CrossOrigin:解决CORS跨域
@CrossOrigin(origins = "\*",maxAge = 3600)
origin="*"代表所有域名都可访问
maxAge飞行前响应的缓存持续时间的最大年龄,简单来说就是Cookie的有效期 单位为秒。
若maxAge是负数,则代表为临时Cookie,不会被持久化,Cookie信息保存在浏览器内存中,浏览器关闭Cookie就消失。
条件注解,@ConditionalOnXXX 中的所有条件都满足,才会加载:
@ConditionalOnBean: 当容器里有指定 Bean 的条件下
@ConditionalOnClass: 当类路径下有指定类的条件下
@ConditionalOnMissingBean: 当容器里没有指定 Bean 的情况下
@ConditionalOnSingleCandidate: 当指定 Bean 在容器中只有一个,或者虽然有多个但是指定首选 Bean
@ConditionalOnMissingClass: 当类路径下没有指定类的条件下
@ConditionalOnProperty: 指定的属性是否有指定的值
@ConditionalOnResource: 类路径是否有指定的值
@ConditionalOnExpression:基于 SpEL 表达式作为判断条件
@ConditionalOnJava:基于 Java 版本作为判断条件
@ConditionalOnJndi: 在 JNDI 存在的条件下差在指定的位置
@ConditionalOnNotWebApplication: 当前项目不是 Web 项目的条件下
@ConditionalOnWebApplication: 当前项目是 Web 项 目的条件下
五、Lombok常用注解
@CrossOrigin:@EqualsAndHashCode:实现equals()方法和hashCode()方法。
1. 它默认使用非静态,非瞬态的属性
2. 可通过参数exclude排除一些属性
3. 可通过参数of指定仅使用哪些属性
4. 它默认仅使用该类中定义的属性且不调用父类的方法
5. 可通过callSuper=true解决上一点问题。让其生成的方法中调用父类的方法。
@ToString:自动重写toString方法,默认情况下,会输出类名、所有属性(会按照属性定义顺序),用逗号来分割。
@Data :注解在类上;提供类所有属性的setter/getter方法,如为final属性,则不会为该属性生成setter方法。此外还提供了equals、canEqual、hashCode、toString 方法
@Setter:注解在属性上;为属性提供 setting 方法
@Getter:注解在属性上;为属性提供 getting 方法
@Log4j :注解在类上;为类提供一个 属性名为log 的 log4j 日志对象
@NoArgsConstructor:注解在类上;为类提供一个无参的构造方法
@AllArgsConstructor:注解在类上;为类提供一个全参的构造方法
@RequiredArgsConstructor:注解在类上;为类提供一个部分参数的构造方法,会生成一个包含常量,和标识了NotNull的变量的构造方法。生成的构造方法是私有的private。
@NonNull: 注解在属性或构造器上,Lombok会生成一个非空的声明,可用于校验参数,能帮助避免空指针。
@NotNull和@NonNull的区别:
@NotNull在类字段中使用,表示该字段不能为空。它是 JSR303(Bean的校验框架)的注解。在调用controller的方法中加入@Valid就可以验证该方法参数中该类的对应属性是否为空,如果为空,注解中的提示信息会保存在result中。
@NonNull在方法或构造函数的参数上使用,表示该参数不能为空。是JSR 305(缺陷检查框架)的注解,是告诉编译器这个域不可能为空,当代码检查有空值时会给出一个风险警告,目前这个注解只有IDEA支持。
@Cleanup:关闭流,如果需要释放的资源没有对应的close方法,而是用其他的方法进行资源的释放,可以使用@Cleanup(“methodName”)来指明需要调用的方法名称。
@Synchronized:对象同步
@SneakyThrows:抛出异常
@Builder:声明实体,表示可以进行Builder方式初始化,它提供在设计数据实体时,对外保持private setter,而对属性的赋值采用Builder的方式,这种方式最优雅,也更符合封装的原则,不对外公开属性的写操作!@Builder注解修饰类时,该类将没有无参构造方法。如果要无参构造,就可以加上@NoArgsConstructor,但是只加这个注解,编译会报错,所以还要加上@AllArgsConstructor。
@Slf4j:日志输出,一般会在项目每个类的开头加入该注解,如果不写下面这段代码,并且想用log。
private final Logger logger = LoggerFactory.getLogger(当前类名.class);
六、自定义注解的元注解
@Target:说明了Annotation所修饰的对象范围。
@Retention:定义了该Annotation被保留的时间长短。
@Documented:用于描述其它类型的annotation应该被作为被标注的程序成员的公共API。
@Inherited:表示某个被标注的类型是被继承的。
七、swagger常用注解
@Api:协议集描述,用于controller类上,表示标识这个类是swagger的资源
tags–表示说明
value–也是说明,可以使用tags替代
@ApiOperation:协议描述,用在controller的方法上,表示一个http请求的操作
@ApiResponses:Response集,用在controller的方法上
@ApiResponse:Response,用在 @ApiResponses里边
@ApiImplicitParams:用在controller的方法上,包含多个 @ApiImplicitParam
@ApiImplicitParam:用在@ApiImplicitParams的方法里边,表示单独的请求参数
@ApiModel:描述返回对象的意义,用在返回对象类上,用于参数用实体类接收
注意:描述一定要能识别,各个对象的描述不能相同。
@ApiModelProperty:用于方法,字段,表示对model属性的说明或者数据操作更改
value–字段说明
name–重写属性名字
dataType–重写属性类型
required–是否必填
example–举例说明
hidden–隐藏
@ApiParam:用于方法,参数,字段说明,表示对参数的添加元数据(说明或是否必填等)
@ApiIgnore:注解在类或者方法上,表示在swagger页面,忽略掉这个类或者方法,不显示。
八、Zuul注解
@EnableZuulServer:高配版本
@EnableZuulProxy:低配版本
如果不想让高版本多出的过滤器生效,可用低配版本注解。
低配版本注解更适合自定义过滤器,因为经过的过滤器少,性能会比较高。
@EnableZuulProxy简单理解为@EnableZuulServer的增强版,当Zuul与Eureka、Ribbon等组件配合使用时,我们使用@EnableZuulProxy。
九、SpringCloud常用注解
@EnableEurekaServer: 该注解表明应用为Eureka服务,也可以联合多个服务作为集群,对外提供服务注册及发现功能。注解在Eureka服务的启动类上。
@FeignClient: FeignClient注解被@Target(ElementType.TYPE)修饰,表示FeignClient注解的作用目标在接口上,分布式架构服务之间,各子模块系统内部通信的核心。一般在一个系统调用另一个系统的接口时使用。该注解一般创建在 interface 接口中,然后在业务类@Autowired进去使用非常简单方便。
声明接口之后,在代码中通过@Resource注入之后即可使用。
@FeignClient标签的常用属性如下:
name:指定FeignClient的名称,如果项目使用了Ribbon,name属性会作为微服务的名称,用于服务发现
url: url一般用于调试,可以手动指定@FeignClient调用的地址
decode404:当发生http 404错误时,如果该字段位true,会调用decoder进行解码,否则抛出FeignException
configuration: Feign配置类,可以自定义Feign的Encoder、Decoder、LogLevel、Contract
fallback: 定义容错的处理类,当调用远程接口失败或超时时,会调用对应接口的容错逻辑,fallback指定的类必须实现@FeignClient标记的接口。(处理类实现接口)
fallbackFactory: 工厂类,用于生成fallback类示例,通过这个属性我们可以实现每个接口通用的容错逻辑,减少重复的代码
path: 定义当前FeignClient的统一前缀
使用fallback属性时,需要使用@Component注解,保证fallback类被Spring容器扫描到。
如:
@Component
public class EmployeeClientFallBack implements EmployeeClient {
private static final Logger logger = LoggerFactory.getLogger(WorkbenchController.class);
@Override
public void saveEmployee(@RequestBody EmployeeParam param) {
logger.info("保存员工信息失败");
}
}
@FeignClient(name ="xxx-employee",fallback = EmployeeClientFallBack.class)
public interface EmployeeClient {
@RequestMapping(value = "/employee/save", method = RequestMethod.POST,produces = "application/json; charset=UTF-8")
void saveEmployee(@RequestBody EmployeeParam param);
}
@ComponentScan:表示将该类自动发现并注册bean 可以自动收集所有的spring组件
@EnableEurekaClient:开启eureka客户端,可以调用在eureka上注册的服务
@EnableDiscoveryClient:不仅可以开启eureka客户端,还有consul、zookeeper,表示当前服务是一个Eureka的客户端。注解在Eureka服务外的其他服务的启动类上,这样这个服务就会被注册到注册中心。
@EnableDiscoveryClient注解基于spring-cloud-common依赖,@EnableEurekaClient注解基于spring-cloud-netflix依赖,如果选用的注册中心是eureka,那么就推荐@EnableEurekaClient,如果是其他的注册中心,那么推荐使用@EnableDiscoveryClient。
@EnableHystrix:表示启动断路器,断路器依赖于服务注册和发现。
@HystrixCommand:容错保护,配合@EnableHystrix
@EnableFeignClients: 开启负载均衡 包装了Ribbon。
@LoadBalanced:开启负载均衡(客户端),配合@EnableFeignClients,标注在javaconfig文件。
@PropertySource:扫描外部资源文件properties 用来配置javabean,标注在service方法。
@StreamListener: 设置监听信道,用于接受来自消息队列的消息。
@input : 设置输入信道名称。应用程序通过它接收消息,不设置参数,通道名称就默认为方法名。
@output:设置输出信道名称。应用程序通过它发布消息,不设置参数,通道名称就默认为方法名。
@SendTo:配合@StreamListener使用,在收到信息后发送反馈信息。
@EnableBinding:注解用于绑定一个或者多个接口作为参数。
十、Mybatis-Plus常用注解
@TableField:映射非主键字段。
value:是映射的字段名(驼峰命名方式,该值可无)。
exist:表示是否为数据库表字段(默认true存在,false 不存在),如果实体类中的成员变量在数据库中没有对应的字段,则可以使用exist,一般VO,DTO中用的比较多。
select:表示是否查询该字段。
condition:预处理 WHERE 实体条件自定义运算规则。
fill:字段填充标记 ( FieldFill, 配合自动填充使用 )
fill值如下:
DEFAULT:默认不处理
INSERT:插入填充字段
UPDATE:更新填充字段
INSERT_UPDATE:插入和更新填充字段
还有很多属性未介绍,打开注解查看即可。有详细注释。
@TableName:映射数据库表名。在你创建的实体类类名与数据库表明不同时可以用@TableName(value = “数据库表名”)。
@TableId:设置主键映射。若变量id与数据库的主键字段名称不一样,就可以用value属性value=“id”。
value:映射注解字段的名字。
type:设置主键的类型,主键的生成策略。
type的类型:
INPUT:如果开发者没有手动赋值,则数据库通过自增的方式给主键赋值。
AUTO:数据库自增,无需赋值。若开发者自己赋值了,还是用数据库自增给的id。
ASSIGN_ID:MP自动赋值。雪花算法,随机生成ID。
ASSIGN_UUID:主键的数据类型必须是String,自动生成UUID进行赋值。
@Version:标记乐观锁,通过version字段保证数据的安全性,当修改数据的时候,会以version作为条件,当条件成立的时候才会修改成功(防止多线程多次更改一个数据)。
version = 1
线程 1:update … set version = 2 where version = 1
线程 2:update … set version = 2 where version = 1
@EnumValue:通枚举类注解。
value:逻辑未删除值
delval:逻辑删除值
@TableLogic:表字段逻辑处理注解(逻辑删除)。
十一、Jackson常用注解
Jackson提供了一系列注解,方便对JSON序列化和反序列化进行控制
@JsonProperty:注解在属性上,作用是把该属性的名称序列化为另外一个名称,如把trueName属性序列化为name,@JsonProperty(“name”)。默认情况下映射的JSON属性与注解的属性名称相同,不过可以使用该注解的value值修改JSON属性名,该注解还有一个index属性指定生成JSON属性的顺序。例如我们有个json字符串为{“user_name”:”aaa”},
而java中命名要遵循驼峰规则,则为userName,这时通过@JsonProperty 注解来指定两者的映射规则即可。这个注解也比较常用。
@JsonProperty("user_name")
private String userName;
@JsonIgnore:注解在属性上,这样该属性就不会被Jackson序列化和反序列化。不管是将 java 对象转换成 json 字符串,还是将 json 字符串转换成 java 对象,Jackson 在处理时忽略该注解标注的 java pojo 属性,即转成json时不会返回前端。
@JsonIgnoreProperties:注解在类上,忽略该注解指定的多个的 java pojo 属性。和 @JsonIgnore 的作用相同,都是告诉 Jackson 该忽略哪些属性,不同之处是 @JsonIgnoreProperties 是类级别的,并且可以同时指定多个属性。
@JsonFormat:出参格式化,注解在属性上,作用是把Date类型直接转化为想要的格式,
如:
@JsonFormat(pattern = “yyyy-MM-dd HH:mm:ss”, timezone = “GMT+8”)
LocalDateTime createTime;
@JsonIgnoreProperties:类注解。在序列化为JSON的时候,@JsonIgnoreProperties({“prop1”, “prop2”})会忽略pro1和pro2两个属性。在从JSON反序列化为Java类的时候,@JsonIgnoreProperties(ignoreUnknown=true)会忽略所有没有Getter和Setter的属性。该注解在Java类和JSON不完全匹配的时候很有用。
@JsonIgnoreType:注解在类上,当其他类有该类作为属性时,该属性将被忽略。
@JsonPropertyOrder:和@JsonProperty的index属性类似,指定属性序列化时的顺序。
@JsonRootName:注解用于指定JSON根属性的名称。
@JsonSetter:标注于 setter 方法上,类似 @JsonProperty ,也可以解决 json 键名称和 java pojo 字段名称不匹配的问题。
@JsonInclude:注解在类或者属性上,在将 java pojo 对象序列化成为 json 字符串时,使用 @JsonInclude 注解可以控制在哪些情况下才将被注解的属性转换成 json,例如只有属性不为 null 时。
如:
@JsonInclude(JsonInclude.Include.NON_NULL)
public class SellerInfoEntity {}
@JsonInclude(JsonInclude.Include.NON_EMPTY)
private String password;
@DateTimeFormat:入参格式化,用于接收前端传的时间值自动转换,可以是Date,可以是string,注意 格式要一样,如:yyyy-MM-dd,yyyy/MM/ddd
@DateTimeFormat(pattern=“yyyy-MM-dd”)
@JsonSerialize:注解在属性或者getter方法上,用于在序列化时嵌入开发者自定义的代码。比如将一个Date类型的变量转换成Long类型,或是序列化一个double时在其后面限制两位小数点。
举个例子,比如一张表中的时间,数据库中存储的是yyy-mm-dd hh:mm:ss 这样的形式,而前段需要的是精确到秒的格式(时间戳,如1579331933000ms),那不可能直接把这种格式的数据直接返回给前端吧?
那怎么办?从数据库查出来的时候去转换一下?可以,但是问题又来了,那我在A方法中查询要转换一下,B方法中要转换一下,这样就会导致代码冗余。
除了使用自定义工具类,还有一种方法更直接使用@JsonSerialize(com.fasterxml.jackson.databind.annotation.JsonSerialize)使用步骤:
1.在实体类中在要转换的字段上加上该注解,如下:
/** 订单创建时间 */
@JsonSerialize(using = DateToLongSerializer.class)
private Date createTiem;
2.并指定一个格式化的类。如下:
public class DateToLongSerializer extends JsonSerializer<Date> {
@Override
public void serialize(Date date, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException {
jsonGenerator.writeNumber(date.getTime() / 1000);
}
}
十二、Hibernate Validator常用注解
| 验证注解 | 验证数据类型 | 说明 |
|---|---|---|
| @AssertFalse | Bool | 元素为 false |
| @AssertTrue | Bool | 元素为 true |
| @NotNull | 任意类型 | 元素值不为 Null |
| @Null | 任意类型 | 元素值为 Null |
| @Min(value = 最小值) | BigDecimal、BigInteger、byte、short、int、long 等 Number 或 CharSequence (数字)子类型 | 元素值需大于等于指定值 |
| @Max(value = 最大值) | 同 @Min | 元素值需小于等于指定值 |
| @DecimalMin(value = 最小值) | 同 @Min | 元素值需大于等于指定值 |
| @DecimalMax(value = 最大值) | 同 @Min | 元素值需小于等于指定值 |
| @Digits(integer = 整数位数, fraction = 小数位数) | 同 @Min | 元素值整数位、小数位需小于对应指定值 |
| @Size(min = 最小值, max = 最大值) | String、Collection、Array 等 | 元素值的字符长度/集合大小需在指定的区间范围内 |
| @Past | DATE、Calendar、Time 等日期 | 元素值需在指定时间之前 |
| @Future | 同 @Past | 元素值需在指定时间之后 |
| @NotBlank | String 等 CharSequence 子类型 | 元素值不为空串(字符串不为 Null 且去除首尾空格后长度不为 0) |
| @Length(min = 最小值, max = 最大值) | String 等 | 元素值长度在指定区间范围内 |
| @NotEmpty | String、Collection、Array 等 | 元素值不为 Null 且长度不为 0 |
| @Range(min = 最小值, max = 最大值) | BigDecimal、BigInteger、byte、short、int、long 等 Number 或 CharSequence (数字)子类型 | 元素值在指定区间范围内 |
| @Email(regexp = 正则式, flag = 标志的模式) | String 等 | 元素值为电子邮箱格式,可通过 regexp、flag 属性指定格式 |
| @Pattern(regexp = 正则式, flag = 标志的模式) | String 等 | 元素值与指定的正则式匹配 |
| @Valid | 任何非原子类型 | 级联验证(常用于对象中对象属性的属性值验证) |
十三、Java其他注解
@Deprecated:注解在类或方法上,表示此方法或类不再建议使用,调用时也会出现删除线,但并不代表不能用,只是说,不推荐使用,因为还有更好的方法可以调用,版本升级之后可能就不支持旧的方法了。
@FunctionalInterface:函数式接口,Java8的注解,这个接口里面只能有一个抽象方法。函数式接口主要用在Lambda表达式和方法引用上。
1)接口有且仅有一个抽象方法 void sub();
2)允许定义静态方法 public static void staticMethod(){}
3)允许定义默认方法 default void defaultMethod(){}
4)允许java.lang.Object中的public方法 public boolean equals(Object var1);
该注解不是必须的,如果一个接口符合"函数式接口"定义,那么加不加该注解都没有影响。加上该注解能够更好地让编译器进行检查。如果你编写的不是函数式接口,但是加上了@FunctionInterface,那么编译器会报错。
如:
@FunctionalInterface
interface GreetingService{
void sayMessage(String message);
}
这样的接口就可以使用Lambda表达式来表示该接口的一个实现
GreetingService greetingService = message → System.our.println("Hello" + message);
@JsonUnwrapped:扁平化对象,对象里面嵌套多个对象,返回前端都是分开,这个注解可以让他们不分开,用最外面这个对象返回,如:
@Getter
@Setter
@ToString
public class Account {
private Location location;
private PersonInfo personInfo;
@Getter
@Setter
@ToString
public static class Location {
private String provinceName;
private String countyName;
}
@Getter
@Setter
@ToString
public static class PersonInfo {
private String userName;
private String fullName;
}
}
未扁平化之前:
{
"location": {
"provinceName": "四川",
"countyName": "达州"
},
"personInfo": {
"userName": "3232",
"fullName": "lisi"
}
}
扁平对象之后:
@Getter
@Setter
@ToString
public class Account {
@JsonUnwrapped
private Location location;
@JsonUnwrapped
private PersonInfo personInfo;
......
}
{
"provinceName": "四川",
"countyName": "达州",
"userName": "3232",
"fullName": "lisi"
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









