









出现了三个关键要素:人类监督的必要性、用于训练数据创建的精心规划的数据拓扑和管道,以及旨在从语言模型中引出特定行为(例如高级推理)的数据。
介绍
在训练模型中,平衡数据数量和质量的挑战非常重要。大型语言模型 (LLM) 通过生成合成数据提供以数据为中心的解决方案。然而,最近的一项研究表明,该领域的研究缺乏统一的框架,并且仍然很肤浅。
本文在合成数据生成的通用工作流程中组织相关研究,强调现有的研究差距并提出未来的研究方向。
目标是引导学术界和商业界对 LLM 驱动的合成数据生成能力和应用进行更彻底的研究。
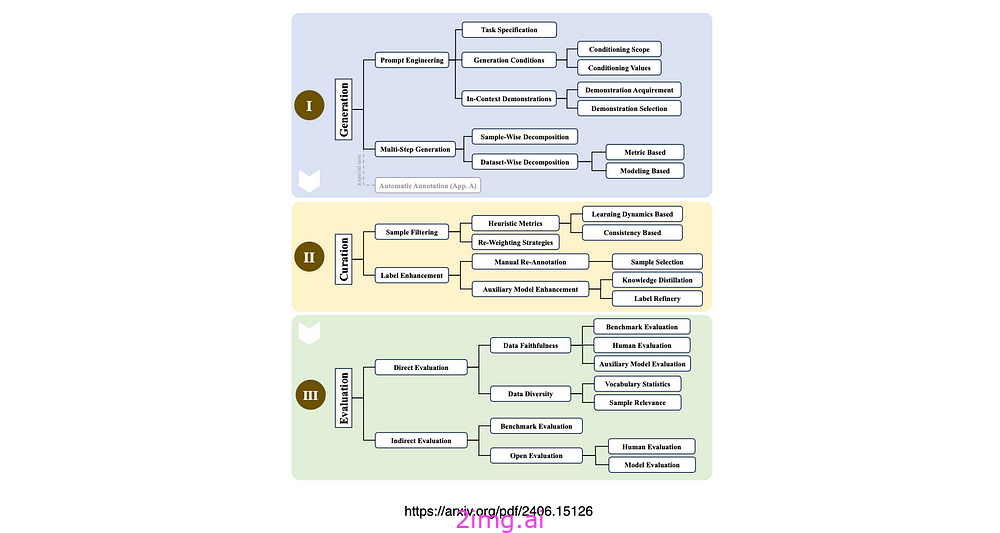
以上是 LLM 驱动的合成数据生成、管理和评估的分类。
小故事和 Phi-3
微软使用Tiny Stories训练 SLM 以及Phi-3模型的训练方式强调了数据设计对模型行为的影响,以及数据质量对于有效的模型学习至关重要。
LLM 使我们能够通过数据操作主动塑造模型的学习内容,大大提高模型训练的有效性和控制力。
截至 2024 年 6 月,Hugging Face 上有超过 300 个标记为合成的数据集。许多主流 LLM,例如 Alpaca、Vicuna、OpenHermes 2.5 和 Openchat 3.5 都利用高质量的合成数据进行训练。
人为干预
数据对于模型智能至关重要,如果没有人工监督就无法完全生成。
合成数据可能会引入噪音和有害信息,这可能会毒害模型并导致崩溃。
由于固有的偏见,LLM 无法自我纠正,可能会偏离预期目标。因此,一个用于注释和验证的人性化交互系统至关重要。目前,数据生产中的人机协作尚无标准化框架。
设计这种系统时,应充分了解人类的优势和局限性,并遵循以人为本的原则。
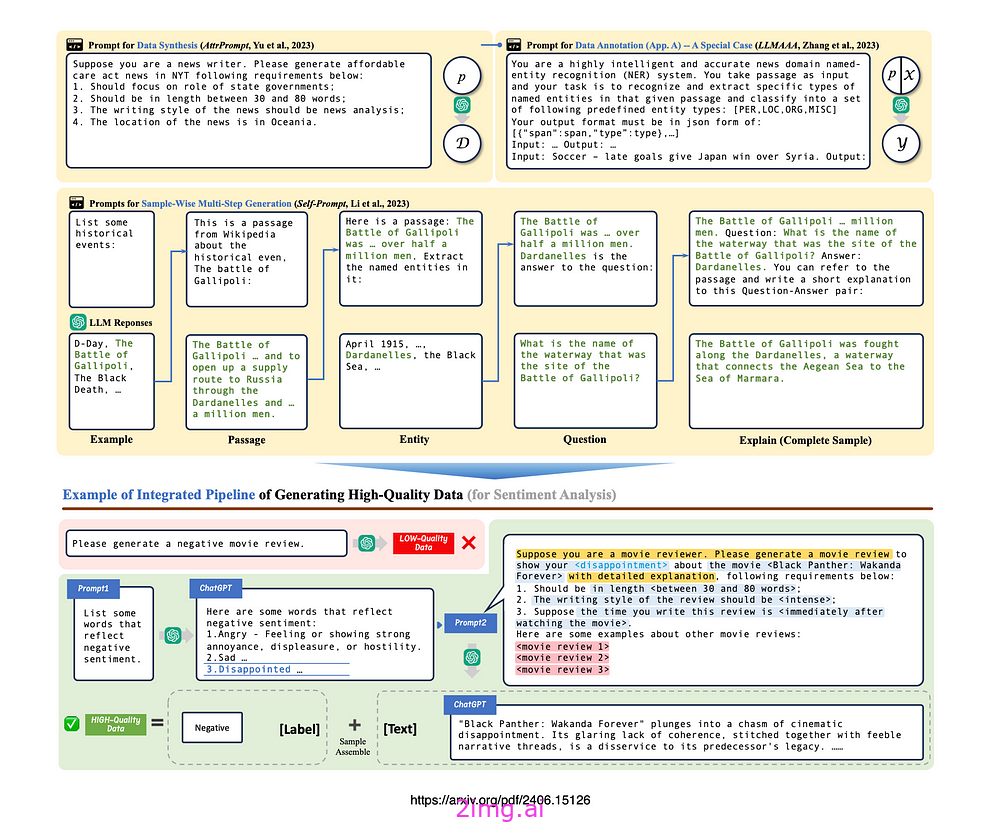
以上示例提示了数据合成、注释、多步骤生成和集成管道。
主要考虑因素包括:
- 确保 LLM 生成的信息的可读性和可解释性,以方便人类理解。
- 实施上游知识丰富或过滤,以优化人力资源利用并减少花在低价值任务上的时间。
- 添加引人入胜的交互功能,使数据处理任务更加有趣并吸引更广泛的受众。
在传统的众包注释中,工作人员会收到一本详细说明任务目的、数据解释和背景知识的代码本,以便更好地了解他们的工作。
同样,对于 LLM 驱动的数据生成,任务规范至关重要,可以包括角色扮演、格式澄清和知识增强。
语境
像这样的简单提示suppose you are a {xxx}可以通过设置正确的上下文来显著提高 LLM 的性能。这种方法让人想起了另一项研究,研究人员提出了一种新的角色驱动的数据合成方法,该方法使用大型语言模型 (LLM) 中的不同视角来创建不同的合成数据。
为了大规模支持这种方法,他们引入了Persona Hub,这是一个从网络数据中自动收集的10 亿个不同角色的集合。
忠诚
为了确保有效的监督,生成的数据必须在逻辑上和语法上连贯。
然而,大型语言模型 (LLM) 中的幻觉和肥尾知识分布等固有问题可能会引入大量噪音。这通常会导致事实错误、标签错误或内容不相关,尤其是在生成较长、复杂或特定领域的数据时。
多样性
多样性是指生成的数据的变化,例如文本长度、主题和写作风格的差异。
创建反映现实世界数据多样性的合成样本至关重要,有助于防止模型训练或评估期间的过度拟合和偏差。
然而,大型语言模型 (LLM) 固有的偏见往往导致内容单调、缺乏多样性,限制了其在下游任务中的实用性。
最后
合成数据的目的不是向目标模型注入知识,而是针对某些角色和特殊能力(如高级推理或任务分解)训练模型。
通过在结构良好的数据拓扑中结合强大的数据发现和数据设计实践,创建合成数据的过程变得更加高效、准确且符合现实需求。
这一基础层对于生成能够有效训练和验证机器学习模型的高质量合成数据至关重要。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











