











图像由 DALL-E 生成
你有没有想过人工智能模型是如何“思考”的?想象一下窥视机器的大脑并观察齿轮的转动。这正是 Anthropic 的一篇开创性论文所探讨的内容。这项研究题为“扩展单义性:从克劳德的 3 首十四行诗中提取可解释的特征”,深入研究了对人工智能思维过程的理解和解释。
研究人员设法从 Claude 3 Sonnet 模型中提取出一些特征,这些特征可以展示它对名人、城市甚至软件安全漏洞的看法。这就像窥视人工智能的思维,揭示它理解并用于决策的概念。
研究论文概述
在这篇论文中,包括 Adly Templeton、Tom Conerly、Jonathan Marcus 等人在内的 Anthropic 团队着手让人工智能模型更加透明。他们专注于中型人工智能模型 Claude 3 Sonnet,旨在扩大规模单义性——本质上确保模型中的每个特征都有明确的单一含义。
但是,为什么扩展单义性如此重要?单义性到底是什么?我们很快就会深入探讨这个问题。
研究的重要性
理解和解释 AI 模型中的特征至关重要。它有助于我们了解这些模型如何做出决策,从而使其更可靠且更易于改进。当我们能够解释这些特征时,调试、改进和优化 AI 模型就会变得更加容易。
这项研究对人工智能安全也有重要意义。通过识别与有害行为(如偏见、欺骗或危险内容)相关的特征,我们可以开发降低这些风险的方法。这一点尤其重要,因为人工智能系统越来越融入日常生活,道德考量和安全至关重要。
这项研究的主要贡献之一是向我们展示了如何理解大型语言模型 (LLM) 的“思维”。通过提取和解释特征,我们可以深入了解这些复杂模型的内部工作原理。这有助于我们了解它们做出某些决定的原因,从而提供一种窥探其“思维过程”的方法。
背景
让我们回顾一下前面提到的一些奇怪的术语:
单义性
单义性就像是一栋大楼里的每个锁都有一把特定的钥匙。想象一下,这栋大楼代表着人工智能模型;每个锁都是模型理解的一个特征或概念。有了单义性,每把钥匙(特征)只能完美地适合一把锁(概念)。这意味着每当使用一把特定的钥匙时,它总是能打开同一个锁。这种一致性有助于我们准确理解模型在做决策时在想什么,因为我们知道哪把钥匙能打开哪把锁。
稀疏自动编码器
稀疏自动编码器就像一个高效的侦探。想象一下,你有一个大而杂乱的房间(数据),里面散落着许多物品。侦探的工作是找到几个关键物品(重要特征),讲述房间里发生的事情的全过程。“稀疏”意味着这位侦探试图用尽可能少的线索来解开谜团,只关注最重要的证据。在这项研究中,稀疏自动编码器就像这位侦探一样,帮助从人工智能模型中识别和提取清晰、易懂的特征,从而更容易看到里面发生了什么。
以下是Andrew Ng 关于自动编码器的一些有用的讲义,可供您了解更多信息。
先前的工作
先前的研究通过探索如何使用稀疏自动编码器从较小的 AI 模型中提取可解释的特征奠定了基础。这些研究表明,稀疏自动编码器可以有效地识别较简单模型中的有意义特征。然而,人们非常担心这种方法是否可以扩展到更大、更复杂的模型,如 Claude 3 Sonnet。
早期的研究重点是证明稀疏自动编码器能够识别和表示较小模型中的关键特征。他们成功地证明了提取的特征既有意义又可解释。然而,主要的限制是这些技术只在较简单的模型上进行了测试。扩大规模至关重要,因为像 Claude 3 Sonnet 这样的大型模型可以处理更复杂的数据和任务,这使得提取的特征更难保持相同的清晰度和实用性。
本研究以这些基础为基础,旨在将这些方法扩展到更先进的人工智能系统。研究人员应用并调整了稀疏自动编码器,以处理更大模型的更高复杂性和维度。通过解决扩展挑战,本研究力求确保即使在更复杂的模型中,提取的特征仍然清晰且有用,从而促进我们对人工智能决策过程的理解和解释。
缩放稀疏自编码器
将稀疏自动编码器扩展为与 Claude 3 Sonnet 等大型模型配合使用,就像从小型本地图书馆升级为管理庞大的国家档案馆一样。适用于较小馆藏的技术需要进行调整,以处理更大数据集的规模和复杂性。
稀疏自动编码器旨在识别和表示数据中的关键特征,同时保持活跃特征的数量较低,就像图书管理员确切地知道数千本书中的哪几本可以回答您的问题一样。

图像由 DALL-E 生成
两个关键假设指导了这一扩展:
线性表示假设
想象一下一张巨大的夜空地图,其中每颗星星都代表人工智能理解的一个概念。该假设表明,每个概念(或星星)在模型的激活空间中都以特定的方向排列。本质上,这就像说,如果你在空间中画一条线直接指向某颗特定的星星,你就可以通过它的方向唯一地识别出那颗星星。
叠加假设
基于夜空类比,该假设就像是说人工智能可以使用这些方向来绘制比使用几乎垂直的线所绘制的方向更多的星星。这允许人工智能通过找到组合这些方向的独特方式来有效地打包信息,就像通过仔细地将它们映射到不同的层中来将更多的星星放入天空中一样。
通过应用这些假设,研究人员可以有效地扩展稀疏自动编码器,使其与 Claude 3 Sonnet 等更大的模型配合使用,从而使它们能够捕获和表示数据中的简单和复杂特征。
训练模型
想象一下,尝试训练一群侦探筛选庞大的图书馆以找到关键证据。这与研究人员在研究 Claude 3 Sonnet(一种复杂的 AI 模型)时使用稀疏自动编码器 (SAE) 所做的工作类似。他们必须调整这些侦探的训练技术,以处理由 Claude 3 Sonnet 模型代表的更大、更复杂的数据集。
研究人员决定将 SAE 应用于模型中间层的残差流激活。将中间层视为侦探调查中的关键检查点,在这里可以找到许多有趣的抽象线索。他们之所以选择这一点,是因为:
- 尺寸更小:残差流比其他层更小,因此计算资源更便宜。
- 减轻跨层叠加:这指的是不同层的信号混合在一起的问题,就像味道混合在一起而难以区分一样。
- 丰富的抽象特征:中间层可能包含有趣的高级概念。
该团队训练了三个版本的 SAE,它们具有不同的处理特征的能力:1M 特征、4M 特征和 34M 特征。对于每个 SAE,目标是在保持准确性的同时保持较低的活动特征数量:
- 活跃特征:平均而言,任何时候都有少于 300 个特征处于活跃状态,可以解释模型激活中至少 65% 的差异。
- 无效功能:这些功能永远不会被激活。他们发现,在 1M SAE 中,无效功能约占 2%,在 4M SAE 中,无效功能约占 35%,在 34M SAE 中,无效功能约占 65%。未来的改进旨在减少这些数字。
缩放定律:优化训练
目标是使用结合均方误差 (MSE) 和 L1 惩罚的损失函数来平衡重建精度和活动特征的数量。
此外,他们还应用了缩放定律,这有助于确定在给定的计算预算内最佳的训练步骤和特征数量。本质上,缩放定律告诉我们,随着我们增加计算资源,特征和训练步骤的数量应该按照可预测的模式增加,通常遵循幂律。
随着计算预算的增加,特征和训练步骤的最佳数量会根据幂律进行扩展。
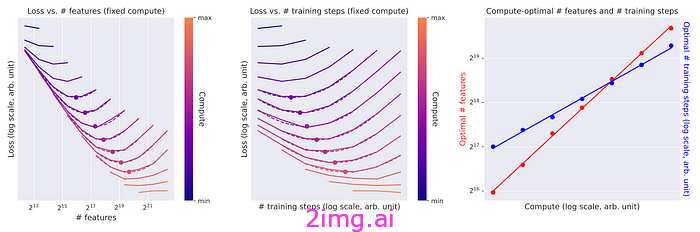
特征损失和训练步骤图——图片摘自“扩展单义性:从克劳德 3 首十四行诗中提取可解释的特征”
他们发现最佳学习率也遵循幂律趋势,帮助他们为更长时间的运行选择合适的学习率。
数学基础
稀疏自动编码器模型背后的核心数学原理对于理解它如何将激活分解为可解释的特征至关重要。
编码器
编码器使用学习到的线性变换和 ReLU 非线性将输入激活转换为更高维空间。这表示为:
![]()
编码器功能 — 作者提供的图片
这里,W^ enc 和b^ enc 是编码器的权重和偏差,fi ( x ) 表示特征i的激活。
解码器
解码器尝试使用另一个线性变换从特征中重建原始激活:
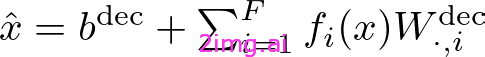
解码器功能 — 作者提供的图片
W^ dec 和b^ dec 是解码器权重和偏差。项fi ( x ) W^ dec 表示特征i对重建的贡献。
损失
模型经过训练,可以最小化重建误差和稀疏性惩罚的组合:
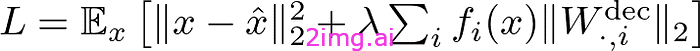
损失函数——作者提供的图片
该损失函数确保重建的准确性(最小化误差的 L2 范数),同时保持活动特征的数量较低(由具有系数λ的 L1 正则化项强制执行)。
可解释的特征
研究揭示了克劳德 3 十四行模型中各种可解释的特征,涵盖抽象和具体概念。这些特征为了解该模型的内部流程和决策模式提供了见解。
抽象特征:这些特征包括模型理解并用于处理信息的高级概念。例如情绪、意图等主题,以及科学或技术等更广泛的类别。
具体特征:这些特征更具体、更具体,例如名人姓名、地理位置或特定物体。这些特征可以直接与可识别的现实世界实体相关联。
例如,该模型具有在提及知名人物时激活的功能。可能有一个专门针对“阿尔伯特·爱因斯坦”的功能,只要文本提到他或他在物理学方面的工作,该功能就会激活。此功能可帮助模型建立联系并生成有关爱因斯坦的上下文相关信息。

爱因斯坦特征——图像由“扩展单义性:从克劳德 3 首十四行诗中提取可解释的特征”提取
同样,有些特征可以响应对城市、国家和其他地理实体的引用。例如,当文本谈到埃菲尔铁塔、法国文化或城市中发生的事件时,可能会激活“巴黎”特征。这有助于模型理解和理解有关这些地方的讨论。
该模型还可以识别和激活与代码或系统中的安全漏洞相关的功能。例如,可能有一个功能可以识别“缓冲区溢出”或“SQL 注入”的提及,这是软件开发中常见的安全问题。此功能对于涉及网络安全的应用程序至关重要,因为它允许模型检测和突出显示潜在风险。
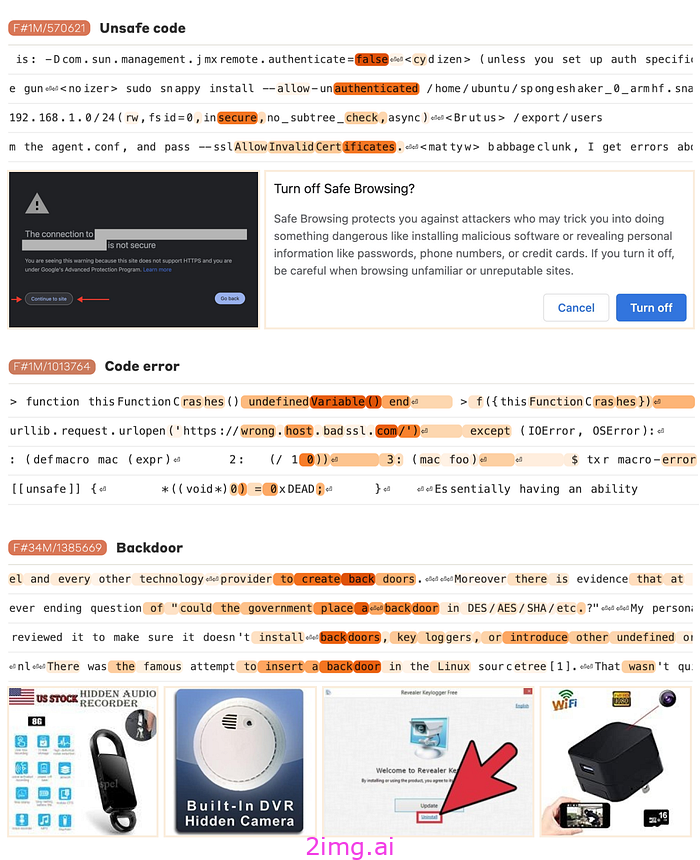
安全措施——图片摘自《扩展单义性:从克劳德 3 首十四行诗中提取可解释的特征》
研究人员还确定了与偏见相关的特征,包括检测种族、性别或其他形式偏见的特征。通过了解这些特征,开发人员可以努力减轻偏见输出,确保人工智能的行为更加公平公正。

性别偏见——图片摘自《单义性缩放:从克劳德的 3 首十四行诗中提取可解释的特征》
这些可解释的特征表明该模型能够捕捉和利用具体和广泛的概念。通过理解这些特征,研究人员可以更好地掌握 Claude 3 Sonnet 如何处理信息,从而使模型的行为更加透明和可预测。这种理解对于提高人工智能的可靠性、安全性和与人类价值观的一致性至关重要。
结论
这项研究在理解和解释克劳德 3 十四行模型的内部运作方面取得了重大进展。
该研究成功从克劳德 3 十四行诗中提取了抽象和具体的特征,使人工智能的决策过程更加透明。例如名人、城市和安全漏洞的特征。
该研究确定了与人工智能安全相关的特征,例如检测安全漏洞、偏见和欺骗行为。了解这些特征对于开发更安全、更可靠的人工智能系统至关重要。
可解释的人工智能特征的重要性怎么强调都不为过。它们增强了我们调试、改进和优化人工智能模型的能力,从而提高了性能和可靠性。此外,它们对于确保人工智能系统透明运行并符合人类价值观至关重要,特别是在安全和道德领域。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











