









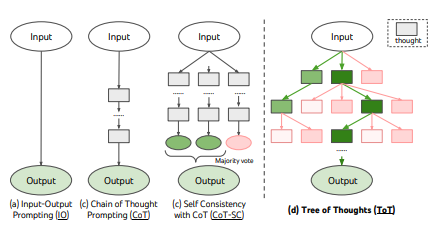
Thoughts on Thoughts(ToT)范式通过模拟人类的多步骤推理过程,结合语言模型(LLM)的生成能力,实现复杂问题的分步解决。ToT灵感来源于“思维树”(Tree of Thoughts)方法,旨在通过生成多个推理路径、评估和选择最佳路径来提升问题解决的准确性和鲁棒性。

ToT范式通过构建一个推理图,将复杂问题分解为多个子步骤,每个步骤由LLM生成多个候选答案(“想法”),并通过评估机制选择最优答案,逐步逼近最终答案。其核心思想包括:
- 多路径推理:为每个问题生成多个可能的推理路径,避免单一答案的局限性。
- 评估与选择:通过LLM或其他机制评估候选答案的质量,筛选出最佳路径。
- 图结构管理:利用LangGraph的图结构协调推理步骤,支持动态分支和状态管理。
- 迭代优化:在推理过程中不断调整路径,模拟人类的试错与反思过程。
ToT特别适用于需要深层推理的任务,例如数学问题求解、逻辑推理或复杂决策。相比传统的ReAct(Reasoning + Acting)范式,ToT通过探索多个推理路径,显著提高了解决复杂问题的能力。
工具定义
定义一个简单的工具,用于验证数学表达式的有效性:
- 输入:一个数学表达式(如(1 * 2 * 3 * 4))。
- 检查:确保表达式只使用数字1、2、3、4各一次,且仅包含加、减、乘、除和括号。
- 验证:通过eval计算表达式结果,检查是否等于24。
- 返回:验证结果(如“Valid: Expression results in 24”或错误信息)。
from langchain_core.tools import tool
@tool
def check_expression(expression: str) -> str:
"""
Check if the expression is valid and results in 24.
Args:
expression (str): The mathematical expression to check.
Returns:
str: String indicating if the expression is valid and results in 24, or error message.
"""
try:
# Remove whitespace
expression = expression.replace(" ", "")
# Check if expression contains only allowed numbers
allowed_numbers = set("1234")
used_numbers = set(char for char in expression if char.isdigit())
if used_numbers != allowed_numbers:
return f"Invalid: Expression must use exactly the numbers 1, 2, 3, 4. Used: {used_numbers}"
# Evaluate the expression
result = eval(expression, {"__builtins__": {}})
# Check if result is 24
if abs(result - 24) < 1e-10: # Using small epsilon for float comparison
return "Valid: Expression results in 24"
else:
return f"Invalid: Expression results in {result}, not 24"
except ZeroDivisionError:
return "Invalid: Division by zero"
except Exception as e:
return f"Invalid: Error in expression - {str(e)}"
- 使用{“__builtins__”: {}}限制eval的内置函数,防止代码注入。
- 处理异常,如除零错误或语法错误。
check_expression工具是ToT范式的关键组件,用于评估候选表达式的正确性。其设计简单但功能明确,适合24点游戏的验证需求。eval的使用虽然方便,但在生产环境中需进一步加固安全性(如使用沙箱或解析器)。
2.3 系统提示与代理定义
代码定义了两个主要提示模板,用于生成和评估推理路径:
2.3.1 生成提示(Generate Prompt)
from langchain_core.prompts import ChatPromptTemplate
generate_prompt = ChatPromptTemplate.from_messages([
("system", """You are a helpful assistant trying to solve a 24-point game. Your goal is to create a mathematical expression that equals 24 using the numbers [1, 2, 3, 4] exactly once each, and only using addition (+), subtraction (-), multiplication (*), division (/), and parentheses ().
2.3.2 评估提示(Evaluate Prompt)这里有点复杂,后续补充。。。2.3.3 代理定义代码使用`ChatOpenAI`创建LLM,并结合提示模板和工具定义生成和评估代理:
- 生成链:generate_prompt与LLM结合,生成k个新表达式。
- 评估链:evaluate_prompt与LLM结合,评估表达式的质量。
- 结构化输出:使用with_structured_output确保LLM输出符合指定的JSON格式。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
generate_chain = generate_prompt | llm.with_structured_output(
schema=List[dict], method="json_mode"
)
evaluate_chain = evaluate_prompt | llm.with_structured_output(
schema=List[dict], method="json_mode"
)
提示模板的设计是ToT范式的核心,生成提示鼓励多样性,评估提示确保评分客观且可解释。with_structured_output提高了输出的一致性和解析效率。
2.4 图结构定义
LangGraph通过StateGraph定义ToT的推理图:
from typing import TypedDict, List, Optional
from langgraph.graph import StateGraph, START, END
class ToTState(TypedDict):
messages: List[dict]
expressions: List[dict]
best_expression: Optional[dict]
workflow = StateGraph(ToTState)
workflow.add_node("generate", generate_node)
workflow.add_node("evaluate", evaluate_node)
workflow.add_edge(START, "generate")
workflow.add_conditional_edges(
"generate",
lambda state: "evaluate" if state["expressions"] else END,
{"evaluate": "evaluate", END: END}
)
workflow.add_conditional_edges(
"evaluate",
should_continue,
{"generate": "generate", END: END}
)
graph = workflow.compile()
2.5 节点实现
2.5.1 生成节点(generate_node)
- 调用generate_chain生成k=3个新表达式。
- 对每个表达式调用check_expression工具,获取验证结果。
- 更新状态,将新表达式(包含表达式、推理和验证结果)添加到expressions列表。
def generate_node(state: ToTState):
k = 3 # Number of expressions to generate
response = generate_chain.invoke({"state": state["expressions"], "k": k})
new_expressions = [
{
"expression": item["expression"],
"reasoning": item["reasoning"],
"validation_result": check_expression(item["expression"])
}
for item in response
]
return {
"expressions": state["expressions"] + new_expressions
}
- 实现细节:
- k=3控制每次生成的数量,平衡探索广度和计算成本。
- 新表达式与现有表达式合并,保留历史记录。
2.5.2 评估节点(evaluate_node)
- 筛选未评分的表达式(score字段不存在)。
- 调用evaluate_chain为这些表达式评分。
- 更新expressions列表,添加评分和评分说明。
- 选择评分最高的表达式作为best_expression。
def evaluate_node(state: ToTState):
to_evaluate = [
{
"expression": item["expression"],
"reasoning": item["reasoning"],
"validation_result": item["validation_result"]
}
for item in state["expressions"]
if "score" not in item
]
if not to_evaluate:
return {}
response = evaluate_chain.invoke({"to_evaluate": to_evaluate})
updated_expressions = state["expressions"].copy()
for eval_item in response:
for expr in updated_expressions:
if expr["expression"] == eval_item["expression"] and "score" not in expr:
expr["score"] = eval_item["score"]
expr["score_explanation"] = eval_item["explanation"]
best_expression = max(
updated_expressions,
key=lambda x: x.get("score", 0.0),
default=None
)
return {
"expressions": updated_expressions,
"best_expression": best_expression
}
- 实现细节:
- 仅评估新生成的表达式,避免重复计算。
- 使用max函数基于评分选择最佳表达式,default=None处理空列表情况。
生成和评估节点的实现清晰地体现了ToT的“生成-评估-选择”循环。生成节点通过k=3控制探索广度,评估节点通过评分机制筛选优质路径。check_expression工具的集成确保了客观验证,评分机制则模拟了主观判断。
2.6 执行与示例
代码通过一个示例展示了图的执行:
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
inputs = {
"messages": [{"role": "user", "content": "Solve the 24-point game using numbers [1, 2, 3, 4]."}],
"expressions": [],
"best_expression": None
}
for output in graph.stream(inputs, {"recursion_limit": 100}):
for key, value in output.items():
print(f"Output from {key}:")
print(value)
print("\n" + "-"*50 + "\n")
- 输入:
- 用户问题:解决24点游戏,使用数字1、2、3、4。
- 初始状态:空表达式列表,无最佳表达式。
- 执行流程:
- generate_node生成3个新表达式(如(1 * 2 * 3 * 4)),并验证。
- evaluate_node评估这些表达式,赋值评分。
- 如果找到评分1.0的表达式(验证通过),图终止;否则继续生成。
- 输出:
- 实时打印每个节点的输出,包括生成的表达式、验证结果、评分和最佳表达式。
- 示例可能输出类似:
- json
- 递归限制:recursion_limit=100防止无限循环。
- 图可视化:通过draw_mermaid_png展示推理图的结构。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











