







262. 行程和用户
表:Trips
+-------------+----------+ | Column Name | Type | +-------------+----------+ | id | int | | client_id | int | | driver_id | int | | city_id | int | | status | enum | | request_at | varchar | +-------------+----------+ id 是这张表的主键(具有唯一值的列)。 这张表中存所有出租车的行程信息。每段行程有唯一 id ,其中 client_id 和 driver_id 是 Users 表中 users_id 的外键。 status 是一个表示行程状态的枚举类型,枚举成员为(‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’) 。
表:Users
+-------------+----------+ | Column Name | Type | +-------------+----------+ | users_id | int | | banned | enum | | role | enum | +-------------+----------+ users_id 是这张表的主键(具有唯一值的列)。 这张表中存所有用户,每个用户都有一个唯一的 users_id ,role 是一个表示用户身份的枚举类型,枚举成员为 (‘client’, ‘driver’, ‘partner’) 。 banned 是一个表示用户是否被禁止的枚举类型,枚举成员为 (‘Yes’, ‘No’) 。
取消率 的计算方式如下:(被司机或乘客取消的非禁止用户生成的订单数量) / (非禁止用户生成的订单总数)。
编写解决方案找出 "2013-10-01" 至 "2013-10-03" 期间有 至少 一次行程的非禁止用户(乘客和司机都必须未被禁止)的 取消率。非禁止用户即 banned 为 No 的用户,禁止用户即 banned 为 Yes 的用户。其中取消率 Cancellation Rate 需要四舍五入保留 两位小数 。
返回结果表中的数据 无顺序要求 。
select request_at as 'Day', round(avg(Status!='completed'), 2) as 'Cancellation Rate'
from
trips t JOIN users u1 ON (t.client_id = u1.users_id AND u1.banned = 'No')
JOIN users u2 ON (t.driver_id = u2.users_id AND u2.banned = 'No')
where
request_at between '2013-10-01' AND '2013-10-03'
Group By
request_at思路:
非常巧妙,avg()函数本来是进行平均值的计算,avg(Status!='completed') 中 Status!='completed' 是布尔判断:Status!='completed'(即被顾客或司机取消的订单)得到值 1; Status='completed' 得到值 0。每条订单会得到一个值0/1。 avg 背后的公式是:所有订单值的和/所有订单的数量。因为不符合题目条件的订单的值是 0 求和相当于把值的和转化成了数量的和,所以 avg 得到的是:满足条件的订单数量/所有订单的数量,即取消率。
然后在与user表进行连接两次确保user状态没被搬掉
例子:
AVG () 计算平均值
AVG(CASE WHEN Status != 'completed' THEN 1 ELSE 0 END)
- 假设我们有 10 条订单,其中 3 条被取消(状态≠completed)是不等于(就是取消的只为真)
- 经过 CASE 转换后,这 10 条记录变为:[1,1,1,0,0,0,0,0,0,0]
- AVG () 计算平均值:(1+1+1+0+0+0+0+0+0+0)/10 = 0.3
- 这个 0.3 恰好就是取消订单的比例(3/10=30%)
511. 游戏玩法分析 I
活动表 Activity:
+--------------+---------+ | Column Name | Type | +--------------+---------+ | player_id | int | | device_id | int | | event_date | date | | games_played | int | +--------------+---------+ 在 SQL 中,表的主键是 (player_id, event_date)。 这张表展示了一些游戏玩家在游戏平台上的行为活动。 每行数据记录了一名玩家在退出平台之前,当天使用同一台设备登录平台后打开的游戏的数目(可能是 0 个)。
查询每位玩家 第一次登录平台的日期。
查询结果的格式如下所示:
Activity 表: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-05-02 | 6 | | 2 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-02 | 0 | | 3 | 4 | 2018-07-03 | 5 | +-----------+-----------+------------+--------------+ Result 表: +-----------+-------------+ | player_id | first_login | +-----------+-------------+ | 1 | 2016-03-01 | | 2 | 2017-06-25 | | 3 | 2016-03-02 | +-----------+-------------+
SELECT
player_id,
event_date AS first_login
FROM (
SELECT
player_id,
event_date,
ROW_NUMBER() OVER (PARTITION BY player_id ORDER BY event_date) AS rn
FROM
Activity
) t
WHERE
rn = 1
ORDER BY
player_id;思路:
-
窗口函数计算排名:
ROW_NUMBER() OVER (PARTITION BY player_id ORDER BY event_date) AS rnPARTITION BY player_id:按玩家分组ORDER BY event_date:在每个玩家组内按登录日期升序排列ROW_NUMBER():为每个分组内的记录分配连续整数(1,2,3...)- 结果:每个玩家的最早登录日期将获得排名
rn=1
-
子查询过滤:
WHERE rn = 1仅保留每个玩家排名为 1 的记录(即最早登录日期)
-
最终结果
SELECT player_id, event_date AS first_login返回玩家 ID 和对应的首次登录日期
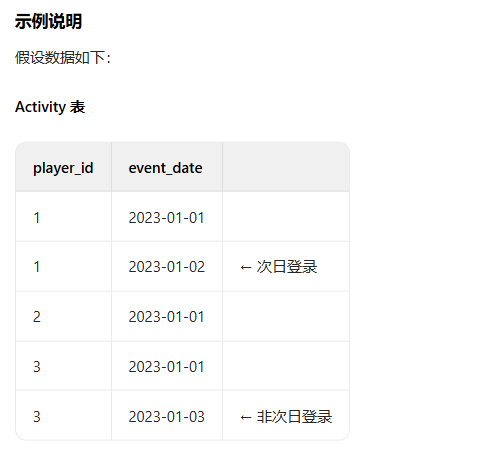
550. 游戏玩法分析 IV
Table: Activity
+--------------+---------+ | Column Name | Type | +--------------+---------+ | player_id | int | | device_id | int | | event_date | date | | games_played | int | +--------------+---------+ (player_id,event_date)是此表的主键(具有唯一值的列的组合)。 这张表显示了某些游戏的玩家的活动情况。 每一行是一个玩家的记录,他在某一天使用某个设备注销之前登录并玩了很多游戏(可能是 0)。
编写解决方案,报告在首次登录的第二天再次登录的玩家的 比率,四舍五入到小数点后两位。换句话说,你需要计算从首次登录日期开始至少连续两天登录的玩家的数量,然后除以玩家总数。
结果格式如下所示:
示例 1:
输入: Activity table: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-03-02 | 6 | | 2 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-02 | 0 | | 3 | 4 | 2018-07-03 | 5 | +-----------+-----------+------------+--------------+ 输出: +-----------+ | fraction | +-----------+ | 0.33 | +-----------+ 解释: 只有 ID 为 1 的玩家在第一天登录后才重新登录,所以答案是 1/3 = 0.33
select round(avg(a.event_date is not null), 2) as fraction
from
(select player_id , min(event_date) as firstLogin
from Activity
group by player_id
) as p left join Activity a
on p.player_id=a.player_id and datediff(a.event_date, p.firstLogin)=1思路先是求出第一天,然后和Activity 表左连接 判断同一用户的登录天数相差为1的id


30. 串联所有单词的子串
给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。
s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。
- 例如,如果
words = ["ab","cd","ef"], 那么"abcdef","abefcd","cdabef","cdefab","efabcd", 和"efcdab"都是串联子串。"acdbef"不是串联子串,因为他不是任何words排列的连接。
返回所有串联子串在 s 中的开始索引。你可以以 任意顺序 返回答案。
示例 1:
输入:s = "barfoothefoobarman", words = ["foo","bar"]
输出:[0,9]
解释:因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。
子串 "barfoo" 开始位置是 0。它是 words 中以 ["bar","foo"] 顺序排列的连接。
子串 "foobar" 开始位置是 9。它是 words 中以 ["foo","bar"] 顺序排列的连接。
输出顺序无关紧要。返回 [9,0] 也是可以的。
示例 2:
输入:s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"]
输出:[]
解释:因为 words.length == 4 并且 words[i].length == 4,所以串联子串的长度必须为 16。
s 中没有子串长度为 16 并且等于 words 的任何顺序排列的连接。
所以我们返回一个空数组。
示例 3:
输入:s = "barfoofoobarthefoobarman", words = ["bar","foo","the"] 输出:[6,9,12] 解释:因为 words.length == 3 并且 words[i].length == 3,所以串联子串的长度必须为 9。 子串 "foobarthe" 开始位置是 6。它是 words 中以 ["foo","bar","the"] 顺序排列的连接。 子串 "barthefoo" 开始位置是 9。它是 words 中以 ["bar","the","foo"] 顺序排列的连接。 子串 "thefoobar" 开始位置是 12。它是 words 中以 ["the","foo","bar"] 顺序排列的连接
public class Solution {
public List<Integer> findSubstring(String s, String[] words) {
List<Integer> result = new ArrayList<>();
if (s == null || s.isEmpty() || words == null || words.length == 0) {
return result;
}
int wordLength = words[0].length();
int totalWords = words.length;
int substringLength = wordLength * totalWords;
int sLength = s.length();
// 统计单词频率
Map<String, Integer> wordCount = new HashMap<>();
for (String word : words) {
wordCount.put(word, wordCount.getOrDefault(word, 0) + 1);
}
// 外层循环遍历所有可能的起始偏移量(0到wordLength-1)
for (int offset = 0; offset < wordLength; offset++) {
int left = offset;
int count = 0;
Map<String, Integer> currentWindow = new HashMap<>();
// 内层循环以wordLength为步长滑动窗口
for (int right = offset; right <= sLength - wordLength; right += wordLength) {
String currentWord = s.substring(right, right + wordLength);
// 如果当前单词不在目标单词列表中,重置窗口
if (!wordCount.containsKey(currentWord)) {
currentWindow.clear();
count = 0;
left = right + wordLength;
continue;
}
// 将当前单词加入窗口
currentWindow.put(currentWord, currentWindow.getOrDefault(currentWord, 0) + 1);
count++;
// 调整窗口:如果当前单词数量超过目标频率,左移窗口
while (currentWindow.get(currentWord) > wordCount.get(currentWord)) {
String leftWord = s.substring(left, left + wordLength);
currentWindow.put(leftWord, currentWindow.get(leftWord) - 1);
if (currentWindow.get(leftWord) == 0) {
currentWindow.remove(leftWord);
}
count--;
left += wordLength;
}
// 当窗口大小等于单词总数时,找到一个有效解
if (count == totalWords) {
result.add(left);
// 左移窗口一个单词长度以继续寻找
String leftWord = s.substring(left, left + wordLength);
currentWindow.put(leftWord, currentWindow.get(leftWord) - 1);
if (currentWindow.get(leftWord) == 0) {
currentWindow.remove(leftWord);
}
count--;
left += wordLength;
}
}
}
return result;
}
}示例输入
s = "barfoothefoobarman"
words = ["foo", "bar"] // m=2, k=3, 子串长度=6
步骤 1:统计目标单词频率
wordCount = {"foo": 1, "bar": 1}
步骤 2:外层循环处理不同起始偏移量
对于 offset 从 0 到 2(k=3),分别执行滑动窗口逻辑:
当 offset = 0
窗口从索引 0 开始,每次滑动 3 个字符:
-
窗口
[0, 5](子串"barfoo"):- 拆分:
["bar", "foo"] - 统计:
currentWindow = {"bar": 1, "foo": 1} - 匹配
wordCount→ 记录索引 0。
- 拆分:
-
窗口
[3, 8](子串"foothe"):- 拆分:
["foo", "the"] "the"不在wordCount中 → 重置窗口。
- 拆分:
-
窗口
[9, 14](子串"foobar"):- 拆分:
["foo", "bar"] - 统计:
currentWindow = {"foo": 1, "bar": 1} - 匹配
wordCount→ 记录索引 9。
- 拆分:
当 offset = 1 和 offset = 2
类似地,处理起始索引为 1 和 2 的窗口,但未发现有效子串。
O了个K 就到这里,


















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









