







1. Kafka概述
Kafka是由Apache软件基金会开发的一个开源流处理平台;Kafka是一种高吞吐量的分布式发布订阅消息系统。kafka对消息保存时根据Topic进行归类,Producer发送消息,Consumer接受消息,kafka集群有多个kafka实例组成,每个实例(server)成为broker。客户端和服务器之间的通信是通过简单,高性能,语言无关的TCP协议完成的。
2. Kafka原理
2.1 相关术语介绍
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储)
对于每个主题,Kafka集群维护一个分区日志,如下所示:
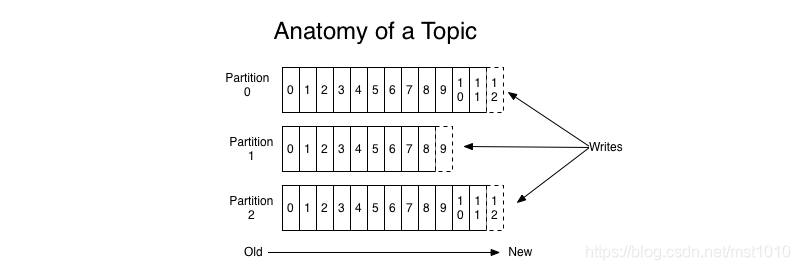
每个分区都是一个有序的、不可变的记录序列,这些记录连续地 appended 到一个结构化的提交日志中。分区中的每条记录都被分配了一个偏移量(连续的id),该偏移量惟一地标识分区中的每条记录。
Kafka集群使用一个可配置的保留期持久地保存所有已发布的记录(无论它们是否已被使用)。例如,如果保留策略被设置为两天,那么在记录发布后的两天内,它是可用的,在此之后,它将被丢弃以释放空间
事实上,基于每个消费者保留的唯一元数据是该消费者在日志中的偏移或位置。这种偏移由消费者控制:通常消费者在读取记录时会线性地提高其偏移量,但事实上,由于消费者控制位置,它可以按照自己喜欢的任何顺序消费记录。例如,消费者可以重置为较旧的偏移量以重新处理过去的数据,或者跳到最近的记录并从“现在”开始消费。
日志中的分区有几个用途。首先,它们允许日志扩展到超出单个服务器所能容纳的大小。每个单独的分区必须适合承载它的服务器,但是一个主题可能有多个分区,因此它可以处理任意数量的数据。
Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition
日志的分区分布在Kafka集群中的服务器上,每个服务器处理数据并请求共享分区。为了容错,每个分区被复制到多个可配置的服务器上。
每个分区都有一个充当“领导者”的服务器和零个或多个充当“追随者”的服务器。leader处理分区的所有读和写请求,而follower被动地复制leader。如果领导者失败,其中一个追随者将自动成为新的领导者。每个服务器充当它的一些分区的领导者和其他分区的追随者,因此集群内的负载非常平衡。
Producer
消息生产者,负责发布消息到Kafka broker
生产者将数据发布到他们选择的主题,生产者选择要分配给主题中的哪个分区的记录
Consumer
消息消费者,向Kafka broker读取消息的客户端
消费者使用消费者组名称标记自己,并且发布到主题的每个记录被交付到每个订阅消费者组中的一个消费者实例。消费者实例可以在单独的进程中,也可以在不同的机器
如果所有消费者实例具有相同的消费者组,则记录将有效地在消费者实例上进行负载平衡。
如果所有消费者实例具有不同的消费者组,则每个记录将广播到所有消费者进程。
2.2 Kafka 架构
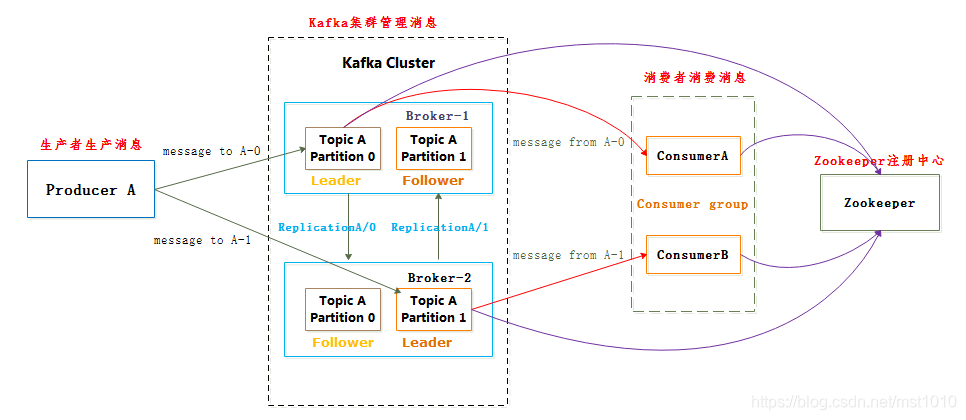
理解:
假设已经搭建 10.0.164.19 ,10.0.164.23,10.0.164.27三个节点的zookeeper集群和kafka集群
① ./kafka-topics.sh --create --zookeeper 10.0.164.19:2181 --topic hart --replication-factor 2 --partitions 2
–replication-factor 定义副本数(实际包含leader和follower);–partitions 定义分区数
阐述:执行命令,在数据目录下会有分区(分区是以文件区分:hart-0和hart-1),因为副本数为2且部署在3台服务器上, 分区数据为 hart-0,hart-1;hart-0;hart-1
② ./kafka-console-producer.sh --broker-list 10.0.164.19:9092 --topic hart
阐述:向topic中写入数据
③ ./kafka-console-consumer.sh --zookeeper 10.0.192.19:2181 --topic hart --from-beginning
报错!报错!报错!(用的最新版的kafka直接报错,前几版中仅报方法过时,但还可以使用),这是因为客户端数据不保存到zookeeper中了,直接把offset数据保存到本地
./kafka-console-consumer.sh --bootstrap-server 10.0.192.19:9092 --topic hart --from-beginning
④ ./kafka-topics.sh --zookeeper 10.0.164.19:2181 --describe --topic hart
阐述:查看topic详情
其中,首行:topic名称 分区数量 副本数量,Configs中,每个分区是一条数据,Partition:分区编号 Leader:分区leader所在broker的Id Replicas:分区副本(follower和leader)所在broker的Id Isr:可以选举的broker的Id
感觉此处应该有图:但是没有找到!


3. Kafka安装
3.1 zookeeper安装
安装过程:zookeeper安装
3.2 kafka安装(集群)
(1) kafka下载
下载地址:官网下载
下载的目前最新版本:
(2) kafka安装
kafka安装过程很简单,上传到服务器解压缩即可
tar -zxf kafka_2.12-2.2.0.tgz -C /usr/local # 解压压缩包到指定目录
cd /usr/local # 切换到指定的目录
mv kafka_2.12-2.2.0 kafka # 重命解压缩文件
(3) kafka 配置
- 创建数据和日志存储目录
mkdir /usr/local/kafka/logs # 文件存储数据和日志
- 修改配置文件:server.properties
vim /usr/local/kafka/config/server.properties
# broker的Id.每个broker设置一个惟一的整数。
broker.id=0
# 套接字服务器监听的地址 例子:listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://10.0.164.19:9092
# broker将向生产者和消费者发布主机名和端口。如果未设置,则在配置时使用"侦听器"的值。
advertised.listeners=PLAINTEXT://10.0.164.19:9092
# 服务器用于从网络接收请求和向网络发送响应的线程数
num.network.threads=3
# 服务器用于处理请求的线程数(其中可能包括磁盘I/O)
num.io.threads=8
# 套接字服务器使用的发送缓冲区
socket.send.buffer.bytes=102400
# 套接字服务器使用的接收缓冲区
socket.receive.buffer.bytes=102400
# 套接字服务器将接受的请求的最大大小(protection against OOM)
socket.request.max.bytes=104857600
# 用于存储日志文件列表(逗号分隔)
log.dirs=/usr/local/kafka/logs/
# 每个topic默认日志分区数。更多的分区允许使用更大的并行性,但这也将导致跨brokers生成更多的文件。
num.partitions=1
# 每个数据目录在启动时用于日志恢复和在关闭时用于刷新的线程数(如果安装的数据目录位于RAID阵列中,建议增加该值)
num.recovery.threads.per.data.dir=1
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# 设置日志文件的生命周期(小时)
log.retention.hours=168
# 日志文件的最大大小。当达到这个大小时,将创建一个新的日志。
log.segment.bytes=1073741824
# 设置检查日志根据保留策略是否可以删除的时间间隔
log.retention.check.interval.ms=300000
# # Zookeeper连接(详见Zookeeper文档),用逗号分隔的主机:端口对
zookeeper.connect=10.0.164.19:2181,10.0.164.23:2181,10.0.164.27:2181
# 连接zookeeper的超时时间(ms)
zookeeper.connection.timeout.ms=6000
# 配置指定了组协调器延迟初始使用者重新平衡的时间(以毫秒为单位)。随着新成员的加入,设置的值将进一步推迟再平衡
# 默认值是3秒。这里设置为0,因为它为开发和测试提供了更好的开箱即用体验。在生产环境中,默认值3秒更合适,有助于避免在应用程序启动期间进行不必要的、可能代价高昂的重新平衡。
group.initial.rebalance.delay.ms=0
修改项:
broker.id=0
listeners=PLAINTEXT://10.0.164.19:9092
advertised.listeners=PLAINTEXT://10.0.164.19:9092
log.dirs=/usr/local/kafka/logs/
zookeeper.connect=10.0.164.19:2181,10.0.164.23:2181,10.0.164.27:2181
group.initial.rebalance.delay.ms=0 # 生产环境需要修改设置
其他2台服务器如是配置!
(4) kafka测试
-
启动kafka
a. 首先启动zookeeper集群
b.执行命令: /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties -
测试运行
查询topic:
./kafka-topics.sh --zookeeper 10.0.164.19:2181 --list
创建topic:
./kafka-topics.sh --zookeeper 10.0.164.19:2181 --create --replication-factor 3 --partitions 3 --topic order
删除topic:
./kafka-topics.sh --zookeeper 10.0.164.19:2181 --delete --topic hart
发送消息:
./kafka-console-producer.sh --broker-list 10.0.164.19:9092 --topic order
消费消息:
./kafka-console-consumer.sh --bootstrap-server 10.0.164.19:9092 --from-beginning --topic order
topic详情:
./kafka-topics.sh --zookeeper 10.0.164.19:2181 --describe --topic order
4. Kafka应用
Spring Boot集成Kafka :官方参考文档
(1) 演示demo
消息生产者:
@RestController
@RequestMapping("kafka")
public class ProducerController {
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
private static final Logger logger = LoggerFactory.getLogger(ProducerController.class);
@RequestMapping("producer")
public void kafkaProducer() {
OrderInfo orderInfo = new OrderInfo();
orderInfo.setOrderNum("HART201904111312");
orderInfo.setOrderSum(588);
orderInfo.setAddress("北京市朝阳区");
orderInfo.setReceive("周休");
orderInfo.setOrderTime(new Date());
String sendData = JSONObject.toJSONString(orderInfo);
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(Constant.TOPIC_NAME, sendData);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
logger.warn("Sending message to Kafka failed: topic {}, content: {}", Constant.TOPIC_NAME, JSON.toJSONString(sendData));
}
@Override
public void onSuccess(SendResult<String, String> producerData) {
ProducerRecord<String, String> producerRecord = producerData.getProducerRecord();
logger.info("Sending message to Kafka finished: topic {}, content: {}", Constant.TOPIC_NAME, producerRecord.value());
}
});
}
}
消息消费者:
@RestController
public class CustomerController {
@KafkaListener(topics = Constant.TOPIC_NAME)
public void kafkaCustomer(String receiveData) {
OrderInfo orderInfo = JSONObject.parseObject(receiveData, OrderInfo.class);
System.err.println("我接收到消息:" + orderInfo.getAddress());
}
}
topic常量
public interface Constant {
String TOPIC_NAME = "order";
}
实体常量
@Data
public class OrderInfo implements Serializable{
private static final long serialVersionUID = 4788755594516737716L;
private String orderNum;
private long orderSum;
private String address;
private String receive;
private Date orderTime;
}
yml文件
server:
port: 7016
#kafka相关配置
spring:
kafka:
# kafka集群配置
bootstrap-servers: 10.0.164.19:9092,10.0.164.23:9092,10.0.164.27:9092
# 配置生产者
producer:
# 重试次数
retries: 5
# 每次批量发送消息的数量
batch-size: 65536
buffer-memory: 524288
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 配置消费者
consumer:
group-id: 66
#key-value序列化反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.edu</groupId>
<artifactId>hart</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>hart</name>
<description>Kafka Demo</description>
<properties>
<java.version>1.8</java.version>
<hutool>4.1.10</hutool>
<lombok>1.18.6</lombok>
<json>1.2.56</json>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.2.5.RELEASE</version>
</dependency>
<!-- https://mvnrepository.com/artifact/cn.hutool/hutool-core -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-core</artifactId>
<version>${hutool}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${json}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>

















 351
351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









