







1. 数据接受,生成Block 流程
- streamingContext启动时,会启动ReceiverTracker, 它会将需要启动的Receiver分发到Executor上,Executor上的ReceiverSuperviser会负责Receiver的启动,停止,重启管理(后续有详细文章描述:如何分发,启动等)。
- Receiver上的store(Item),实际调用ReceiverSuperviser(具体实现ReceiverSuperviserImpl)的pushSingle(),来存储每条数据。
- 在ReceiverSuperviserImpl的内部,他是通过BlockGenerator.addData 来进行具体的数据存储
- 在BlockGenerator内部,有几个核心组件:缓存数据的buffer, 存储block的queue, 定时将buffer数据包装成Block扔到queue的定时器,定时从queue拉取Block然后通过ReceivedBlockHandler将其存储的线程。
具体如下图所示:
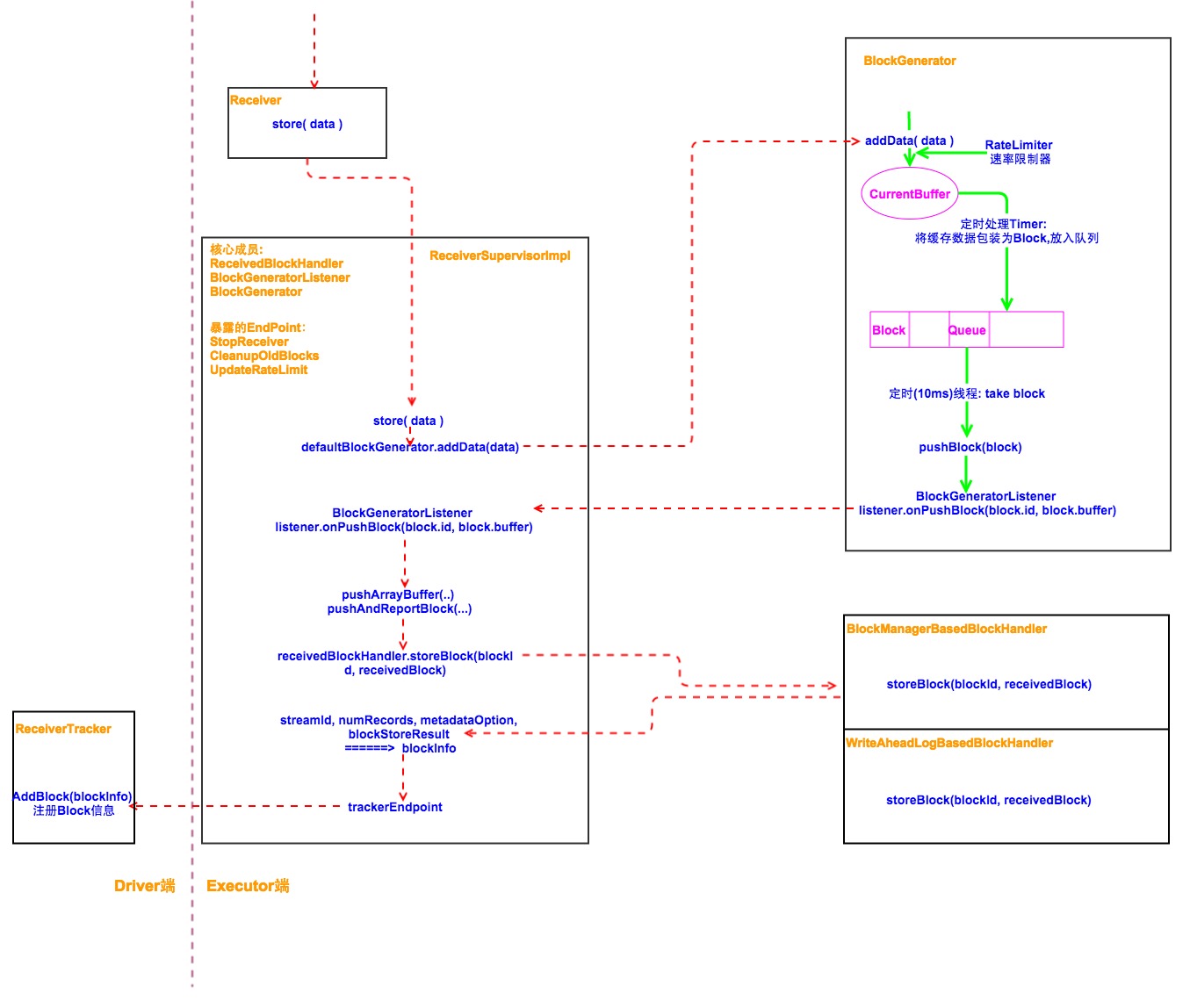
2. 一些问题的思考
在整个的执行流程中,线性调用链上基本不会发生任何问题。只是在BlockGenerator缓存接受的数据,生成Block的时候需要重点关注,以及receivedBlockHandler如何将Blocks存储在Spark Mem中也需要被关注。
- BlockGenerator中的currentBuffer:它缓存的数据会被定时器每隔blockInterval(默认200ms)的时间拿走,这个缓存所用的是spark运行时内存(默认heap*0,4),而不是storage内存。那么如果在一个blockInterval时间内,接受速率很大的话,这部分内存很容易OOM 或者 进行大量的 GC,从而导致receiver所在的Executor极容易挂掉,或者处理速度很慢。
- BlockGenerator中的BlockQueue作为缓存buffer和BlockManager的中转站,一般没有什么问题。
- receivedBlockManager将获取的Block都存储在自己所在的这个Executor上,即一个batchInterval内的所有数据都存储在一个Executor上,如果Executor的storage 内存不是很大,而一个batchInterval时间内接受过多的数据,很容撑爆内存导致Receiver挂掉。
- 时刻关注batch processing延迟,如果batch processing延迟较大,那么上游的数据会被累计,从而导致内存问题。
- 尽量打开 backpressure 的功能 link。
StorageLevel的设置:
Memory_Disk: 如果Receiver一旦挂掉,部分block就找不到,从而整个作业失败。Memory_Disk_2: 有了replication,一般就不容易出现数据丢失,但是内存压力大问题仍然存在。Memory_AND_DISK_SER_2: 数据序列化存储,比较适合。
3. 一些优化尝试
- 让receiver尽量均匀的分布到Executor上, 1.5版本之后采用的这种方式。
- 启动的Receiver个数:一般为Executor个数的 1/4, 在做repelication的情况下,内存最大可以占用到 1/2 的storage.
- 务必给你系统设置 spark.streaming.receiver.maxRate。假设你启动了 N个 Receiver,那么你系统实际会接受到的数据不会超过 N*MaxRate,也就是说,maxRate参数是针对每个 Receiver 设置的。这个MaxRate在实际使用中需要测试出经验值
设置blockInterval:
blockInterval = batchInterval * #receiver / (partitionFactor * sparkProcessCore)
sparkProcessCores = spark.cores.max - #receiver
单个Executor的内存不要设置的太大,避免大内存GC问题。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









