







目录
哈希索引
哈希索引(hash index)基于哈希表实现,只有精确匹配索引所有列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
1. 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。
2. 哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序。
3. 哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的。
4. 哈希索引只支持等值比较查询,包括=、IN()、<>(注意<>和<=>是不同的操作)。也不支持任何范围查询,例如WHERE price>100。
5. 访问哈希索引的数据非常快,除非有很多哈希冲突(不同的索引列值却有相同的哈希值)。当出现哈希冲突的时候,存储引擎必须遍历链表中所有的行指针,逐行进行比较,直到找到所有符合条件的行。
6. 如果哈希冲突很多的话,一些索引维护操作的代价也会很高。例如,如果在某个选择性很低(哈希冲突很多)的列上建立哈希索引,那么当从表中删除一行时,存储引擎需要遍历对应哈希值的链表中的每一行,找到并删除对应行的引用,冲突越多,代价越大。
二叉搜索树索引
二叉查找树(二叉搜索树或二叉排序树)是指要么是一颗空树,要么就是具有如下性质的二叉树:
1. 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2. 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3. 任意节点的左、右子树也分别为二叉查找树;
4. 没有键值相等的节点。
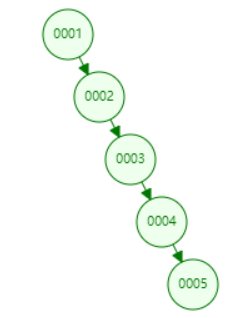
二叉搜索树在使用时可能会退化为类似于链表的结构。
平衡二叉树索引 (AVL树)
1. 非叶子节点最多拥有两个子节点。
2. 非叶子节值大于左边子节点、小于右边子节点。
3. 树的左右两边的层级数相差不会大于1。
4. 没有值相等重复的节点。

磁盘io:当在大量数据存储中,查询时我们不能将所有数据加载到内存中,只能逐一加载磁盘页,每个磁盘页对应树的节点。造成大量磁盘io操作(最坏情况下为树的高度),而磁盘io操作的效率时非常低的。
平衡二叉树作为数据库索引时查找效率接近O(logn),在大量数据插入时,平衡二叉树的深度会非常大,mysql读取时会消耗大量磁盘io,树越高查找速度越慢。在查找大于或者小于的数据时,要先定位再回溯查询,效率非常慢;而且计算机从磁盘读取数据时以页(4KB)为单位的,每次读取4096byte。平衡二叉树每个节点只保存了一个关键字(如int即4byte),浪费了4092byte,极大的浪费了读取空间。
B树(Balance Tree)
B树(Balance Tree)又称为多路平衡查找树,它是一种多叉树,一颗m阶B树或者是一颗空树,或者是满足以下要求的树:B树中所有结点的孩子结点最大值称为B树的阶,通常用m表示。一个结点有k个孩子时,必有k-1个关键字才能将子树中所有关键字划分为k个子集。
1. 根结点至少有两个子女。
2. 每个中间节点都包含k-1个元素和k个孩子,其中 ceil(m/2) ≤ k ≤ m
3. 每一个叶子节点都包含k-1个元素,其中 ceil(m/2) ≤ k ≤ m
4. 所有的叶子结点都位于同一层。
5. 每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分
6.每个结点的结构为:
| n | A0 | K1 | A1 | K2 | A2 | ... | Kn | An |
其中,Ki(1≤i≤n)为关键字,且Ki<Ki+1(1≤i≤n-1)。Ai(0≤i≤n)为指向子树根结点的指针。且Ai所指子树所有结点中的关键字均小于Ki+1。n为结点中关键字的个数,满足ceil(m/2)-1≤n≤m-1。

m阶B树一个节点可以存储多个值,降低树的高度。相比AVL树,B树的比较次数并未减少,但是再大量数据的情况下,磁盘的io次数会减少,查找速度会更快。
存在问题:例如在查找大于5的数据时,会先定位到5的位置,然会进行回溯查找,仍然存在回溯查找的过程。
B+树
B+树与B树相差并不大,由于B树可能会最高级的根节点查询到最低级的叶子节点。那我们可以从叶子节点开始查啊,这就产生了B+树结构。
一颗m阶B+树的满足条件:
1. 有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2. 所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3. 所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。

卫星数据:指的的是索引元素所指向的数据记录,比如数据库中的某一行,在B树中,无论中间节点还是叶子节点都带有卫星数据;而在B+树中,只有叶子节点带有卫星数据,其余中间节点仅仅是索引,没有任何的数据关联。
B+树的叶子节点层利用双向链表来记录元素指向,在查找范围数据时不用回溯查找,B+ 树对查询操作有了很大的提升,但同时也降低了数据插入和删除的效率。
B树解决的两大问题是(每个节点存储更多关键字;路数更多),B+Tree 的磁盘读写能力相对于 B Tree 来说更强,同数据量下磁盘I/0次数更少(根节点和枝节点不保存数据区,所以一个节点可以保存更多的关键字,一次磁盘加载的关键字更多),范围查询和排序能力更强(因为叶子节点上有下一个数据区的指针,数据形成了链表),效率更加稳定(B+Tree 永远是在叶子节点拿到数据,所以 IO 次数是稳定的)。
B树和B+树的区别
1. B+树内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为 O(logn)。而B树查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)。
2. B+树叶节点两两相间访问性,可使用在范围连可大大增加区查询等,而B树每个节点 key 和 data 在一起,则无法区间查找。
3. B+树更适合外部存储。由于内节点无 data 域,每个节点能索引的范围更大更精确















 1139
1139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









