







 本文详细介绍了多线程中的锁策略,包括悲观锁与乐观锁的概念,以及轻量级锁、重量级锁的区别。讨论了自旋锁和挂起等待锁的实现方式,对比了读写锁与普通互斥锁的特点。此外,文章还探讨了synchronized的原理和优化机制,以及CAS(CompareandSwap)操作在并发编程中的应用,包括ABA问题和解决方案。最后,提到了Java并发编程中的一些重要组件,如ReentrantLock、原子类和线程安全的集合类。
本文详细介绍了多线程中的锁策略,包括悲观锁与乐观锁的概念,以及轻量级锁、重量级锁的区别。讨论了自旋锁和挂起等待锁的实现方式,对比了读写锁与普通互斥锁的特点。此外,文章还探讨了synchronized的原理和优化机制,以及CAS(CompareandSwap)操作在并发编程中的应用,包括ABA问题和解决方案。最后,提到了Java并发编程中的一些重要组件,如ReentrantLock、原子类和线程安全的集合类。
文章目录
前言 :
本文主要内容 , 关于多线程的八股文,常见面试题 以及一些不常用的组件。
常见锁策略了
这里锁策略 , 主要是为了实现锁的 , 这里不管是 java 还是 c++等都适用
1.悲观锁 VS 乐观锁
悲观锁 :预期所冲突的概率会很高 .
简单来说 :认为加上了锁就会出现锁冲突
乐观锁 :预期冲突的概率很低
简单来说 : 认为不加锁也不会出现锁冲突
简答举个例子 : 现在疫情放开,有些人 觉得这没啥,我在家一样的此时就不会做太多关于疫情方面的工作,认为一切都照旧 ,而有些人且觉得疫情放开肯定会再次出现爆发,所以开始屯米屯粮 , 还有屯药 , 以防不时之需 .
这里啥都不做肯定就是乐观的 , 而屯物资的就是悲观的。
那么 这里提出一个问题 : 是乐观锁背后做的事多还是悲观锁呢?
很明显这里是悲观锁背后做到事情多 , 既然多做了事肯定是需要资源和空间的 , 所以它的效率也就低了 。
放在上面的例子就是, 既然你要屯物资 肯定是需要时间去买,需要花费钱财 .
而乐观锁 就不需要做太多的事情,一切照旧 该乍样咋样,此时效率就高了 ,不需要申请额外的空间和资源 .
放在上面的例子就是 , 我在家里啥都不买,爆发就爆发咯,我该干啥干啥.
2. 轻量级锁 VS 重量级锁
这里的两个锁 与乐观锁和悲观锁的概念非常像 ,但是有本质上的区别 .
轻量级锁 : 加锁解锁开销比较小 ,效率高
重量级锁 : 加锁解锁开销比较大 , 效率低
乐观锁 :锁竞争不是很激烈 , 做的事少,效率高
悲观锁 : 锁竞争激烈, 做的事多,效率低
此时很明显 , 乐观锁 就很像 轻量级锁 , 悲观锁就很像重量级锁 。
但是这里有本质上的区别,乐观锁和悲观锁 并没有做 而是认为当前加锁后锁冲突的概率高或者低然后采取 多做事还是少做事。
而轻量级锁和重量级锁是已经将锁冲突处理了, 实现了代码,此时发现当前这种实现方式 有点重 开销比较大, 或者这种方式实现,比较轻开销比较小.
简单来说 : 一个是做了, 一个是没做 。
3.自旋锁 VS 挂起等待锁
1.自旋锁是轻量级锁的一种典型实现
自旋锁 往往是通过 用户态代码来实现的, 往往比较轻
2.挂起来等待锁是重量级锁的一种典型实现
挂起来等待锁 往往是通过内核的一些机制来实现的, 比较重
下面来看一下自旋锁和 挂起来等待锁的区别 :
这里考虑一个情况 , 我要向女神表白 (尝试对女神进行加锁操作)
接下来 喜提 好人卡, 女神告诉我 , 你很好 , 但我有男朋友了 (说名女神已经被别人加锁了)
此时我 作为一个究极舔够,觉得被发好人卡没有啥, 就告诉女神我愿意等 , 愿意当你的备胎 .
为了找到这个机会上位, 就有两种方式等待机会 (锁释放 , 女神分手)
1.采用自旋锁的方式 : 每天都给女神问候 早安午安晚安 , 一旦女神分手就能第一时间知道 .
一旦锁被释放, 就能第一时间感知到,从而有机会获取到锁.
很明显 采用自旋锁,会占用大量的系统资源 , 每天都舔也是一件累人的事情
2.采用挂起来等待锁 : 此时我说愿意等,我选择傻等 , 我知道你过的很好, 我就悄悄躲起来也不打扰你 , 如果有一天你想起我,请告诉我 .
如果女神分手了, 有可能想起来我, 就告诉我,她分手了,求安慰 。
当时更大的概率是,女神也把你给忘了, 指不定啥时候才想起来 , 当真的被唤醒的时候,中间已经是沧海桑田了。
这里就是将CPU的资源给剩下来了.
4. 读写锁 VS 普通的互斥锁
互斥锁 : 就是 像 synchronized 这样的锁
互斥锁 提供 加锁和解锁操作 ,如果一个线程加锁了, 另一个个线程也尝试加锁,就会阻塞等待
读写锁 :提供了三种操作
1.针对读加锁 (读锁)
2.针对写加锁 (写锁)
3.解锁
此时就将读和写加锁进行分开, 那么这里分开有啥好处呢 ?
之前说过 : 多线程针对同一个变量并发度,这个时候没有线程安全问题 , 也不需要加锁.
我们读写锁,就是针对当前这种情况 , 将读和写进行分开,
因为读锁和读锁之间,没有互斥
写锁和写锁之间,存在互斥
写锁和读锁之间,存在互斥
此时我们就可以根据需求 , 让我们的代码分别加上不同的锁 。
如 : 当前代码中, 如果只是读操作,加读锁即可, 如果有写操作,就加写锁。
假设 当前有一组线程都去读(加读锁 : 读锁之间没有互斥 ,也就不会使线程阻塞) , 这些线程之间没有锁竞争的也就没有没有线程安全问题 这里就可以使 效率 又快有准.
假设 当前 的一组操作有读也有写, 才会产生竞争 , 此时会出现线程安全问题,就需要加写锁 , 让线程阻塞.
另外一个事实 : 很多开发场景中 , 读操作非常高频 , 比写操作的频率高很多 .
读写锁 再java 标准库提供了 ReentrantReadWriteLock 类实现了读写锁
ReentrantReadWriteLock.ReadLock 类表示一个读锁. 这个对象提供了 lock / unlock 方法进行加锁解锁.
ReentrantReadWriteLock.WriteLock 类表示一个写锁. 这个对象也提供了 lock / unlock 方法进行加锁解锁.
5. 公平锁 和 非公平锁
公平锁 : 多个线程等待同一个把锁的时候,谁先来谁就能获取到这把锁 (相当于先来后到)
非公平锁 : 多个线程再等待一把锁的时候,不遵循先来后到。
此时就有就容易混淆了,公平不因该是雨露均沾了吗 。
很抱歉,人家设计出来的时候就认为 ,先来后到是公平的,雨露均在反而是不公平的.
下面举个例子 :

6. 可重入锁 VS 不可重入锁
不可重入锁 : 一个线程针对一把锁,连续加锁两次,出现死锁
可重入锁 : 一个线程针对一把锁 , 连续加锁多次都不会死锁 .
这里啥是死锁,再之前的文章中说过,这里不就不展开了。
下面就来 看一下 synchronized 与 锁策略的对应关系 .
1. synchronized 既是一个悲观锁,也是一个 乐观锁 (synchronized 会根据锁竞争的激烈程度,自适应。).
synchronized 默认是乐观锁, 但是如果发现当前锁竞争比较激烈 ,就会变成悲观锁.
2. synchronized 既是一个轻量级锁,也是一个重量级锁
synchronized 默认是轻量级,但是发现当前锁竞争比较激烈,就会换成重量级锁.
3. synchronized 这里的轻量级锁,是基于自旋锁的方式实现的
synchronized 这里的重量级锁,是基于挂起等待锁的方式实现的
4. synchronized 不是读写锁
5. synchronized 是非公平锁
6. synchronized 是可重入锁
到此锁策略就学习完成了, 下面我们来看看 CAS
CAS
什么是CAS ?
CAS: 全称Compare and swap,字面意思:比较并交换“,
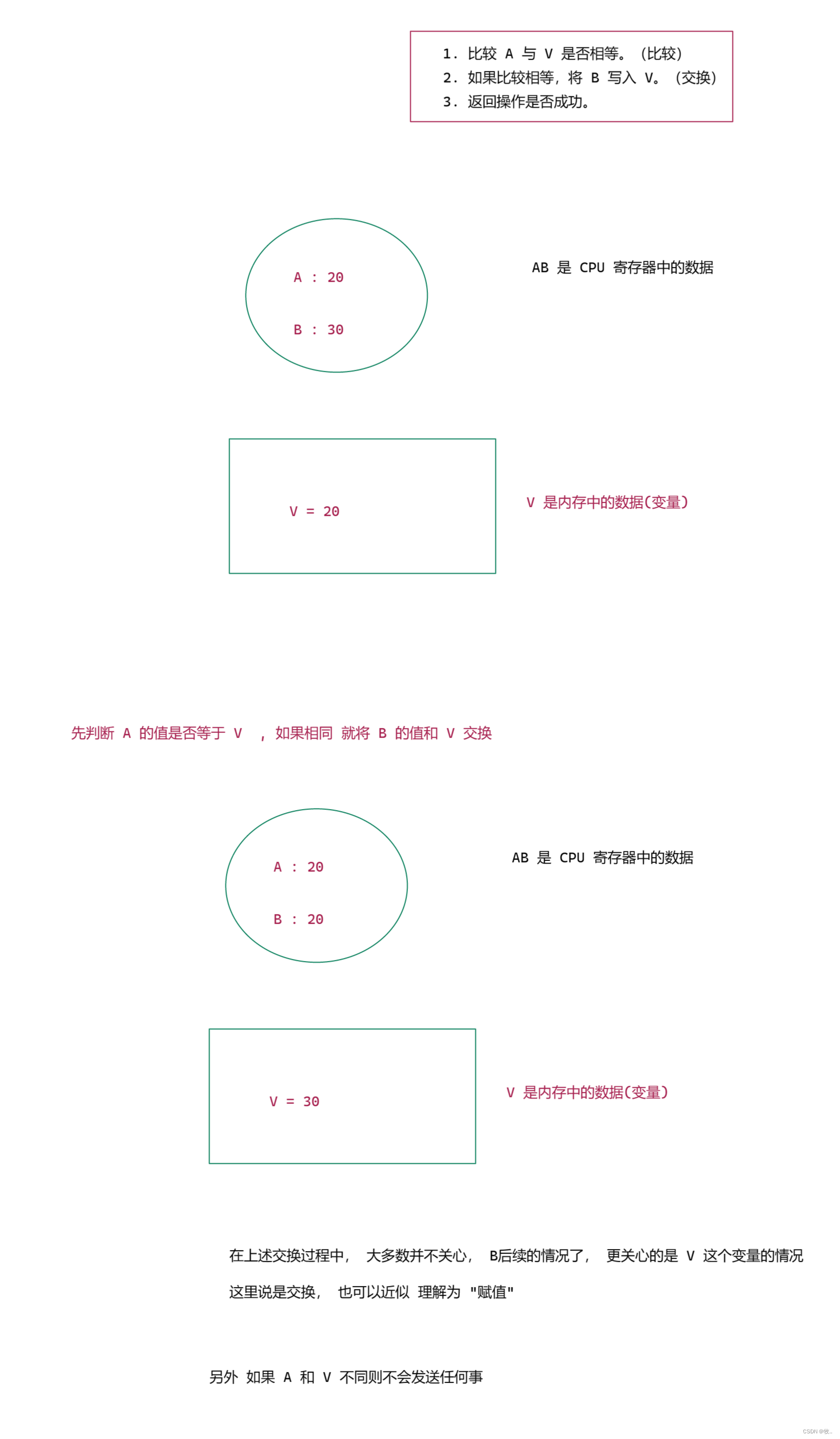
一个 CAS 设计到的 操作 :
假设内除中的原数据 V, 旧的预期值 A ,需要修改的新值 B
1.比较 A 与 V 是否相等 。(比较)
2.如果比较值相等 ,将 B写入 V 。 (交换)
3. 返回操作是否成功
上述的过程就称为 CAS ,此时是不是就有疑惑 ,上述操作有啥特别的吗?
这不就是一个比较和交换吗 几行代码就搞定了 , 其实CAS的过程并非是通过一段代码实现的而是通过一条 CPU 指令完成的。
这里的一条 CPU指令 有一个潜台词 ,指的是 CAS 操作是原子的.
这里本身是原子的 ,所以就可以在一定程度上回避线程安全问题.
这里我们解决线程安全问题除了加锁之外,又有了一个新的方向了。
这里: CAS 可以理解成 是 CPU 给我们提供的一个特殊指令 ,通过这个指令,就可以一定程度的处理线程安全问题.
1. CAS 的应用场景
1.实现原子类
原子类 是java 标准库提供的类, 特点 就是自加 , 自减操作时是原子的。
下面通过代码来了解一下:

下面来看一下实现原子类的伪代码 :
图一 :
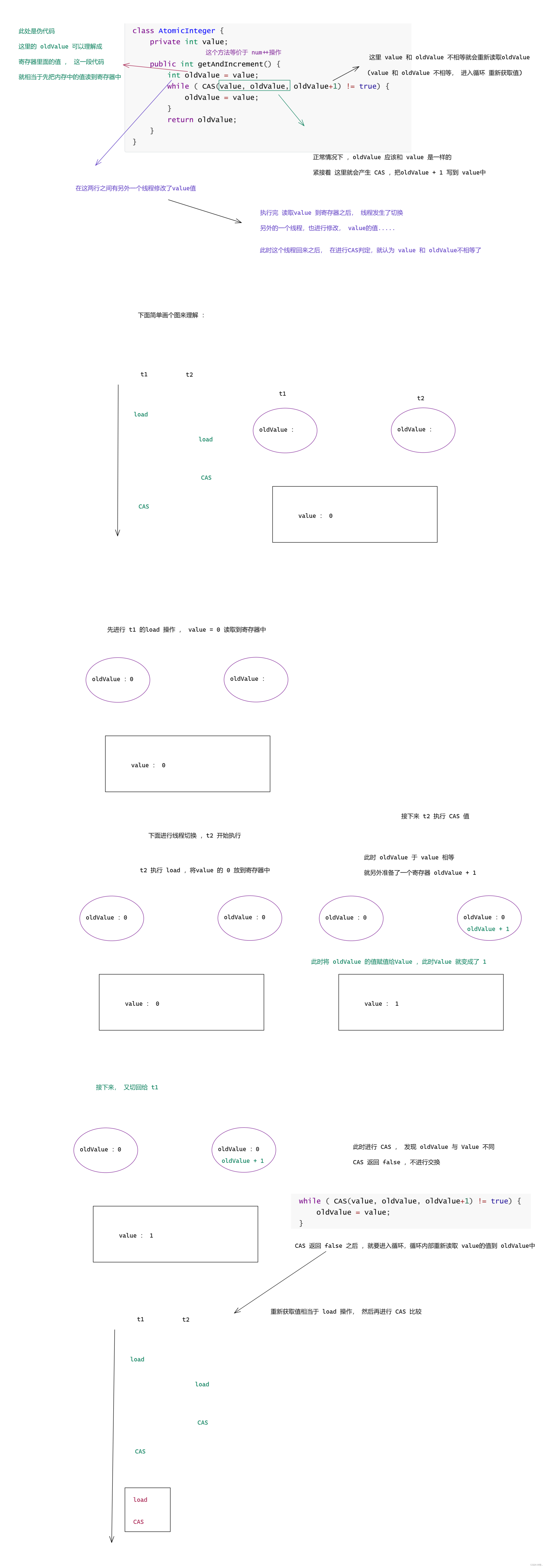
图二 :
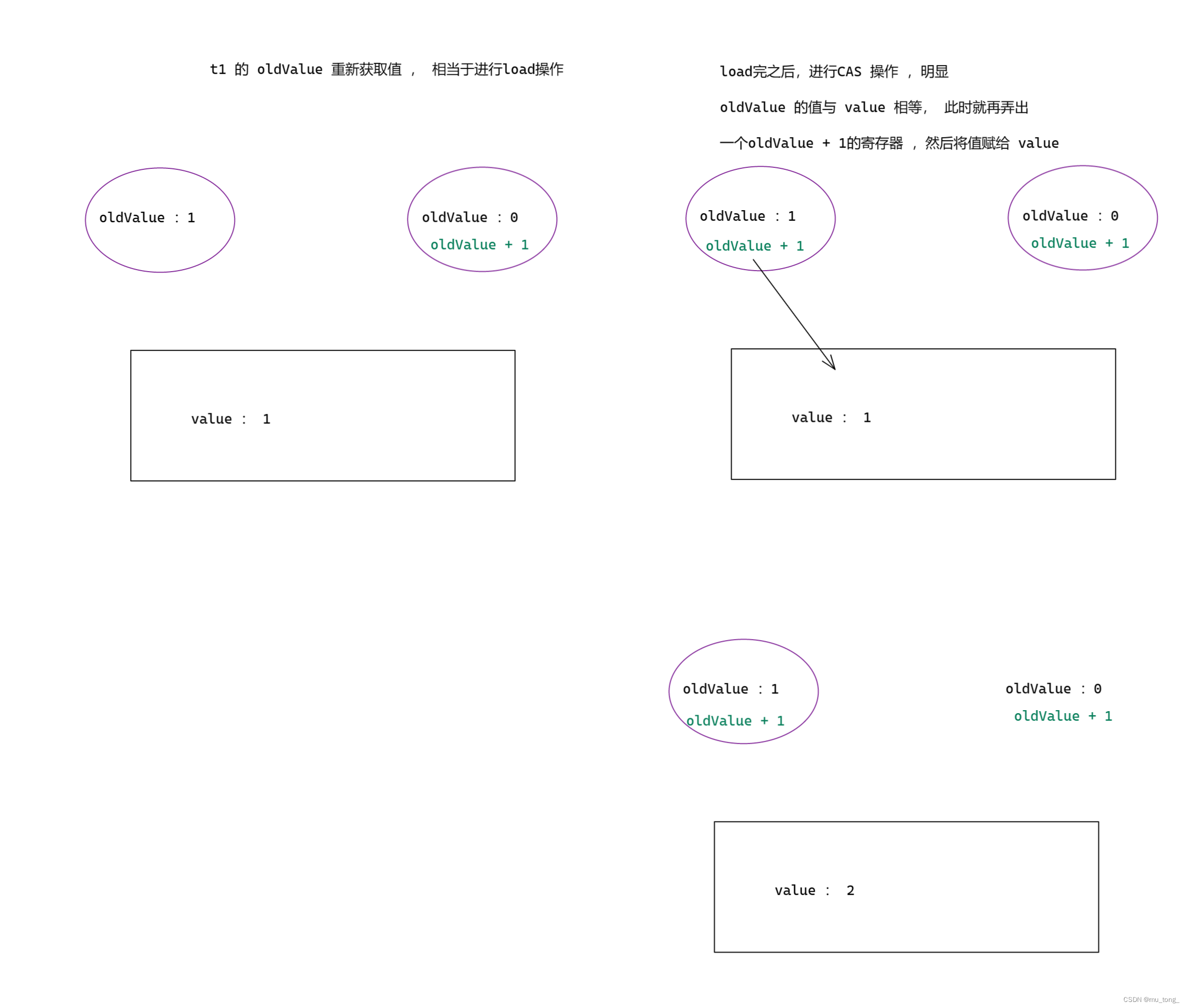
原子类这里的实现,每次修改之前,再确认一下这个值是否符合要求.
2.实现自旋锁

这里CAS 的应用场景看完,下面来了解一下, CAS 的典型问题 : ABA 问题.
2. CAS 的典型问题 : ABA 问题
ABA问题 : CAS 的核心操作是检查 value 和 oldValue 是否一致 ,如果一致 ,就视为 value 中途没有被修改过,所以进行下一步交换操作是没问题的。
但是这里的一致 就有问题 , value值可能没有修改过 ,也可能修改过,但是换元回来了 .
比如 : 将 value的值设为 A 的话 , CAS 判定 value 为 A ,此时可能确实 value 始终是 A , 也可能 value 本来是 A , 被改为了 B ,又被还原成了 A 。
简单来说 ABA 问题 就相当于 : 买部手机 , 我们买到的手机,可能是新机 ,也可能是翻新机 .
因为 翻新机被销售商回收 , 经过一系列翻新操作, 让我们感知不到这是一部新机还是一把翻新机.
这里就是 ABA 问题的重点, 我们无法感知到 value 值是否改变过 .
ABA 这种情况,大部分情况下,其实不会对代码/逻辑产生太大的影响 , 但是不排除一些极端的情况, 也是可能造成影响的。
下面来了解一下极端情况下造成的影响.

下面就来解决一下 ABA 问题
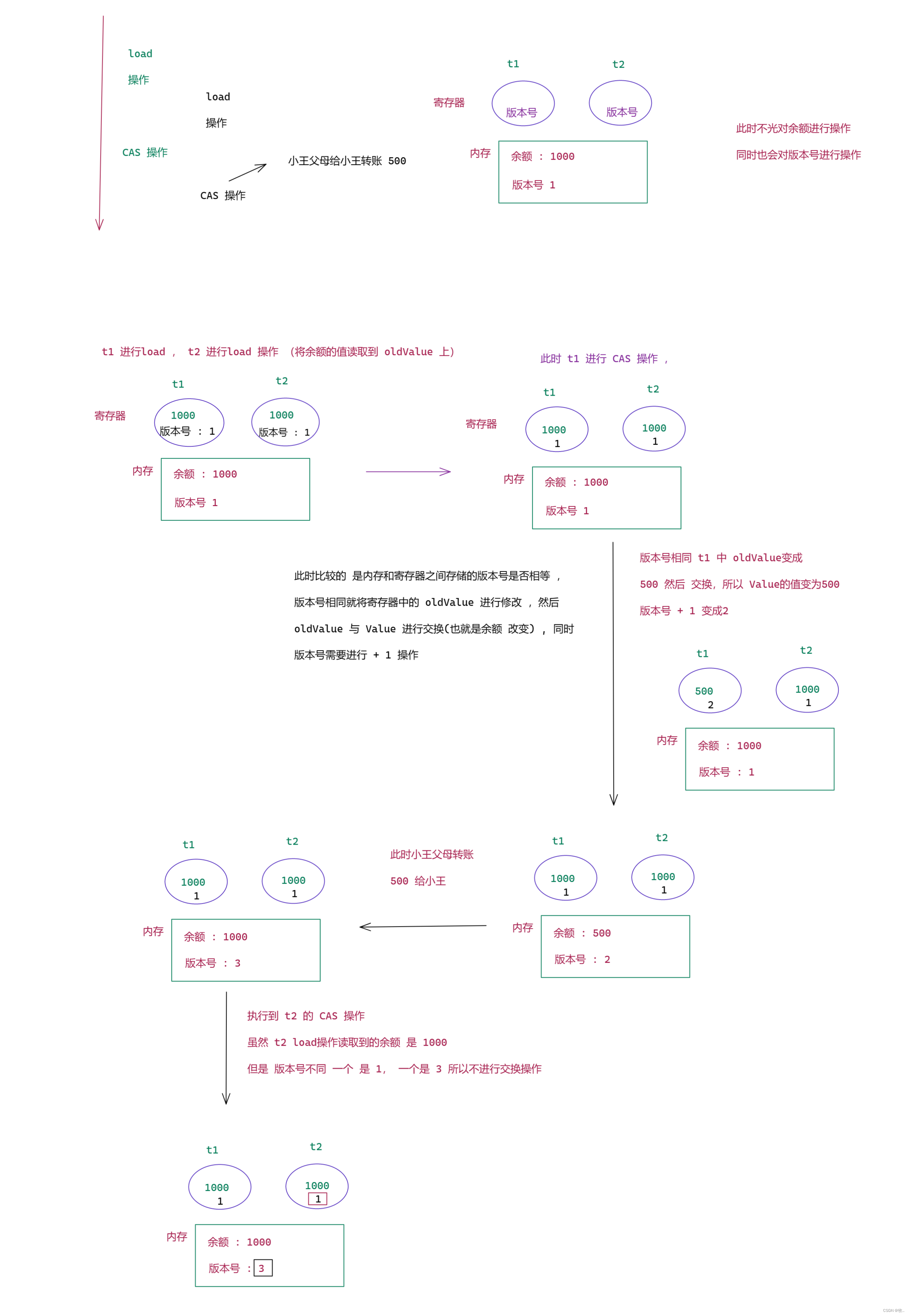
针对ABA 问题 ,采取的方案 ,就是加入一个版本好 , 想象成 ,初始版本号是 1 , 每次修改版本号都 + 1 ,然后进行 CAS 的时候 ,不是以金额为基准了 ,而是以版本号为基准 .
此时版本号要是没变,就是一定没有发生改变 (版本号是只能增长 ,不能降低的 )
简单画个图了解一下 :
这里 CAS 就说这么多,这里也是面试中容易被问到的。
如果 被问到 有关 CAS的 上面这些就极有可能是答案.
下面来看看 synchronized 的原理
synchronized 原理
基本特点 :
- 开始时是乐观锁, 如果锁冲突频繁, 就转换为悲观锁.
- 开始是轻量级锁实现, 如果锁被持有的时间较长, 就转换成重量级锁.
- 实现轻量级锁的时候大概率用到的自旋锁策略
- 是一种不公平锁
- 是一种可重入锁
- 不是读写锁
另外 :两个线程针对同一个对象加锁,就会产生阻塞等待 .
上面这些在锁策略就说过,这里简单来看一看 .
除了上面这些 synchronized 内部其实还有一些优化机制, 存在的目的就是为了让这个锁更高效, 更好用
这里就来看看有啥优化机制 :
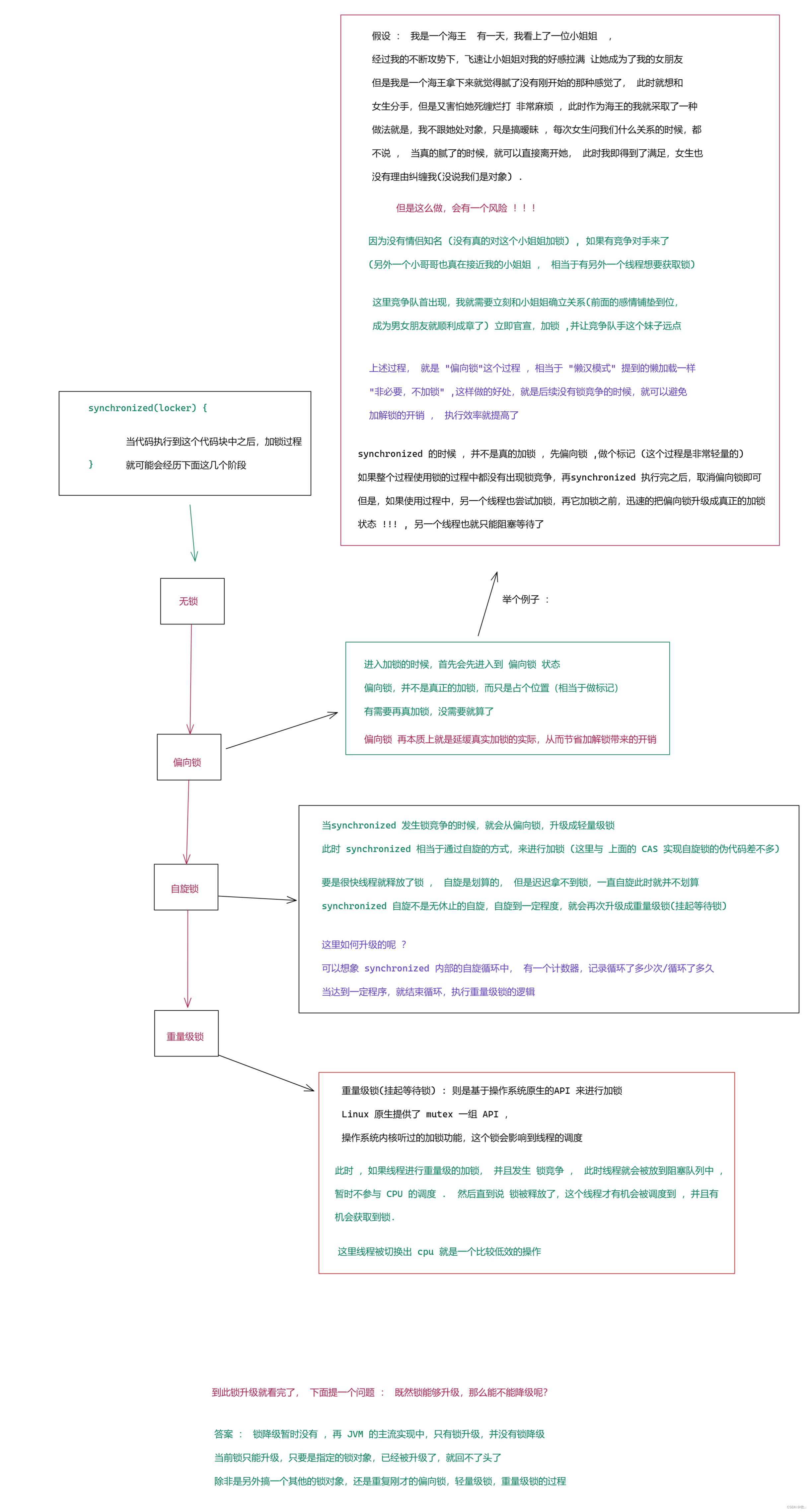
1.锁升级 / 锁膨胀
关于锁升级 , 主要体现 synchronized 能够 自适应 的能力
2.锁消除
锁消除 : 编译器智能的判定 , 看当前的代码是否是真的要加锁, 如果这个场景不需要加锁 ,程序猿加了,就自动把所给去掉.
一个典型场景 :
StringBuffer 相比 StringBuilder 其实就是关键方法都带有synchronized .
如果再单线程使用 StringBuffer , synchronized 加了也白加, 编译器就会直接把这些加锁操作给去掉
3.锁粗化
什么叫锁粗化呢 ?
这里涉及到一个概念, 锁的粒度 , 那么啥叫锁的粒度呢?
锁的粒度 : synchronized 包含代码越多,粒度就越粗 ,包含的代码越少,粒度就越细.
通常情况下 ,认为锁的粒度细一点比较好。
加锁的部分代码是不能并发执行的,锁的粒度越细,能并发的代码就越多,反之就越少
但是有些情况下 ,锁的粒度粗一些反而更好 .
JUC
JUC : java.util.concurrent , 各种集合类 如 : scanner , random…
另外 : concurrent 意思为 : 并发, 这个包内放了很多并发编程(多线程) 相关的组件 .
小提一嘴 : 并发编程,更广义的概念 , 多线程, 是实现并发编程的一种具体方式(同时也是java 中提供的默认的方法)
除了这种方式外 ,还有很多其他方式(其他的并发编程模型) 。
关于 JUC 在学习线程池的时候提到过一嘴,下面来学习一下 JUC 这个包地下的另外一些类.
Callable 接口
Callable 接口 类似于 Runnable 一样 。
Runnable 用来描述一个任务 , 描述的任务没有返回值
Callable 也是用来描述一个任务, 描述的任务是有返回值
下面通过 Callable 来描述一个任务,并拿到返回值
主要任务 : 使用Callable 来计算 1 + 2 + 3 + 4 …+ 1000

这里想要使用 Runnable 也是可以的,只不过 略显麻烦 ,这里就简单来看看即可

callable 看完, 我们来看下一个 JUC 的组件 .
ReentrantLock
来个灵魂问题 : ReentrantLock 咋念 ?
下面就有请有道 :

这里 ReentrantLock 是标准库给我们提供的另一种锁 , 顾名思义 也是 可重入的 。
synchronized 也是可重入锁,为啥还需要 ReentrantLock 呢 ?
还不是因为 ReentrantLock 可以做到一些 synchronized 实现不了的功能 .
下面就来学习一ReentrantLock 的基础用法 .
synchronized 是直接基于代码块的方式来加锁解锁的 , 而ReentrantLock更传统,使用 lock 方法 和 unlock 方法 来进行加锁和解锁的。
图一 :

图二 :

ReentrantLock 就看到这里,实际开发 还是以 synchronized 为主,下面我们来看看原子类 .
原子类
原子类 内部 用的是 CAS 实现 , 所以性能要比加锁实现的 i++ 高很多 。
原子类有以下几个 :
- AtomicBoolean
- AtomicInteger
- AtomicIntegerArray
- AtomicLong
- AtomicReference
- AtomicStampedReference
这里还是拿出之前在 CAS 说过的 Atomiclnteger 来看看
addAndGet(int delta); i += delta;
decrementAndGet(); --i;
getAndDecrement(); i--;
incrementAndGet(); ++i;
getAndIncrement(); i++;
另外 : 虽然基于CAS , 确实是更高效的解决了线程安全问题,但是CAS 不能代替锁, CAS 适用范围是有限的,不像锁适用的范围那么广.
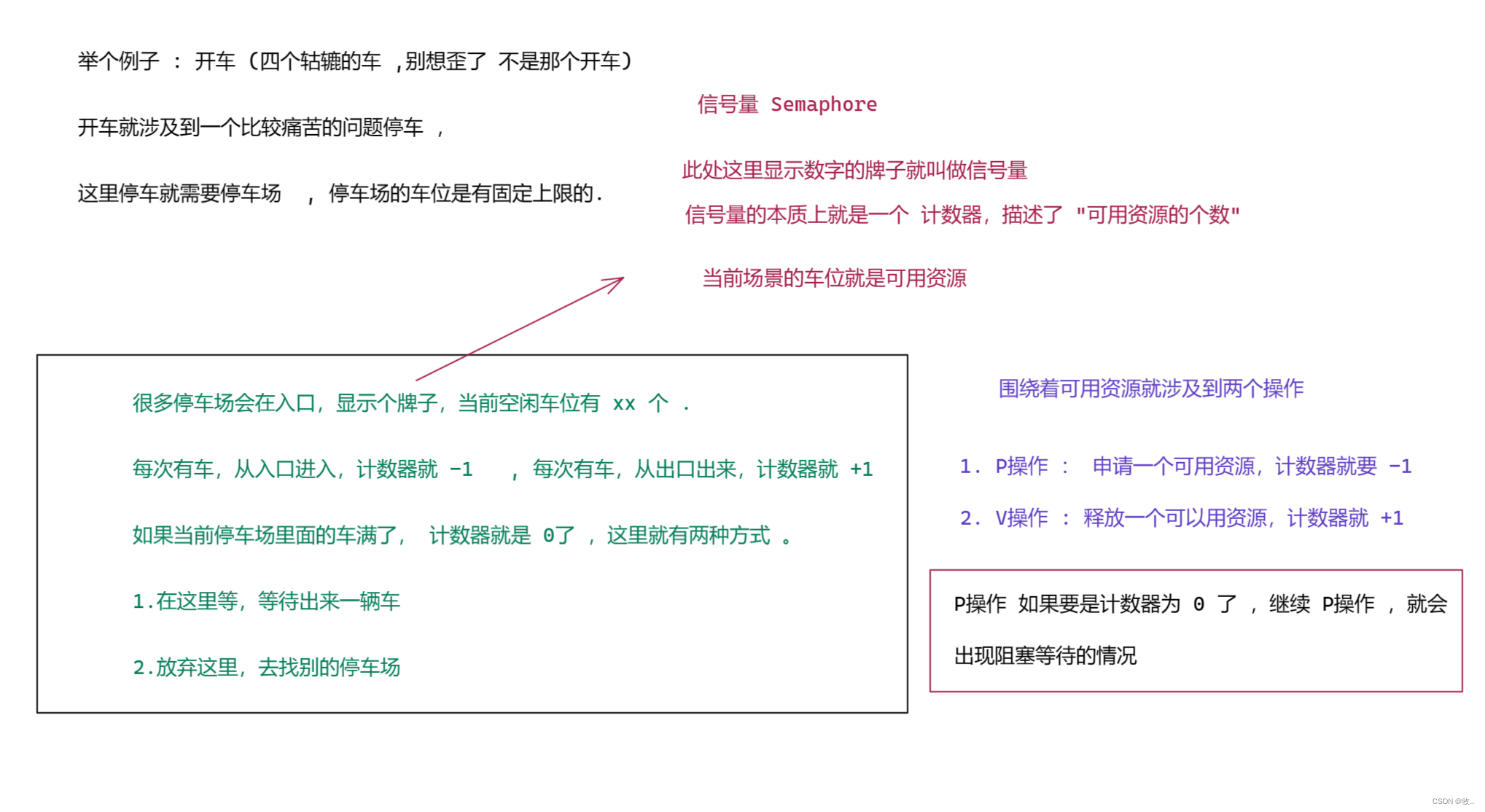
信号量 - Semaphore
还是那个灵魂问题 : Semaphore 咋读呢?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zoJNjpgt-1674437727837)(C:\Users\A\AppData\Roaming\Typora\typora-user-images\image-20230110190414799.png)]
下面就来学习一下这个信号量 :
了解 : 一些背景知识
这里的 P 和 V 是哪个英文单词的缩写?
很遗憾,这里没有对应的英文单词。
因为提出“信号量”的人,叫做“迪杰斯特拉”(数学家)。
数据结构中的图 里面有一个算法叫做“迪杰斯特拉算法”,能够计算两点之间的距离。这也是他提出的。
他是一个芬兰人,P 和 V 是芬兰语的单词缩写。
意思在英文中对应的单词,P:acquire 申请,V:release 释放
即 P 和 V 操作,又被称为 acquire 和 release 操作。
这里关于信号量还有一个重要的要点 , 考虑一个计数初始值为 1 的信号量 .
针对这个信号量的值,就只有 1 和 0 的两种取值 !!! (注意 : 信号量不能是 负的)
执行一次 P操作 , 1变为 0
执行一次 V 操作 , O 变为 1
如果已经进行一次 P 操作了, 继续进行P 操作 就会阻塞等待 .
看完这个有没有啥感觉, 会不会有种这不就是锁的感觉?
比如 :线程 1 获取到锁, 线程二再获取同一把锁时 就会阻塞 , 这不就是上面的执行一次 P 操作, 1 变为 0 , 然后再执行一次 P 操作,此时就会阻塞.
是不是很像 , 其实我们的锁就可以视为是计数器 为 1 的信号量 , 二元信号量。
因此 锁是信号量的一种特殊情况 , 信号量就是锁的一般表达.
在实际开发中,虽然锁是最常用的, 但是信号量也是会偶尔用到的, 主要还是看实际的需求场景 。
举个例子 : 图书馆 借书
假设图书馆里有一本书(java 从入门 到放弃) 有 20本 ,此时就可以使用一个初始值为 20的信号量来表示 , 每次有同学借书 ,就进行 P 操作 ,每次有同学来还书就进行 V操作 ,如果计数器为 0了, 还有同学想要继续借这本书 ,此时就需要等待.
知道了 信号量 - Semaphore 可能会使用到,下面就来简单的看看如何使用 :

信号量看完,来看一下 CountDownLatch 这个组件
CountDownLatch
关于CountDownLatch 暂时没有啥号的中文翻译, 这里可以理解为 中点线的意思.
下面直接来看用例 :

上面这些组件了解即可, 关于多线程的知识之前的文章才是重点 。
下面继续 来看一下, 线程安全的集合类
线程安全的集合类
在之前的文章中提到过一嘴 , 那些类是线程安全的, 那些类不是 .
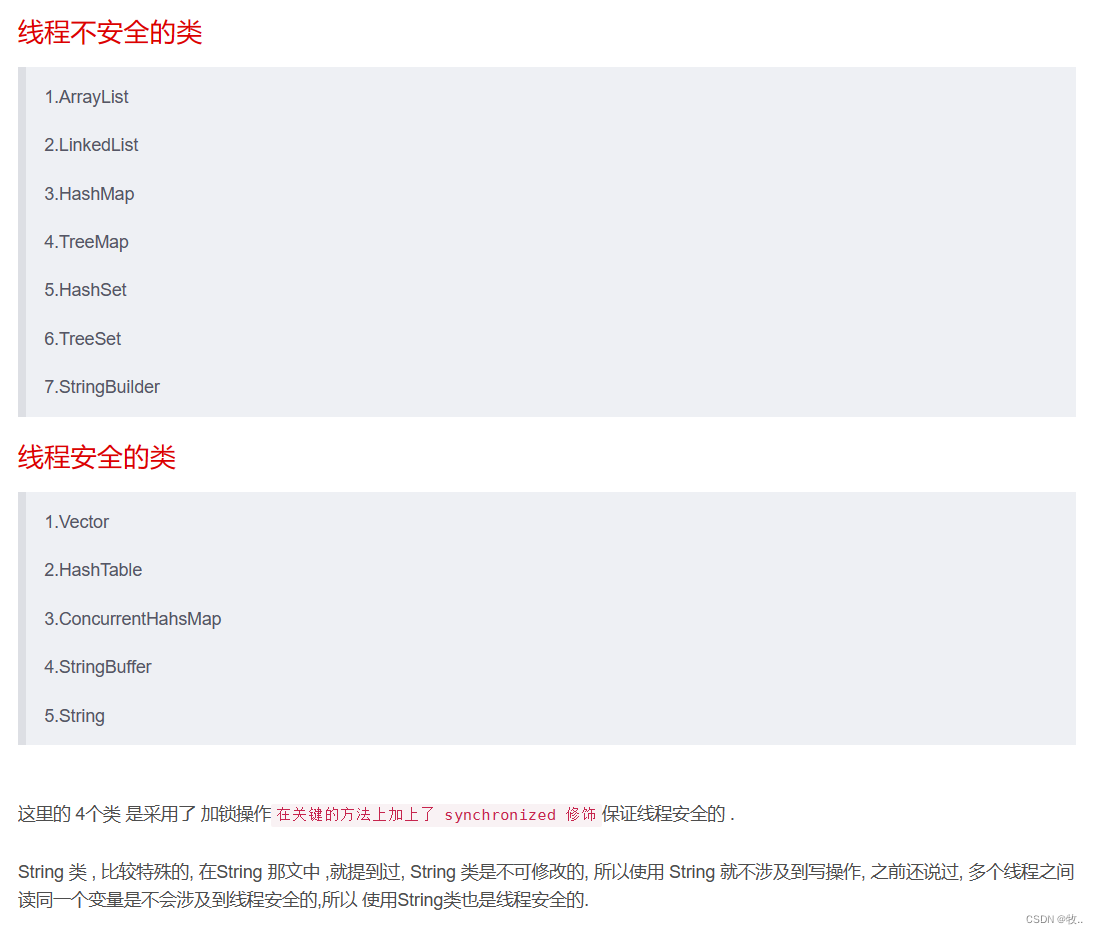
另外 在java 标准库里面 大部分集合类都是 “线程不安全” 的 , 多个线程使用同一个集合类对象, 很可能会 出现问题 .
vector , Statck , HashTable 这几个类是少数的线程安全的集合类 ,关键方法带有 synchronized , 但是不咋推荐使用,因为使用这几个类就有点无脑加锁的感觉, 在很多场景下是不需要加锁的 ,你使用了这些类就加上了锁。
既然 使用不咋推荐使用这些线程安全的集合,那么在多线程下,想要使用集合要如何处理呢?
好问题 ,下面就来通过在多线程环境下使用一下 ArrayList
多线程环境下使用 ArrayList
这里有三个方法 :
1.自己加锁 , 自己使用 synchronized 或者 ReentrantLock[这种比较常见] (这种方法 不就是求人不如求己吗, 既然线程安全的类 会无脑加锁,那么我自己加,在 需要的场景下加,不需要的场景下不加)
2.使用 Collections.synchronizedList 这里会提供一些 ArrayList 相关的方法,同时是带锁的 , 使用这个方法把集合类套一层 (用的少, 本质上就是方法一)
3.使用 CopyOnWriteArrayList 这里可以简称为 COW 也做 “写时拷贝”
如果针对这个ArrayList 进行读操作 ,不做任何额外的工作 ,
如果进行写操作 ,则拷贝一份新的ArrayList ,针对新的进行修改 , 修改过程中如果有读操作 , 就继续读旧的这份数据,当修改完毕了,使用新的替换旧的(本质旧时一个引用之间的赋值, 这里的赋值操作是原子的)

很明显当前这种方案的优点是不需要加锁,缺点则是要求这个ArrayList不能太大,因为每次都需要拷贝一份副本 , 如果ArrayList 太大拷贝的时间可能比加锁的还大,此时还不如加锁.
所以这种方法只是使用于这种数组比较小的情况
这里服务器配置和维护就会用到写实拷贝的 思路,
回想一下我们在MySQL 里面是不是修改过配置文件, 让我们的字符集变为 utf8 ,并且重启MySQL的服务器,让它能够识别中文 ,这里重启服务器也同理,当
我们需要更新某些配置文件的时候就需要重新启动 , 但是 想象某些大公司 有很多服务器,如果想要重启就必须要一个一个的来, 比如百度假设重启 一台服器,
可能需要 5分钟 ,假设有20台,此时就需要等待100分钟是非常浪费时间的 , 此时肯定会有疑惑为啥不一起重启呢? 你想 百度每分钟的搜索量有多少,这些都是
请求是需要服务器返回响应的,在这服务器重启的时间内,是会损失很多请求 , 就会影响的用户体验,导致产品口碑下降 等一系列问题。 所以这里才会一台一台的重启,一台重启 并不会对剩下的服务器带来很大的影响 , 可以看到这种更新配置文件需要重启是非常麻烦的,因此很多服务器都提供了 热加载(reload) 这样功能 , 通过这样的功能就可以不重启服务器实现配置的更新.
热加载的实现,就可以使用 写实拷贝 的思路
新的配置放到新的对象中 , 加载过程里,请求仍然基于旧配置进行工作
当新的对象加载完毕,使用新对象替换旧对象(替换完成之后,旧的对象就可以释放了)
多线程环境下使用队列
1、 ArrayBlockingQueue:基于数组实现的阻塞队列
2、 LinkedBlockingQueue:基于链表实现的阻塞队列
3、 PriorityBlockingQueue:基于堆实现的带优先级的阻塞队列
4、TransferQueue:最多只包含一个元素的阻塞队列
上面这几个是不是很熟悉 在之前的多线程 4 文章中 几个关于多线程的代码案例就说过 , 所以这里不在继续赘述 另外第四个用的少这里也不说了。
最后来看一下 多线程环境下使用 哈希表 这个也是面试容易考的
多线程环境下使用哈希表
HashMap 是线程不安全的,所以在多线程下一般不推荐使用 。
这里HashMap 用不了,可以使用 HashTable
HashTable 是线程安全的 , HashTable 给关键方法加了synchronized 所以是线程安全的 。
明显 HashTable 也不是一个很好的选着, 还是那个问题,并不是每个场景下就需要加锁,这里 无闹使用 HashTable 就相当于无脑加锁 , 稍微看一下 HashTable 的源码
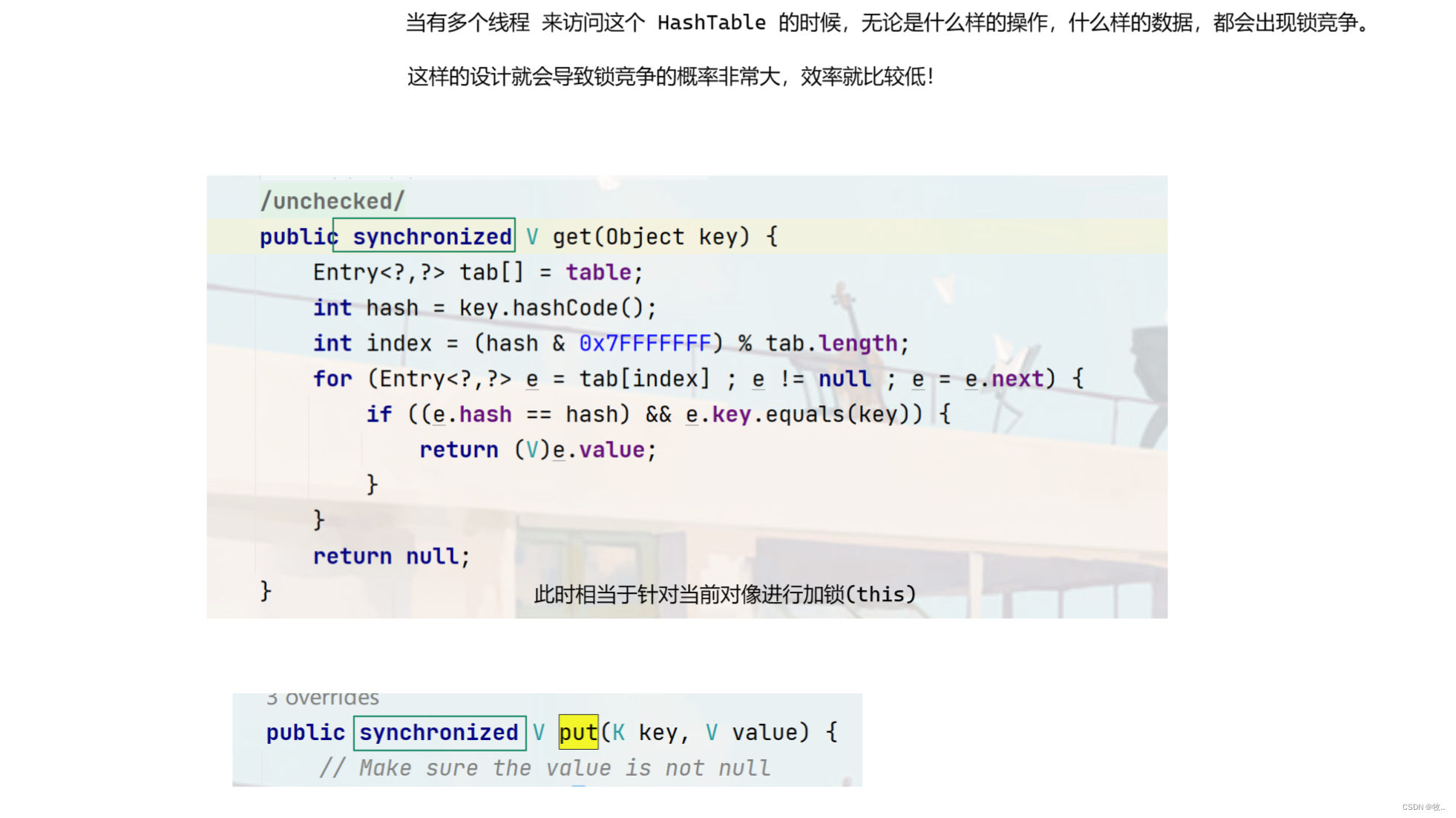
既然 HashMap 和 HashTable 就不推荐使用 ,那么到底使用啥呢 ?
这里我们一般推荐使用 ConcurrentHashMap 更优化的线程安全哈希表 。
引出了 ConcurrentHashMap , 那么下面来看一下考点(面试容易被问到)
考点 : ConcurrentHashMap 进行了那些优化 ? 好在哪里 ?和 HashTable 之间的区别是啥? (这三个问题其实就一个)
这里就来解决一下上面这个问题 .
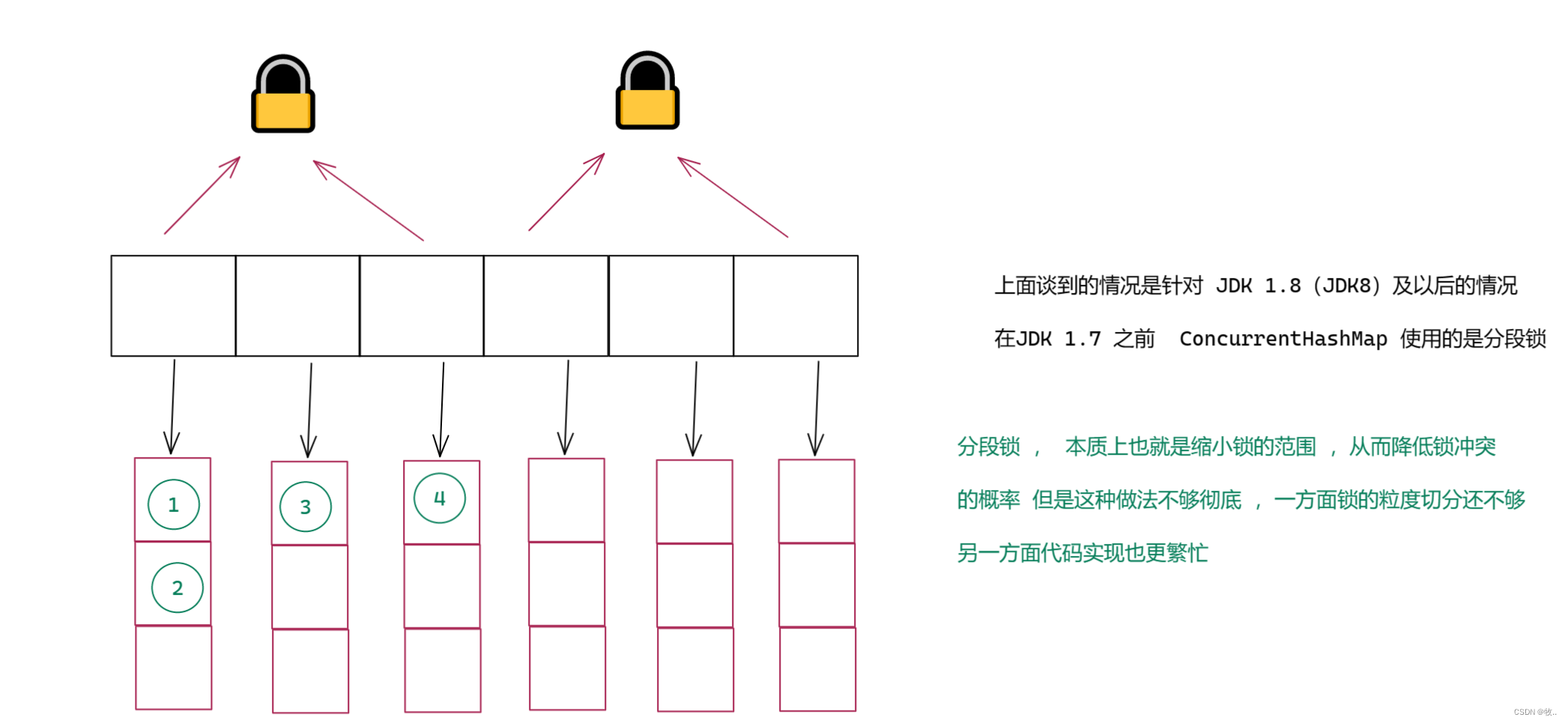
第一个 也是最大的优化之处 : ConcurrentHashMap 相当于比 HashTable 大大缩小了锁冲突的概率 ,将一把大锁转化为多把小锁 .
这里将一把大锁转化成多把小锁啥意思呢?
解释 : HashTable 做法是直接在方法上加 synchronized 等于 是给 this 加锁(刚刚看 put 和 get 方法也可以知道直接再加方法上,相当于给this加锁) 只要操作哈希表上的任意元素 , 都会产生锁也就都可能会发生锁冲突.
但实际上,仔细思考不难发现,其实基于哈希表的结构特点,有些元素在进行并发操作的时候,是不会产生线程安全问题,也就不需要使用锁控制.
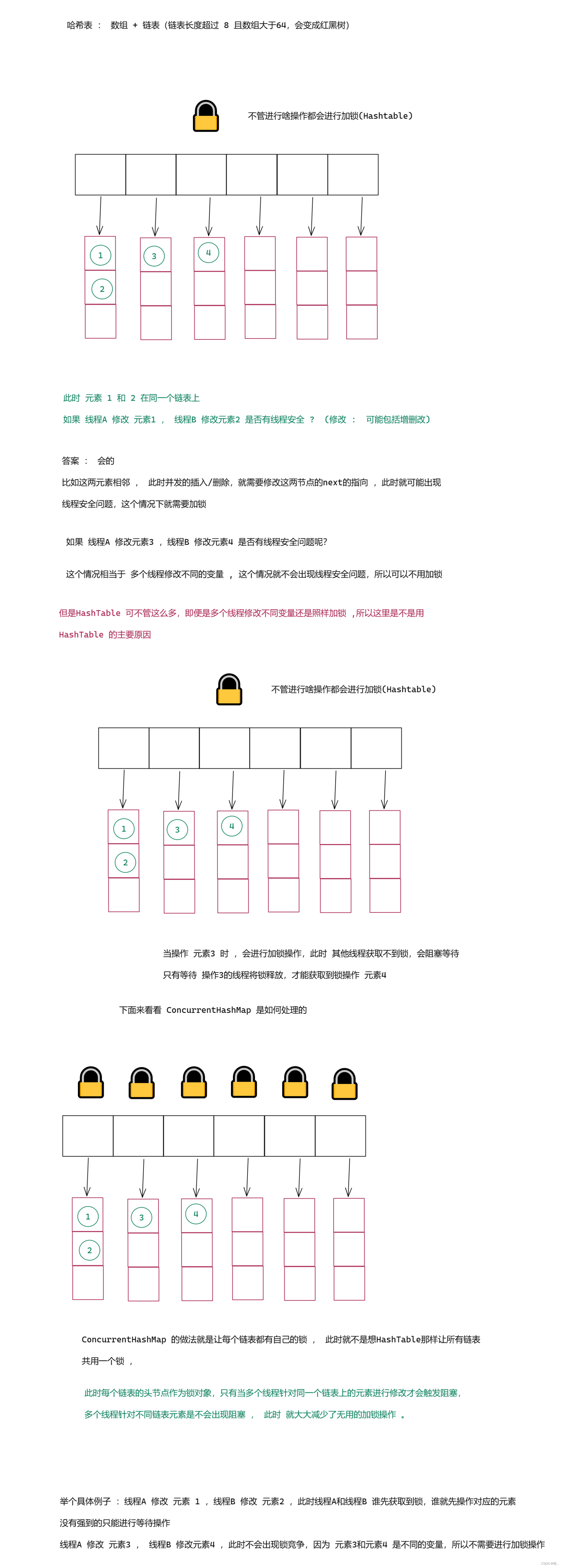
了解 :分段锁
第二个 : ConcurrentHashMap 做了一个激进的操作
针对读操作 , 不加锁 ,只针对写操作加锁.
这里与读写锁还有区别 :
这里 读和读没有冲突 ,
写和写之间 有冲突
读和写之间也没有冲突 (这里就与读写锁冲突了,在很多场景下,读写之间不加锁控制,可能会读到一个写了一半的结果,如果写操作不是原子的, 此时读就可能会读到写了一半的数据)
这里ConcurrentHashMap 是通过 volatile + 原子的写操作 ,保证了写操作是原子的,另外volatile 也解决了内存可见性问题
第三个 : ConcurrentHashMap 内部充分的使用了CAS , 通过这个进一步的消减加锁操作的数目
第四个 : 针对扩容,采取了 化整为零 的方式
回忆一下 :HashMap / HashTable 扩容 :
是不是创建一个更大的数组空间,把旧的数组上的链表的每一个元素搬运到新的数组上(删除 + 插入) .
这个扩容操作会在某次 put 的时候进行触发 .
如果元素个数特别多 ,就会导致这样的搬运操作,比较耗时 , 就会出现,某次 put 比平时的put卡很多倍 (用户的感受,大部分用户用着好好的,某个用户就卡了)
针对上面这个问题,就可以采用化整为零来解决
ConcurrentHashMap 中 ,扩容采取的是每次搬运一小部分元素的方式 , 创建新的数组, 旧的数组也保留 。
每次 put 操作,都往新的数组上添加,同时进行一部分搬运(把一小部分旧的元素搬运到新数组上)
每次get 的时候 则旧数组和新数组都查询
每次 remove 的时候,把元素删了即可
经过一段时间之后,所有的元素都搬运好了,最终再释放旧数组.















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









