






文章目录
前言
参考博客和视频
b站视频:
我是土堆 up主的教程视频
GPU版本:
https://blog.csdn.net/weixin_38909544/article/details/104807749
https://blog.csdn.net/qq_40710418/article/details/109100802
CPU版本:
https://blog.csdn.net/qq_52178584/article/details/132807684
一、深度学习环境了解
深度学习环境的配置分为两种:CPU版本(无显卡版本)和GPU版本(有显卡版本),本文即介绍的是GPU版本。
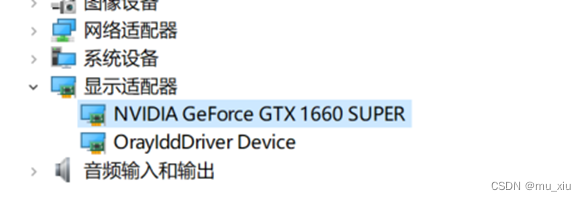
可以通过百度搜索,查看电脑是否有显卡的方式。具体的示意图如下所示:
搭建环境原理和流程如下图所示,图片来源自【我是土堆】up


Anaconda配置虚拟环境在大多教程中都建议安装Jupyter Notebook,安装的过程中容易报错,出各种bug。目前笔者没有发现不安装有啥后果,可以不安。
二、配置环境的步骤
具体的环境要求参见下载代码的requirement.txt,结合版本兼容问题,做出调整,比如最终下载的tensorflow_gpu版本是1.15.0的。

1.安装CUDA和CUDNN
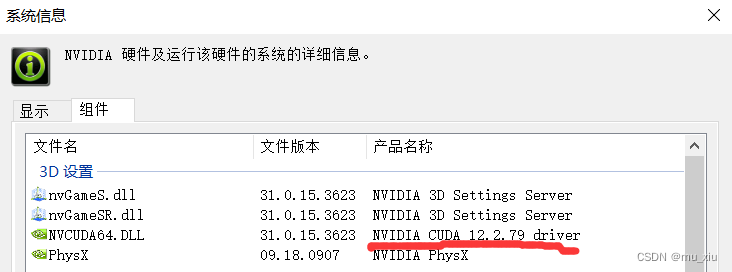
比如笔者的电脑上的驱动型号是12.2.X的,下载的CUDA runtime版本(即CUDA)要小于12.2.X的。结合CSDN1660super成功的经验,最后选取10.0版本的CUDA,以及V7.4版本的CUDNN。

安装CUDA和CUDNN的具体步骤,可以见下面的链接所示的博客:
https://blog.csdn.net/qq_40710418/article/details/109100802
2.安装anaconda,并利用anaconda prompt配置环境
笔者下载的anaconda版本是3.0的,这个版本的使用人数比较多。
具体的安装步骤可见博客:
https://blog.csdn.net/qq_28053421/article/details/117875784
接下来用到anaconda的命令行窗口Anaconda Prompt,创建python环境。
例如,创建名称为py36的,python3.6的环境
conda create --name py36 python=3.6
创建成功后激活环境,之后安装其他库都在新创建好的环境中进行。
conda activate py36
离开环境:
conda deactivate
遇到安装速度较慢的情况,可以采用镜像下载。可以在安装代码上添加镜像网址(有时候会出现报错的情况)也可以直接将镜像网站添加到下载路径。
pip install easydict==1.7-i https://pypi.tuna.tsinghua.edu.cn/simple
tensorflow的安装
一定要在官网看好,找好和CUDA,CUDNN对应的版本。
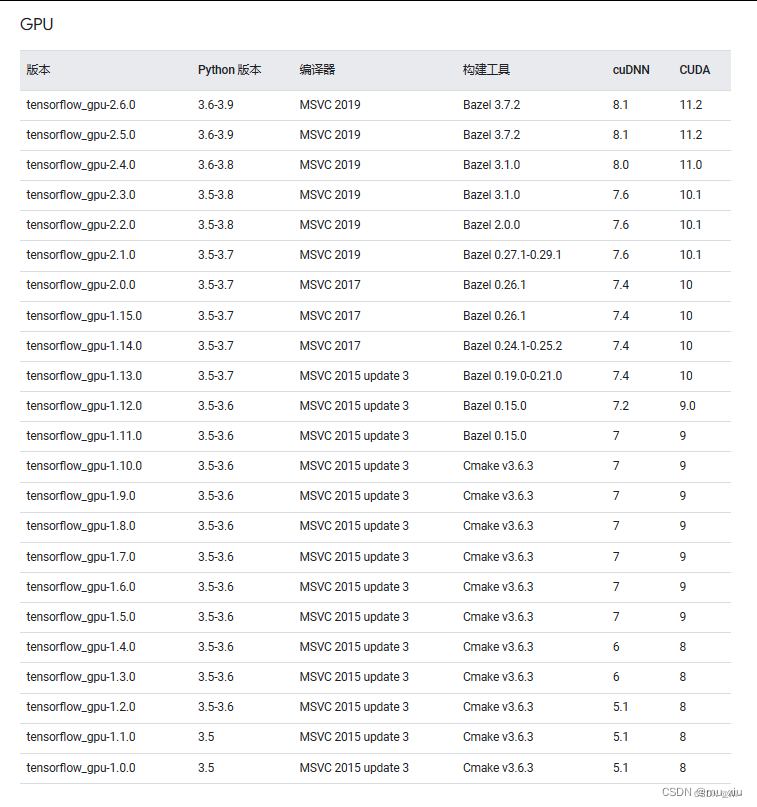
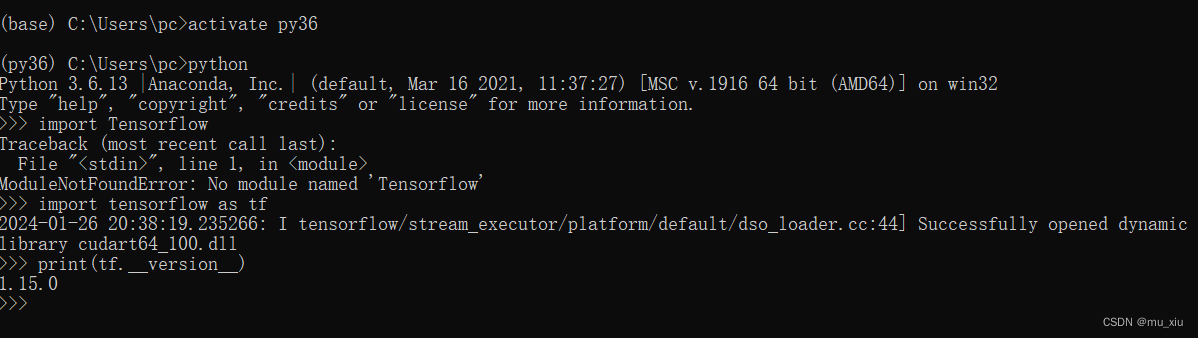
安装好了以后可以在py36中检验:
python
import tensorflow as tf
print(tf.version)
可以参考博客:
https://blog.csdn.net/ly869915532/article/details/124542362
https://blog.csdn.net/m0_68233404/article/details/128525860
3.安装pycharm,并导入anaconda创建的环境。
一定要看准,导入到新创建的python环境。
具体步骤可以参考博客:
https://blog.csdn.net/qq_28053421/article/details/117875784
http://t.csdnimg.cn/QMZGF
创建一个新的python文件,检验是否能调用gpu.
import tensorflow as tf
import timeit
def cpu_run():
with tf.device('/cpu:0'):
cpu_a = tf.random.normal([10000, 1000])
cpu_b = tf.random.normal([1000, 2000])
c = tf.matmul(cpu_a, cpu_b)
return c
def gpu_run():
with tf.device('/gpu:0'):
gpu_a = tf.random.normal([10000, 1000])
gpu_b = tf.random.normal([1000, 2000])
c = tf.matmul(gpu_a, gpu_b)
return c
cpu_time = timeit.timeit(cpu_run, number=10)
gpu_time = timeit.timeit(gpu_run, number=10)
print("cpu:", cpu_time, " gpu:", gpu_time)
运行成功标志:

至此,可以优雅地使用配置好的环境了。(bushi)

















 4139
4139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









