








1912年4月15日,泰坦尼克号在首次航行期间撞上冰山后沉没,船上共有2224名乘客和乘务人员,最终有1502人遇难。沉船导致大量伤亡的重要原因之一是,没有足够的救生艇给乘客和船员。虽然从这样的悲剧性事故中幸存下来有一定的运气因素,但还是有一定规律可循的,一些人,比如妇女、儿童和上层人士,比其他人有更高的存活可能性。泰坦尼克号事件留下了“弥足珍贵”的数据记录。如前所述,乘客的幸存率存在一定的规律,因此这些数据记录集成了Kaggle上流行的入门机器学习的数据集。同时,又由于该数据集中的记录不完整,存在缺失值、异常值等,因此也成了很典型的练习数据分析的数据集。
1. 预览数据
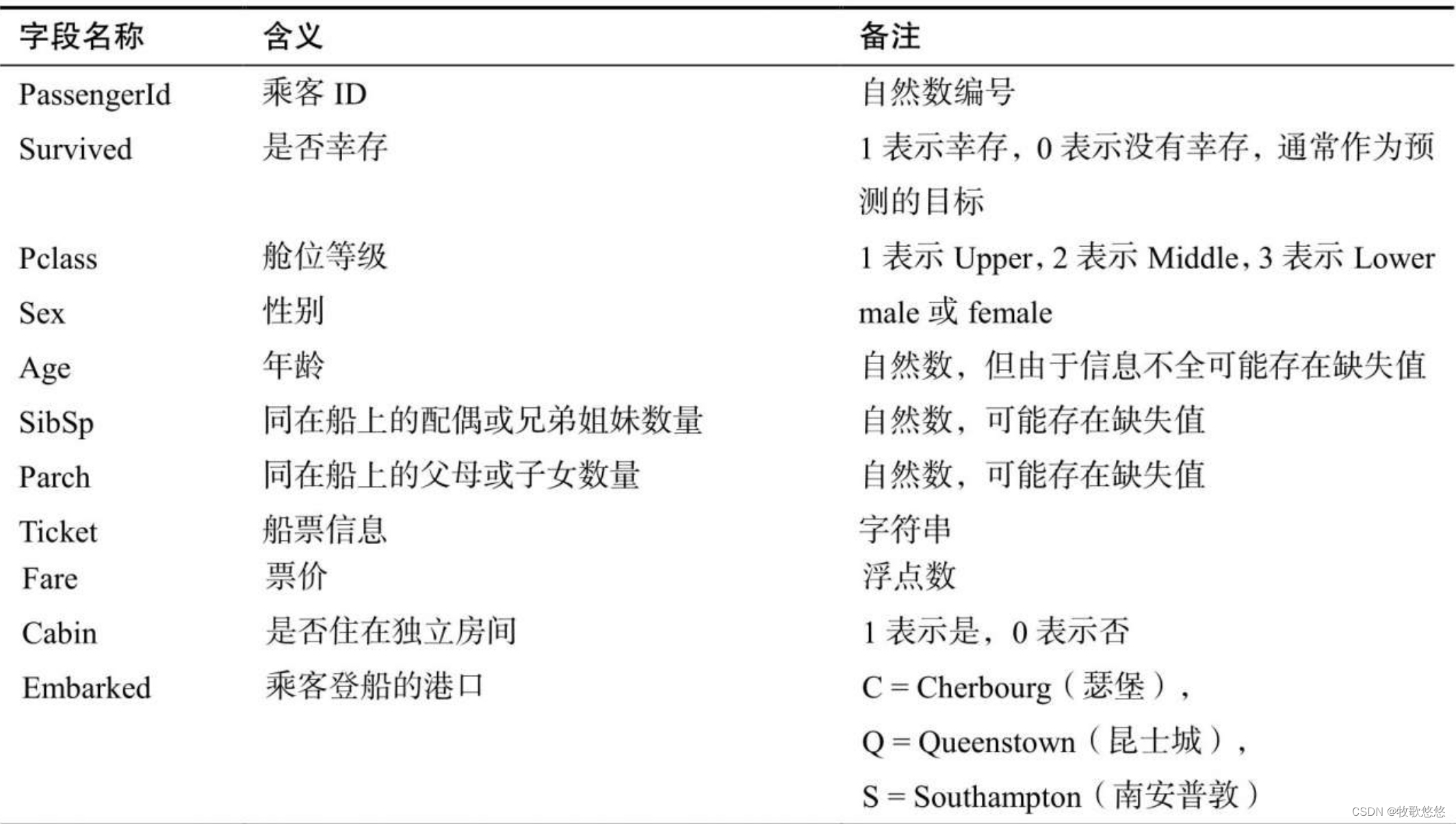
由于我们用到的数据集是CSV格式的,所以直接利用Pandas提供的read_csv()方法来读取数据即可。在将数据读取到内存之后,最好对数据进行简单的预览(使用head()方法)。预览的目的主要是了解数据表的大小、字段的名称及数据格式等。这为理解数据及后续的数据处理工作做了铺垫。

2. 获取该数据集的更多信息
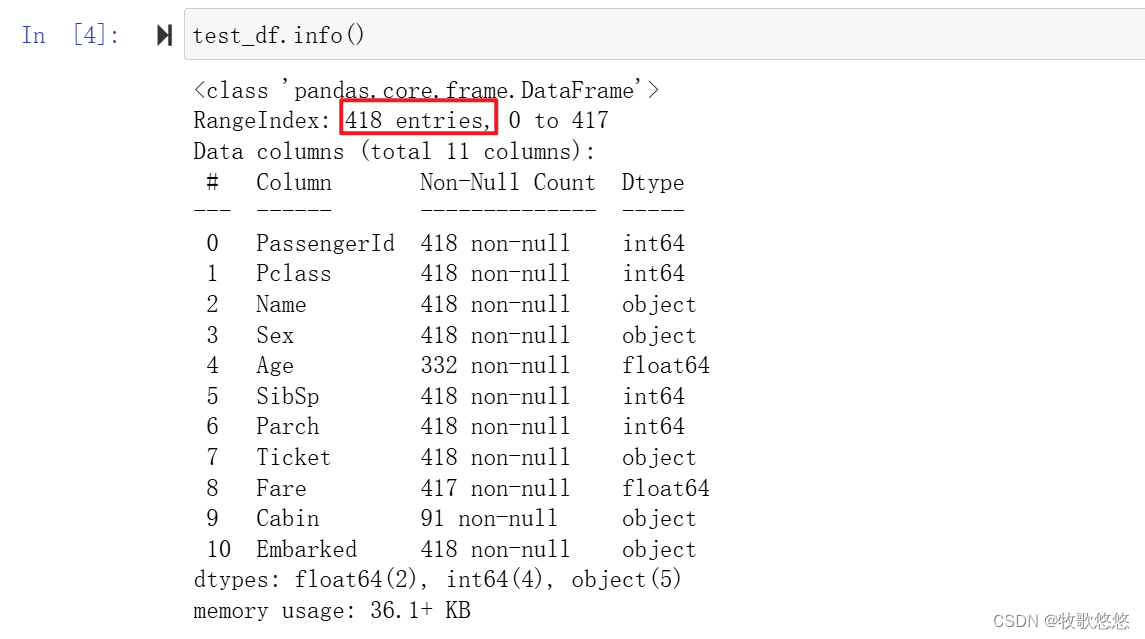
我们还可以用shape属性和info()方法来获取该数据集的更多信息


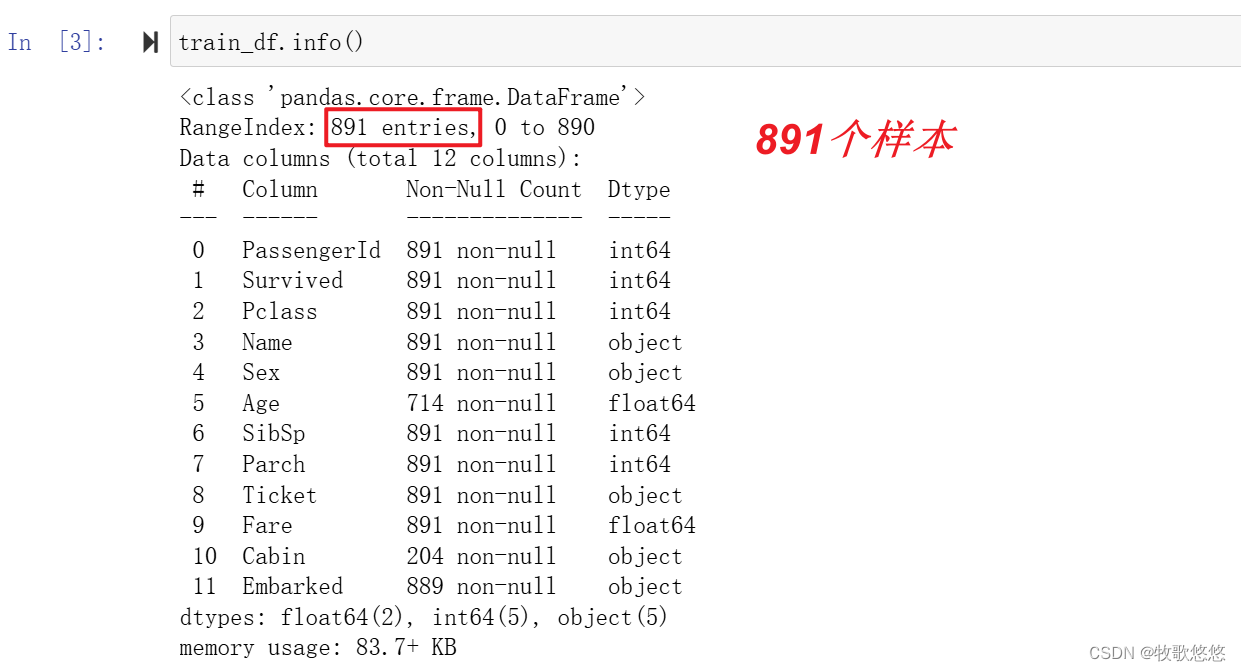
从上面的输出不仅可看出每个字段的数据类型,更重要的是,还可从每个字段的计数信息看出,Cabin相比于其他字段仅有204个有效数据,数据缺失严重。
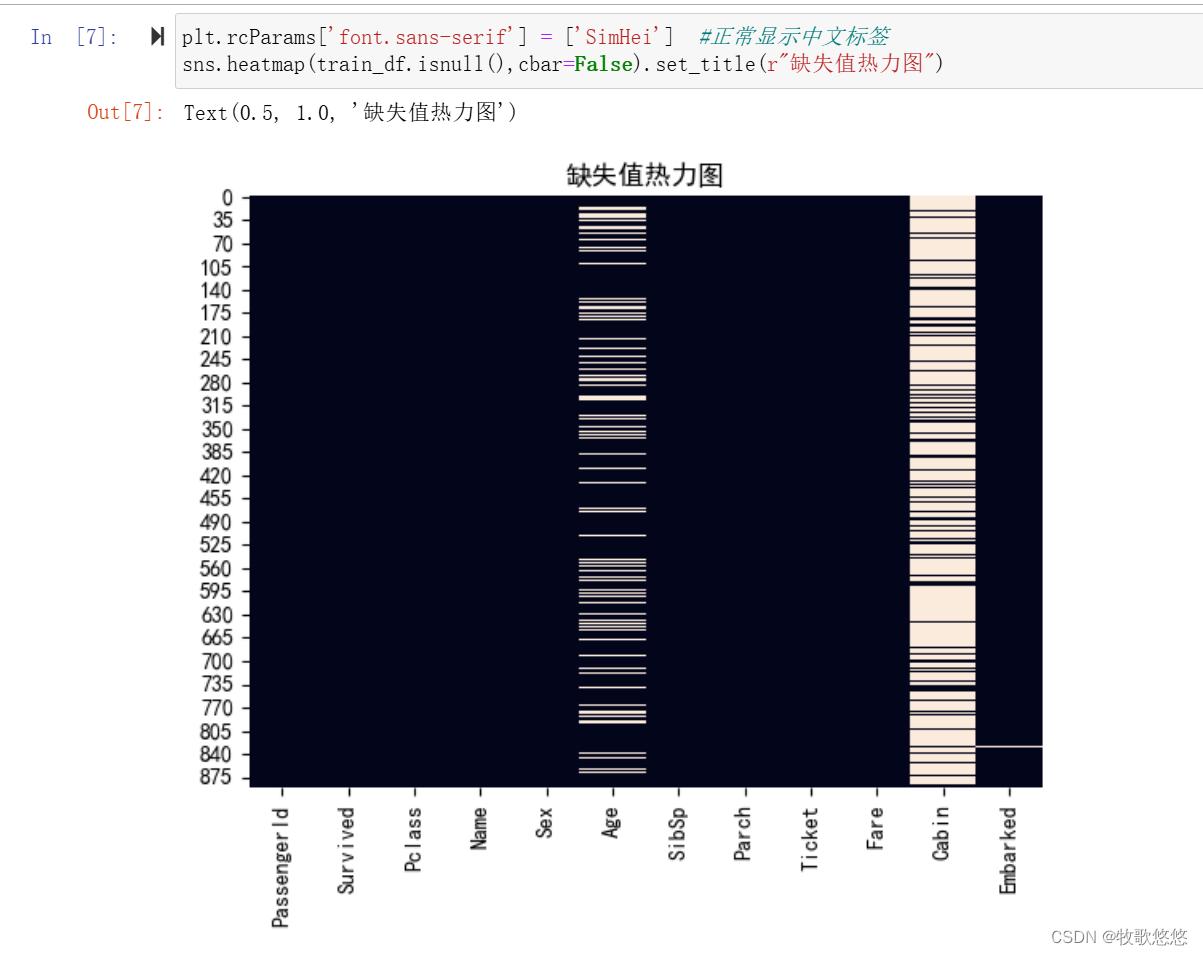
对于泰坦尼克幸存者数据集,我们也可以借助于热力图来查看缺失值的情况。
plt.rcParams['font.sans-serif'] = ['SimHei'] #正常显示中文标签
sns.heatmap(train_df.isnull(),cbar=False).set_title(r"缺失值热力图")
3. 数据分布
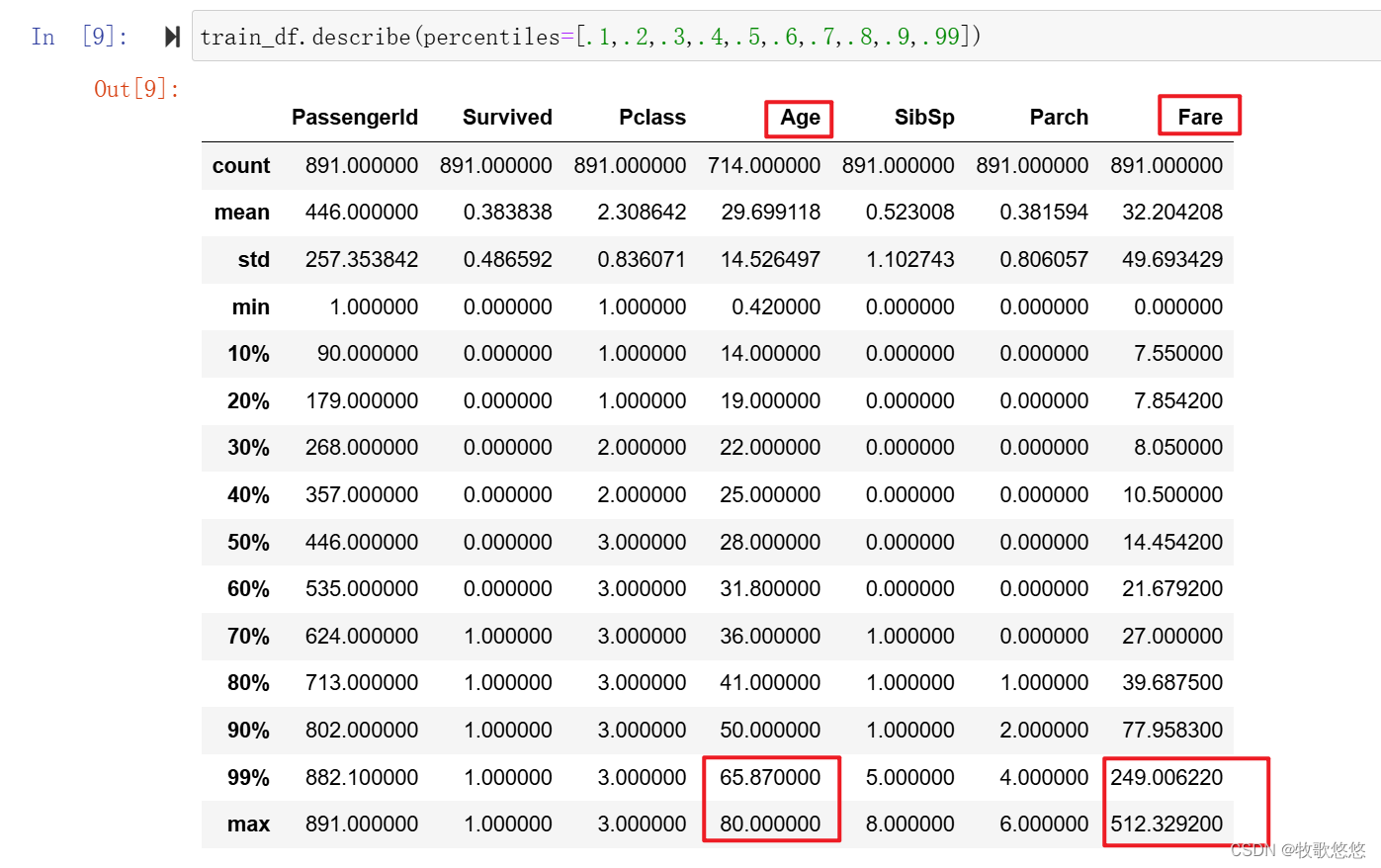
describe()会对所有数值型字段进行一些必要的统计:
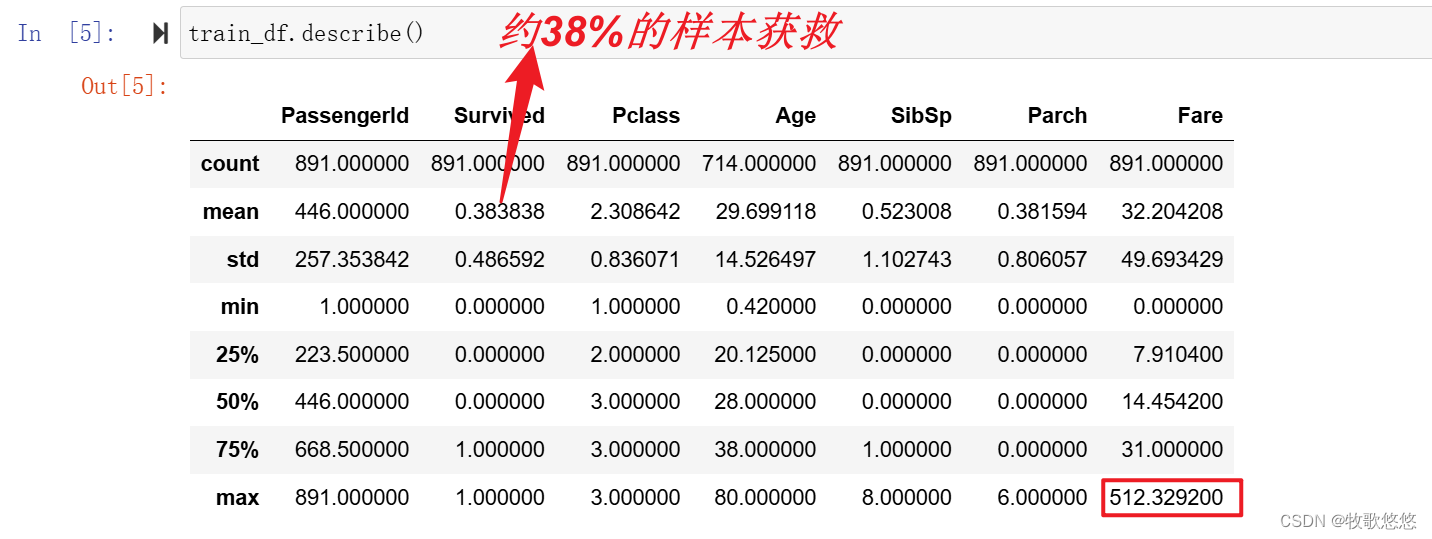
细细体会describe()给出的信息,我们还能多少看到“异常值”(Outlier)的侧影。比如说,票价(Fare)的平均值为32.4美元,而中位数为14.45美元,平均值居然比中位数大很多,说明该特征分布是严重右偏的,我们又看到最大值是512.32美元,严重偏离均值和中位数,所以这个值很可能是潜在的异常值。
此外,还可从describe()的输出大致看到整个数据集的缺失值情况。比如,从count(计数)这个指标来看,多特征的个数都是981个,而年龄只有714个,这表明这个数据集中年龄字段至少有200个值是缺失的。

38%的乘客生存率
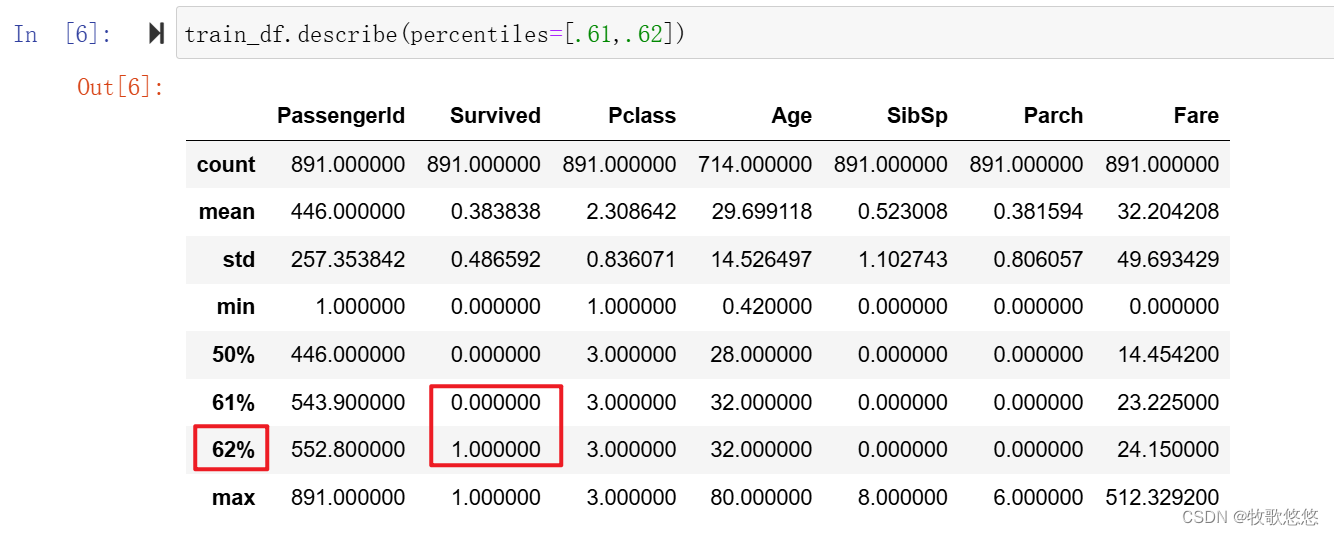
超过76%的乘客没有与父母和孩子一起旅行
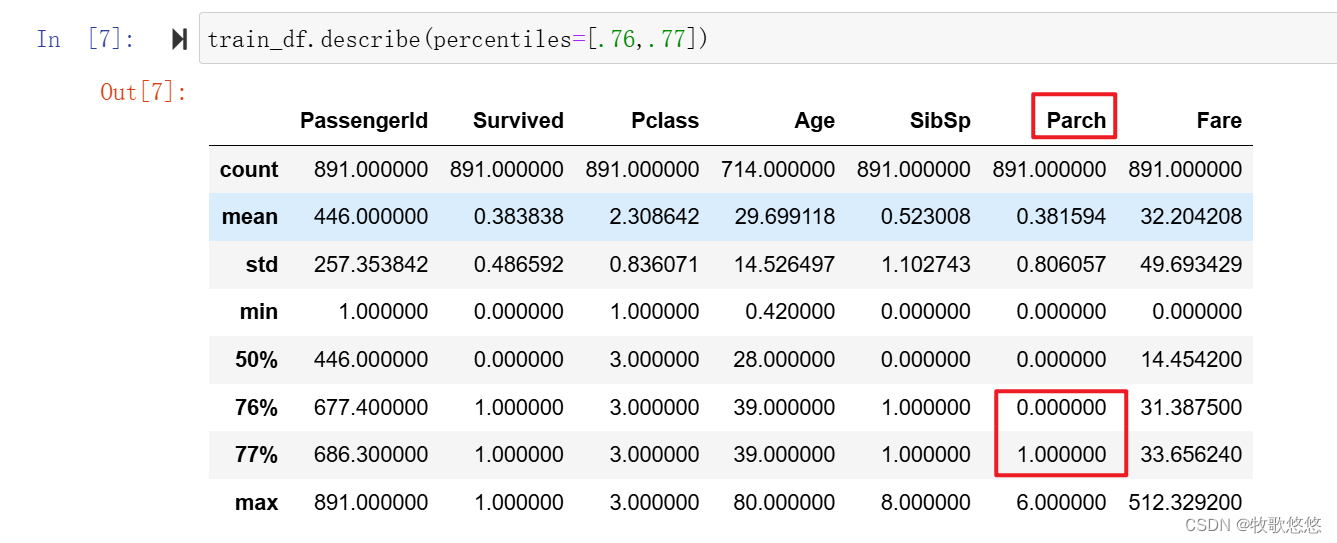
大约31% 的乘客与亲属一起登船
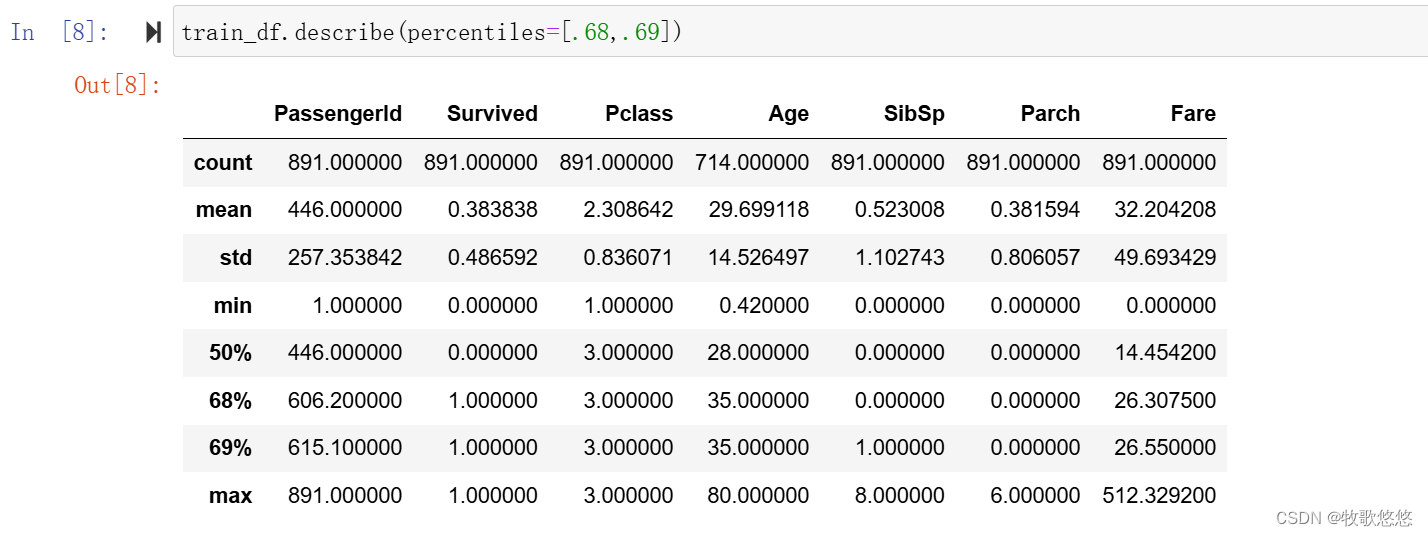
少于1%的乘客付了高达512美元的船票费,少于1%的乘客年龄在64~80岁
Sex特征中有65%为男性
577➗891=0.6476
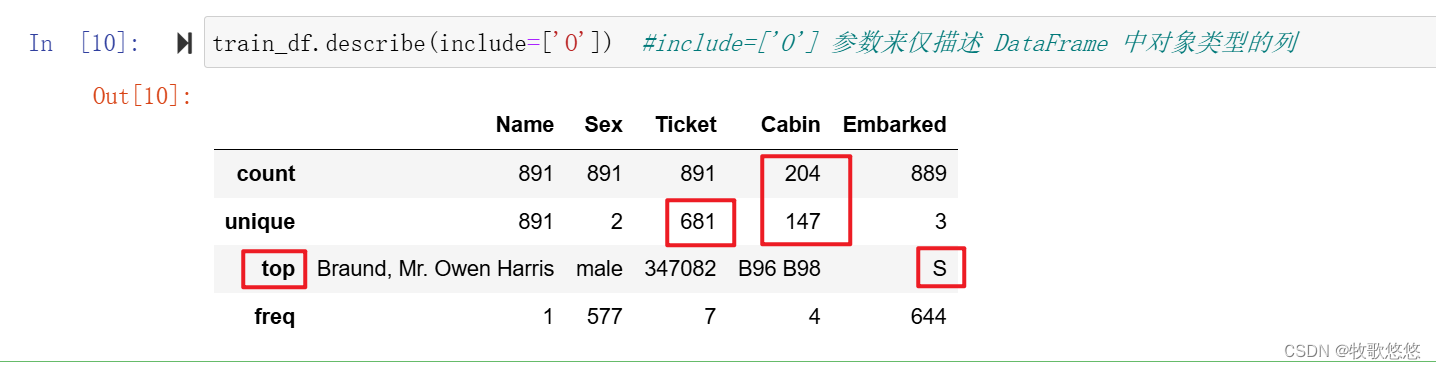
Cabin 中的count 与unique并不相等,说明有些乘客共享一个Cabin
Embarked一共有3种取值,其中从S港口登船的人最多
Ticket的特征下,有22%左右的重复值(unique=618)
4. 特征相关性分析与可视化
fig , [ax1,ax2,ax3] = plt.subplots(1,3,figsize=(20,5))
sns.countplot(x='Sex',hue='Survived',data=train_df,ax=ax1)
sns.countplot(x='Pclass',hue='Survived',data=train_df,ax=ax2)
sns.countplot(x='Embarked',hue='Survived',data=train_df,ax=ax3)
ax1.set_title('Sex 特征分析')
ax2.set_title('Pclass 特征分析')
ax3.set_title('Embarked 特征分析')
countplot()是“计数图”的意思。我们可将它认为是一种对某些分类进行计数的直方图。通过设置方法中的hue参数,可分标签显示不同类别。
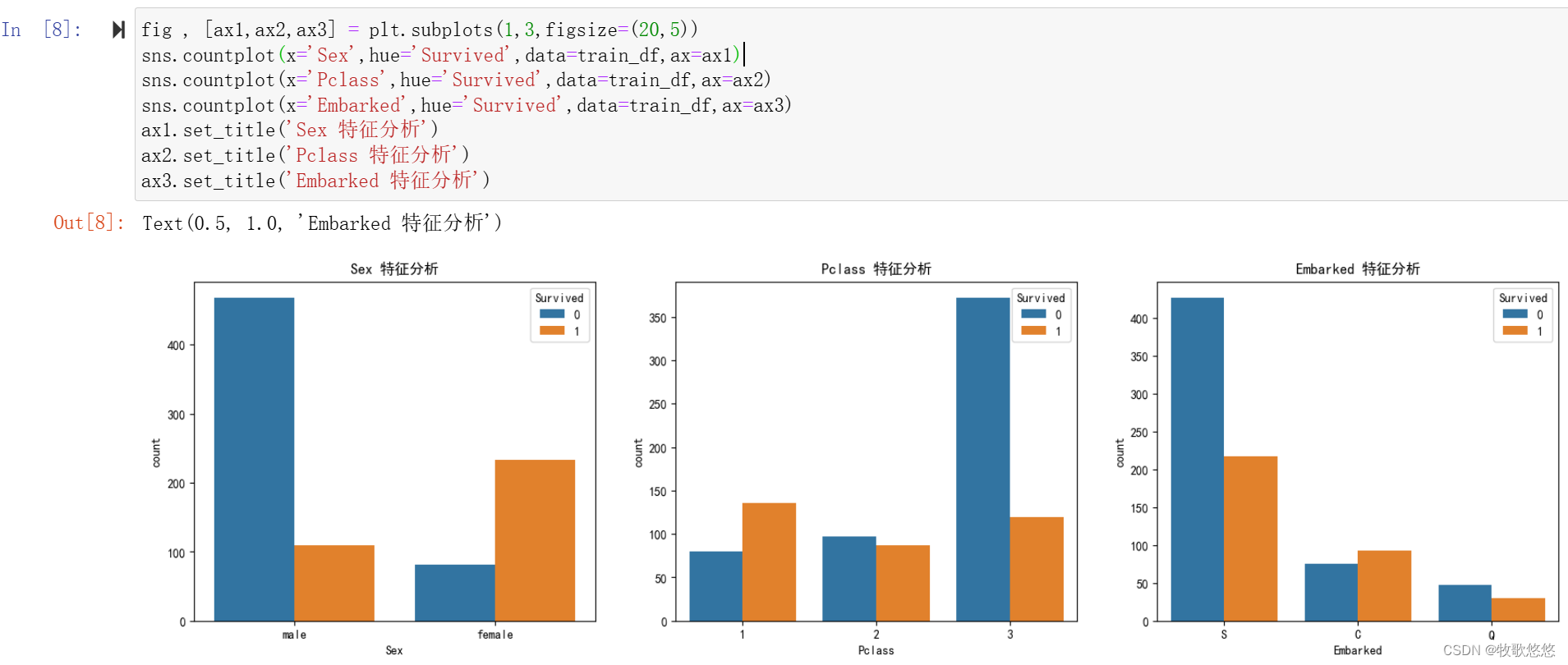
女性有更大的存活率
train_df[['Sex','Survived']].groupby(['Sex'],as_index=False).mean()

上等舱的乘客(Plass=1)有更大的存活率
train_df[['Pclass','Survived']].groupby(['Pclass'],as_index=False).mean()

SipSp和Parch与Survive有相关性
train_df[['SibSp', 'Survived']].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived', ascending=False)

train_df[['Parch', 'Survived']].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived', ascending=False)

还可以进行可视化分析:
fig ,ax =plt.subplots(1,2,figsize=(20,5))
sns.countplot(x='SibSp',hue='Survived',data=train_df,ax=ax[0])
sns.countplot(x='Parch',hue='Survived',data=train_df,ax=ax[1])
ax1.set_title('SibSp 特征分析')
ax2.set_title('Parch 特征分析')
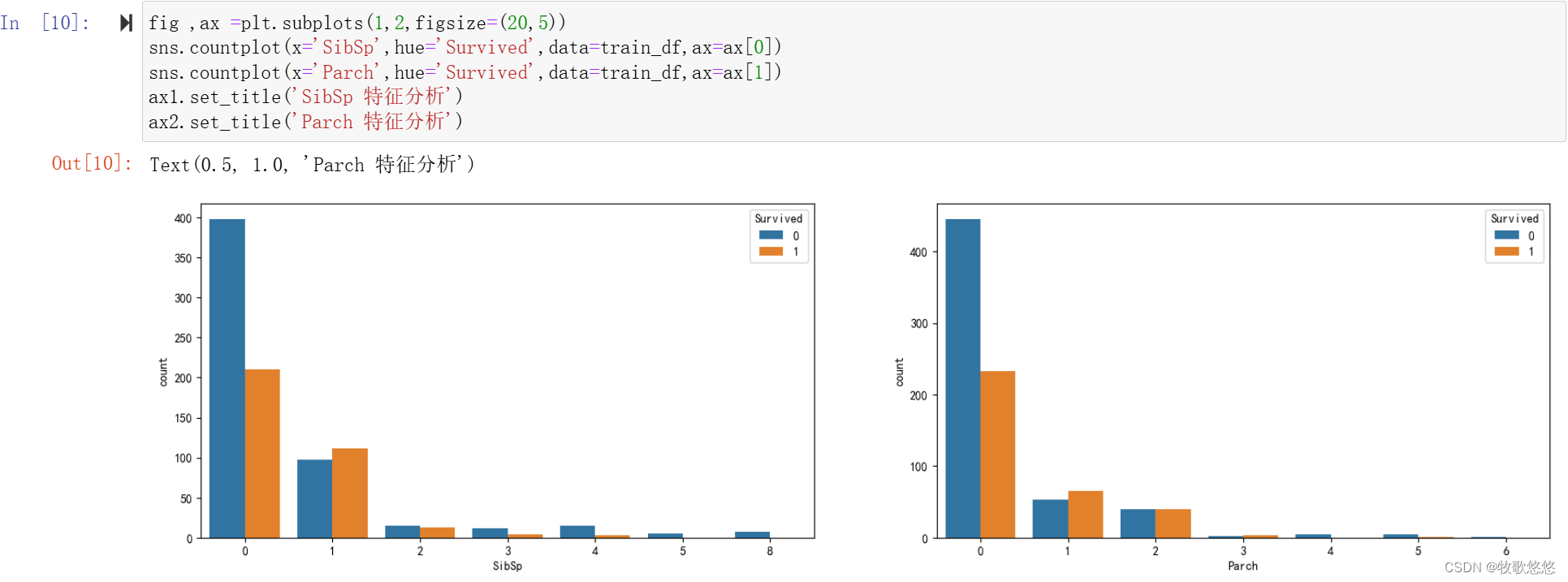
可以看出,配偶或兄弟姐妹数量为0的人(如同Jack一样的单身汉)最多,但获救率最低,而配偶或兄弟姐妹数量为1的人群获救率相对较高,超过50%。观察Parch这个特征可以发现,情况和SibSp基本相同,在做模型特征选择时,可考虑将二者合并。
Age与Survived有相关性
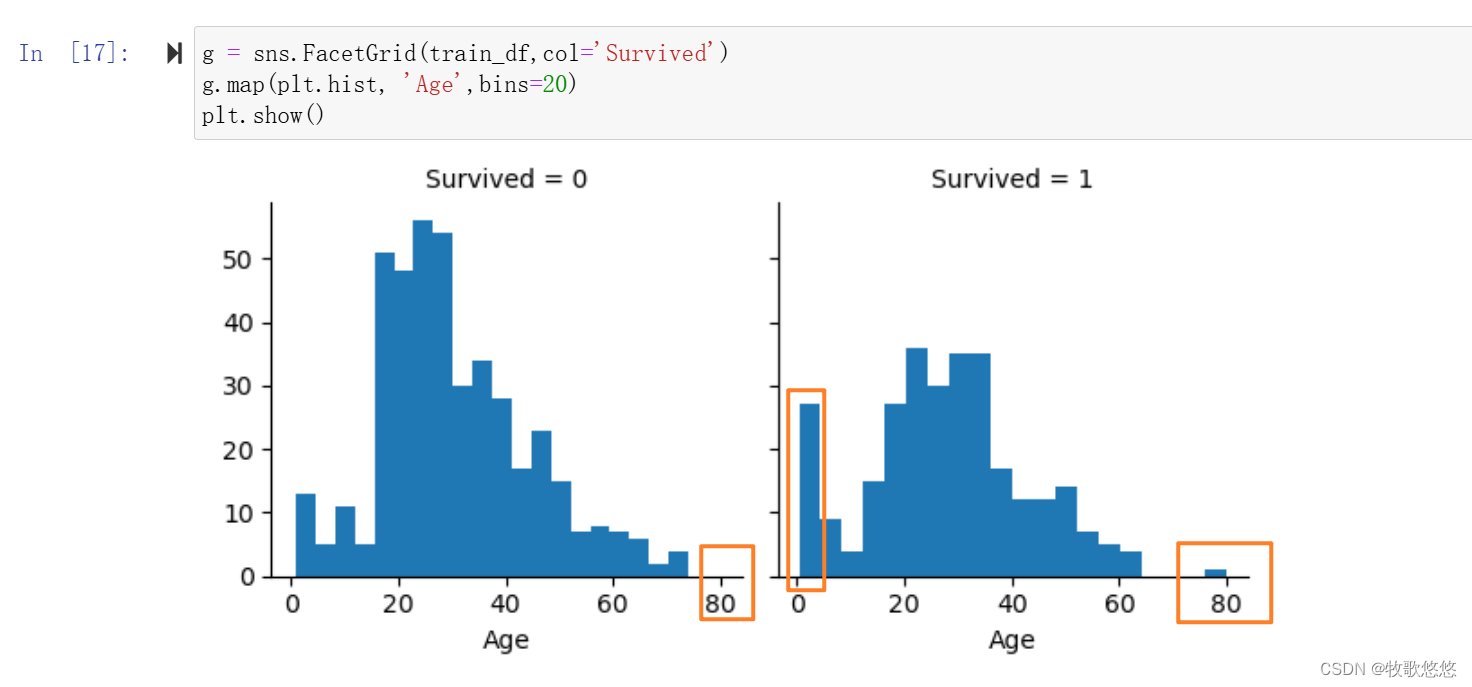
使用了seaborn库中的FacetGrid对象来绘制一个分面图(faceted plot),其中按照train_df数据集中的’Survived’列的值(0表示未存活,1表示存活)来分面,并在每个分面中绘制’Age’列的直方图:
g = sns.FacetGrid(train_df,col='Survived')
g.map(plt.hist, 'Age',bins=20)
plt.show()
'Age’参数指定了要绘制直方图的列,bins=20指定了直方图中条形的数量
密度图
此外,以上分析多是定量分析,我们还可以定性分析。这里的定性特指基于密度图进行分析。下面我们以年龄(Age)特征为例来说明:
fig,ax = plt.subplots(figsize=(20,5))
sns.kdeplot(train_df.loc[(train_df['Survived']==0),'Age'],color='gray',linestyle="--",fill=True,label='非幸存')
sns.kdeplot(train_df.loc[(train_df['Survived']==1),'Age'],color='gray',linestyle="--",fill=True,label='非幸存')
plt.title('Age 特征分布 - Survivor V.S. Not Survivor',fontsize=15)
plt.xlabel("Age(年龄)",fontsize=15)
plt.ylabel("Frequency(频度)",fontsize=15)
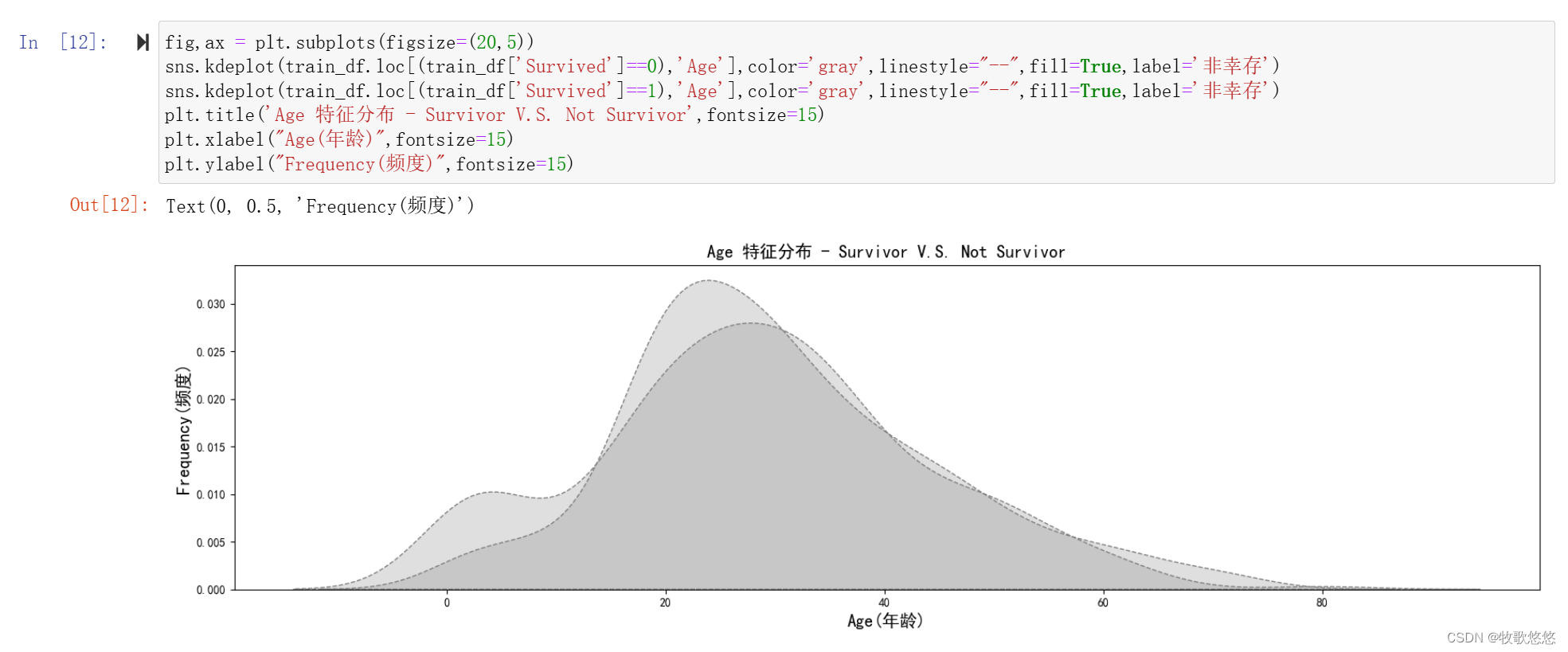
可以很明显看到,15岁以下的乘客的幸存率出现了小高峰,也就是说孩子的幸存率比较高,而对于15岁以上的乘客,幸存与否并无明显区别。
箱形图
当然,我们还可以接着挖掘,看看年龄(Age)和舱位等级(Pclass)有什么关联。
# 箱型图特征分析
fig ,ax = plt.subplots(figsize=(20,5))
sns.boxplot(x = "Pclass", y = "Age", data=train_df,ax=ax)
sns.swarmplot(x="Pclass", y="Age", data=train_df,ax=ax,hue="Survived")
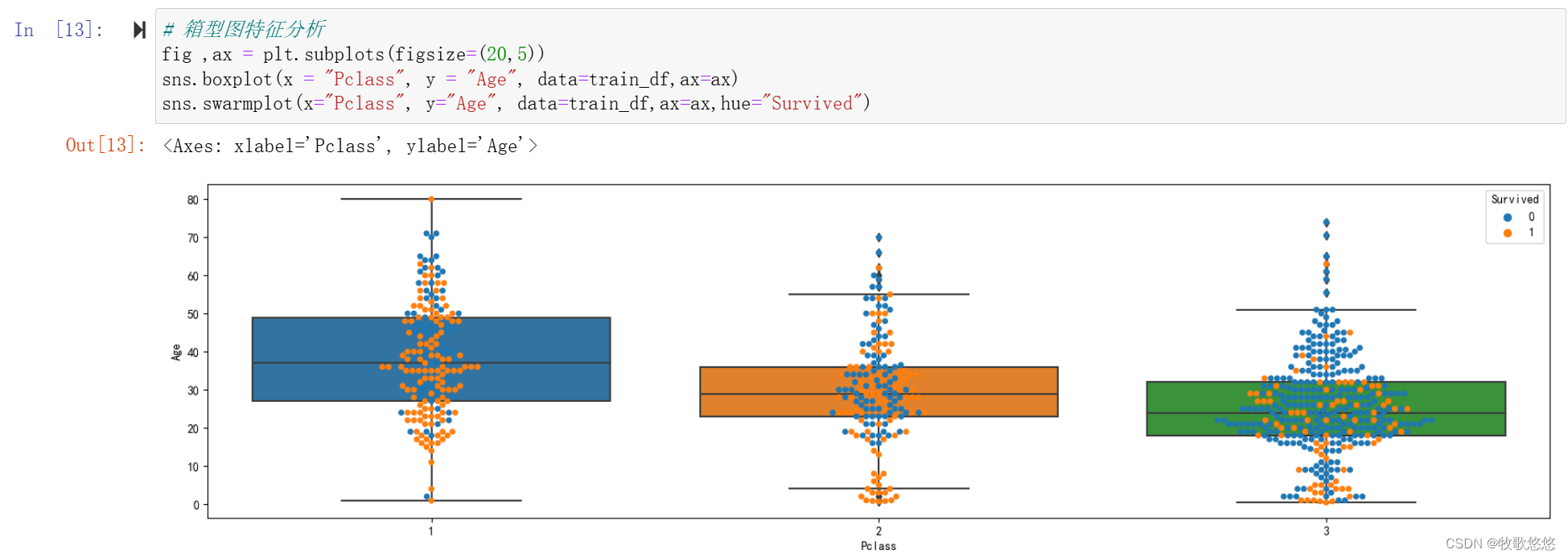
如果说舱位等级(Pclass)能在一定程度上代表社会地位的话,那么,不同Pclass下的年龄分布也不同,三个分布的**中位数(箱形图的中间线)**的关系为Pclass1 > Pclass2 > Pclass3。
社会地位高的人,年龄一般会比较大。而三等舱中人数众多,他们大多数是普通的想去美国讨生活的年轻人,年龄在20~30岁之间。
我们还用swarmplot()绘制了带分布的散点图,并用不同的颜色展示是否幸存,从图中可以看出,社会等级较高(即Pclass等级高)的人,他们的幸存率更高。
PS:从代码层面,如果想将两种不同类型的图形绘制在一起,可将它们的绘图坐标轴设置为一样的。
5. 数据清洗与预处理
前面我们已经收集了一些假设和结论,接下来清洗数据。
修正数据
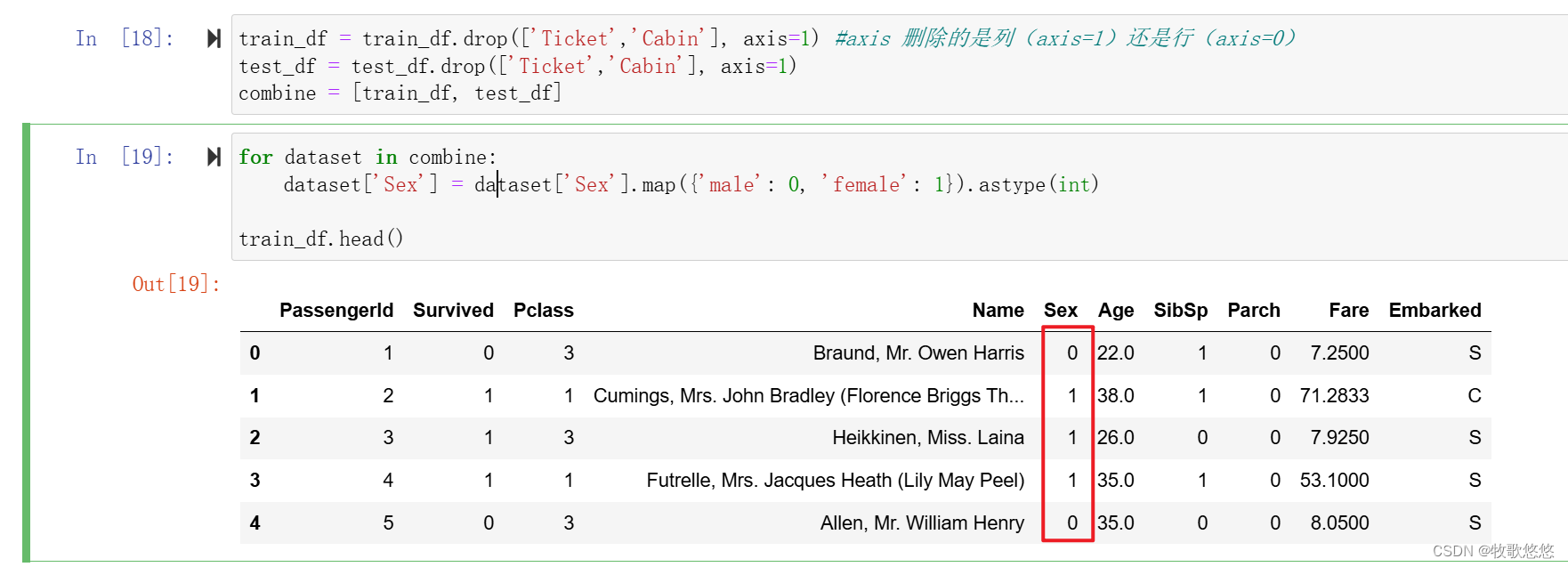
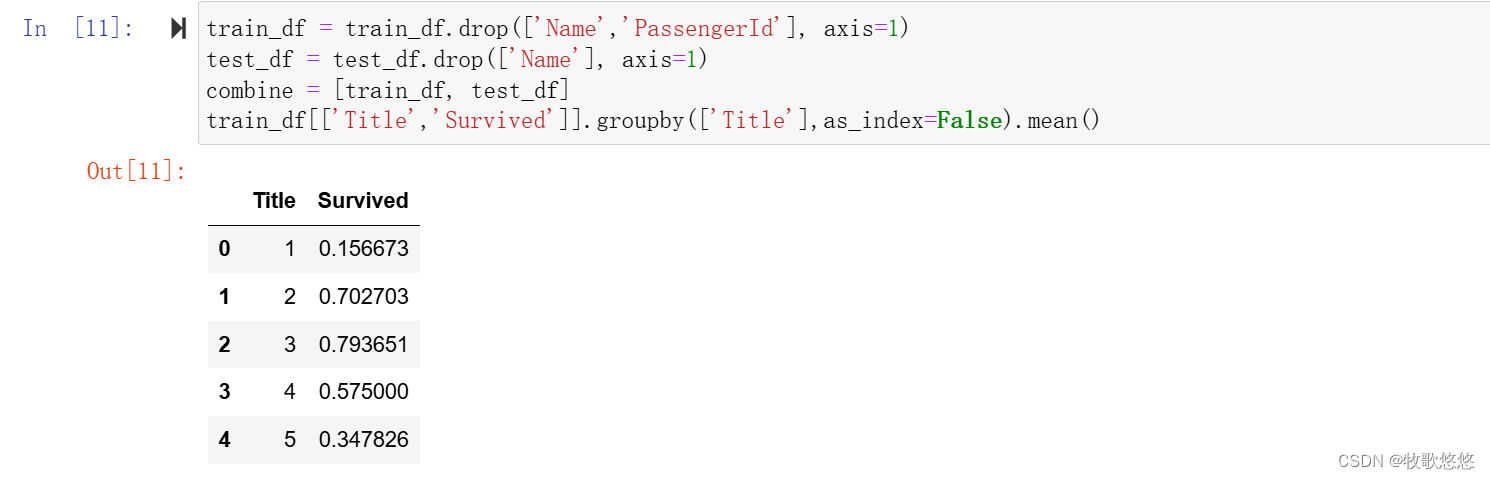
丢弃Cabin 和 Ticket这两个特征(同时在训练集和测试集中丢弃)
train_df = train_df.drop(['Ticket','Cabin'], axis=1) #axis 删除的是列(axis=1)还是行(axis=0)
test_df = test_df.drop(['Ticket','Cabin'], axis=1)
combine = [train_df, test_df]
female 转换为1,male 转换为0
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map({'male': 0, 'female': 1}).astype(int)
train_df.head()
创建数据
Title特征
从Name特征中提取Title特征,并测试Title与Survive之间的关系
在泰坦尼克号数据集中,乘客的姓名(Name 列)通常包含了他们的称谓(如 Mr., Mrs., Miss., Master, Dr., etc.),这些称谓后面通常跟着一个点(.)和乘客的名字。由于这些称谓可能与乘客的社会地位、年龄或性别有关,它们可能包含对预测乘客生存几率有用的信息。
在数据分析和机器学习的预处理阶段,提取这些称谓并将其作为新的特征(或称为列)添加到数据集中是很常见的做法。这有助于捕捉原始数据中可能隐藏的模式或相关性,并可能提高模型的预测性能。
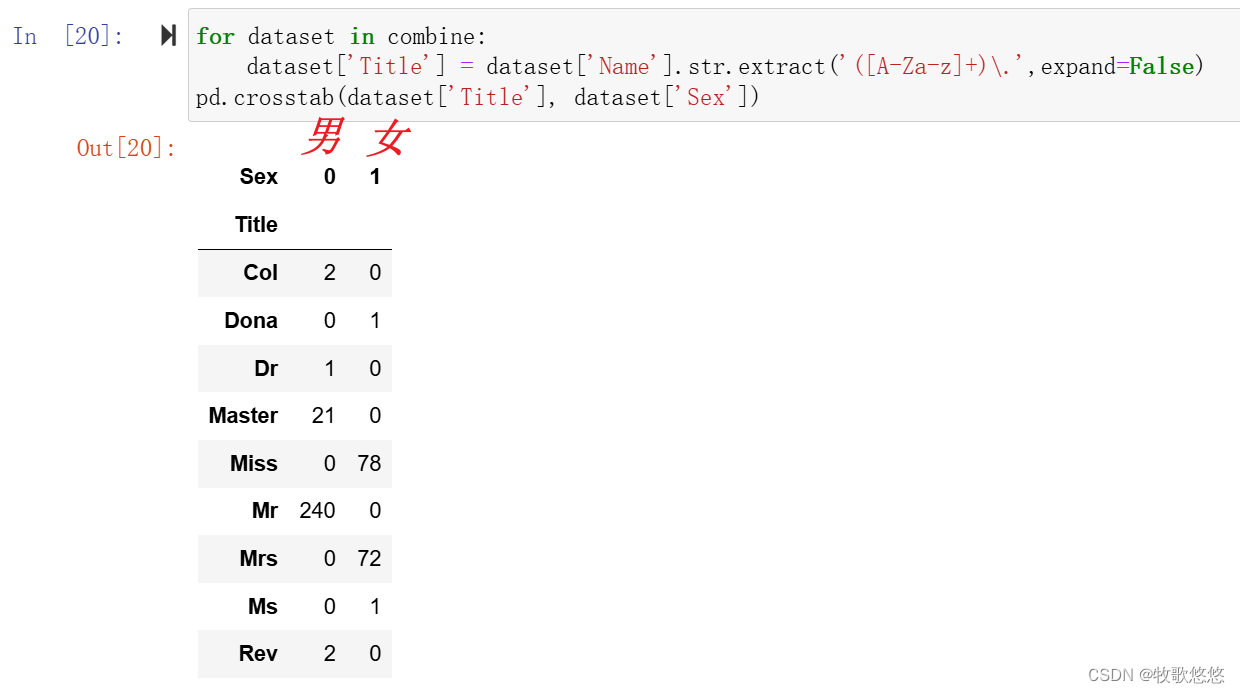
for dataset in combine:
dataset['Title'] = dataset['Name'].str.extract('([A-Za-z]+)\.',expand=False)
pd.crosstab(dataset['Title'], dataset['Sex'])
使用 pandas 的 .str.extract() 方法可以很容易地从包含这些称谓的字符串中提取它们。在这个方法中,我们使用了正则表达式 ([A-Za-z]+)\. 来匹配一个或多个字母(不区分大小写),后面紧跟着一个点号(.)。正则表达式的括号 () 用于捕获匹配的文本,而 expand=False 参数确保只返回一个列
再将Title特征中常见的称呼用“Rare”来替代:
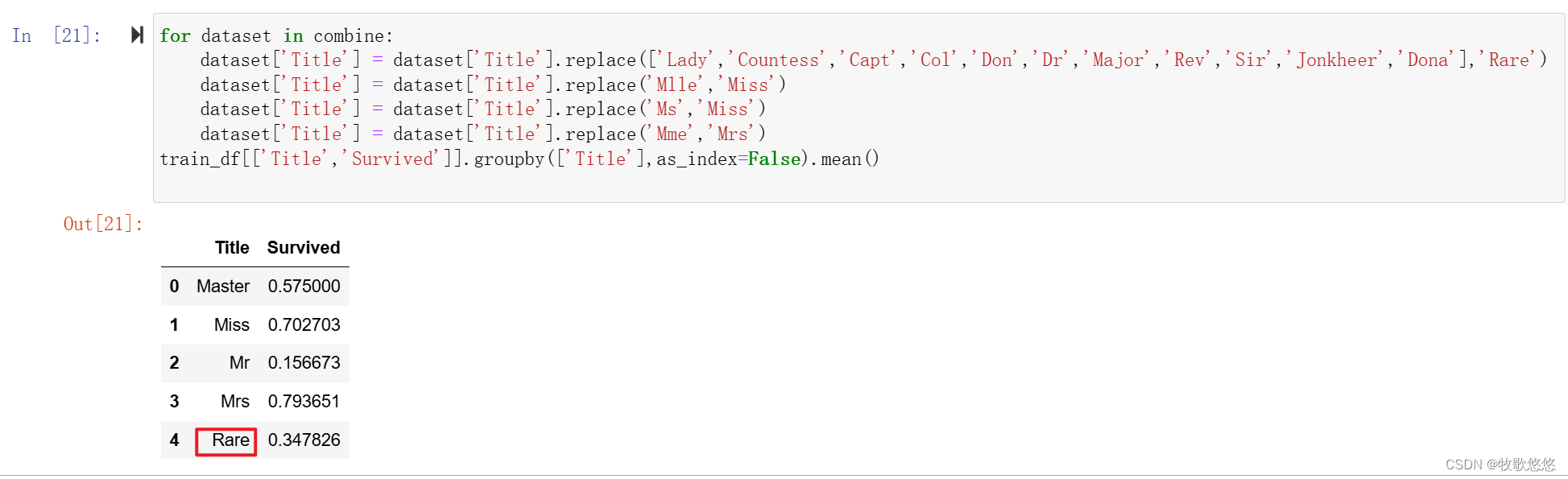
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady','Countess','Capt','Col','Don','Dr','Major','Rev','Sir','Jonkheer','Dona'],'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle','Miss')
dataset['Title'] = dataset['Title'].replace('Ms','Miss')
dataset['Title'] = dataset['Title'].replace('Mme','Mrs')
train_df[['Title','Survived']].groupby(['Title'],as_index=False).mean()
再将离散型的Title转化为有序的数值型:
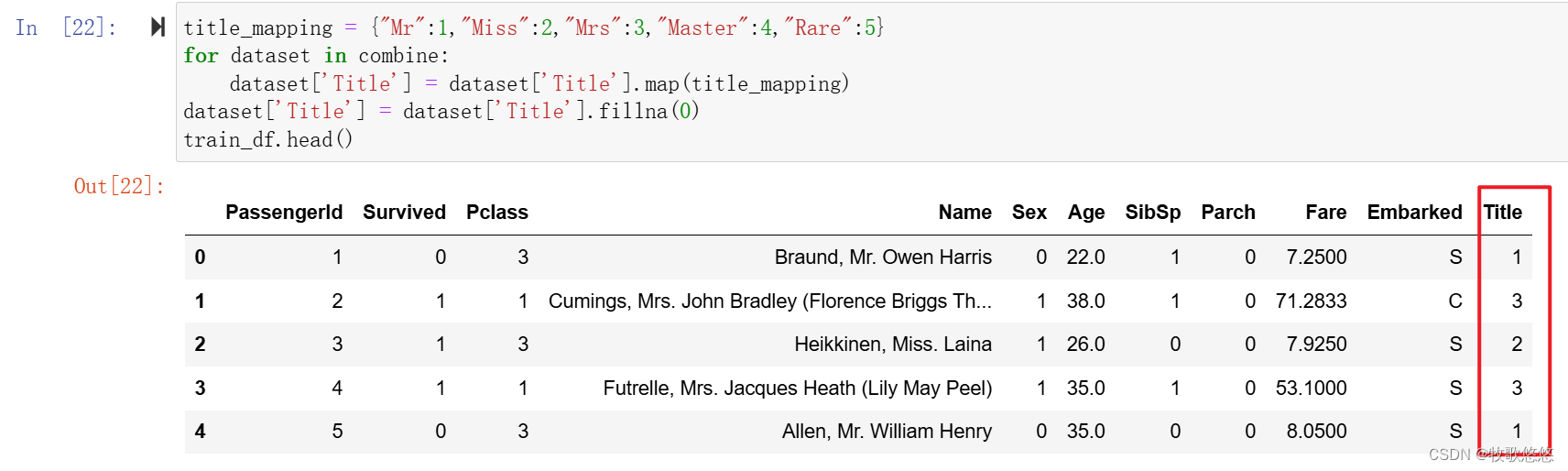
title_mapping = {"Mr":1,"Miss":2,"Mrs":3,"Master":4,"Rare":5}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
train_df.head()
丢弃Name 特征和PassengerId 特征
现在丢弃训练集和测试集中的Name特征,丢弃训练集的PassengerId特征
train_df = train_df.drop(['Name','PassengerId'], axis=1) #axis 删除的是列(axis=1)还是行(axis=0)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]
IsAlone 特征
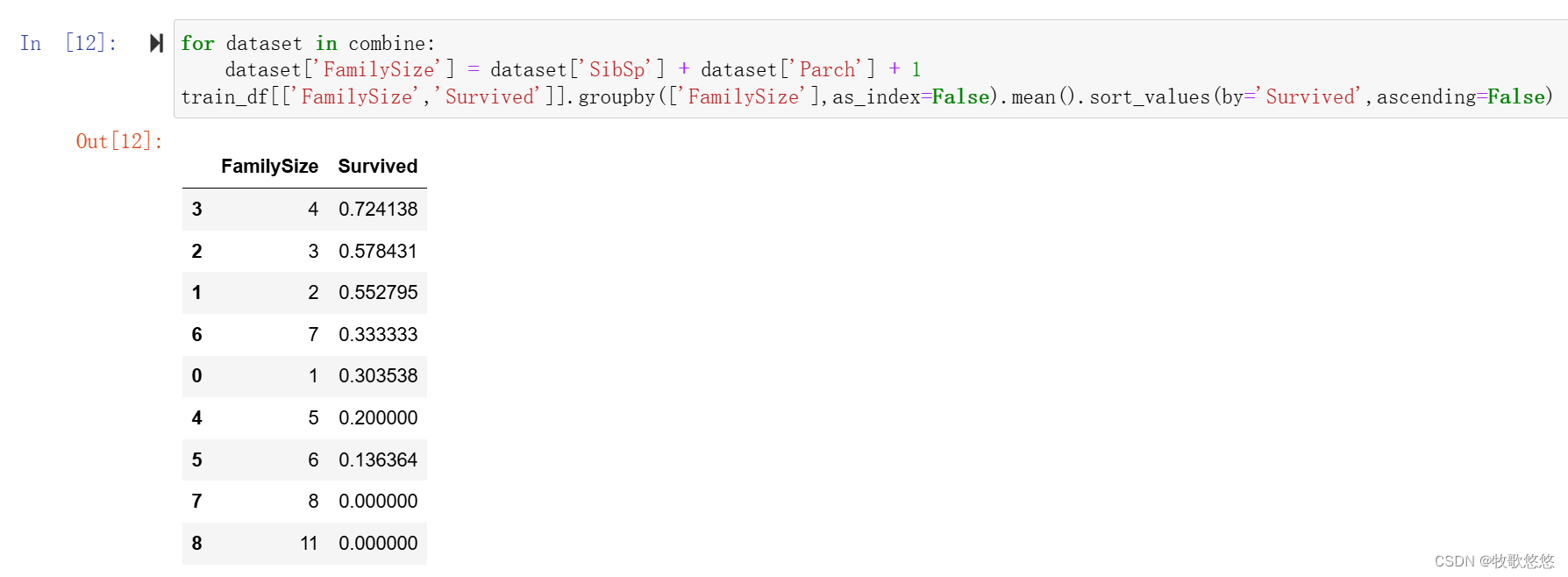
组合Parch和SibSp特征,创建一个新的FamilySize特征,再通过FamilySize特征创建一个名为IsAlone的特征。最后丢弃Parch、SibSp和FamilySize特征,保留IsAlone特征。
for dataset in combine:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
train_df[['FamilySize','Survived']].groupby(['FamilySize'],as_index=False).mean().sort_values(by='Survived',ascending=False)


















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









