







以某狗音乐为例
import requests
import re
import time
import hashlib
def GetResponse(url):
# 模拟浏览器
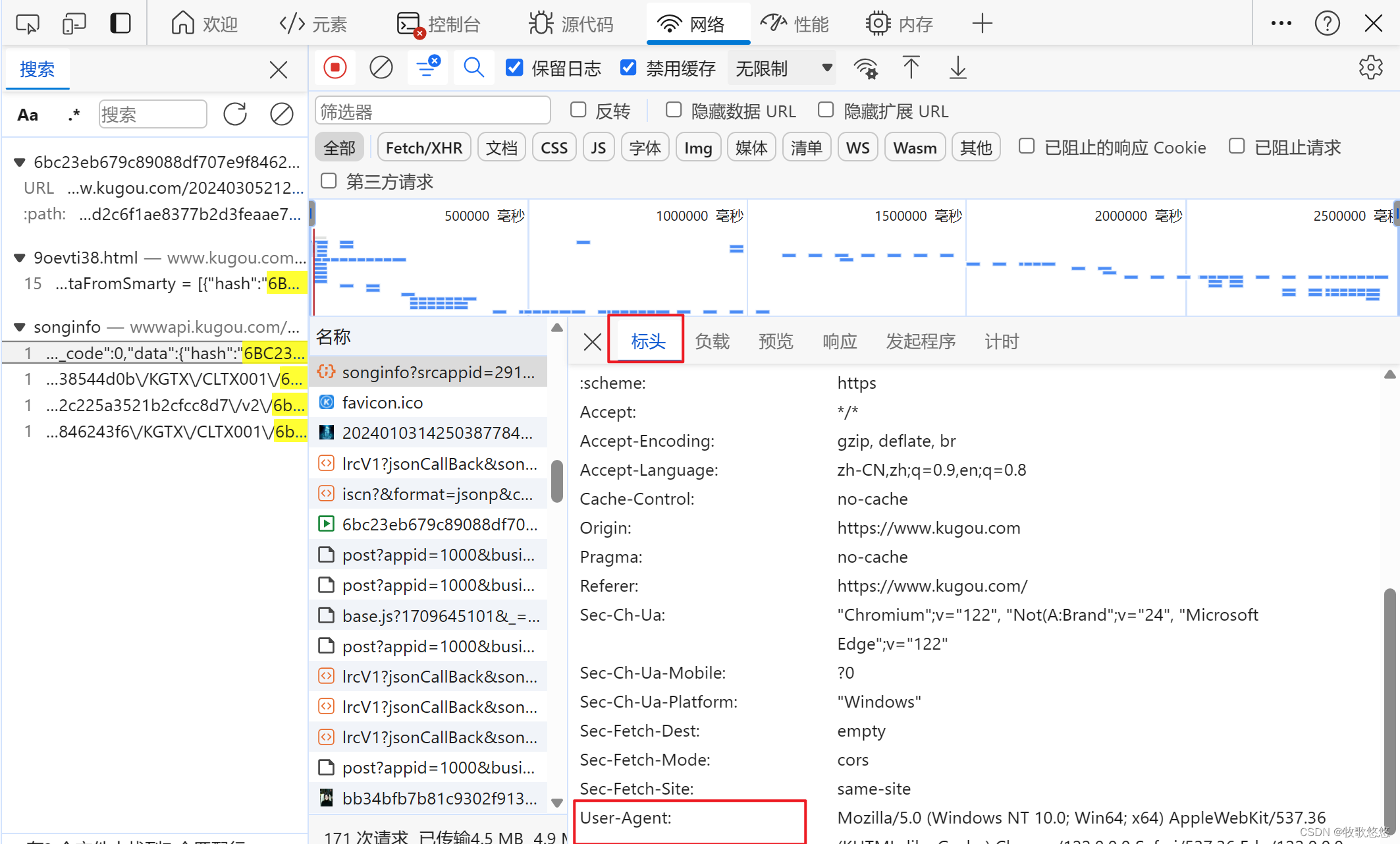
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'
}
# 发送请求
response = requests.get(url=url,headers=headers)
# 返回内容
return response
def GetInfo():
# 请求网址
link='https://wwwapi.kugou.com/play/songinfo?srcappid=2919&clientver=20000&clienttime=1709645100257&mid=99fdc9044912dc3185ee58da1a9f87d0&uuid=99fdc9044912dc3185ee58da1a9f87d0&dfid=3exBpJ2WlTHO4N287r0necyx&appid=1014&platid=4&encode_album_audio_id=9oevti38&token=2544e791bc15f255e8737748178f76680a2205d03c2259e2fc4892e9aa500045&userid=2195647882&signature=a6efee3c478d7a625553ab35eb149df9'
JsonData = GetResponse(url=link).json()
# 提取歌曲链接
play_url = JsonData['data']['play_url']
# 提取歌名
audio_name = JsonData['data']['audio_name']
# 获取数据
return audio_name,play_url
def Save(title,url):
# 对歌曲链接发送请求
music_data = GetResponse(url=url).content
# wb 保存模式
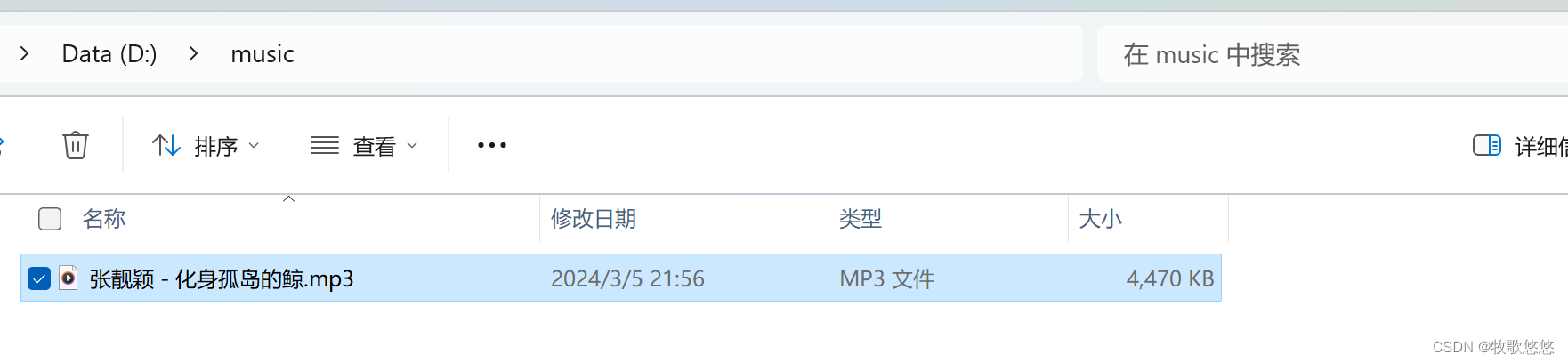
with open("D:/music/{}.mp3".format(title), mode='wb') as f:
f.write(music_data)
if __name__ == '__main__':
audio_name,play_url = GetInfo()
Save(audio_name,play_url)
print(audio_name,'保存成功!!')
修改User-Agent,link,保存地址即可。
详细步骤截图:
点开播放某首音乐
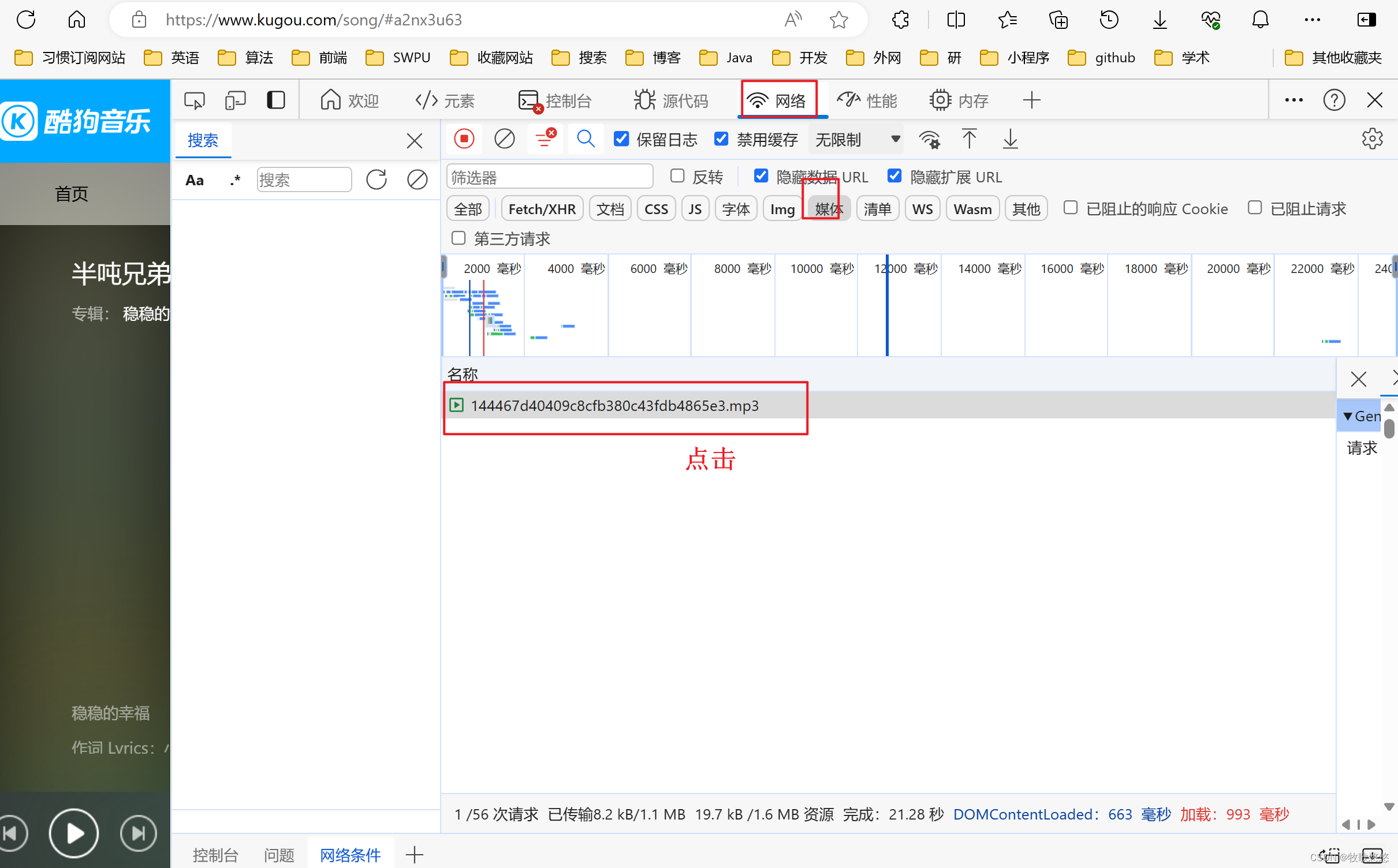
复制搜索
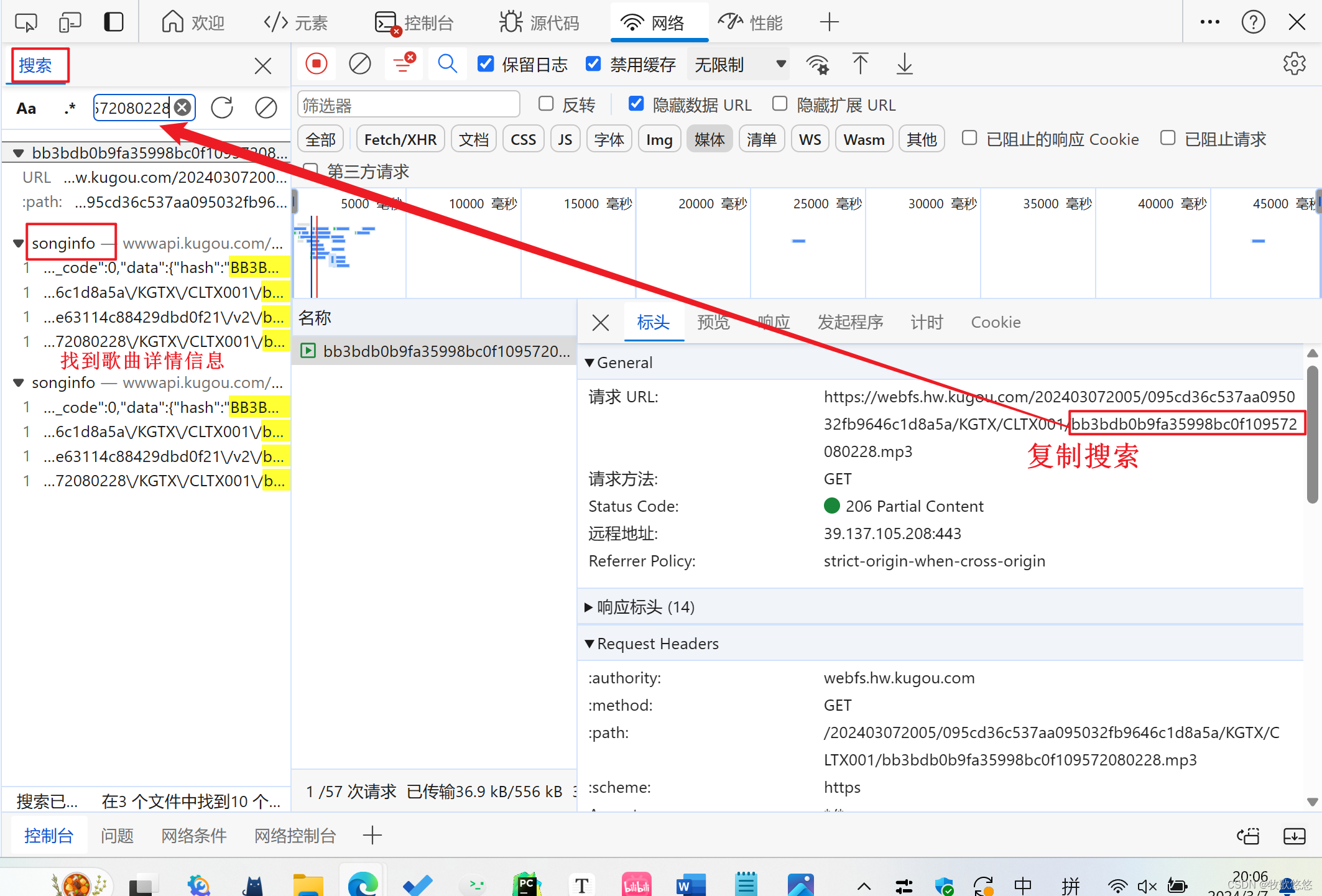
找到songInfo,link就是请求URL
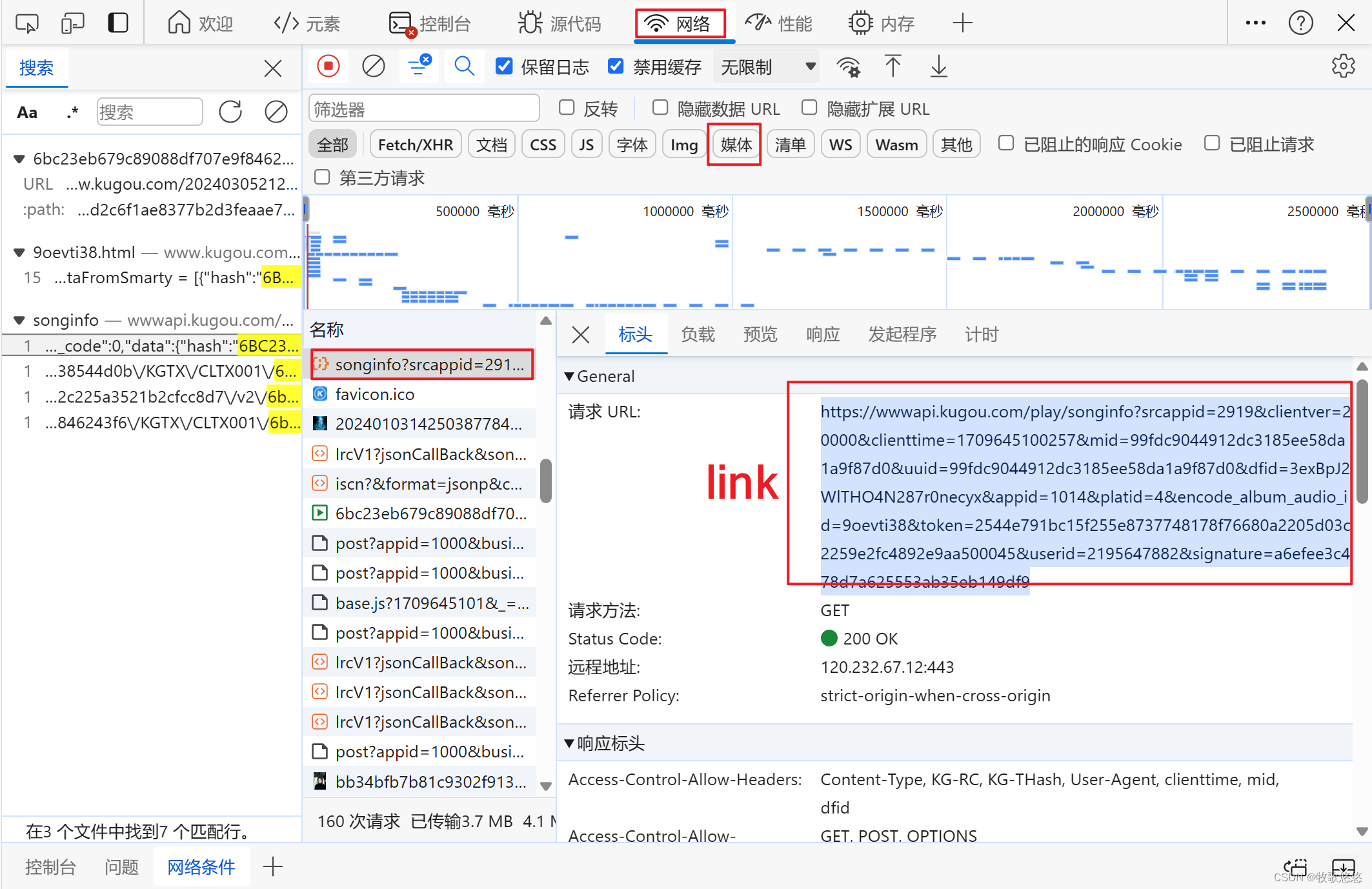
















 3891
3891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









