







在KMP模式匹配算法中,next数组是一个很关键的东西,next[j]表示当模式中第j个字符与主串中相应字符“失配”时,在模式中需重新和主串中该字符进行比较的字符的位置。理解求next数组的算法是一个难点,在本文中,我尽量不使用公式,只通过描述性语句来说明这个算法到底做了什么,是怎么求出的next数组。
next数组的定义方式有两种,第一种是严蔚敏数据结构书中的定义方式,next数组下标为0的地方没有存储数据,下标为1的地方存储模式中第一个字符的next值,其定义方式如下:

与此对应,字符串下标为0的位置存储的是字符串的长度,字符是从下标1处开始存储的。
另一种定义方式实际使用时比较常见,next数组的值是从下标0处开始存储的,与之对应的字符串也是C风格的,以“\0”结尾,此时的next数组对应位置的值比第一种定义中的分别小1,原理相同,这里使用第一种定义。
在第一种定义下,next数组的值有两个含义:
1、对于求next数组的程序,next[j]指 字符串T中j字符之前的字符串 的前缀与后缀匹配的字符数加1
2、对于使用next数组的KMP程序,next[j]指子串中j处字符与主串不相等时,j需回溯到的位置
(结合二者,可知字符串T中j字符之前的字符串的前缀与后缀匹配的字符数加1 的值等于 子串中j处字符与主串不相等时,j需回溯到的位置,至于二者为什么相等,可以参考《算法导论》字符串匹配一章的证明。)
对于next数组的求法,如果直接笔算的话并不难写出,
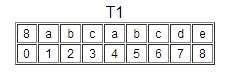
如对于字符串T1,
| 8 | a | b | c | a | b | c | d | e |
其对应的next数组为(下标0处存储字符串长度):
| 8 | 0 | 1 | 1 | 1 | 2 | 3 | 4 | 1 |
下面就是我们最常见到的求next数组的算法:
void get_next(String T, int *next)
{
int i, j;
i = 1;
j = 0;
next[1] = 0;
while(i < T[0]) //此处T[0]表示串T的长度
{
if(j == 0 || T[i] == T[j]){ //T[i]表示后缀的单个字符
i++; //T[j]表示前缀的单个字符
j++;
next[i] = j;
}
else
j = next[j]; //若字符不相同,则j值回溯
}
}int Index_KMP(String S, String T)
{
int i = 1, j = 1; //i用于主串S当前位置下标值,j用于子串T
int next[MAXSIZE];
get_next(T, next);
while(i <= S[0] && j <= T[0]){
if(j == 0 || S[i] == T[j]){
i++;
j++;
}
else{
j = next[j]; //j回溯到合适的位置,i值不变
}
}
if(j > T[0])
return i - T[0];
else
return 0;
}我是通过函数运行的过程对get_next函数进行分析的,输入上述的T1字符串,可得i与j的变化过程如下:
| i | 1 | 2 | * | 3 | * | 4 | 5 | 6 | 7 | 7 | * | 8 |
| j | 0 | 1 | 0 | 1 | 0 | 1 | 2 | 3 | 4 | 1 | 0 | 1 |
| 8 | a | b | c | a | b | c | d | e |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
结合get_next程序和i,j的变化表,可以发现:i值只增不减,j值由于存在回溯,有增有减,这一点与KMP程序的执行过程很相似;
此外,由程序可知,next[1]=0,next[2]=1是固定的,分别对应于T1[j]前不含和只含一个字符,这两个next值不随字符串T变化,这从定义中也可得出。
在i,j变化表中,除了初始行i=1,j==0和最后一行i=8,j=1,同时含有两数(不含*)的行都执行了语句T[i]==T[j],
也就是说,当T1[i]的前面含有两个或两个以上的字符时,首先对首字符T1[1]和T1[i-1]进行比较,
如果相等,执行语句:
i++;
j++;
next[i] = j;即i,j同时加1,j代表了前后缀匹配的字符数,并将j值赋给next[i],i,j同时加1相当于它们所指向的位置同时后移一位,然后再执行比较语句T[i]==T[j],
如果仍然相同,进行上述同样的操作;
如果不相等,则执行语句:
j = next[j]; //若字符不相同,则j值回溯 KMP算法中有一句相同的语句,事实上,它们的作用也相同,在朴素的模式匹配算法(即原始的直接匹配算法)中,如果遇到不等的字符,主串与子串都需要回溯,子串的当前字符需回溯到首位,而主串当前字符要回溯到上次匹配首位的下一位,而在KMP中,由于next数组的应用,主串不需要回溯,子串也不一定要回溯到首位,而是根据不相等位的next值进行回溯。
为了便于理解,下面画出字符串匹配过程中,子串回溯的过程:
如下图所示,上面是主串,下面是子串,在x位置处出现了字符不相等:

由于x位置处的next值为3,则在下次匹配过程中,可以直接跳到下标为3的字符处进行比较,即是c的位置,如下图:
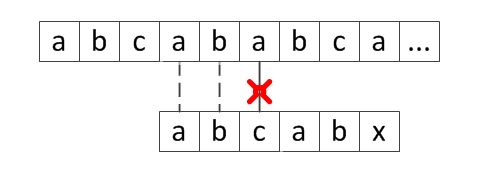
虚线表示不需要进行,即被省略的比较。
下面注意力重新回到get_next函数的j = next[j]语句,它利用前面已经求得的next值进行回溯,以找到当前字符不相等时,j需要回溯到的地方,这里有一种递归的意味;
再来看i,j变化表,当T[i]处遇到不相等字符时,
若前后缀已匹配的字符数为0,则说明之前是T1[1]和T1[i-1]的比较,即j=1,j值按照j=next[1]=0进行回溯,对应于j==0语句,接下来的三步操作前面已经分析过;
若前后缀已匹配的字符数不为0,如i=7,j=4时,(此时前后缀已匹配的字符数为3),则j值按照j=next[4]=1进行回溯,回溯后比较
T1[7]与T1[1],为什么要回溯到next[4]呢,来看T1字符串:
当i=7时,前面已知前后缀有三个字符匹配,即abc,然后i,j各加1,比较a与d,字符不相等,接下来i值不变,也就是d不变,j值回溯,意即既然长的匹配不了,那就退而求其次,看看短的能不能匹配,这是容易理解的思路,而恰好next[4]中的值指的就是当下标为4的字符与主字符(即i所指的字符)不匹配时,应该与主字符比较的下一个字符的下标,在这里,next[4]为1,则接下来应该比较d与a(a的下标为1)。
下面再举一个例子来说明next数组回溯的妙处:
令字符串T2如下:
| 9 | a | b | a | e | a | b | a | b | h |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
已得在下标为8处的b字符处,next[8]=4,意即此时j=4,接下来比较b与e(i=8,j=4),二者不等,
然后,i不变,j值按照j=next[j]=next[4]=2回溯至2,
此时i=8,j=2,比较T2[8]与T2[2],二者相等都是b,至此就不用再回溯了,可得next[9]=j++=3;
这里由于next数组的使用,当b与e不等时,j不用直接跳回到字符串首部让b与a(j=1)去比较,只需要按照next[4]的指引与b(j=2)比较即可,如果相等,可直接得出h处的next值,如果不等,则j需要继续回溯,直至j为0。
事实上,按照next数组的定义,完全可以用朴素的模式匹配算法来求next数组,那样的话就容易理解多了,在上面的get_next函数中,求后面的next值需要用到前面已经求得的next值,正是这一点给算法的理解带来了困难。















 1190
1190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









